环境搭建请参考:Win10 搭建 YOLOv8 运行环境(20240423)-CSDN博客
环境测试请参考:本地运行测试 YOLOv8(20240423)-CSDN博客
一、使用 YOLOv8 的 coco128 数据集熟悉一下如何训练和预测
1.1、在项目根目录下创建文件夹 datasets。
。 1.2、在 datasets 目录下添加 yaml 配置文件 coco128.yaml,并复制以下内容。
# 数据集的根目录路径。
# 由于 YOLOv8 对目录做了默认的一些设置(第一次运行时的位置,而不是当前项目路径来查找),
# 虽然可以修改配置文件或者在代码中指定,但是我觉得在这边使用绝对路径更为方便一些。
path: E:/PyCharmProjects/yolov8_learn/datasets/coco128
# 训练图像位于 images/train2017,这是相对于 path 的相对路径
train: images/train2017
# 验证图像也位于 images/train2017,与训练图像使用相同的路径。
# 需要注意的是,通常训练集和验证集应该包含不同的图像,以确保模型验证的有效性。但在这里,它们使用了相同的图像,这在实际应用中可能不是最佳实践。
val: images/train2017
# 测试图像的路径,这是一个可选字段。
test:
# 类别
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush1.3、下载 coco128(下载地址)训练集数据,解压后将 coco128 文件夹放在 datasets 目录下。数据集包含两个子文件夹 images(用于训练的图片) 和 labels(每张图片对应的标签),此处images 和 labels 文件夹下只有一个名为 train2017 的文件夹,实际上应该分别再创建 train(训练)、val(验证)、test(测试)等文件夹,例如 train2017、val2017、test2017。当然这不是必须的,训练、验证、测试都使用相同的图片也是没有问题的。
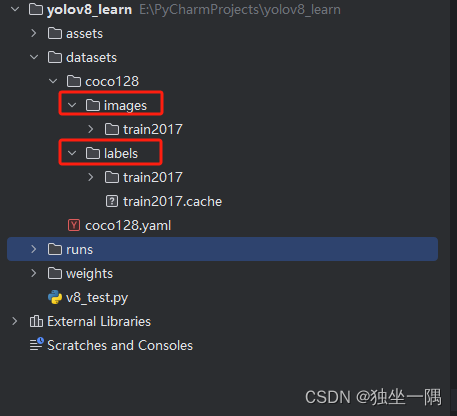
1.4、编写代码,启动训练。
from ultralytics import YOLO
if __name__ == '__main__':
# 训练数据集
# YOLOv8 提供了 n、s、m、l、x 五种预训练模型,模型精度递增,相应的训练速度越慢
# 加载一个预训练模型
model = YOLO('./weights/yolov8m.pt')
# 启动模型的训练
# 1)、data = './datasets/coco128.yaml': 这个参数指定了用于训练的数据集配置文件
# 2)、epochs=3: 这个参数指定了训练的轮数(或周期)
# 3)、results = ...: 这行代码将训练过程的结果(如损失值、准确率、模型权重更新等)赋值给results变量。这些结果可以用于后续的分析和模型评估
results = model.train(data='./datasets/coco128.yaml', epochs=3)
1.5、训练后的结果将保存到 runs 目录下。
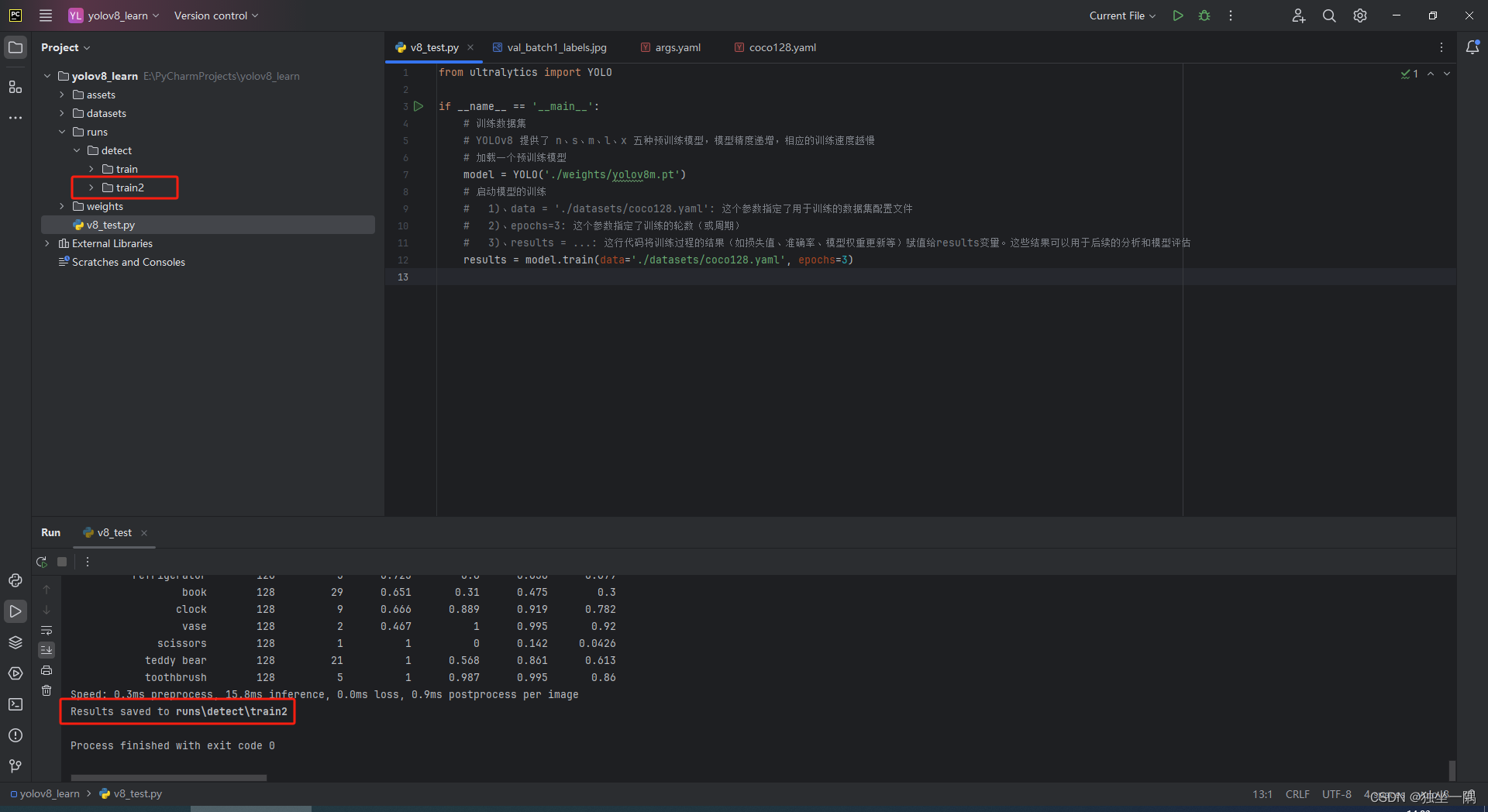
1.6、编写代码,启动预测。不过这次我们不用 YOLOv8 的模型,使用之前训练后得到的最好的一次结果模型。
from ultralytics import YOLO
if __name__ == '__main__':
# 预测数据集
# 加载一个预训练模型
model = YOLO('./runs/detect/train2/weights/best.pt')
# 预测图片 ./assets/zidane.jpg,并保存预测结果
results = model.predict("./assets/zidane.jpg", save=True)1.7、预测后的结果将保存到 runs 目录下。
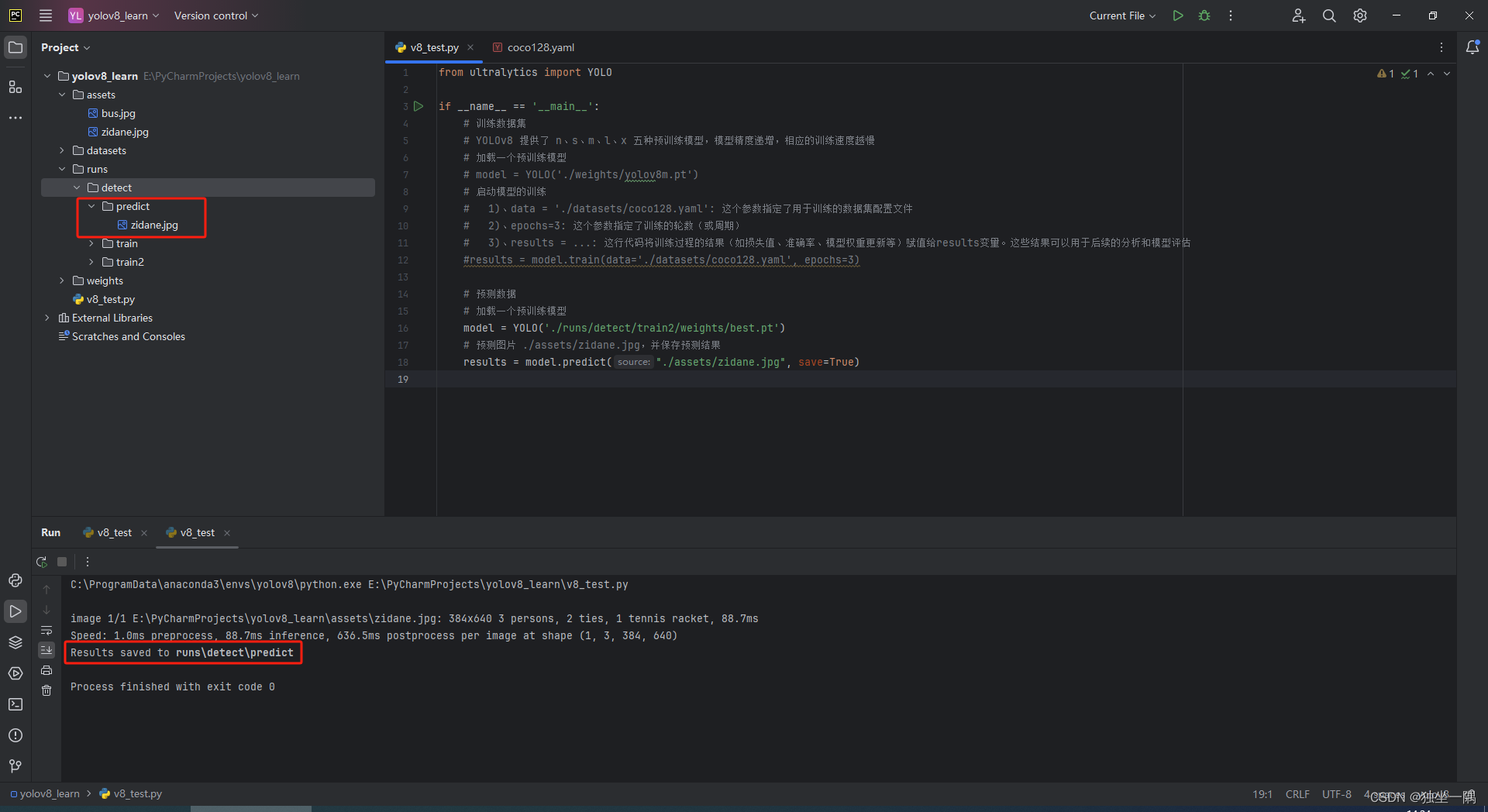
二、安装 LabelImg
2.1、下载安装 LabelImg,LabelImg 是一款开源的图片标注工具,使用 Python 编写并基于 PyQt5 框架。它提供了一个直观的图形用户界面,方便用户对图片进行标注,并生成标注结果。LabelImg 支持多种常见的标注格式,如 PASCAL VOC、YOLO等,适用于各种计算机视觉任务。我们之前安装了 Anaconda,这里就直接使用 Anaconda 进行 LabelImg 的安装。
2.2、在开始菜单中找到并打开 Anaconda 的命令行工具,Anaconda Powershell Prompt 或者 Anaconda Prompt 均可。
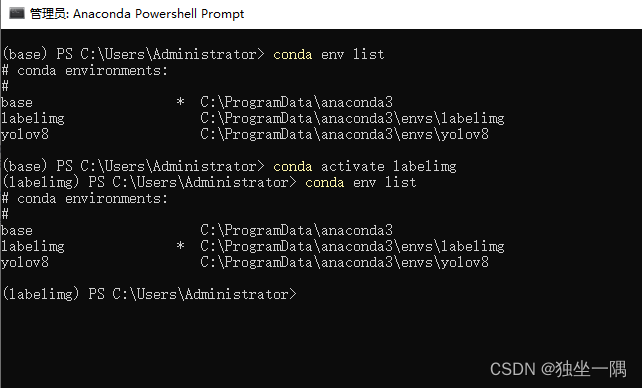
2.3、输入命令使用 python 3.9.16 创建 LabelImg 虚拟机环境。
conda create -n labelimg python=3.9.162.4、输入命令 conda activate labelimg 激活 LabelImg 虚拟机环境
2.5、输入命令 conda install labelimg 安装 LabelImg。
conda install labelimg2.6、如果没有安装成功,提示 PackagesNotFoundError: The following packages are not available from current channels时,通常意味着Anaconda的默认仓库中并没有包含LabelImg这个包,或者该包尚未被加入到你的当前通道中。可以尝试添加一些常用的社区维护的通道,比如conda-forge,这个通道包含了大量额外的包。使用以下命令添加conda-forge通道。
conda config --add channels conda-forge2.7、输入命令 labelimg 启动软件。
labelimg 2.7、将软件切换为标注 YOLO 数据,并设置自动保存(需要注意的是软件使用期间不要关闭 Anaconda 的命令行工具) 。
三、使用 LabelImg 标注数据
3.1、创建文件夹 mydata,在mydata 文件夹下分别创建 images 和 labels 两个文件夹。
3.2、分别在 images 和 labels 下创建 train 文件夹用于存放用于训练的图片文件和图片文件对应的标签。
3.3、将用于训练的图片放入 mydata/images/train 文件夹后,在 LabelImg 中点击 Open Dir 导入。

3.4、点击 Change Save Dir,修改存储路径为 mydata/images/train。

3.5、点击 Create RectBox,对图片进行标注。
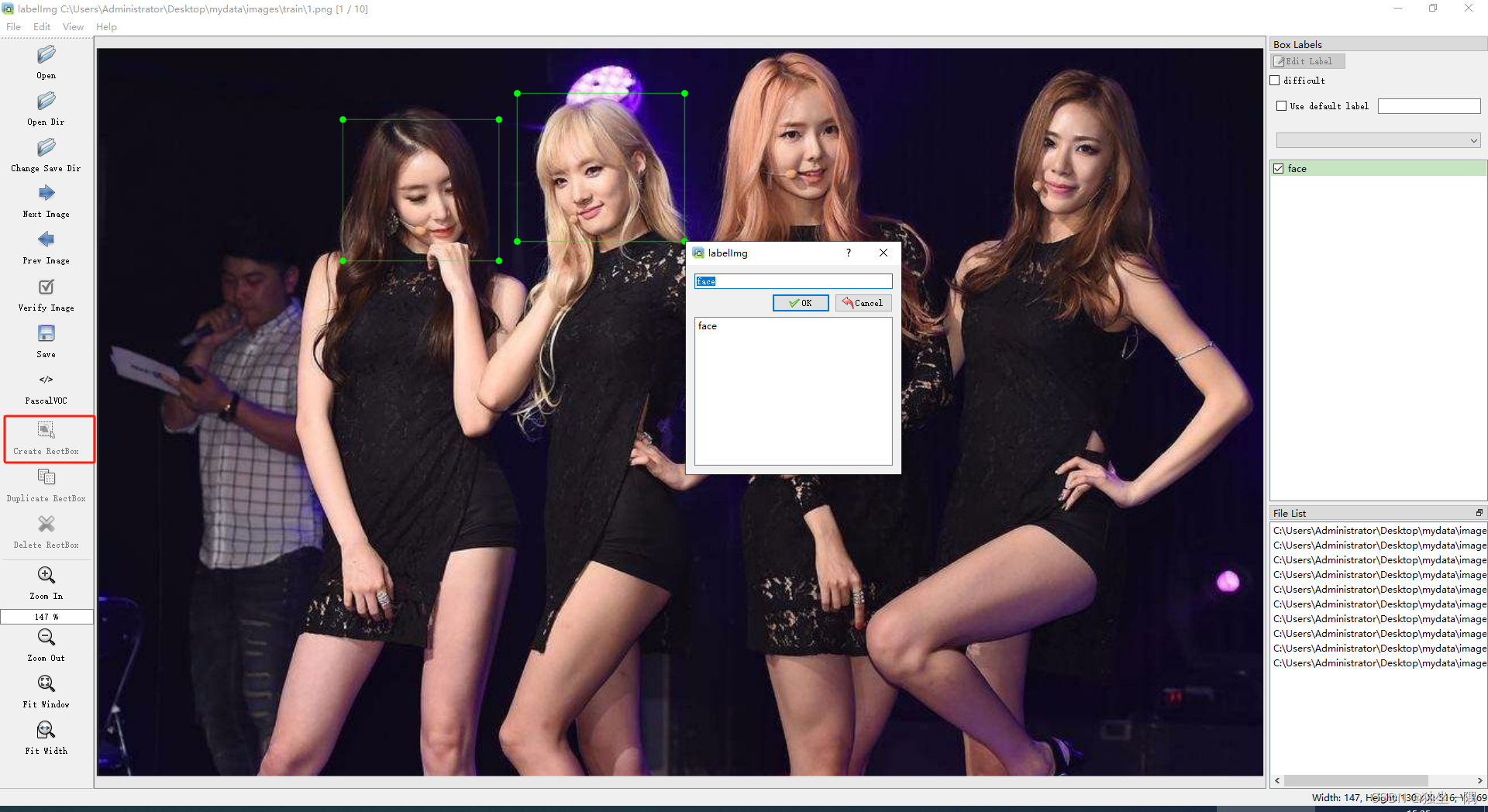
3.6、将标注好数据后的 mydata 文件夹移动至项目根目录下创建文件夹 datasets。
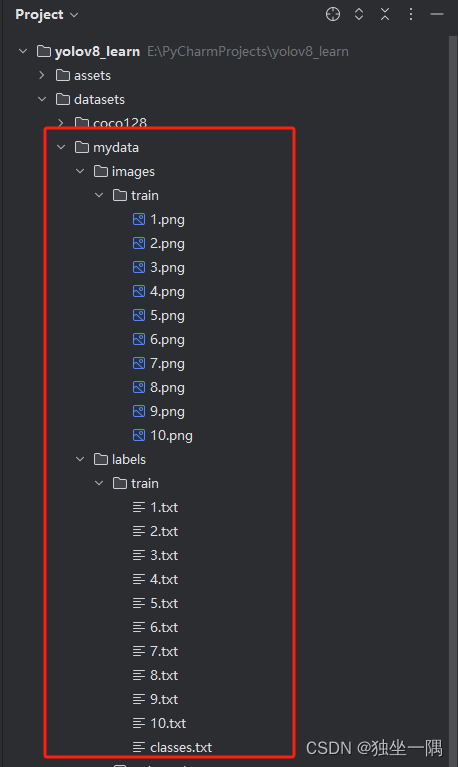
四、编写代码进行训练预测
4.1、参考 coco128.yaml 编写 mydata.yaml,类别在 datasets/mydata/labels/classes.txt 中。
# 数据集的根目录路径。
# 由于 YOLOv8 对目录做了默认的一些设置(第一次运行时的位置,而不是当前项目路径来查找),
# 虽然可以修改配置文件或者在代码中指定,但是我觉得在这边使用绝对路径更为方便一些。
path: E:/PyCharmProjects/yolov8_learn/datasets/mydata
# 训练图像位于 images/train,这是相对于 path 的相对路径
train: images/train
# 验证图像也位于 images/train,与训练图像使用相同的路径。
# 需要注意的是,通常训练集和验证集应该包含不同的图像,以确保模型验证的有效性。但在这里,它们使用了相同的图像,这在实际应用中可能不是最佳实践。
val: images/train
# 测试图像的路径,这是一个可选字段。
test:
# 类别
names:
0: face
1: leg4.2、参考 yolov8.yaml 文件修改出自己的模型配置文件 myyolo.yaml。
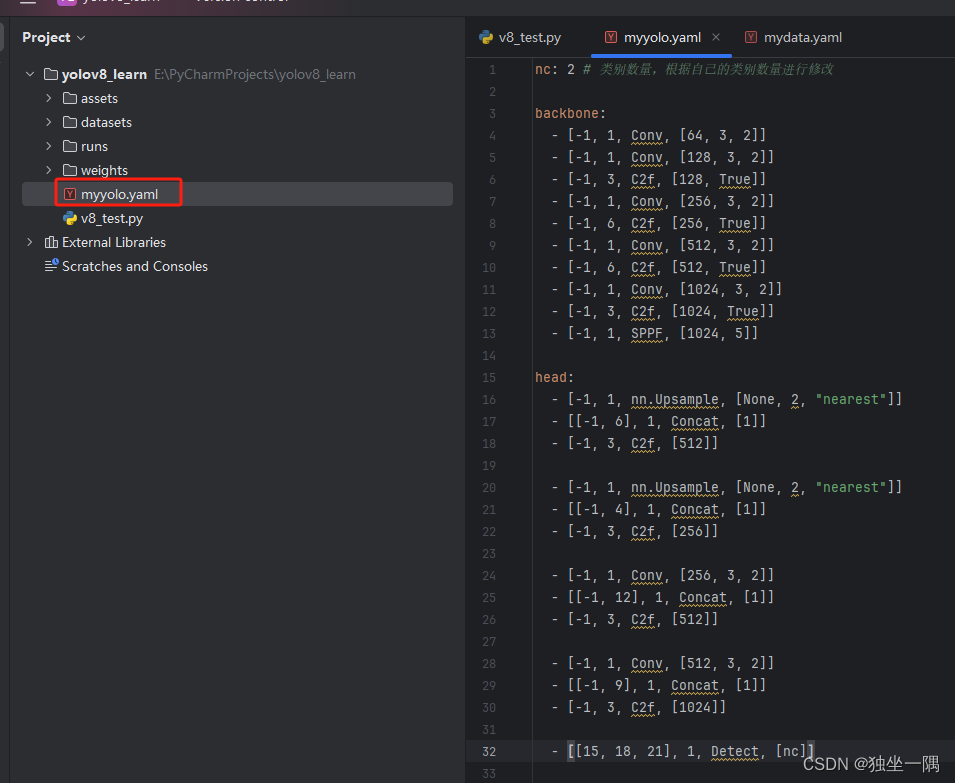
# 模型参数
nc: 2 # 类别数(nc),它指定了模型可以检测的不同对象的数量
scales: # 模型缩放常数(scales),用于调整模型的规模,实现不同复杂度的模型设计
# 深度(depth)、宽度(width)和最大通道数(max_channels)
# 这些缩放常数会应用到模型的骨架(backbone)和头部(head)结构中,从而得到不同复杂度和性能的模型。
# 这里定义了五个缩放级别:'n'(小型)、's'(标准型)、'm'(中型)、'l'(大型)和 'x'(特大型)
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs 解释如下
# 225 layers: 这表示YOLOv8n模型由225个层组成。这些层包括卷积层、池化层、激活函数层、特征融合层等,它们共同构成了模型的网络结构。
# 3157200 parameters: 这表示模型中总共有3157200个参数。参数是模型在训练过程中需要学习的变量,它们决定了模型从输入图像中提取特征和进行预测的方式。
# 参数的数量通常与模型的复杂度和性能相关,但并非绝对。更多的参数可能会使模型更强大,但也更容易导致过拟合。
# 3157184 gradients: 梯度是在训练过程中用于更新模型参数的值。这里提到的梯度数量与参数数量非常接近,这是因为在反向传播过程中,
# 通常会对每个参数计算一个梯度。这些梯度指示了如何调整参数以最小化训练损失。
# 8.9 GFLOPs: GFLOPs(Giga Floating Point Operations)是浮点运算次数的度量单位,用于衡量模型的计算复杂度。
# 8.9 GFLOPs表示模型进行一次前向传播(从输入到输出)大约需要执行8.9×10^9次浮点运算。这个数值可以帮助评估模型在推理(即预测新数据)时的计算需求,
# 以及在不同硬件上的运行效率。
# 模型的主干网络结构,它负责从输入图像中提取特征。
# 通常,骨架由一系列的卷积层、池化层和其他可能的模块组成,这些层通过下采样来逐渐提取不同尺度的特征。
# 这里使用了 Conv 和 C2f 模块,并指定了它们的参数。
# 每个条目都包含了一个列表,表示了模块的类型、参数以及该模块应用于的层。
# 例如,[-1, 1, Conv, [64, 3, 2]] 表示在上一层(由 -1 指示)之后添加一个卷积层,该卷积层有 64 个输出通道,卷积核大小为 3,步长为 2
backbone:
# [from, repeats, module, args]
# from 指示该层或模块是从哪个先前的层或模块获取的输入。这通常是一个索引值,其中 -1 表示前一个层,-2 表示前两个层,依此类推。这允许模型配置中的层引用前面的层作为输入。
# repeats 表示该层或模块应该重复的次数。这允许你定义重复的层结构,这对于创建深度网络结构特别有用。
# module 定义了要使用的层或模块的类型。这可以是一个预定义的层类型(如 Conv 表示卷积层),或者是一个自定义的模块(如 C2f,它可能是某种特定的卷积和特征融合模块的组合)。
# args 是一个列表,包含了传递给 module 的参数。这些参数具体取决于所使用的层或模块类型。例如,对于卷积层,参数可能包括输出通道数、卷积核大小和步长等。
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# 从主干网络提取的特征中检测对象。它可能包括上采样层、特征融合模块以及最终的检测层。多尺度检测是 YOLO 系列模型的一个特点,通过在多个尺度上检测对象,模型可以更好地处理不同大小的对象。
# 这里定义了多个上采样层、连接层(Concat)和检测层(Detect)。上采样层用于增加特征图的尺寸,连接层用于将不同尺度的特征图合并在一起,而检测层则负责在合并后的特征图上检测对象。
# Detect 层接受多个输入(在这里是 P3、P4 和 P5 三个尺度的特征图),并输出每个尺度的检测结果。每个检测结果都包含了边界框的坐标、置信度和类别得分。
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
4.3、编写代码,启动训练。我们通过参考 yolov8.yaml 文件修改出自己的模型配置文件 myyolo.yaml,可以调整模型的配置以适应特定的任务和数据集。然而,对于大多数用户来说,直接使用预定义的配置文件(如 yolov8n.yaml、yolov8s.yaml 等)作为起点,并根据需要进行微调可能更为简单和有效。
from ultralytics import YOLO
if __name__ == '__main__':
# 创建一个新的 YOLO 模型
# model = YOLO('yolov8n.yaml')
model = YOLO('myyolo.yaml')
# 启动模型的训练
# 1)、data = './datasets/coco128.yaml': 这个参数指定了用于训练的数据集配置文件
# 2)、epochs=3: 这个参数指定了训练的轮数(或周期)
# 3)、results = ...: 这行代码将训练过程的结果(如损失值、准确率、模型权重更新等)赋值给results变量。这些结果可以用于后续的分析和模型评估
results = model.train(data='./datasets/mydata.yaml', epochs=3)
4.4、训练后的结果将保存到 runs 目录下。
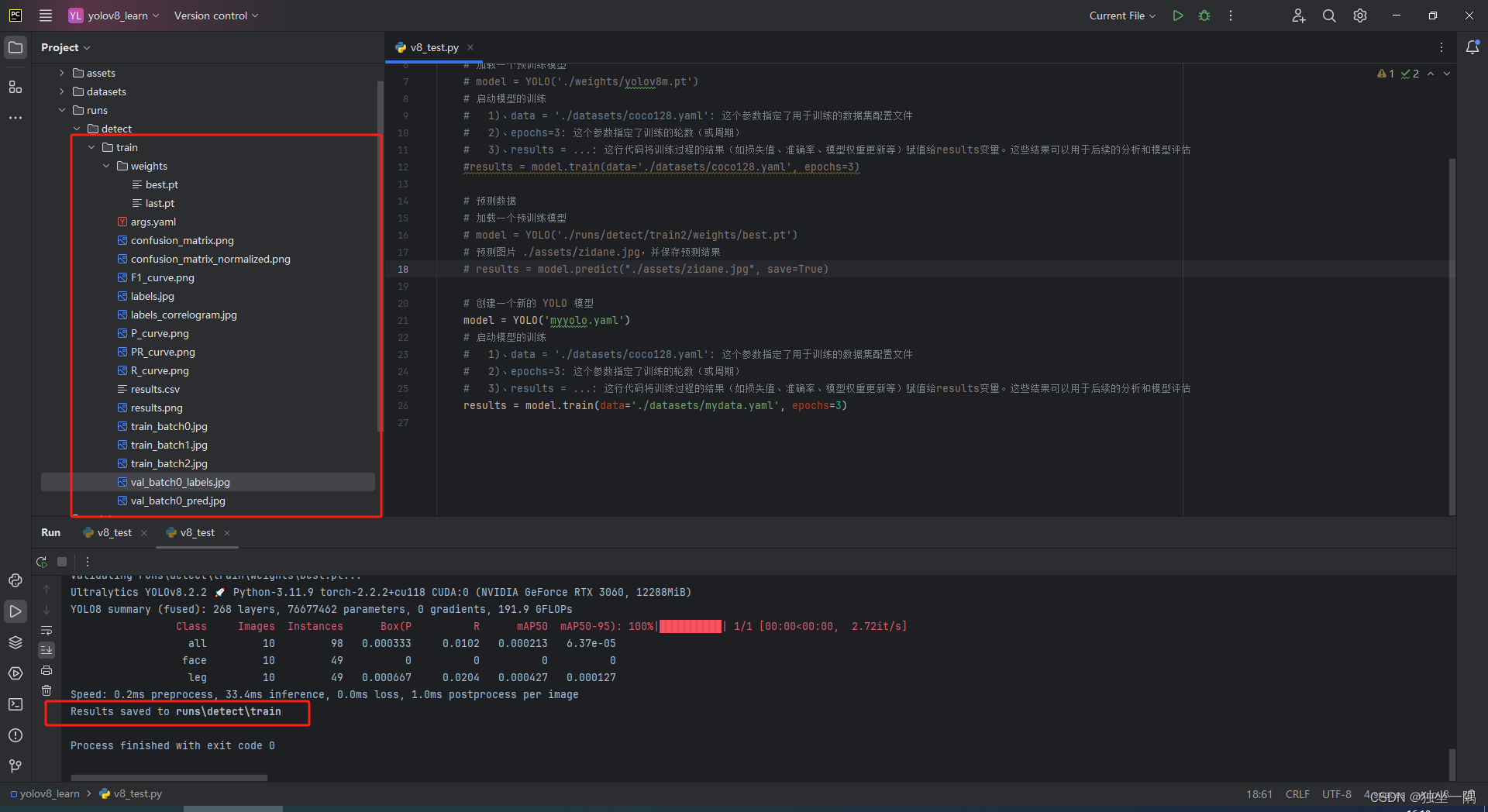
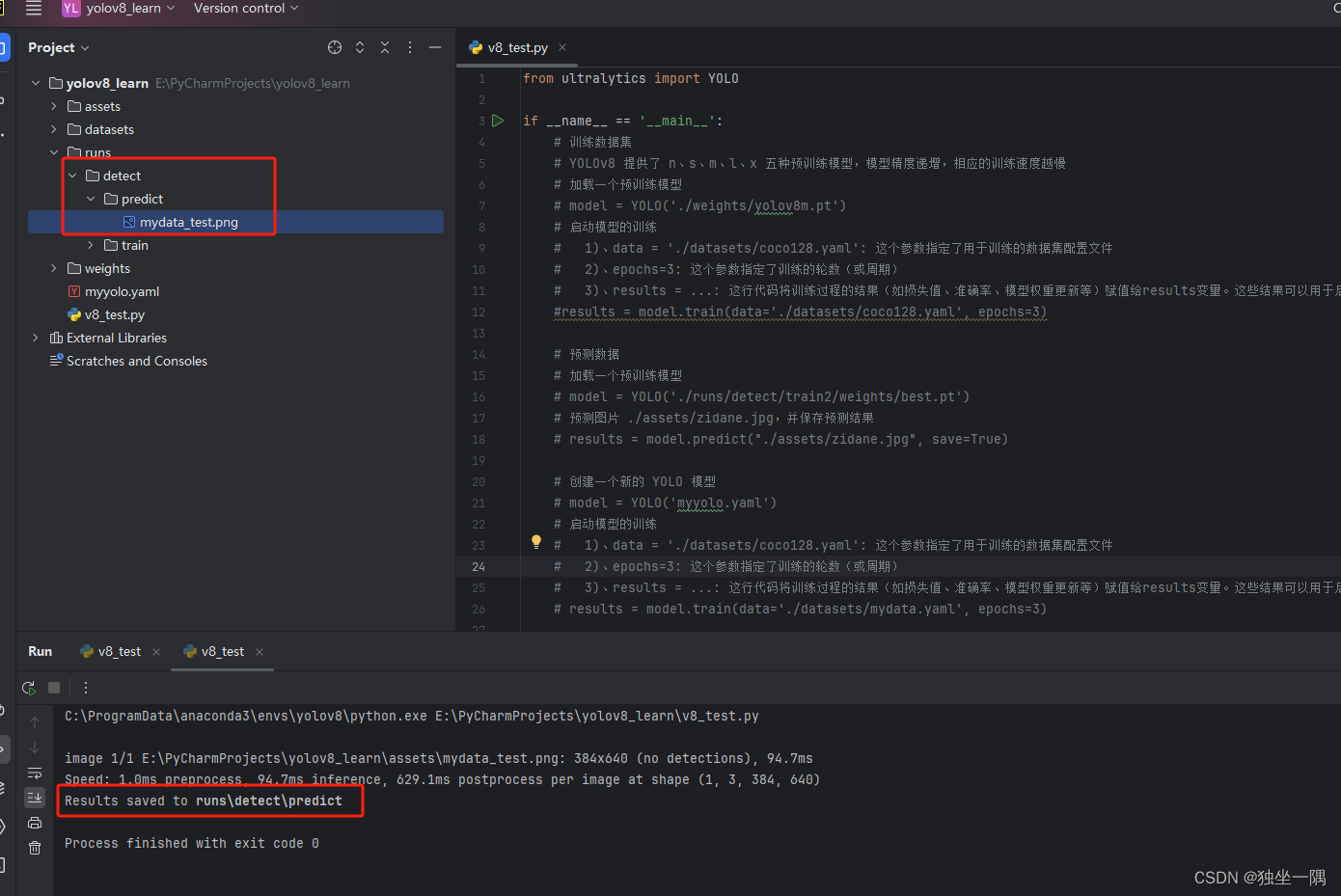
4.5、编写代码,启动预测。不过这次我们不用 YOLOv8 的模型,使用之前训练后得到的最好的一次结果模型。
from ultralytics import YOLO
if __name__ == '__main__':
# 预测数据
# 加载一个预训练模型
model = YOLO('./runs/detect/train/weights/best.pt')
# 预测图片 ./assets/zidane.jpg,并保存预测结果
results = model.predict("./assets/mydata_test.png", save=True)4.6、预测后的结果将保存到 runs 目录下。