NLP方面知识
- 一 基础
- 1.Tokenizer
- 1.1 分词粒度:
- 1.2 大模型的分词粒度
- 1.3 各路语言模型中的tokenizer
- 2.Embedding layer
- 2.1 理解Embedding矩阵
一 基础
1.Tokenizer
tokenizer总体上做三件事情:
分词。tokenizer将字符串分为一些sub-word token string,再将token string映射到id,并保留来回映射的mapping。从string映射到id为tokenizer encode过程,从id映射回token为tokenizer decode过程。映射方法有多种,例如BERT用的是WordPiece,GPT-2和RoBERTa用的是BPE等等,后面会详细介绍。
扩展词汇表。部分tokenizer会用一种统一的方法将训练语料出现的且词汇表中本来没有的token加入词汇表。对于不支持的tokenizer,用户也可以手动添加。
识别并处理特殊token。特殊token包括[MASK], <|im_start|>等等。tokenizer会将它们加入词汇表中,并且保证它们在模型中不被切成sub-word,而是完整保留。
1.1 分词粒度:
单词分词法将一个word作为最小元,也就是根据空格或者标点分词;
单字分词法(character-base)。单字分词法会穷举所有出现的字符,所以是最完整的;
子词分词法,会把上面的句子分成最小可分的子词[‘To’, ‘day’, ‘is’, ‘S’, ‘un’, ‘day’]
1.2 大模型的分词粒度
GPT族:Byte-Pair Encoding (BPE)
1. 统计输入中所有出现的单词并在每个单词后加一个单词结束符</w> -> ['hello</w>': 6, 'world</w>': 8, 'peace</w>': 2]
2. 将所有单词拆成单字 -> {'h': 6, 'e': 10, 'l': 20, 'o': 14, 'w': 8, 'r': 8, 'd': 8, 'p': 2, 'a': 2, 'c': 2, '</w>': 3}
3. 合并最频繁出现的单字(l, o) -> {'h': 6, 'e': 10, 'lo': 14, 'l': 6, 'w': 8, 'r': 8, 'd': 8, 'p': 2, 'a': 2, 'c': 2, '</w>': 3}
4. 合并最频繁出现的单字(lo, e) -> {'h': 6, 'lo': 4, 'loe': 10, 'l': 6, 'w': 8, 'r': 8, 'd': 8, 'p': 2, 'a': 2, 'c': 2, '</w>': 3}
5. 反复迭代直到满足停止条件
显然,这是一种贪婪的算法。在上面的例子中,'loe’这样的子词貌似不会经常出现,但是当语料库很大的时候,诸如est,ist,sion,tion这样的特征会很清晰地显示出来,在获得子词词表后,就可以将句子分割成子词了。
BERT族:Word-Piece
Word-Piece和BPE非常相似,BPE使用出现最频繁的组合构造子词词表,而Wordpiece使用出现概率最大的组合构造子词词表。换句话说,WordPiece每次选择合并的两个子词,通常在语料中以相邻方式同时出现。比如说 P(ed) 的概率比P(e) + P(d)单独出现的概率更大(可能比他们具有最大的互信息值),也就是两个子词在语言模型上具有较强的关联性。这个时候,Word-Piece会将它们组合成一个子词。
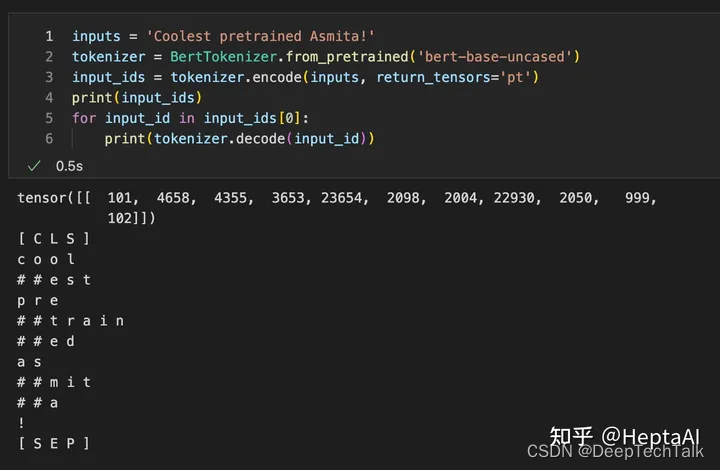
发现BERT在句首加上了[CLS],句尾加上了[SEP],而且对coolest做了子词分解,对词根est加上了##来表示这是一个后缀。对于没有出现在词汇表里的单词例如asmita(是个印度人名),BERT所用的Word-Piece tokenizer会将它分解为Word-Piece算法形成的子词词汇表中存在的as,mit和a,组成一个子词。
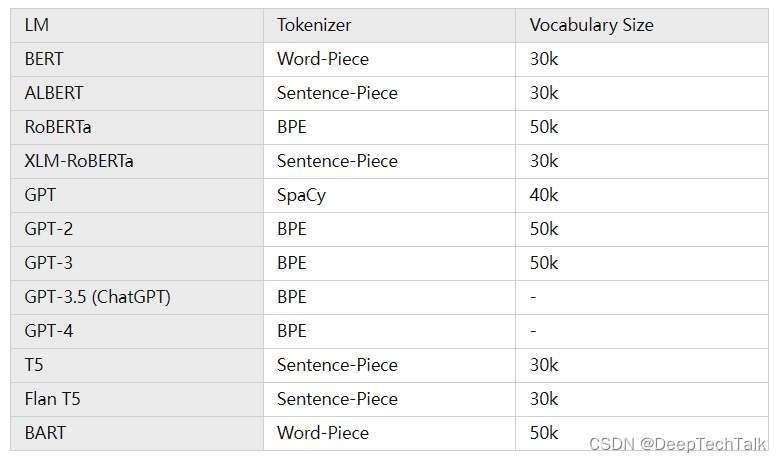
1.3 各路语言模型中的tokenizer
2.Embedding layer
tokenize完的下一步就是进行embedding编码:将token的one-hot编码转换成更dense的编码形式。
首先,一般的Embedding模型是这样调用的:
input_ids = tokenizer.encode('Hello World!', return_tensors='pt')
output = model.generate(input_ids, max_length=50)
tokenizer.decode(output[0])
上面的代码主要涉及三个操作:tokenizer将输入encode成数字输入给模型,模型generate出输出数字输入给tokenizer,tokenizer将输出数字decode成token并返回。
举一个例子,以T5TokenizerFast为例:
1.tokenizer会将token序列 [‘Hello’, ‘World’, ‘!’] 编码成数字序列[8774, 1150, 55, 1],也就是[‘Hello’, ‘World’, ‘!’, ‘’],然后在句尾加一个表示句子结束。
**2.**这四个数字会变成四个one-hot向量,例如8774会变成[0, 0, …, 1, 0, 0…, 0, 0],其中向量的index为8774的位置为1,其他位置全部为0。假设词表里面一共有30k个可能出现的token,则向量长度也是30k,这样才能保证出现的每个单词都能被one-hot向量表示。
**3.**也就是说,一个形状为 (4)的输入序列向量,会变成形状为 (4,30k) 的输入one-hot向量。为了将每个单词转换为一个word embedding,每个向量都需要被被送到embedding层进行dense降维。
**4.**现在思考一下,多大的矩阵可以满足这个要求?没错,假设embedding size为768,则矩阵的形状应该为 (30k,768),与BERT的实现一致
2.1 理解Embedding矩阵
Embedding矩阵的本质就是一个查找表。由于输入向量是one-hot的,embedding矩阵中有且仅有一行被激活。行间互不干扰。这是什么意思呢?如下图所示,假设词汇表一共有6个词,则one-hot表示的长度为6。现在我们有三个单词组成一个句子,则输入矩阵的形状为 (3,6) 。然后我们学出来一个embedding矩阵,根据上面的推导,如果我们的embedding size为4,则embedding矩阵的形状应该为 (6,4) 。这样乘出来的输出矩阵的形状应为 (3,4)。

我在图中用不同颜色标明了三个subword embedding分别的计算过程。对于第一个单词’I’,假设其one-hot编码为 [0,0,1,0,0,0],将其与embedding矩阵相乘,相当于取出embedding矩阵的第3行(index为2)。同理,对于单词’love’,相当于取出embedding矩阵的第二行(index为1)。这样一来大家就理解了,embedding矩阵的本质是一个查找表,每个单词会定位这个表中的某一行,而这一行就是这个单词学习到的在嵌入空间的语义。