1、概述
在kubernetes中,有很多类型的pod控制器,每种都有自己的适合的场景,常见的有下面这些:
-
ReplicationController:比较原始的pod控制器,已经被废弃,由ReplicaSet替代
-
ReplicaSet:保证副本数量一直维持在期望值,并支持pod数量扩缩容,镜像版本升级
-
Deployment:通过控制ReplicaSet来控制Pod,并支持滚动升级、回退版本
-
Horizontal Pod Autoscaler:可以根据集群负载自动水平调整Pod的数量,实现削峰填谷
-
DaemonSet:在集群中的指定Node上运行且仅运行一个副本,一般用于守护进程类的任务
-
Job:它创建出来的pod只要完成任务就立即退出,不需要重启或重建,用于执行一次性任务
-
Cronjob:它创建的Pod负责周期性任务控制,不需要持续后台运行
-
StatefulSet:管理有状态应用
在前面文章中我们详解了ReplicaSet、Deployment控制器,这篇我们详解Horizontal Pod Autoscaler控制器
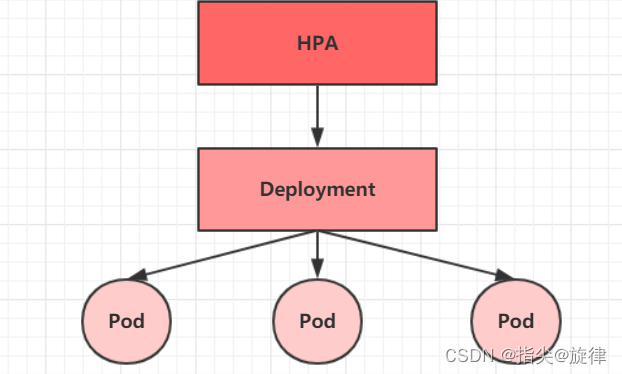
2、Horizontal Pod Autoscaler(HPA)控制器详解
在前面的文章中,我们已经可以实现通过手工执行kubectl scale命令实现Pod扩容或缩容,但是这显然不符合Kubernetes的定位目标--自动化、智能化。 Kubernetes期望可以实现通过监测Pod的使用情况,实现pod数量的自动调整,于是就产生了Horizontal Pod Autoscaler(HPA)这种控制器。
HPA可以获取每个Pod利用率,然后和HPA中定义的指标进行对比,同时计算出需要伸缩的具体值,最后实现Pod的数量的调整。其实HPA与之前的Deployment一样,也属于一种Kubernetes资源对象,它通过追踪分析RC控制的所有目标Pod的负载变化情况,来确定是否需要针对性地调整目标Pod的副本数,这是HPA的实现原理。
3、 Horizontal Pod Autoscaler(HPA)实例操作
为了达到自动扩缩容的目的,我们需要清楚的知道每个pod、node使用资源情况,这个时候就需要安装metrics-server,如果不会安装,请看这篇文章:https://blog.csdn.net/u011837804/article/details/128487211
metrics-server安装后效果
# 查看k8s集群 所有节点资源使用情况
[root@k8s-master ~]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master 425m 5% 2787Mi 17%
k8s-node1 100m 2% 4488Mi 59%
k8s-node2 799m 9% 21492Mi 33%
[root@k8s-master ~]#
[root@k8s-master ~]#
# 查看pod 资源使用情况
[root@k8s-master ~]# kubectl top pod -n kube-system
NAME CPU(cores) MEMORY(bytes)
calico-kube-controllers-59697b644f-bqhsg 5m 33Mi
calico-node-6x9rq 20m 107Mi
calico-node-9npwl 16m 180Mi
calico-node-s9g7k 47m 159Mi
coredns-c676cc86f-n4nj8 3m 21Mi
coredns-c676cc86f-rhvwg 3m 18Mi
etcd-k8s-master 43m 321Mi
kube-apiserver-k8s-master 77m 350Mi
kube-controller-manager-k8s-master 30m 57Mi
kube-proxy-62sbc 1m 26Mi
kube-proxy-qq58v 1m 34Mi
kube-proxy-w6p29 1m 20Mi
kube-scheduler-k8s-master 6m 24Mi
metrics-server-f68c598fc-vt4pz 2m 19Mi
[root@k8s-master ~]#3.1、创建deploy并限制pod资源使用上限
创建pc-hpa-pod.yaml文件,内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: dev
spec:
strategy: # 策略
type: RollingUpdate # 滚动更新策略
replicas: 1
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
resources: # 资源配额
limits: # 限制资源(上限)
cpu: "1" # CPU限制,单位是core数
requests: # 请求资源(下限)
cpu: "100m" # CPU限制,单位是core数# 创建deployment
[root@k8s-master01 1.8+]# kubectl run nginx --image=nginx:1.17.1 --requests=cpu=100m -n dev
# 创建service
[root@k8s-master01 1.8+]# kubectl expose deployment nginx --type=NodePort --port=80 -n dev
# 查看
[root@k8s-master01 1.8+]# kubectl get deployment,pod,svc -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx 1/1 1 1 47s
NAME READY STATUS RESTARTS AGE
pod/nginx-7df9756ccc-bh8dr 1/1 Running 0 47s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/nginx NodePort 10.101.18.29 <none> 80:31830/TCP 35s3.2、部署HPA
创建pc-hpa.yaml文件,内容如下:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: pc-hpa
namespace: dev
spec:
minReplicas: 1 #最小pod数量
maxReplicas: 10 #最大pod数量
targetCPUUtilizationPercentage: 3 # CPU使用率指标
scaleTargetRef: # 指定要控制的nginx信息
apiVersion: /v1
kind: Deployment
name: nginx# 创建hpa
[root@k8s-master01 1.8+]# kubectl create -f pc-hpa.yaml
horizontalpodautoscaler.autoscaling/pc-hpa created
# 查看hpa
[root@k8s-master01 1.8+]# kubectl get hpa -n dev
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
pc-hpa Deployment/nginx 0%/3% 1 10 1 62s3.3、测试
使用压测工具对service地址192.168.5.4:31830进行压测,然后通过控制台查看hpa和pod的变化
hpa变化
[root@k8s-master01 ~]# kubectl get hpa -n dev -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
pc-hpa Deployment/nginx 0%/3% 1 10 1 4m11s
pc-hpa Deployment/nginx 0%/3% 1 10 1 5m19s
pc-hpa Deployment/nginx 22%/3% 1 10 1 6m50s
pc-hpa Deployment/nginx 22%/3% 1 10 4 7m5s
pc-hpa Deployment/nginx 22%/3% 1 10 8 7m21s
pc-hpa Deployment/nginx 6%/3% 1 10 8 7m51s
pc-hpa Deployment/nginx 0%/3% 1 10 8 9m6s
pc-hpa Deployment/nginx 0%/3% 1 10 8 13m
pc-hpa Deployment/nginx 0%/3% 1 10 1 14mdeployment变化
[root@k8s-master01 ~]# kubectl get deployment -n dev -w
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 11m
nginx 1/4 1 1 13m
nginx 1/4 1 1 13m
nginx 1/4 1 1 13m
nginx 1/4 4 1 13m
nginx 1/8 4 1 14m
nginx 1/8 4 1 14m
nginx 1/8 4 1 14m
nginx 1/8 8 1 14m
nginx 2/8 8 2 14m
nginx 3/8 8 3 14m
nginx 4/8 8 4 14m
nginx 5/8 8 5 14m
nginx 6/8 8 6 14m
nginx 7/8 8 7 14m
nginx 8/8 8 8 15m
nginx 8/1 8 8 20m
nginx 8/1 8 8 20m
nginx 1/1 1 1 20mpod变化
[root@k8s-master01 ~]# kubectl get pods -n dev -w
NAME READY STATUS RESTARTS AGE
nginx-7df9756ccc-bh8dr 1/1 Running 0 11m
nginx-7df9756ccc-cpgrv 0/1 Pending 0 0s
nginx-7df9756ccc-8zhwk 0/1 Pending 0 0s
nginx-7df9756ccc-rr9bn 0/1 Pending 0 0s
nginx-7df9756ccc-cpgrv 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-8zhwk 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-rr9bn 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-m9gsj 0/1 Pending 0 0s
nginx-7df9756ccc-g56qb 0/1 Pending 0 0s
nginx-7df9756ccc-sl9c6 0/1 Pending 0 0s
nginx-7df9756ccc-fgst7 0/1 Pending 0 0s
nginx-7df9756ccc-g56qb 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-m9gsj 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-sl9c6 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-fgst7 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-8zhwk 1/1 Running 0 19s
nginx-7df9756ccc-rr9bn 1/1 Running 0 30s
nginx-7df9756ccc-m9gsj 1/1 Running 0 21s
nginx-7df9756ccc-cpgrv 1/1 Running 0 47s
nginx-7df9756ccc-sl9c6 1/1 Running 0 33s
nginx-7df9756ccc-g56qb 1/1 Running 0 48s
nginx-7df9756ccc-fgst7 1/1 Running 0 66s
nginx-7df9756ccc-fgst7 1/1 Terminating 0 6m50s
nginx-7df9756ccc-8zhwk 1/1 Terminating 0 7m5s
nginx-7df9756ccc-cpgrv 1/1 Terminating 0 7m5s
nginx-7df9756ccc-g56qb 1/1 Terminating 0 6m50s
nginx-7df9756ccc-rr9bn 1/1 Terminating 0 7m5s
nginx-7df9756ccc-m9gsj 1/1 Terminating 0 6m50s
nginx-7df9756ccc-sl9c6 1/1 Terminating 0 6m50s