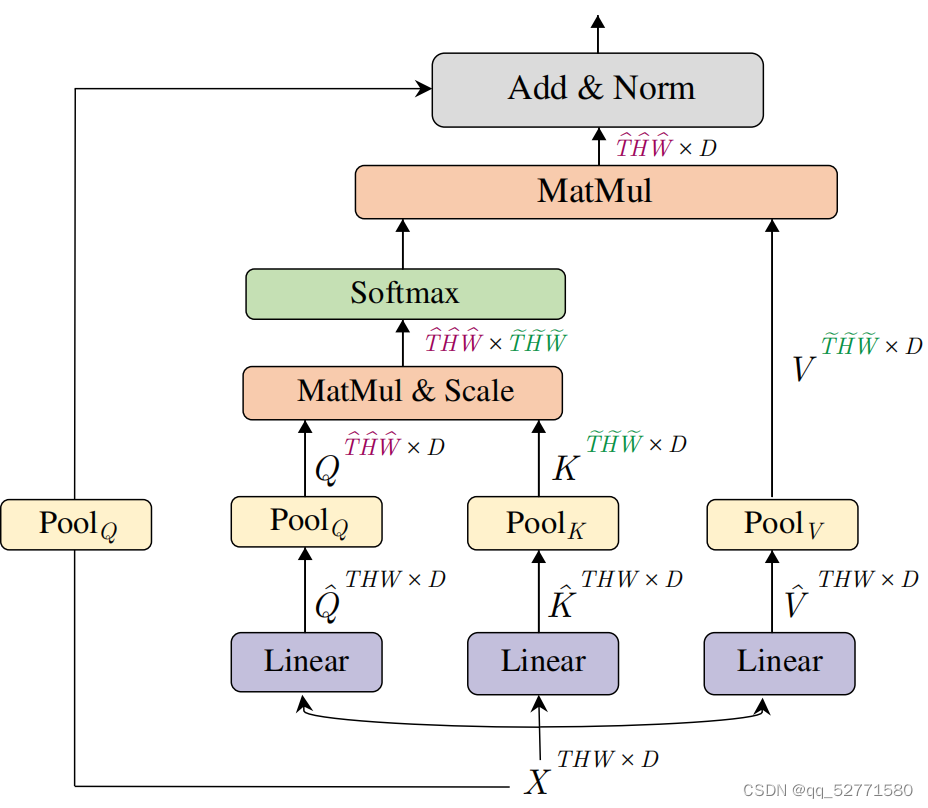
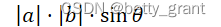为方便大家理解YOLO的原理,这里将YOLOv1的部分内容基础内容进行用比较直白的话和例子进行阐述,为后续大家学习YOLO作为铺垫。
1、模型所干的活
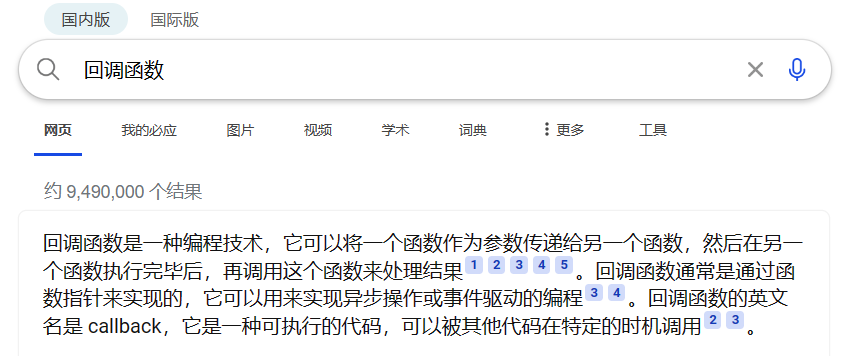
工作中,大家经常将 Word 文档 上传到某转换器,然后转换输出为PDF文档。目标检测中我们想做的事也类似,就是输入一张图,输出一张带有框(标注对应的物体)的图片 。如下图所示:

问题:这个框是如何还出来的呢?通过模型画出来的,这模型就相当于 word到pdf的转换器。 如下图:

进一步理解,需要不断调试,不断计算损失,看看在哪个位置画框最合适。
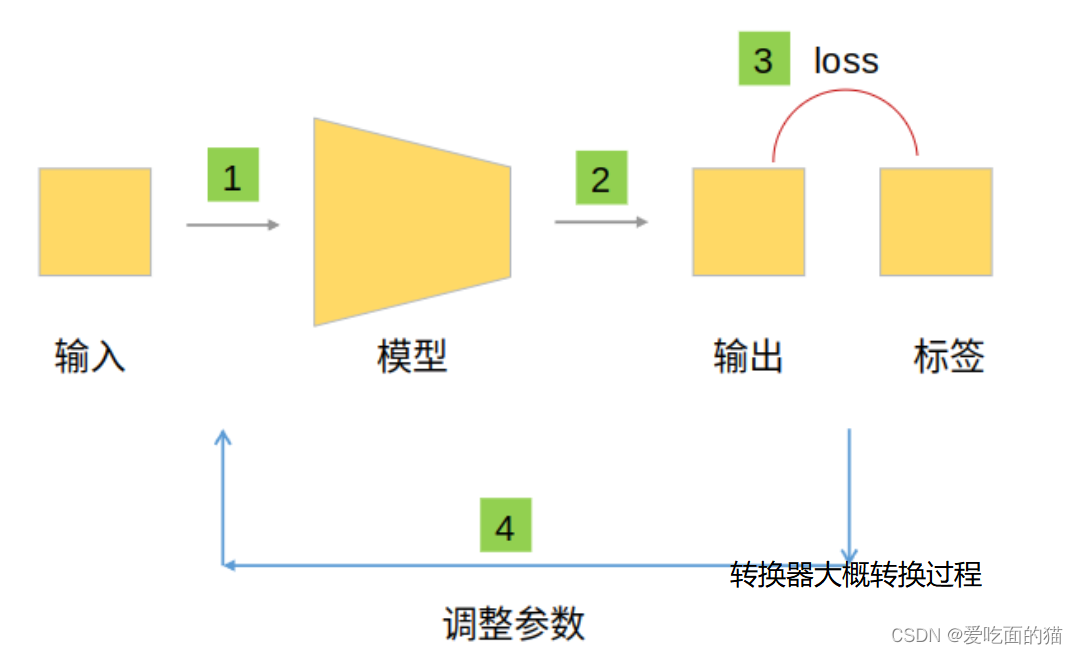
这个模型其实就是经常所说的网络的模型。如下图:

2、相关概念
在网络中,一切都是以数据形式存在的,更具体是以“数组”的形式存在。
在目标检测学习过程中,我们提到“物体”落在某个“格子”中 ,就由那个格子负责,这里的物体指的是什么,格子指的又是什么?
下图是算是“经典”示例图了,
当我们看到图中物体“狗”时,我们说的时“狗这个区域”如何如何,是为了便于直观的理解。但是反映在程序中,这张图片是一个多维数组(三维,长度、宽度和通道),所以在程序中,狗这个区域是用三维数组中的数值体现的。而这里所说的区域,是另一类任务即分割。

在目标检测中,我们谈“物体”又是什么呢?就是目标框,如下图所示,我们说到物体,本质还在说这个框,因为我们需要的也正是这个框。而这个框反映在程序中,是这框的四个顶点(坐标),在程序中我们由四个顶点也就确定了这个框。或者用这个框的另一种表示: (x, y, w, h),x和y表示这个框的中心点坐标,w和h表示图片的宽高。
所以,当我们谈物体的时候,是在谈框(包围物体的框即包围框),换句话说就是在谈四个顶点,**(x, y, w, h)**

当我们提到“格子”的时候,先了解一下下面内容。假设下面的图片是我们用来训练的图片,即图片已经提前人工进行标记好中心点和图片宽高,人工标记好的图片中心点是(85,176),宽高是(115,232),我们的图片大小是256*256,即像素点是25*256个像素点。
现在将每个像素点作为一个中心点画一个框,然后让这个中心点所在的框和人工标记的中心点所在的框进行计算,判断是不是人工标记的中心点所在的框,因此需要遍历并计算和判断256*256次。目前我们判断的只是一个物体(即人工标记的中心点所在的框)就需要256*256次。

刚刚我们判断的只是一个物体(即人工标记的中心点所在的框),而实际过程中则一个图片中可能有多个物体(即人工标记的中心点所在的框),如下图所示,有3个物体(即人工标记的中心点所在的框),我们就需要3*256*256次。如果有n个物体,则需要判断 n*256*256。
此时我们是 为每个像素点画一个框,就这么多的计算,如果每个像素点画多个框(假如是3个框,则需要3*3*256*256),计算量会直线上升。同时在实际中图片往往会更大,如2560*1440,此时计算量非常庞大。

上面这种方式,就类似于我们在成都内找一个人一样,一个坐标一个坐标的找,花费的时间就很多。
为减少找人时间,我们可以将成都按区划分,例如高新区、开发区、武侯区、青羊区、锦江区、温江区、金堂县、双流区、金牛区、成华区等不同区,通过这个区,也就知道一个人的大概位置了。
同理,为了减少计算量,我们将图片进行分区,我们将图片分成 7*7=49个区。这些区就是我们所说的格子。我们将每个格子做为一个中心点画框,然后再和人工标记好的图片中心点(85,176)所在的格子所在的框进行计算,因此需要遍历并计算和判断7*7,如果是多个物体 n,则需要遍历n*7*7次。

3、数据的表示方式
前面提到在网络中,一切都是以数据形式存在的,更具体是以“数组”的形式存在。
那么 “狗” 即中心点所在的框如何用数据表示呢?
在YOLO的论文中,作者将分类分为了20类,例如人、猫、狗、车、自行车等等,并且为每个分类给一个标记分别记作1、2、3、4、5......20,如下面所示:
| 人 | 猫 | 狗 | 车 | 自行车 | .... | .. |
| 1 | 2 | 3 | 4 | 5 | 20 |
对于上图的狗,我们知道狗即中心点所在的框“落”在其中一个格子(区域)中,那么我们这里也就确定了狗在哪了。比如下图,我们给狗所在的格子赋值为它的类别3,也就是说狗和3这个值一一对应,其他物体再赋一个别的值,自然实现了区分。(为什么要赋值?因为在程序中一切都是数据,我们用3表示狗,回头预测的时候,在把3还原成“狗”这个汉字,也就好了)
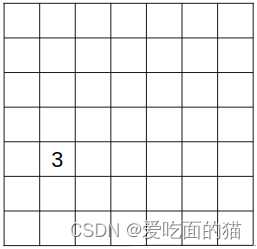
那么狗(中心点)所在的格子我们如何用数据表示呢?
我们用长度为20的向量表示类别,而狗即中心点所在的框是人为标记的,表示属于狗这个类别,那么在狗所在的类别3的位置上记作为1,其他记0,即物体类别的one-hot编码,如下图中的蓝色部分。同时增加中心点坐标和宽高以及置信度p(表示这个是狗的概率)五个数据。
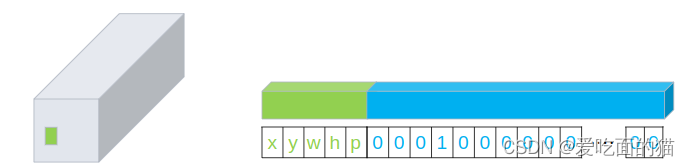
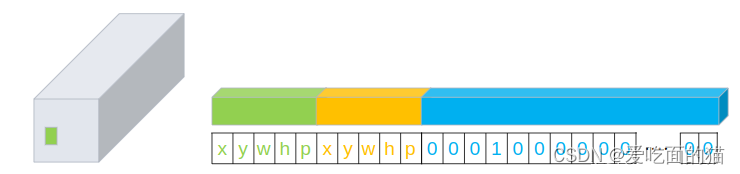
因此狗(即中心点所在的框)的数据,可以用上图方式表示,向量长度为25。 在论文中,作者会预测两个框(即2个中心点),每个框和真值计算IoU,结果大的代表我们预测的物体。两个框的数据长度是30,形式如下:
4、损失函数
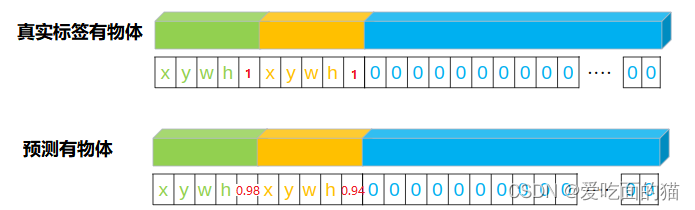
现在我们知道了目标图片即人工标记的图片和标签所对应的形式(x,y,w,h,p,x,y,w,h,p,0,0,1,0,....,0),假如下图中标签的真实值是:(85,176,232,115,1,84,172,230,156,1,0,0,1,0,....,0),此处的红色 1 表示有物体,如果是0表示无物体。
现在我们把需要检测的图片输入给模型,模型则会输出预测的值,蓝色和绿色分别代表两个预测的框:(84,175,234,116,0.98,83,173,231,154,0.94,0,0,1,0,....,0),此处的0.98和0.94表示的是两个框有物体(即包含中心点所在的格子)的概率。
我们用这个预测值和真实值进行计算点坐标的差距(损失),长宽差距(损失),还有预测的概率,以及类型的差距(损失)。

对于标签,我们将数据组织如下形式,没有物体,所有值为0,有物体值为对应的值。如下图所示 :

对于有物体来说,我们需要计算中心点坐标的差距(损失),长宽差距(损失),还有预测的概率,以及类型的差距(损失)。
我们这里的计算单元是格子,即每个格子中是否物体。作者论文中将图片划分成S×S的格子,S为7。因为格子分为有物体(即格子中有目标值的中心点)和没有物体两种情况,所以损失也分为两种情况。
一张图片一般含有少数的物体。如上图的狗图片,含有狗、自行车、汽车三种物体。而我们的格子有49个。所以对于有物体和没有物体损失的权重是不一样的。没有物体设置一个小的权重,有物体设置一个大一点的权重。如图:

格子有物体的损失
有物体的损失需要将坐标损失、长宽损失、置信度损失、类别损失四项相加:

格子没有物体的损失
没有物体我们只需要计算置信度损失即可。

5、数据处理
通过前面的讲解,我们大概知道了整体的思路和相关概念,那么我们你在训练模型的时候,为了方便数据计算,常将数据进行归一化。
图片对应的数据归一化:我们可以简单粗暴的将值除以255,缩放到0-1之间。
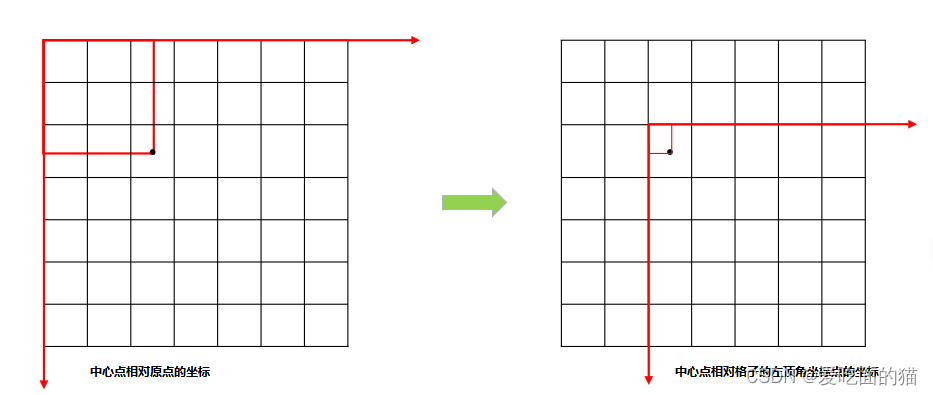
标签归一化:对于类别,我们采用one-hot编码归一化,对于置信度(或者说概率)采用0或1归一化,物体(中心点所在框)的x,y,w,h中,w,h除以图片的长宽即可。对于x,y同样可以除以图片的长宽。但是一般采取更巧妙的办法即局部坐标变换与缩放:原始的xy是相对于原点(图片左上角),我们将其变换到相对于所在格子的左上角(可以理解为坐标变换),然后除以格子的长宽即可。
6、部分说明


这里的p只是一个数字的表示,例如在在人工标记阶段,p=1包含物体,或p=0不包含物体。举个例子如标签的真实值(85,176,232,115,1,84,172,230,156,1,0,0,1,0,....,0)中p=1。而预测值中p表示包含物体的概率如(84,175,234,116,0.98,83,173,231,154,0.94,0,0,1,0,....,0)中p=0.98 或p0.94。如下图:
置信度则是: C=(1-0.98)**2 * IOU
深入学习通道:https://blog.csdn.net/qq_41946216/article/details/132733387
参考:https://blog.csdn.net/weixin_39190382/article/details/130336487?spm=1001.2014.3001.5502