文章目录
- 前言
- 一、深度优先搜索
- 1.引入
- 2.概念
- 3.迷宫问题中的DFS算法步骤
- 4.特点
- 5.时间、空间复杂度
- 5.1 时间复杂度 (Time Complexity)
- 5.2 空间复杂度 (Space Complexity)
- 5.3 小结
- 二、例题讲解
- 1.问题:1586 - 扫地机器人
- 问题:1430 - 迷宫出口
- 三、总结
- 四、感谢
前言
深度优先搜索(Depth-First Search, DFS)作为一种基础而强大的图遍历算法,在信息学奥林匹克竞赛(NOI)及广泛的计算机科学应用中占据重要地位。本章节专为C++初学者设计,旨在系统性地介绍深度优先搜索的基本原理、实现方法及其在实际问题中的应用,为后续深入学习更复杂的算法和数据结构打下坚实基础。
在学习过程中,我们将以直观易懂的迷宫问题为切入点,引导读者理解DFS如何模拟人类在迷宫中寻找出路的过程,从而掌握其核心思想和操作步骤。通过细致剖析DFS的算法流程,包括初始化、选择子节点、递归访问与回溯等关键环节,读者将对DFS如何深入探索图的结构、避免重复访问以及如何在遇到死路时回溯至先前节点有深刻理解。
学习路线:C++从入门到NOI学习路线
学习大纲:C++全国青少年信息学奥林匹克竞赛(NOI)入门级-大纲
一、深度优先搜索
1.引入
想象一下,有一天你被传送到了一个迷宫,或者你正在参加一个迷宫挑战游戏,你会怎么做才能让自己走出迷宫呢?

在迷宫里面我们是没有方向感的,如何找到正确的路径是我们的首要任务。
假如我被传送到了一个充满未知的迷宫:
-
首先,我会仔细观察周围的环境,注意光线来源、地面特征、空气流动方向等自然线索,这些都可能是导航的依据。
-
采用“右手法则”或“左手法则”作为基本的探索策略,始终贴着右手边(或左手边)的墙壁行走,理论上这能帮助探索整个迷宫区域而不会错过任何角落。
-
如果没有任何现成的标记工具,我会利用环境中的自然特征(如在泥土上划线、移动小石头堆等)来标记已探索的路径,避免重复走回头路。
-
在每个岔路口,我会小心选择路径,并在心里或用标记记录下来。如果遇到死路,立刻返回上一个岔路口,尝试另一条路径。
那能写一个程序并模拟这个过程吗,让计算机帮我们完成吗?
答案是肯定的,这就是我们今天需要学习的内容-深度优先搜索。
2.概念
深度优先搜索(Depth-First Search,简称DFS)是一种用于遍历或搜索树或图的算法。它遵循“深入到底”的原则,即一旦选择了一个分支,就会沿着这条路径一直探索下去,直到达到叶子节点或者无法继续前进为止,此时再回溯到上一层,选择其他未探索的分支进行探索。
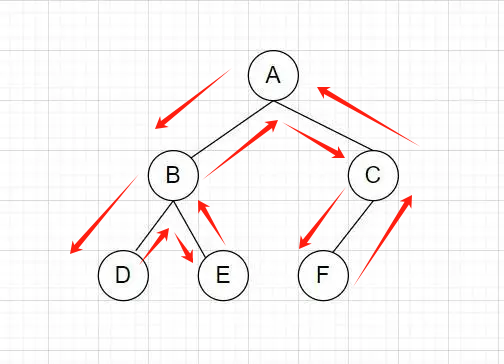
简单的来说:就是一路走到头,不撞南墙不回头。

3.迷宫问题中的DFS算法步骤
- 初始化
- 起始位置:在迷宫问题中,我们首先确定一个起始节点,通常是迷宫的入口。在二维数组表示的迷宫中,这个起始节点可以用特定坐标表示,比如(0, 0)代表左上角。
- 标记:标记起始节点为已访问,这可以通过在二维数组中对应的元素上做标记,比如将(0, 0)处的值改为一个特殊标记,表示这个位置已经探索过了。
- 选择子节点
- 探索方向:在当前节点,我们检查四个基本方向(上、下、左、右),遵循一定的顺序,比如先右后下再左最后上,来决定探索的路径。
- 有效性检查:对于每个方向,我们需要检查是否越界(确保还在迷宫内)以及该方向上的下一个格子是否可通行(即值为0,代表空地)。
- 选择未访问节点:从这四个方向中选择第一个未访问的节点作为下一个探索目标。如果所有方向都已访问,则当前节点探索完毕,需要回溯。
- 递归访问
- 递归调用:当选择了一个新的未访问节点后,对该节点进行标记,并递归地调用DFS函数,以该节点作为新的起始点继续探索。这一步是DFS算法递归性的体现,它确保了我们能够深入迷宫的每一个可到达角落。
- 目标检测:在递归过程中,如果发现到达了迷宫的出口(即目标节点),则探索成功,可以结束递归并返回找到路径的信息。
- 回溯
- 无路可走:如果在当前节点的四个方向都已无未访问的节点,说明当前路径无法继续,此时需要从递归调用栈中返回至上一层节点。
- 状态恢复:在回溯时,通常不需要特别的操作来“恢复状态”,因为DFS在递归返回时自然会放弃对当前路径的探索,回到上一个节点,继续探索其剩余的未访问邻居。
假设迷宫是一个5x5的二维数组,起始点为(0, 0),出口为(4, 4)。我们从(0, 0)开始,首先尝试向右探索,标记(0, 0)为已访问。如果右边是空地,则继续深入探索(0, 1),否则尝试下一个方向。以此类推,如果所有方向都探索完毕,则回溯到(0, 0),尝试向下探索(1, 0)。整个过程持续进行,直到找到(4, 4)或所有可能路径都探索完毕。
4.特点
-
深度优先:DFS的核心理念是尽可能深入地探索图或树的结构。一旦选择了一个分支,DFS会一直沿着这个分支探索,直到达到叶子节点或无法继续深入为止,然后回溯到上一个节点,再选择其他未探索的分支。
-
递归或栈的使用:DFS可以通过递归或使用栈来实现。递归自然地体现了DFS的回溯过程,而栈则是在非递归实现中模拟递归调用栈的行为,用于存储待探索的节点。
-
路径跟踪与回溯:DFS在搜索过程中需要记录已访问过的节点,以避免重复访问。当一条路径探索完毕后,通过回溯到上一个节点,寻找其他未探索路径,这是DFS算法区别于广度优先搜索(BFS)的重要特征。
-
目标导向与路径探索:DFS适合寻找是否存在一条路径到达目标,或者需要遍历所有可能路径的问题,如迷宫求解、环检测、强连通分量的发现等。
-
非最优性:DFS不保证找到最短路径,它更适合于寻找任意路径而非最短路径问题。在需要寻找最优解时,如最短路径问题,通常会选择广度优先搜索或其他更高效的算法。
-
拓扑排序:在有向无环图(DAG)中,DFS可以用来进行拓扑排序,即确定顶点的线性排序,使得对于每条有向边 u → v,顶点u总是在顶点v之前。
-
回溯思想:DFS中蕴含了回溯的思想,这在解决约束满足问题、组合优化问题时非常有用,比如八皇后问题、图的着色问题等。
5.时间、空间复杂度
5.1 时间复杂度 (Time Complexity)
DFS的时间复杂度主要取决于图的结构,即顶点数(V)和边数(E)。
- 基础分析:
- 遍历每个节点:DFS算法需要遍历图中的每一个节点至少一次,确保所有节点都被访问到。因此,基础时间消耗与图中节点的数量有关,即为V。
- 遍历每条边:在访问每个节点的同时,DFS也会检查与之相邻的边,以决定下一个要访问的节点。在无向图中,每条边都会被两端的节点各访问一次,而在有向图中,每条边只会在其起点处被考虑。因此,边的数量E也直接影响时间复杂度。
- 最坏情况分析:
- 无权图:在最坏的情况下,假设图是完全图,即每一对不同的顶点之间都有一条边相连,此时每访问一个节点,都需要检查所有的邻接点,导致时间复杂度为O(V*E),但通常简化表述为O(V+E)。
- 特殊结构:对于特定的图结构,如树(一种特殊的图,每个节点最多有一条入边),DFS的时间复杂度依然为O(V+E),但E此时等于V-1(因为树中没有环)。
5.2 空间复杂度 (Space Complexity)
DFS的空间复杂度主要涉及递归调用栈的深度或手动管理的栈大小。
- 递归实现
- 递归栈:递归版本的DFS主要消耗在于调用栈的空间。在最不利条件下,即图形成一个长链,递归深度达到最大,需要存储从根节点到当前节点的路径,导致空间复杂度为O(V)。这是因为每深入一层递归,栈中就会增加一个调用记录。
- 路径长度:实际上,空间复杂度取决于从根节点到当前探索节点的最长路径长度,而不是所有节点的数量。在极端情况下,若存在一条从根到叶子的最长路径,空间复杂度表现为这条路径的长度,即O(V)。
- 非递归实现(栈)
- 手动管理栈:非递归实现中,通过手动维护一个栈来追踪待探索的节点,栈中存储的是未完全探索的节点。在最坏情况下,如果图呈现一条单链形式,栈的大小同样会达到O(V),因为需要存储从起点到当前节点的所有节点。
- 优化:在某些情况下,通过特定的数据结构或算法优化,如迭代深化深度优先搜索(IDDFS)中的递归深度限制,可以减少所需的最大栈空间,但这通常以增加时间复杂度为代价。
5.3 小结
- 时间复杂度:DFS的典型时间复杂度为O(V+E),反映了遍历所有节点和边的开销。
- 空间复杂度:递归和非递归实现的空间复杂度在最坏情况下均为O(V),这与图中可能出现的最长路径长度直接相关。
二、例题讲解
1.问题:1586 - 扫地机器人
类型:深度优先搜索
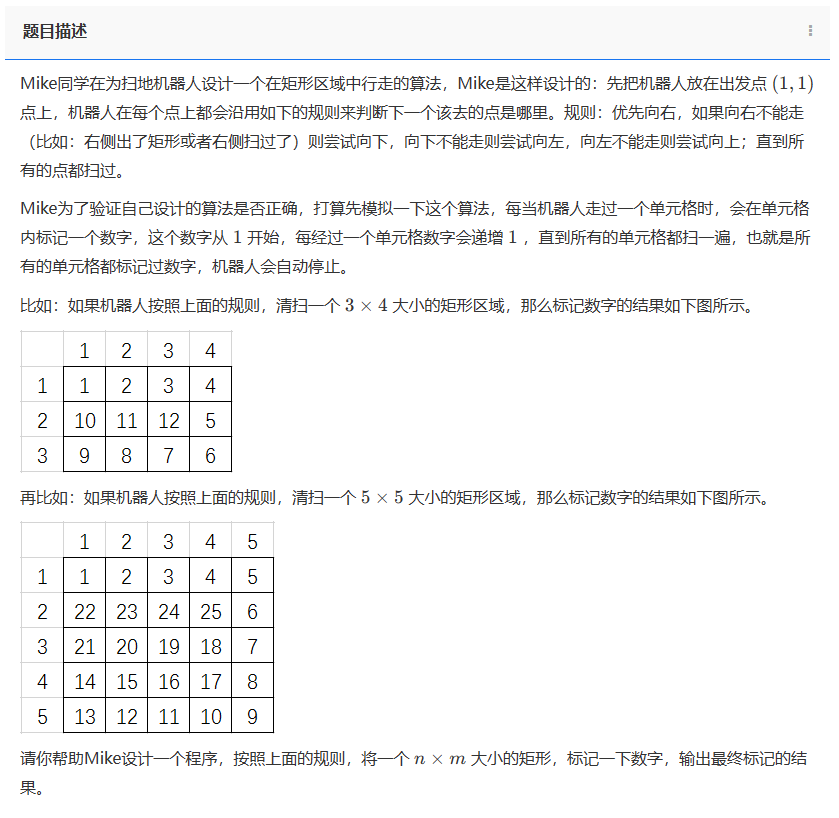
题目描述:
Mike同学在为扫地机器人设计一个在矩形区域中行走的算法,Mike是这样设计的:先把机器人放在出发点
(1,1) 点上,机器人在每个点上都会沿用如下的规则来判断下一个该去的点是哪里。规则:优先向右,如果向右不能走(比如:右侧出了矩形或者右侧扫过了)则尝试向下,向下不能走则尝试向左,向左不能走则尝试向上;直到所有的点都扫过。
Mike为了验证自己设计的算法是否正确,打算先模拟一下这个算法,每当机器人走过一个单元格时,会在单元格内标记一个数字,这个数字从 1 开始,每经过一个单元格数字会递增 1 ,直到所有的单元格都扫一遍,也就是所有的单元格都标记过数字,机器人会自动停止。
输入:
一行内有 2 个两个整数 n 和 m ,用空格隔开,分别代表矩形区域的行数(高)和列数(宽)。
1<n,m<10。
输出:
输出按题意机器人走过每个点之后,标记数字的结果,每个数字输出时场宽设置为 3。
样例:
输入:
3 4
输出:
1 2 3 4
10 11 12 5
9 8 7 6
解题思路:
老规矩,首先读题,找出可用条件,过滤无用信息。
可能很多人看到这么长的题目,就不想做了。这也太难了。
看起来本题题目很长,实际上讲了一堆废话。
简单整理一下:

接下来一个一个解决问题。
- 首先n*m的矩形区域。1<n,m<10。
因此直接使用二维数组表示这个地图。
int n,m;
int a[20][20];
- 初始化:先把机器人放在出发点 (1,1) 点上,会在单元格内标记一个数字,这个数字从 1 开始。
那我们需要定义一个递归函数,这个函数的参数除了需要有x,y坐标,还有标记值k。
然后将初始值出发点 (1,1) ,标记值1,传递给递归函数即可。
void dfs(int x,int y,int k){
a[x][y]=k;//赋值
}
dfs(1,1,1);
- 右、下、左、上的顺序行走。
当选择了一个新的未访问节点后,对该节点进行标记,并递归地调用DFS函数,以该节点作为新的起始点继续探索。这一步是DFS算法递归性的体现,它确保了我们能够深入迷宫的每一个可到达角落。
//右
if(y+1<=m && a[x][y+1]==0){
dfs(x,y+1,k+1);
}
//下
if(x+1<=n && a[x+1][y]==0){
dfs(x+1,y,k+1);
}
//左
if(y-1>=1 && a[x][y-1]==0){
dfs(x,y-1,k+1);
}
//上
if(x-1>=1 && a[x-1][y]==0){
dfs(x-1,y,k+1);
}
那关于这个题目的难点问题就解决完成了。
1.分析问题
- 已知:将一个 n×m 大小的矩形,标记一下数字。
- 未知:输出最终标记的结果。
- 关系:优先向右,如果向右不能走(比如:右侧出了矩形或者右侧扫过了)则尝试向下,向下不能走则尝试向左,向左不能走则尝试向上;直到所有的点都扫过。
2.定义变量
- n 代表二维数组的行数,m 代表列数
- 初始化一个20x20的二维数组,用于存储遍历过程中的标记值
// 全局变量定义
int n, m;
int a[20][20];
3.输入数据
- 输入二维数组的尺寸,即行数n和列数m。
cin >> n >> m;
4.数据计算
- 从二维数组的左上角(1,1)开始进行深度优先搜索,初始标记值为1。
dfs(1, 1, 1);
- 深度优先搜索函数。
void dfs(int x, int y, int k) {
// 在当前位置(x, y)标记为k
a[x][y] = k;
// 检查右方的格子是否在范围内且未被访问过,如果是,则继续深入探索
if(y + 1 <= m && a[x][y+1] == 0) {
dfs(x, y+1, k+1);
}
// 检查下方的格子
if(x + 1 <= n && a[x+1][y] == 0) {
dfs(x+1, y, k+1);
}
// 检查左方的格子
if(y - 1 >= 1 && a[x][y-1] == 0) {
dfs(x, y-1, k+1);
}
// 检查上方的格子
if(x - 1 >= 1 && a[x-1][y] == 0) {
dfs(x-1, y, k+1);
}
}
5.输出结果
- 输出遍历后的二维数组,展示每个格子被访问的顺序。
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= m; j++) {
// 使用setw(3)设置输出宽度,保持输出对齐美观
cout << setw(3) << a[i][j];
}
// 每行输出结束后换行
cout << endl;
}
完整代码如下:
#include<bits/stdc++.h> // 引入标准库中的所有常用头文件,简化编程时的头文件包含
using namespace std; // 使用std命名空间,可以直接调用std中的函数和对象,无需前缀
// 全局变量定义
int n, m; // n 代表二维数组的行数,m 代表列数
int a[20][20]; // 初始化一个20x20的二维数组,用于存储遍历过程中的标记值
// 深度优先搜索函数
void dfs(int x, int y, int k) {
// 在当前位置(x, y)标记为k
a[x][y] = k;
// 检查右方的格子是否在范围内且未被访问过,如果是,则继续深入探索
if(y + 1 <= m && a[x][y+1] == 0) {
dfs(x, y+1, k+1);
}
// 检查下方的格子
if(x + 1 <= n && a[x+1][y] == 0) {
dfs(x+1, y, k+1);
}
// 检查左方的格子
if(y - 1 >= 1 && a[x][y-1] == 0) {
dfs(x, y-1, k+1);
}
// 检查上方的格子
if(x - 1 >= 1 && a[x-1][y] == 0) {
dfs(x-1, y, k+1);
}
}
int main() {
// 主函数开始
// 用户输入二维数组的尺寸,即行数n和列数m
cin >> n >> m;
// 从二维数组的左上角(1,1)开始进行深度优先搜索,初始标记值为1
dfs(1, 1, 1);
// 输出遍历后的二维数组,展示每个格子被访问的顺序
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= m; j++) {
// 使用setw(3)设置输出宽度,保持输出对齐美观
cout << setw(3) << a[i][j];
}
// 每行输出结束后换行
cout << endl;
}
// 程序结束,返回0表示成功执行
return 0;
}
解法二
解题思路:使用方向数组
在解决迷宫问题时,方向数组用于指导搜索算法(如深度优先搜索、广度优先搜索)探索相邻的可通行格子。例如,从当前格子出发,按照方向数组中指定的偏移量,检查上下左右(或更多方向)的格子是否可通行,并决定下一步的移动方向。
通常情况下,迷宫问题中采用的坐标系与数学上的笛卡尔坐标系有所不同,通常约定:
- y 表示横向(列),从左到右递增。
- 表示纵向(行),从上到下递增。
按照这样的约定,迷宫中四个基本方向的坐标增量应为:
右(0, 1)
下(1, 0)
左(0, -1)
上(-1, 0)
示例:
以下是一个二维空间中表示四个基本方向(上、下、左、右)的方向数组:
int directions[4][2] = {
{-1, 0}, // 上:向负x方向移动,y坐标不变
{1, 0}, // 下:向正x方向移动,y坐标不变
{0, -1}, // 左:向负y方向移动,x坐标不变
{0, 1} // 右:向正y方向移动,x坐标不变
};
当然也可以使用一维数组表示:
右(0, 1)、下(1, 0)、左(0, -1)、上(-1, 0)。
int fx[5]={0,0,1,0,-1};
int fy[5]={0,1,0,-1,0};
完整代码如下:
#include <bits/stdc++.h>
using namespace std;
// 定义全局变量
int n, m; // 矩形网格的行数(n)和列数(m)
int a[20][20]; // 用于存储每个格子的标记值的二维数组,大小为 n × m
// 定义方向数组,存储x和y坐标变化的值
int fx[5] = {0, 0, 1, 0, -1}; // 右(0, 1)、下(1, 0)、左(0, -1)、上(-1, 0)
int fy[5] = {0, 1, 0, -1, 0};
// 深度优先搜索(DFS)函数
// 参数:当前格子的坐标 x, y,当前标记值 k
void dfs(int x, int y, int k) {
// 将当前格子 (x, y) 的标记值更新为 k
a[x][y] = k;
// 遍历四个方向(右、下、左、上),按照索引 i(1~4)
for (int i = 1; i <= 4; i++) {
// 计算下一个待访问格子的坐标 tx 和 ty
int tx = x + fx[i];
int ty = y + fy[i];
// 递归之前先判断,确保要访问的点的有效性
// (1)坐标在矩形范围内:1 <= tx <= n 且 1 <= ty <= m
// (2)该格子尚未被访问过:a[tx][ty] == 0
if (tx >= 1 && tx <= n && ty >= 1 && ty <= m && a[tx][ty] == 0) {
// 若满足条件,递归调用 dfs 函数,继续标记下一个格子
dfs(tx, ty, k + 1);
}
}
}
int main() {
// 一、分析问题
// 已知:将一个 n×m 大小的矩形,标记一下数字。
// 未知:输出最终标记的结果。
// 关系:优先向右,如果向右不能走(比如:右侧出了矩形或者右侧扫过了)则尝试向下,
// 向下不能走则尝试向左,向左不能走则尝试向上;直到所有的点都扫过。
// 二、数据定义
// 已在全局变量中定义
// 三、数据输入
cin >> n >> m;
// 四、数据计算
// 为(1,1)点赋值为1
dfs(1, 1, 1);
// 五、输出结果
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
// 输出每个格子的标记值,格式化输出宽度为3
cout << setw(3) << a[i][j];
}
// 每行输出结束后换行
cout << endl;
}
return 0;
}
问题:1430 - 迷宫出口
类型:深搜 递归 广搜
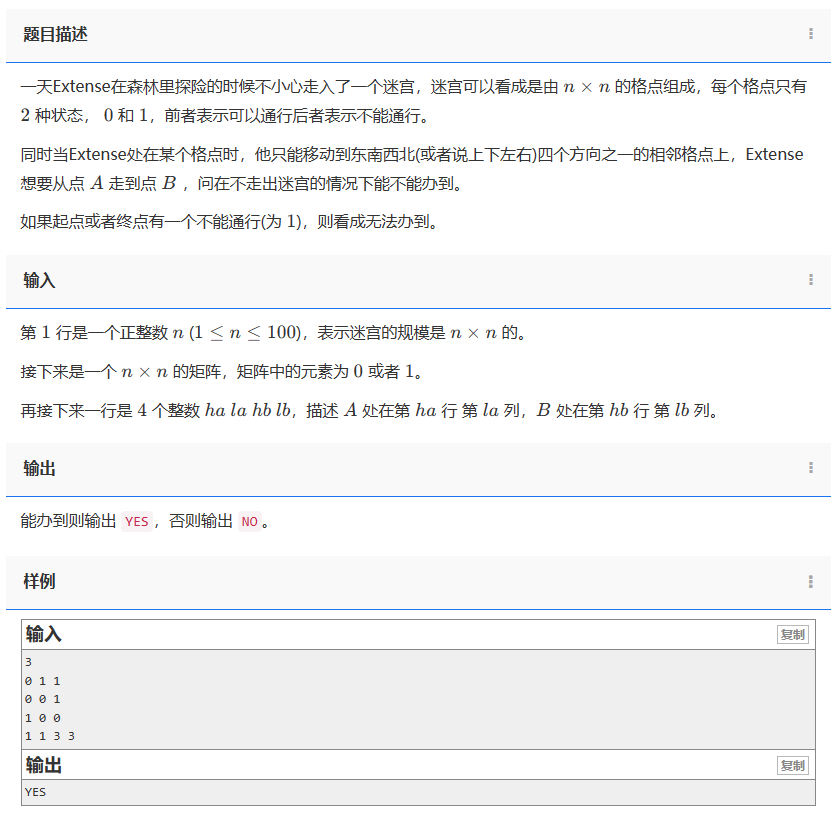
题目描述:
一天Extense在森林里探险的时候不小心走入了一个迷宫,迷宫可以看成是由 n×n 的格点组成,每个格点只有 2 种状态, 0 和 1,前者表示可以通行后者表示不能通行。
同时当Extense处在某个格点时,他只能移动到东南西北(或者说上下左右)四个方向之一的相邻格点上,Extense想要从点 A 走到点 B ,问在不走出迷宫的情况下能不能办到。
如果起点或者终点有一个不能通行(为 1),则看成无法办到。
输入:
第 1 行是一个正整数 n (1≤n≤100),表示迷宫的规模是 n×n 的。
接下来是一个n×n 的矩阵,矩阵中的元素为 0 或者 1。
再接下来一行是 4 个整数 ha la hb lb,描述 A 处在第 ha 行 第 la 列,B 处在第 hb 行 第lb 列。
输出:
能办到则输出 YES,否则输出 NO。
样例:
输入:
3
0 1 1
0 0 1
1 0 0
1 1 3 3
输出:
YES
解题思路:
本题是问有一个n*n的迷宫,从点 A 走到点 B ,问在不走出迷宫的情况下能不能办到。
那如何判断是否存在这一条路径是解题的关键。
其实可以像上一题一样,让点A移动,如果点A的坐标和点B的坐标重合,那就意味着存在这么一条路径。
并且本题只是问了是否存在点A到点B的路径,因此只要找到1条就可以了。
1.分析问题
- 已知:n*n的迷宫 ,每个格点只有 2 种状态, 0 和 1,前者表示可以通行后者表示不能通行。
- 未知:从点 A 走到点 B ,问在不走出迷宫的情况下能不能办到。
- 关系:如果起点或者终点有一个不能通行(为 1),则看成无法办到。
2.定义变量
- 整型变量 n 存储迷宫的边长(假设为正方形迷宫)。
- 整型变量 ha、la、hb、lb 分别存储起点和终点的行、列坐标。
- 定义一个 n × n 的二维整型数组 mg,用于存储迷宫的格子状态,其中0表示可通行,1表示不可通行。
- 布尔变量 pathFound 用于记录是否找到了从起点到终点的路径。
- 定义两个一维整型数组 fx 和 fy,分别存储在遍历时x轴和y轴方向的变化值。这里定义了四个基本方向。
//二、数据定义
int n;
int ha,la,hb,lb;
int mg[110][110];
bool pathFound =false;
int fx[5]={0,0,1,0,-1};
int fy[5]={0,1,0,-1,0};
3.输入数据
- 输入迷宫的边长 n 和迷宫数据。
- 输入起点和终点坐标。
//三、数据输入
cin>>n;
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
cin>>mg[i][j];
}
}
cin>>ha>>la>>hb>>lb;
4.数据计算
- 检查起点或终点是否不可通行(值为1)。若任意一个不可通行,输出 “NO”,表示无法从起点走到终点。
- 若起点和终点均可通行,调用 dfs(ha, la) 进行深度优先搜索。
- 根据 pathFound 的值输出结果:
若 pathFound 为 true,输出 “YES”,表示找到了从起点到终点的路径。
若 pathFound 仍为 false,输出 “NO”,表示未能找到从起点到终点的路径。
//四、数据计算
//如果起点或者终点有一个不能通行(为 1),则看成无法办到
if(mg[ha][la]==1 || mg[hb][lb]==1){
//五、输出结果
cout<<"NO";
}else{
dfs(ha,la);
if(pathFound){
//五、输出结果
cout<<"YES";
}else{
//五、输出结果
cout<<"NO";
}
- 函数 dfs(x, y) 接收当前格子的坐标 x 和 y。
- 首先将当前格子 mg[x][y] 标记为已访问(值为1)。
- 使用两个变量 tx 和 ty 存储下一个待探索格子的坐标。
- 循环遍历方向数组 fx 和 fy,依次尝试向右、下、左、上移动。
- 计算下一个待探索格子的坐标 tx 和 ty。
- 检查新坐标是否有效(即位于迷宫范围内且未被访问过):
如果有效且到达终点 (tx == hb 且 ty == lb),将 pathFound 设为 true 并结束搜索。
如果有效且未到达终点,递归调用 dfs(tx, ty) 继续探索下一个格子。 - 递归结束后,若 pathFound 仍为 false,说明从当前格子出发无法到达终点。
void dfs(int x,int y){
mg[x][y]=1;//走过的路进行标记
int tx,ty;//表示要探索的点
for(int i=1;i<=4;i++){
tx=x+fx[i];
ty=y+fy[i];
if(tx>=1&&tx<=n&&ty>=1&&ty<=n&&mg[tx][ty]==0){
if(tx==hb&&ty==lb){
pathFound=true;
}else{
dfs(tx,ty);
}
}
}
}
完整代码如下:
#include <iostream>
using namespace std;
// 二、数据定义
int n; // 迷宫的边长(假设为正方形迷宫)
int ha, la, hb, lb; // 起点和终点的行、列坐标
int mg[110][110]; // 用于存储迷宫的格子状态,0表示可通行,1表示不可通行
bool pathFound = false; // 记录是否找到了从起点到终点的路径
// 方向数组,存储x和y坐标变化的值,符合迷宫问题中约定的坐标系
int fx[5] = {0, 0, 1, 0, -1}; // 右(0, 1)、下(1, 0)、左(0, -1)、上(-1, 0)
int fy[5] = {0, 1, 0, -1, 0};
// 深度优先搜索(DFS)函数
// 参数:当前格子的坐标 x, y
void dfs(int x, int y) {
mg[x][y] = 1; // 将当前格子标记为已访问(值为1)
int tx, ty; // 表示要探索的点
// 遍历四个方向(右、下、左、上),按照索引 i(1~4)
for (int i = 1; i <= 4; i++) {
tx = x + fx[i];
ty = y + fy[i];
// 检查新坐标是否有效(即位于迷宫范围内且未被访问过)
if (tx >= 1 && tx <= n && ty >= 1 && ty <= n && mg[tx][ty] == 0) {
// 若有效且到达终点,将 pathFound 设为 true 并结束搜索
if (tx == hb && ty == lb) {
pathFound = true;
break;
}
// 若有效且未到达终点,递归调用 dfs 继续探索下一个格子
else {
dfs(tx, ty);
}
}
}
}
int main() {
// 一、分析问题
// 已知:n × n 的迷宫,每个格点只有 2 种状态,0 和 1,前者表示可以通行,后者表示不能通行。
// 未知:从点 A 走到点 B,问在不走出迷宫的情况下能不能办到。
// 关系:如果起点或者终点有一个不能通行(为 1),则看成无法办到。
// 二、数据定义
// 已在全局变量中定义
// 三、数据输入
cin >> n;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
cin >> mg[i][j];
}
}
cin >> ha >> la >> hb >> lb;
// 四、数据计算
// 如果起点或者终点有一个不能通行(为 1),则看成无法办到
if (mg[ha][la] == 1 || mg[hb][lb] == 1) {
// 五、输出结果
cout << "NO";
} else {
dfs(ha, la); // 执行深度优先搜索
if (pathFound) {
// 五、输出结果
cout << "YES";
} else {
// 五、输出结果
cout << "NO";
}
}
return 0;
}
三、总结
本章节聚焦于深度优先搜索(DFS)这一基础且实用的图遍历算法,以迷宫问题为引,深入浅出地阐述了其原理、步骤、特点及复杂度分析,辅以实例讲解和代码示例,为C++初学者提供了清晰的学习脉络。
DFS遵循“深入到底”的原则,借助递归或栈实现,依次探索分支直至叶子节点或死路,再回溯至前一节点探寻其他未探索路径。其特点包括深度优先特性、递归或栈的使用、路径跟踪与回溯、目标导向探索以及非最优性,适用于寻找路径、环检测、拓扑排序等问题。时间复杂度为O(V+E),空间复杂度在最坏情况下为O(V),与最长路径长度相关。
通过“扫地机器人”和“迷宫出口”等例题,本章生动展示了DFS在实际问题中的应用,如矩形区域遍历标记与迷宫路径查找。这些实例强化了理论理解,培养了将算法转化为代码的能力。
总之,本章系统讲解了DFS算法,从理论到实践全方位赋能C++初学者,为其在信息学奥林匹克竞赛(NOI)及类似编程挑战中运用DFS解决图搜索问题奠定了坚实基础。
四、感谢
如若本文对您的学习或工作有所启发和帮助,恳请您给予宝贵的支持——轻轻一点,为文章点赞;若觉得内容值得分享给更多朋友,欢迎转发扩散;若认为此篇内容具有长期参考价值,敬请收藏以便随时查阅。
每一次您的点赞、分享与收藏,都是对我持续创作和分享的热情鼓励,也是推动我不断提供更多高质量内容的动力源泉。期待我们在下一篇文章中再次相遇,共同攀登知识的高峰!





![[Windows] Bypass分流抢票 v1.16.25 五一黄金周自动抢票软件(2024.02.08更新)](https://img-blog.csdnimg.cn/direct/5a933d8bb0a44159bbae2b92f80cb2be.png)