接前一篇文章:软考 系统架构设计师系列知识点之大数据设计理论与实践(12)
所属章节:
第19章. 大数据架构设计理论与实践
第4节 Kappa架构
19.4.2 Kappa架构介绍
Kappa架构由Jay Kreps提出(Lambda由Storm之父Nayhan Marz提出),不同于Lambda同时计算流计算和批计算合并视图,Kappa只会通过流计算一条数据链路来计算并产生视图。Kappa同样采用了重新处理事件的原则,对于历史数据分析类的需求,Kappa要求数据的长期存储能够以有序日志流的方式重新流入计算引擎,重新产生历史数据的视图。本质上是通过改进Lambda架构中的Speed Layer,使它既能够进行实时数据处理,同时也有能力在业务逻辑更新的情况下,重新处理以前处理过的历史数据。
Kappa架构的原理就是:
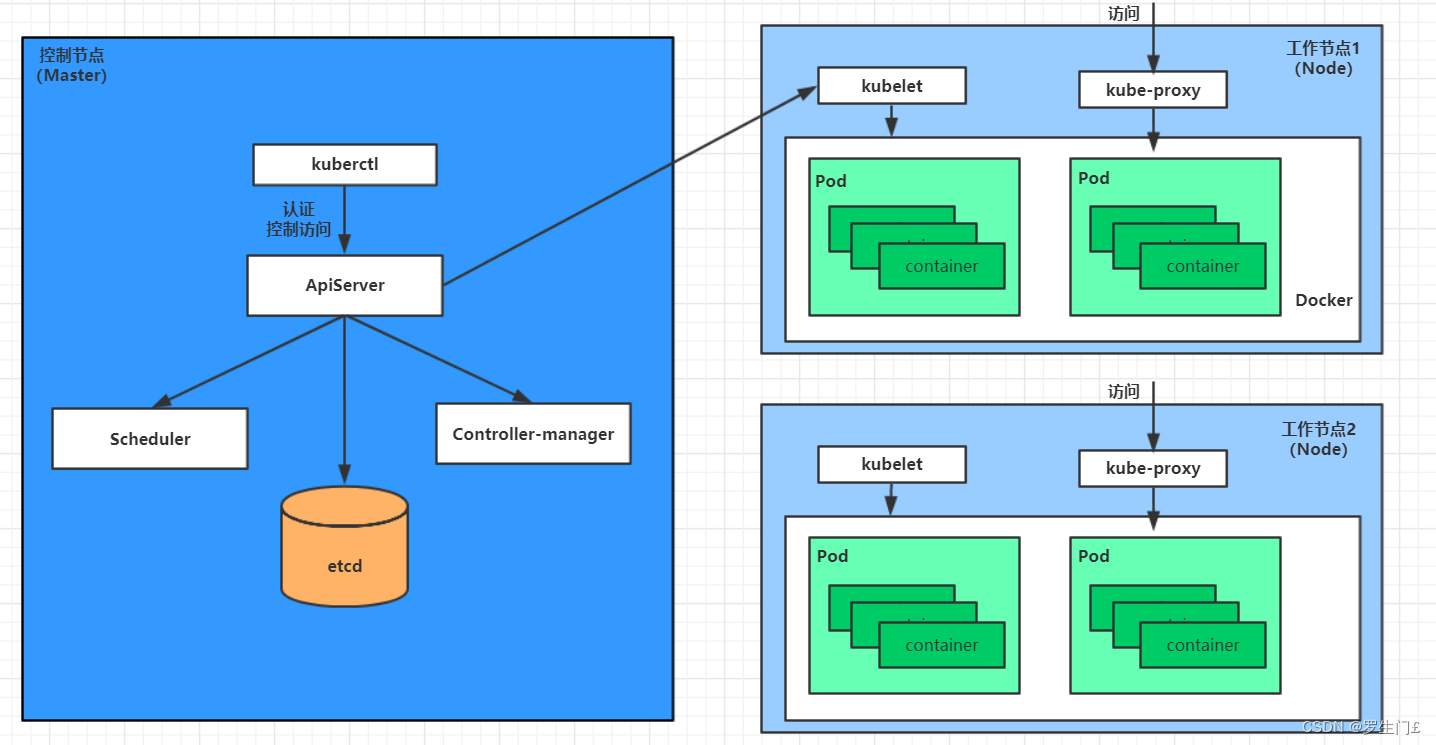
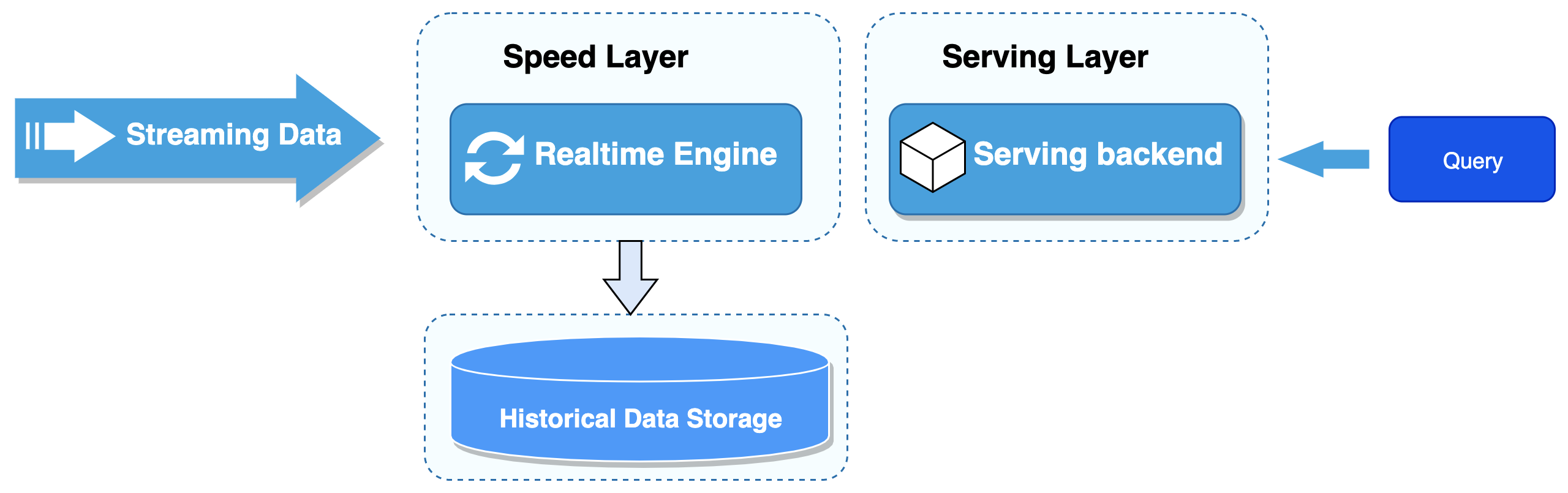
在Lambda的基础上进行了优化,删除了Batch Layer的架构,将数据通道以消息队列进行替代。因此对于Kappa架构来说,依旧以流处理为主,但是数据却在数据湖层面进行了存储。当需要进行离线分析或者再次计算的时候,则将数据湖的数据再次经过消息队列重播一次即可。Kappa数据处理架构如图19-10所示:
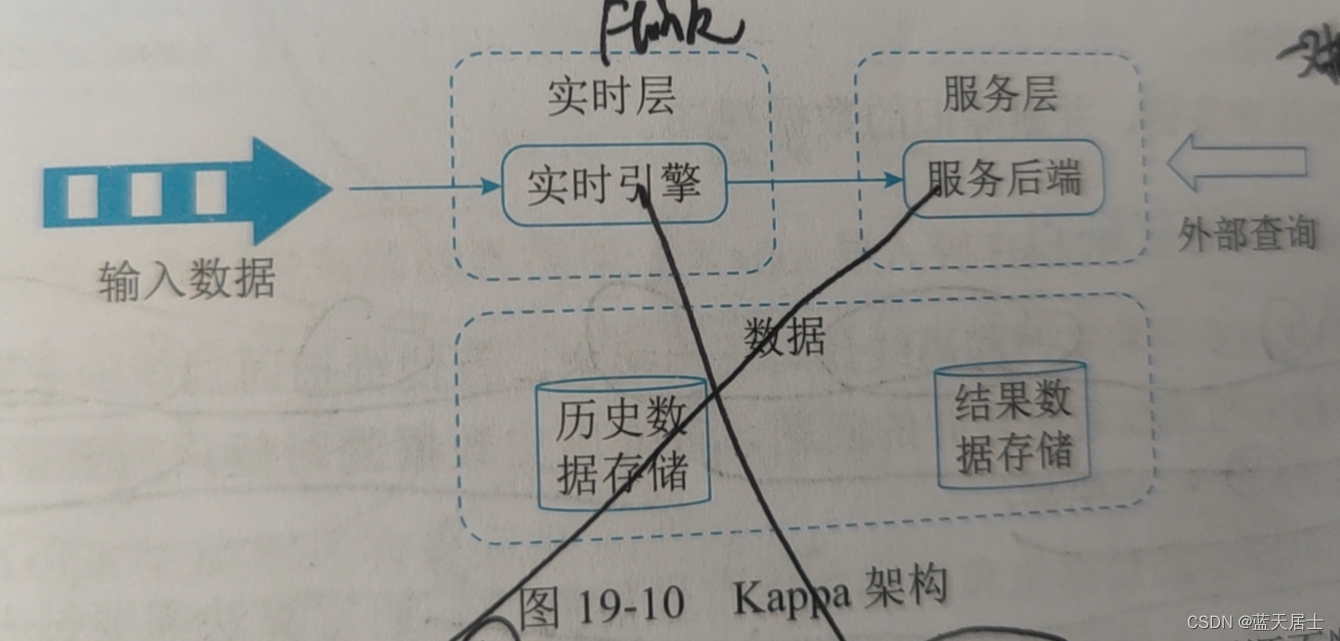
如上图所示,输入数据直接由实时层的实时数据处理引擎对源源不断的源数据进行处理,再由服务层的服务后端进一步处理以提供上层的业务查询。而中间结果的数据都是需要存储的,这些数据包括历史数据与结果数据,统一存储在存储介质中。
Kappa方案通过精简链路解决了数据写入和计算逻辑复杂的问题。但它依然没有解决存储和展示的问题,特别是在存储上,使用类似Kafka的消息队列存储长期日志数据,数据无法压缩,存储成本很大。绕过(work around)方案是使用支持数据分层存储的消息系统(如Pulsar,支持将历史消息存储到云上存储系统),但是分层存储的历史日志数据仅能用于Kappa backfill作业,数据的利用率依然很低。
从使用场景上来看,Kappa架构与Lambda架构相比,主要有两点区别:
(1)Kappa不是Lambda的替代架构,而是其简化版本。Kappa架构放弃了对批处理的支持,更擅长业务本身为增量数据写入场景的分析需求。例如,各种时序数据场景,天然存在时间窗口的概念,流式计算直接满足其实时计算和历史补偿任务需求;
(2)Lambda直接支持批处理,因此更适合对历史数据分析查询的场景。比如,数据分析师需要按任意条件组合对历史数据进行探索性的分析,并且有一定的实时性需求,期望尽快得到分析结果,批处理可以更直接高效地满足这些需求。
至此,“19.4.2 Kappa架构介绍”的全部内容就讲解完了。更多内容请看下回。