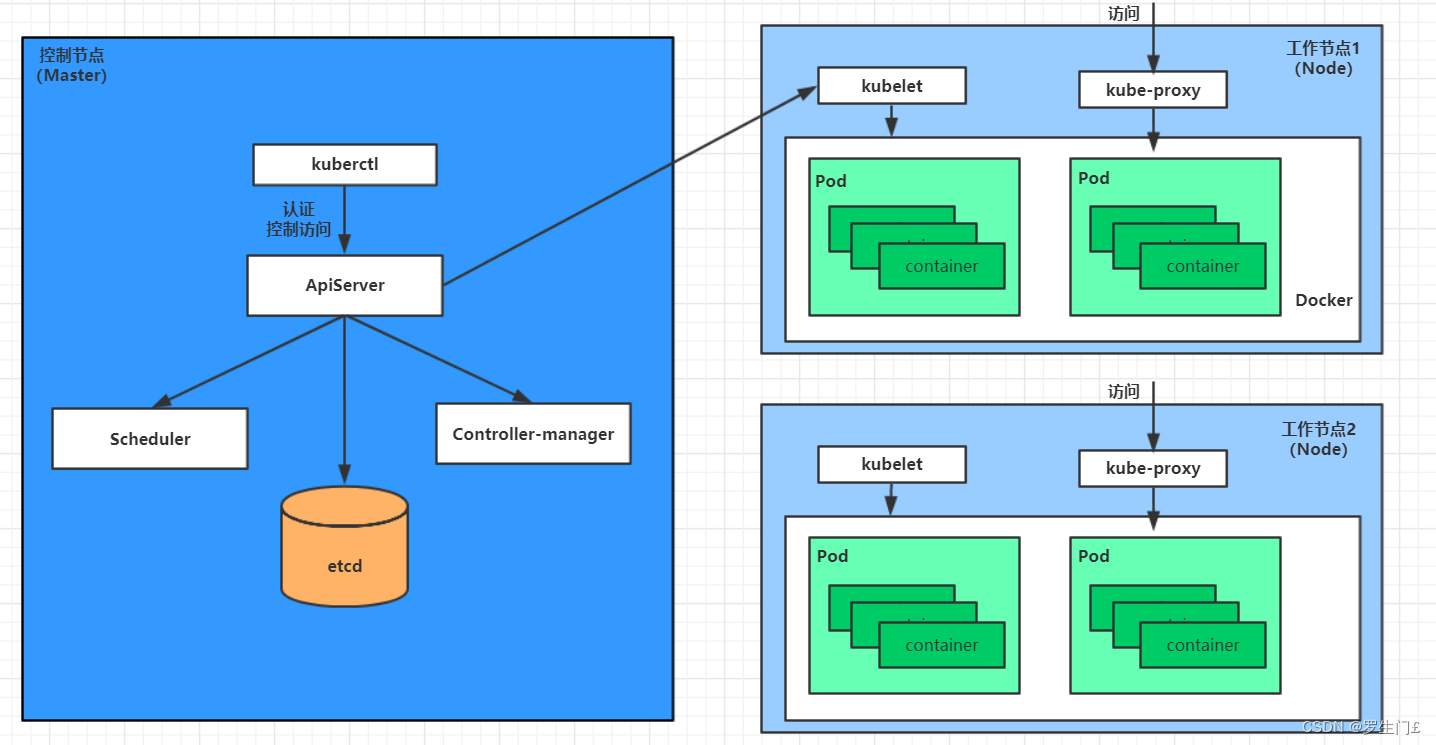
在训练神经网络时,权重初始化是确保良好收敛的关键步骤之一。不合适的初始化方法可能会导致梯度消失或爆炸,特别是在深层网络中。那么都有哪些神经网络的初始化参数方法呢?选择它这些方法的原则是什么?
一、常用神经网络初始化参数方法
(1)随机初始化
关于随机初始化神经网络参数的方法,我在之前的文章中详细写到过,这里就不重点赘述。只做简单回顾,如果大家想进一步了解可以点击链接单独看看。
随机初始化参数分成两种:一种是在一个均匀分布的区间内随机抽取,这种初始化方法确保参数具有一定的随机性,避免所有神经元开始时状态过于相似。另一种则是在参数遵循均值为0、标准差为某个特定值的正态分布的区间中随机抽取,这种初始化方法保证参数初始值围绕零点呈钟形分布,有助于防止参数值过大或过小导致的学习问题。
【机器学习300问】68、随机初始化神经网络权重的好处?![]() http://t.csdnimg.cn/Muzbf
http://t.csdnimg.cn/Muzbf
(2)Xavier初始化
Xavier初始化方法的基本想法是保持每一层的输入和输出的方差相等,以避免在训练过程中信号变得太小(梯度消失)或太大(梯度爆炸)。当使用Sigmoid或tanh等激活函数时,Xavier初始化尤其有效,因为这些激活函数在输入较小时近似线性,且当激活函数在其线性区域中时,我们希望信号的方差保持不变。
具体来说,Xavier初始化方法会从一个均匀分布或正态分布中抽取初始化权重,这个分布的尺度为:
或均匀分布的区间为:
其中是输入单元的数量,
是输出单元的数量。
(3)He初始化
He初始化专门针对使用ReLU及其变种作为激活函数的神经网络设计。He初始化基于Xavier初始化的思想,但考虑到ReLU激活函数仅对正半轴有非线性响应(即ReLU在其负区域的输出为0)。
因此,He初始化将权重初始化为:
当从正态分布中抽取初始化权重时,这个分布的标准差应该设置为:
对于均匀分布来说,它的范围是:
有的论文提出对于tanh函数来说常量1比常量2的效率更高,所以权重初始化公式为:
其中是输入单元的数量。
二、选择方法的原则是什么?
(1)不同的激活函数选择不同的初始化参数方法
不同的激活函数对输入信号的敏感度不同,因此需要不同的初始化策略来保持激活函数的输入信号在一个合理的范围内。按激活函数来选取初始化参数的方法是主要的选取原则。
| 激活函数 | 初始化参数方法 |
| Sigmoid | Xavier初始化 |
| Tanh | Xavier初始化或He初始化 |
| Relu等 | He初始化 |
(2)分析神经网络的深度和网络结构
对于非常深的网络,需要特别小心地选择初始化方法,因为信号必须通过许多层而不被衰减或增强太多。Xavier和He初始化通过考虑输入和输出节点数,确保信号在多层网络中传递时保持合理的幅度,避免梯度在反向传播过程中变得过小(消失)或过大(爆炸),从而提高深层网络的训练可行性。
不同网络结构(如全连接网络、卷积神经网络、循环神经网络等)有不同的连接结构和参数分布特点,可能受益于不同的初始化方法。例如,具有残差连接的网络如ResNet可能对初始化方法的选择不那么敏感,因为残差连接能帮助缓解梯度消失的问题。再例如,卷积层和循环层中的权重通常以矩阵形式存在,可能更适合采用正交初始化来确保空间或时间上的独立性。而对于全连接层,均匀或正态分布的随机初始化可能更为常见。