目录
前言
一、安装 Sklearn
二、导入 Sklearn
三、加载数据集
四、划分数据集
五、数据预处理
六、选择模型并训练
七、模型评估
八、实验不同的模型
九、调整模型参数
十、实例:使用Sklearn库来进行鸢尾花(Iris)数据集的分类
#sklearn
前言
Sklearn,或称为Scikit-learn,是一个非常流行的Python库,用于机器学习。它提供了简单高效的工具来进行数据挖掘和数据分析,是入门机器学习的绝佳选择。下面,我将为您提供一个基础教程,涵盖安装、基本用法、以及一些常见的机器学习模型的使用。
一、安装 Sklearn
首先,您需要确保已安装 Python。Sklearn 需要 Python 版本至少为 3.6。然后,您可以使用 pip 来安装 Sklearn:
pip install -U scikit-learn二、导入 Sklearn
在 Python 中使用 Sklearn 前,需要导入相应的模块:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report三、加载数据集
Sklearn 自带了几个标准的数据集,用于实践和测试算法:
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target四、划分数据集
将数据集分为训练集和测试集:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)五、数据预处理
通常需要对数据进行标准化处理,使之更适合模型:
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)六、选择模型并训练
选择一个模型并进行训练。这里以 K-最近邻 (K-NN) 为例:
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)七、模型评估
评估模型的性能:
predictions = knn.predict(X_test)
print(classification_report(y_test, predictions))八、实验不同的模型
Sklearn 提供了多种机器学习模型,例如支持向量机 (SVM)、决策树、随机森林等。您可以尝试不同的模型来看哪个最适合您的数据。
from sklearn.svm import SVC
model = SVC(kernel='linear')
model.fit(X_train, y_train)
# 再次评估模型九、调整模型参数
大多数机器学习模型都有可以调整的参数。使用 GridSearchCV 或 RandomizedSearchCV 来找到最佳的参数组合:
from sklearn.model_selection import GridSearchCV
param_grid = {'n_neighbors': [3, 5, 11, 19],
'weights': ['uniform', 'distance'],
'metric': ['euclidean', 'manhattan']}
grid_search = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
print(grid_search.best_params_)十、实例:使用Sklearn库来进行鸢尾花(Iris)数据集的分类
代码:
# 导入必要的库
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 数据预处理,标准化特征值
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 选择 K-最近邻模型并设置初始参数
knn = KNeighborsClassifier(n_neighbors=3)
# 训练模型
knn.fit(X_train, y_train)
# 使用测试集进行模型评估
predictions = knn.predict(X_test)
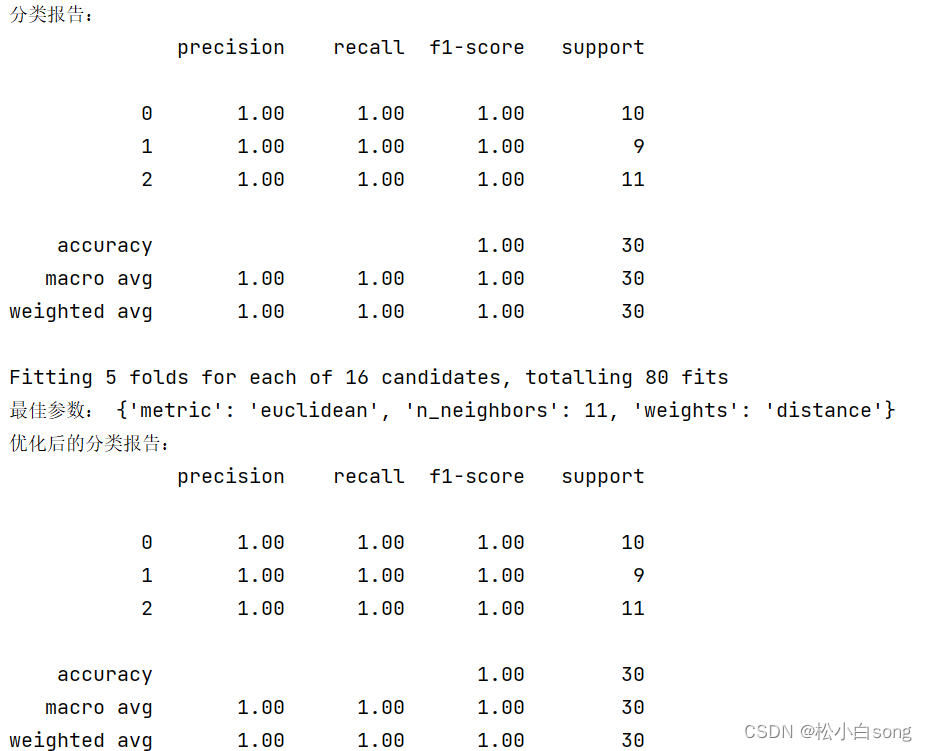
print("分类报告:")
print(classification_report(y_test, predictions))
# 使用 GridSearchCV 进行参数调整
param_grid = {
'n_neighbors': [3, 5, 11, 19],
'weights': ['uniform', 'distance'],
'metric': ['euclidean', 'manhattan']
}
grid_search = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5, verbose=1)
grid_search.fit(X_train, y_train)
# 输出最佳参数和对应的模型性能
print("最佳参数:", grid_search.best_params_)
best_knn = grid_search.best_estimator_
predictions = best_knn.predict(X_test)
print("优化后的分类报告:")
print(classification_report(y_test, predictions))
说明:
数据加载与划分:我们从 Sklearn 库中加载了鸢尾花数据集,该数据集包含了150个样本和4种特征。数据集被划分为80%的训练集和20%的测试集。
数据预处理:数据标准化是重要的预处理步骤,它帮助去除不同特征之间的量纲影响,使得机器学习算法能更好地学习。
模型训练与评估:我们使用了 K-最近邻算法,并选择了3个邻居进行分类。然后,我们用测试集评估了模型的性能。
参数调整:使用
GridSearchCV对 K-NN 的参数进行了优化,包括邻居数、权重函数和距离度量方式,以找到最优的模型配置。结果输出:展示了模型的分类报告,包括精度、召回率和 F1 分数等评价指标。
结果: