前言
本文介绍了如何使用 Python 的 requests 库和 BeautifulSoup 库来爬取研究方向信息,并将其保存为 CSV 文件。爬取的网站为“中国研究生招生信息网”(https://yz.chsi.com.cn/)。代码从指定的专业目录页面爬取研究方向的相关信息,并保存为 CSV 文件。
代码
import requests
from bs4 import BeautifulSoup
import re
from fake_useragent import UserAgent
# 伪装请求头
ua = UserAgent()
url = input('请输入专业目录的url:')
response = requests.get(url, headers={'User-Agent': ua.random})
soup = BeautifulSoup(response.text, 'lxml')
# 使用css选择器来查找包含"查看"文本的a标签,并提取其href属性
hrefs = soup.select('a:-soup-contains("查看")')
# 解析学校名称和研究方向代码
dwmc = requests.utils.unquote(url.split('&')[1].split('=')[1], 'utf-8')
yjxkdm = url.split('&')[4].split('=')[1]
filename = dwmc + '_' + yjxkdm + '.csv'
# 打开文件,如果不存在则创建
f = open(filename, 'w')
# 提取href属性,添加上前缀
for href in hrefs:
href = 'https://yz.chsi.com.cn' + href['href']
response = requests.get(href, headers={'User-Agent': ua.random})
soup = BeautifulSoup(response.text, 'lxml')
# 提取详情页信息并写入文件
a = soup.select('td.zsml-summary')
for i in a:
f.write(i.text.strip().replace(',', ' ') + ',')
b = soup.select('span.zsml-bz')
for i in b:
f.write(i.text.strip().replace(',', ' ') + ',')
c = soup.select('tbody.zsml-res-items')
for i in c:
cleaned_text = re.sub(r'\s+', ' ', i.text.strip()).replace('见招生简章', '')
f.write(cleaned_text.replace(',', ' ') + ',')
f.write('\n')
# 关闭文件
f.close()
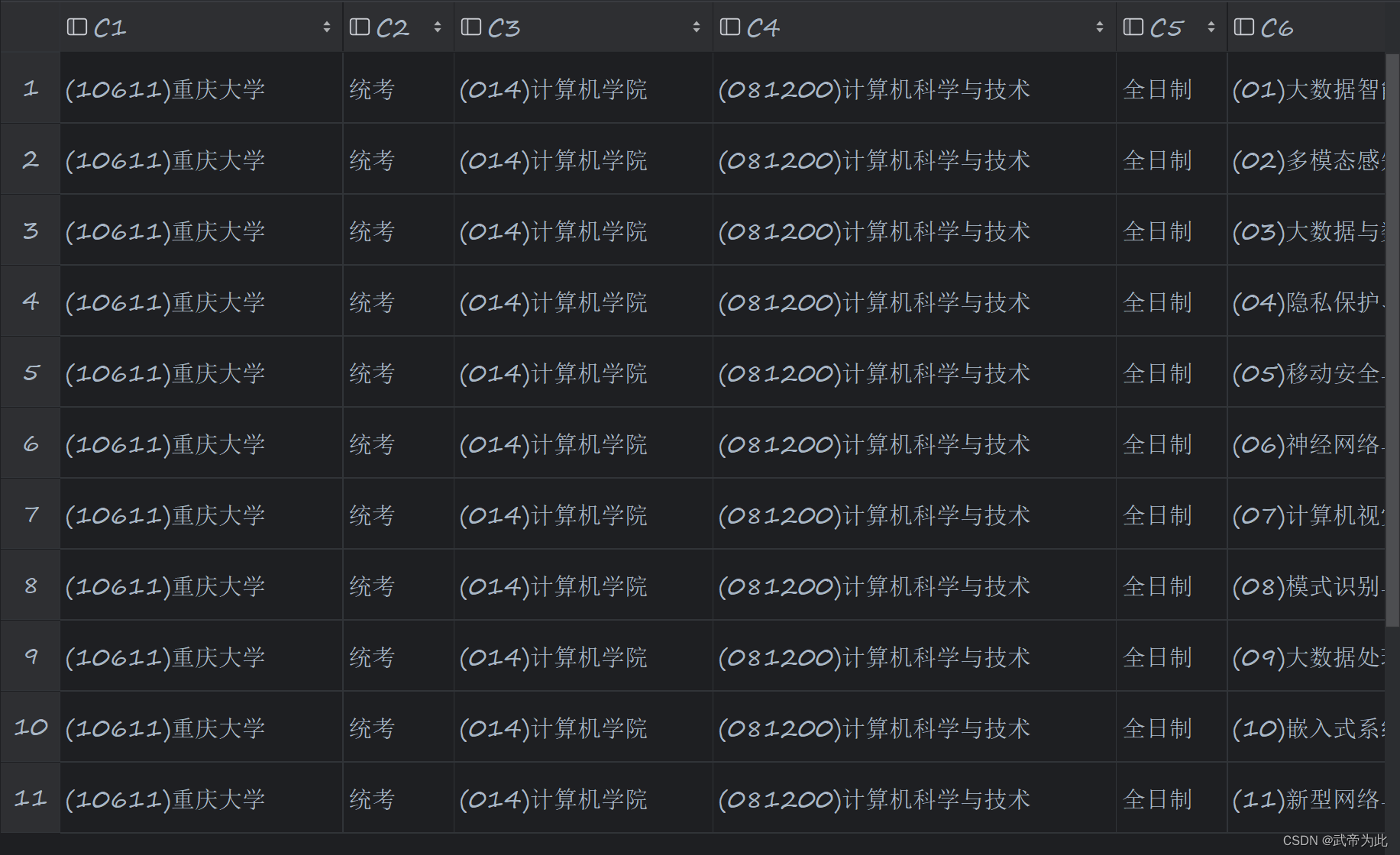
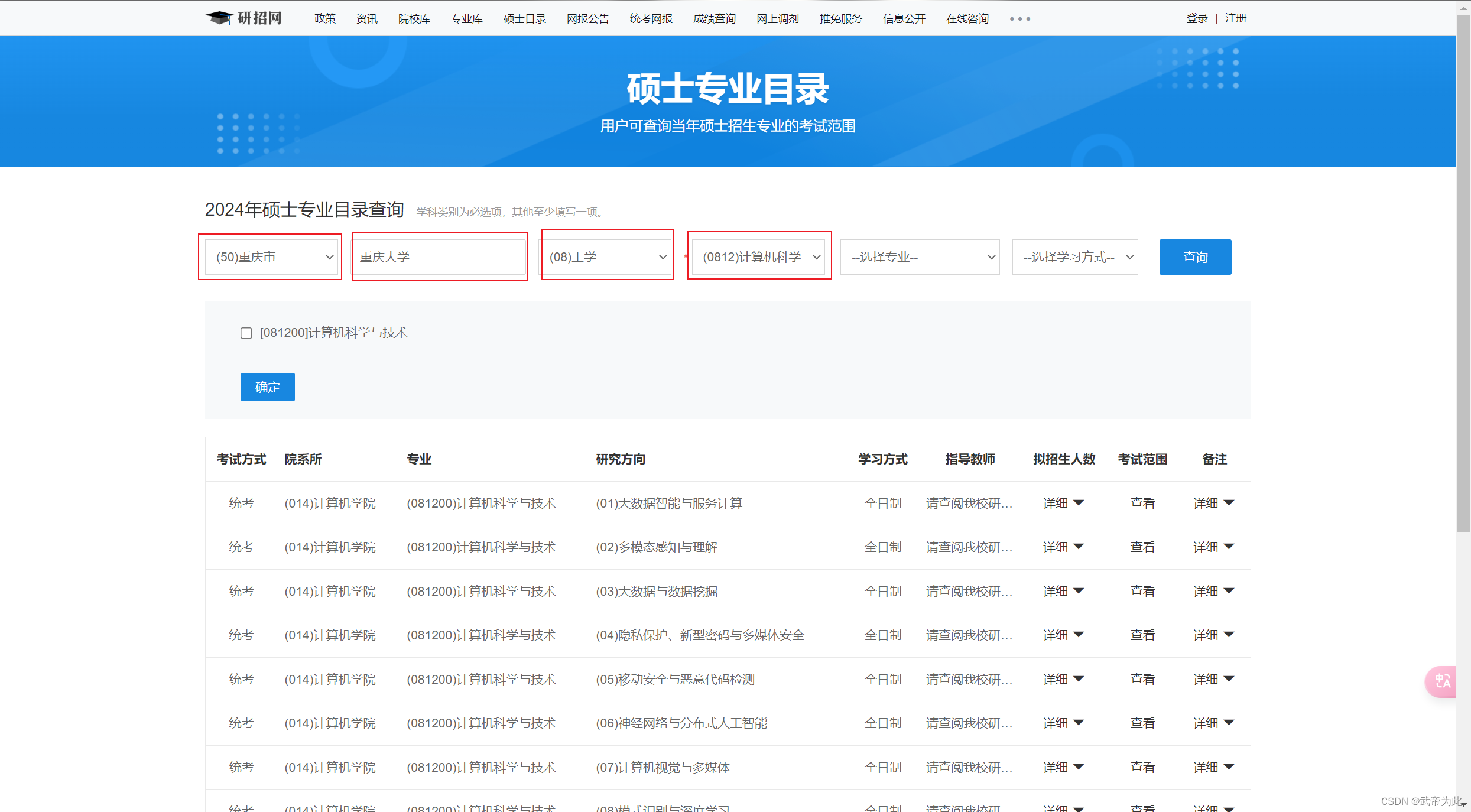
示例
输入内容:
https://yz.chsi.com.cn/zsml/querySchAction.do?ssdm=50&dwmc=%E9%87%8D%E5%BA%86%E5%A4%A7%E5%AD%A6&mldm=08&mlmc=&yjxkdm=0812&xxfs=&zymc=
文件内容: