文章目录
- 一、前言
- 二、语法对比
- 数据表
- concat(多列合并为一列)
- group_concat(多行合并为一行)
- 一列拆分为多列
- 一行拆分为多行
- 多行转为多列
- 多列转为多行
- 三、小结
一、前言
环境:
windows11 64位
Python3.9
MySQL8
pandas1.4.2
本文主要介绍行列转换几个常见的行列转换问题在 Python 和 MySQL 的实现及语法对比,包含了:多列合并为一列、多行合并为一行、一列拆分为多列、一行拆分为多行、多行转多列、多列转多行。
注:Python是很灵活的语言,达成同一个目标或有多种途径,我提供的只是其中一种解决方法,大家有其他的方法也欢迎留言讨论。
二、语法对比
数据表
本次使用的数据如下。
使用 Python 构建该数据集的语法如下:
import pandas as pd
import numpy as np
df1 = pd.DataFrame({ 'col1' : list(range(1,7))
,'col2' : ['AA','AA','AA','BB','BB','BB']#list('AABCA')
,'col3' : ['X',np.nan,'Da','Xi','Xa','xa']
,'col4' : [10,5,3,5,2,None]
,'col5' : [90,60,60,80,50,50]
,'col6' : ['Abc','Abc','bbb','Cac','Abc','bbb']
})
df2 = pd.DataFrame({'col2':['AA','BB','CC'],'col7':[1,2,3],'col4':[5,6,7]})
df3 = pd.DataFrame({'col2':['AA','DD','CC'],'col8':[5,7,9],'col9':['abc,bcd,fgh','rst,xyy,ijk','nml,opq,wer']})
注:直接将代码放 jupyter 的 cell 跑即可。后文都直接使用
df1、df2、df3调用对应的数据。(注意,该数据集 df3 和上一节不同)
使用 MySQL 构建该数据集的语法如下:
with t1 as(
select 1 as col1, 'AA' as col2, 'X' as col3, 10.0 as col4, 90 as col5, 'Abc' as col6 union all
select 2 as col1, 'AA' as col2, null as col3, 5.0 as col4, 60 as col5, 'Abc' as col6 union all
select 3 as col1, 'AA' as col2, 'Da' as col3, 3.0 as col4, 60 as col5, 'bbb' as col6 union all
select 4 as col1, 'BB' as col2, 'Xi' as col3, 5.0 as col4, 80 as col5, 'Cac' as col6 union all
select 5 as col1, 'BB' as col2, 'Xa' as col3, 2.0 as col4, 50 as col5, 'Abc' as col6 union all
select 6 as col1, 'BB' as col2, 'xa' as col3, null as col4, 50 as col5, 'bbb' as col6
)
,t2 as(
select 'AA' as col2, 1 as col7, 5 as col4 union all
select 'BB' as col2, 2 as col7, 6 as col4 union all
select 'CC' as col2, 3 as col7, 7 as col4
)
,t3 as(
select 'AA' as col2, 5 as col8, 'abc,bcd,fgh' as col9 union all
select 'DD' as col2, 7 as col8, 'rst,xyy,ijk' as col9 union all
select 'CC' as col2, 9 as col8, 'nml,opq,wer' as col9
)
select * from t1;
注:直接将代码放 MySQL 代码运行框跑即可。后文跑 SQL 代码时,默认带上数据集(代码的1~18行),仅展示查询语句,如第19行。(注意,该数据集 t3 和上一节不同,多了
col9列)
对应关系如下:
| Python 数据集 | MySQL 数据集 |
|---|---|
| df1 | t1 |
| df2 | t2 |
| df3 | t3 |
concat(多列合并为一列)
MySQL 使用concat()可以将多列拼接为一列,除了该函数,还有concat_ws(),二者的用法和返回的结果有一些不同。concat()是将所有需要拼接的字段或字符用逗号隔开放到括号里,而concat_ws()需要指定分隔符,统一使用该分隔符对数据进行分割,具体看以下例子。
两个非空字段拼接-concat/concat_ws
当 MySQL 的字段都是非空时,concat()和concat_ws()如果使用相同的分隔符,结果一致。
在 Python 中,可以使用+、apply()+lambda或str.cat()等方法实现相同的结果。
需要注意的是,MySQL 会对数值字段col5进行隐式转换为字符串,然后进行拼接,而 Python 不能,需要手动进行转化,可以使用astype()或map()等进行转化。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | 【Python1】 df1_1 = df1.copy() df1_1[‘col5’] = df1_1.col5.astype(‘str’) df1_1.col2+‘‘+df1_1.col5 【Python2】 df1_1 = df1.copy() df1_1[‘col5’] = df1_1.col5.astype(‘str’) df1_1.apply(lambda x:x.col2+’’+x.col5,axis=1) 【Python3】 df1_1 = df1.copy() df1_1[‘col5’] = df1_1.col5.astype(‘str’) df1_1.col2.str.cat(df1_1.col5,sep=‘_’) | 【MySQL1】 select concat(col2,‘‘,col5)as col9 from t1; 【MySQL2】 select concat_ws(’’,col2,col5)as col9 from t1; |
| 结果 |  |  |
多个字段(含空值)拼接-concat/concat_ws
当字段含有空值时,concat()返回null,而concat_ws()返回非空值部分的拼接。
使用两个非空值字段的三个方法(如下)结果也有所差异,使用+和str.cat()的结果都是返回null(如下【Python1】和【Python2】),使用apply()+lambda则将空值处理为nan,全部字段拼接起来(如下【Python3】)。
【Python1】和【Python2】实现了concat()的效果,但是【Python3】和concat_ws()不完全等同。如果要实现concat_ws()的效果,可以在【Python3】的基础上加一步替换值的处理,如【Python4】,加上.apply(lambda x:x.replace('_nan',''))将_nan替换为空字符串。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | 【Python1】 df1_1 = df1.copy() df1_1[‘col5’] = df1_1.col5.astype(‘str’) df1_1.col2+‘‘+df1_1.col5+’’+df1_1.col3 【Python2】 df1_1 = df1.copy() df1_1[‘col5’] = df1_1.col5.astype(‘str’) df1_1.col2.str.cat([df1_1.col5,df1_1.col3],sep=‘‘) 【Python3】 df1_1 = df1.copy() df1_1[‘col5’] = df1_1.col5.astype(‘str’) df1_1[‘col3’] = df1_1.col3.astype(‘str’) df1_1.apply(lambda x:x.col2+’’+x.col5+‘‘+x.col3,axis=1) 【Python4】 df1_1 = df1.copy() df1_1[‘col5’] = df1_1.col5.astype(‘str’) df1_1[‘col3’] = df1_1.col3.astype(‘str’) df1_1.apply(lambda x:x.col2+’’+x.col5+‘_’+x.col3,axis=1)\ .apply(lambda x:x.replace(‘_nan’,‘’)) | select concat(col2,‘‘,col5,’’,col3) f_concat,concat_ws(‘_’,col2,col5,col3) f_concat_ws from t1; |
| 结果 | 【Python1和Python2结果】 【Python3结果】  【Python4结果】  | 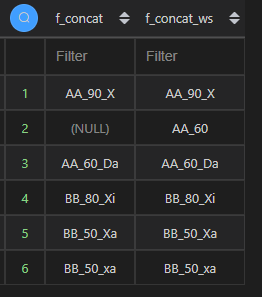 |
group_concat(多行合并为一行)
MySQL 的group_concat()函数一般用于将多行数据聚合为一行数据。在聚合的过程中,涉及到几种不同的情况,下面逐一看看。
单字段(字符串)聚合,无排序
注意这里有几个限定条件,必须是字符串字段。Python 里没有隐式转换,如果非字符串,需要转化数据类型。转化方式参考concat(),使用astype()进行转化。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | 【Python1】 df2 = df1.groupby(‘col2’).apply(lambda x:‘,’.join(x.col6)).reset_index().rename(columns={0:‘col6’}) df2 【Python2】 df1.groupby(“col2”).agg({“col6”: lambda x: ‘,’.join(x)}).reset_index() | select col2,group_concat(col6 separator ‘,’) col6 from t1 group by col2; |
| 结果 |  |  |
聚合和排序为同一字段
当有排序时,不管聚合字段和排序字段是不是同个字段,在 MySQL 中加一个 order by 子句加上字段即可。
不过在 Python 的实现上二者有一些差异,同一字段时,可以在聚合的时候对列字段进行排序(如下 Python 代码)。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1.groupby(“col2”).agg({“col6”: lambda x: ‘,’.join(sorted(x, reverse=True))}).reset_index() | select col2,group_concat(col6 order by col6 desc separator ‘,’) col6 from t1 group by col2; |
| 结果 |  | 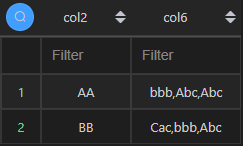 |
聚合和排序为不同字段
当聚合字段和排序字段为不同字段时,就不可以使用上面的方法实现了,需要提前对数据排好序,再进行聚合(如下 Python 代码)。其实该语法通用性较好,同一字段也可以使用该语法,改一下排序的字段即可。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1.sort_values(by=[‘col5’],ascending=False).groupby(“col2”).agg({“col6”: lambda x: ‘,’.join(x)}).reset_index() # 先排序,再聚合。第二排序默认index | select col2,group_concat(col6 order by col5 desc separator ‘,’) col6 from t1 group by col2; |
| 结果 |  | 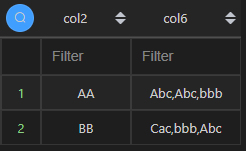 |
去重聚合,聚合和排序必须为同一字段
去重聚合在 Python 中,可以看作是去重+同字段聚合排序的集合体,先去重,然后根据同一字段聚合排序的逻辑聚合起来。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | 【Python1】 df1[[‘col2’,‘col6’]].drop_duplicates().sort_values(by=[‘col6’],ascending=False).groupby(“col2”).agg({“col6”: lambda x: ‘,’.join(x)}).reset_index() 【Python2】 df1.sort_values(by=[‘col6’],ascending=False).groupby(“col2”).agg({‘col6’:‘unique’}).agg({“col6”: lambda x: ‘,’.join(x)}).reset_index() 【Python3】 df1.sort_values(by=[‘col6’],ascending=False).groupby(“col2”).agg({‘col6’:‘unique’})[‘col6’].apply(lambda x:‘,’.join(x)).reset_index() | select col2,group_concat(distinct col6 order by col6 desc separator ‘,’) col6 from t1 group by col2; |
| 结果 |  | 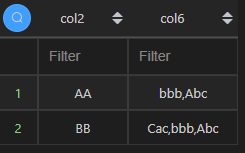 |
多字段拼接并聚合
多字段拼接并聚合本质上就是使用concat()+group_concat() 进行实现。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1_1 = df1.copy() df1_1[‘col5’] = df1_1.col5.astype(‘str’) df1_1.groupby(‘col2’).apply(lambda x:‘,’.join(x.col6+‘_’+x.col5)).reset_index().rename(columns={0:‘col6’}) | select col2,group_concat(concat(col6,‘_’,col5) order by col6 separator ‘,’) col6 from t1 group by col2; |
| 结果 |  | 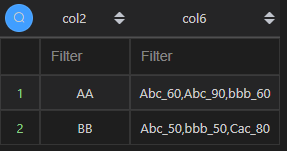 |
一列拆分为多列
一列拆为多列,一般是在某一列有某些特征明显的数据规律,然后通过这些规律将数据拆开,变成多个列。在 MySQL 中,像t3.col9是有多个值通过逗号连在一起,这时候可以通过substring_index()识别逗号进行拆分(如下 MySQL 代码)。
在 Python 中,可以直接使用apply(pd.Series,index=['col_1','col_2','col_3'])实现对应的效果,然后再用pandas.concat()把需求字段拼接返回,如下【Python1】。当然,也可以使用类似 MySQL 的逻辑,分别处理每一个列,将df3.col9使用str.split()拆分开,然后通过索引分别取值,如下【Python2】
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | 【Python1】 df1_1 = df3.col9.apply(lambda x:x.split(‘,’)).apply(pd.Series,index=[‘col_1’,‘col_2’,‘col_3’]) pd.concat([df3.col2,df1_1],axis=1) 【Python2】 df3_1 = df3.copy() df3_1[‘col_1’]=df3.col9.map(lambda x:x.split(‘,’)[0]) df3_1[‘col_2’]=df3.col9.map(lambda x:x.split(‘,’)[1]) df3_1[‘col_3’]=df3.col9.map(lambda x:x.split(‘,’)[2]) df3_1[[‘col2’,‘col_1’,‘col_2’,‘col_3’]] | select col2,substring_index(col9,‘,’,1)col_1,substring_index(substring_index(col9,‘,’,-1),‘,’,-1)col_2,substring_index(col9,‘,’,-1)col_3 from t3; |
| 结果 | 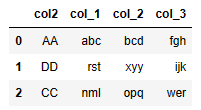 | 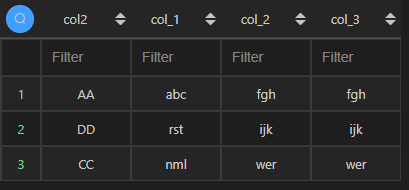 |
一行拆分为多行
一行拆分多行和一列拆分多列从字面上看都是一变多的逻辑,不过实现过程大不同。在 MySQL 中,需要借助一个连续增加的列来实现增加行的效果,然后针对每一行再对拆分后的字段进行取舍,如下 MySQL 代码。
在 Python 中,有一个专门将列表数据沿行向展开接口:pandas.explode()。只要将目标列的数据处理成列表的结构,便可直接使用它进行转化,如下 Python 代码。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | pd.concat([df3.col2,df3.col9.apply(lambda x:x.split(‘,’))],axis=1).explode(“col9”) | select t3.col2,substring_index(substring_index(t3.col9,‘,’,t1.col1),‘,’,-1) col9 from t3 join t1 on t1.col1<=length(t3.col9)-length(replace(t3.col9,‘,’,‘’))+1 |
| 结果 |  | 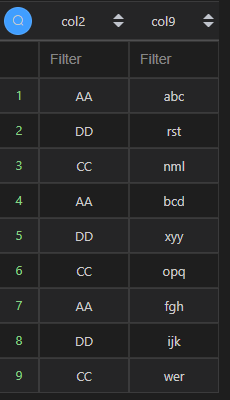 |
多行转为多列
多行转多列,在 MySQL 中,通常是通过max(case when)+group by实现,具体语法如下 MySQL 代码。
在 Python 中,则可以使用透视表方法pivot_table()实现。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | pd.pivot_table(df1, values=‘col5’, index=[‘col6’],columns=[‘col2’], aggfunc=np.max).reset_index() | select col6,max(case when col2=‘AA’ then col5 end) “AA”,max(case when col2=‘BB’ then col5 end) “BB” from t1 group by col6; |
| 结果 | 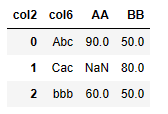 | 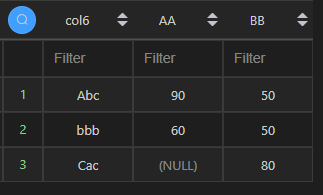 |
多列转为多行
多列转多行,在 MySQL 中,其实就是将多列合并为一列,再通过一行转多行实现,即多列转为多行=多列转一列+一行拆分为多行(参考上文和以下 MySQL 代码)。
而 Python 中,有更多的实现方法,如下【Python1】,通过melt()方法便可直接将列值拍平,降维返回。如下【Python2】,通过stack()也可以实现相同的效果。二者不同点在于stack()是对所有的字段进行操作,所以需要把要保留的字段设置为索引,并只取需要拍平的列进行操作,而melt()更简便,直接指定对应的字段即可。
除了这两种方法,还可以使用和 MySQL 代码相同的逻辑,通过先拼接列再拆分行进行处理(如下【Python3】)
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | 【Python1】 df2.melt(id_vars=[‘col2’], value_vars=[‘col4’, ‘col7’],var_name=‘指标’, value_name=‘指标值’) # ignore_index=False不重置索引,默认重置 【Python2】 df2.set_index(‘col2’).stack().reset_index().rename(columns={‘level_1’:‘指标’,0:‘指标值’}) 【Python3】 df2_1 = df2.copy() df2_1[‘col4’] = df2_1.col4.astype(‘str’) df2_1[‘col7’] = df2_1.col7.astype(‘str’) df2_target = pd.concat([df2_1.col2,pd.Series([‘col4,col7’]*3).apply(lambda x:x.split(‘,’))],axis=1).explode(0).rename(columns={‘col2’:‘col’,0:‘指标’}) df2_value = pd.concat([df2_1.col2,df2_1.apply(lambda x:x.col4+‘,’+x.col7,axis=1).apply(lambda x:x.split(‘,’))],axis=1).explode(0).rename(columns={0:‘指标值’}) pd.concat([df2_target,df2_value],axis=1)[[‘col2’,‘指标’,‘指标值’]] | select t2.col2,if(t1.col1=1,‘col4’,‘col7’) “指标”,substring_index(substring_index(concat(t2.col4,‘,’,t2.col7),‘,’,t1.col1),‘,’,-1) “指标值” from t2 join t1 on t1.col1<=2 |
| 结果 | 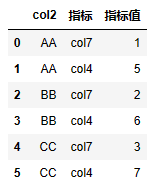 | 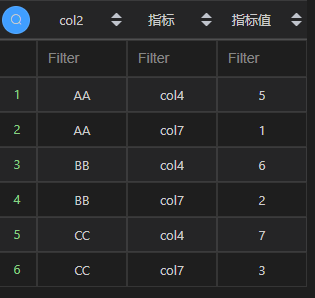 |
三、小结
MySQL 和 Python 在处理行列转化时,灵活性都很强。二者相比较之下,Python 会略胜一筹,它提供更多的接口,可以辅助我们更加灵活地处理数据,实现预期效果。不过,MySQL 相对会更简洁一些,格式比较统一,语法也比较简单。










![LeetCode[295]数据流的中位数](https://img-blog.csdnimg.cn/img_convert/def2872e75a34ee9a738fabbf5603e7d.png)




