论文:WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia
⭐⭐⭐⭐
Stanford University, EMNLP 2023
相关地址:
- demo 体验地址
- Code
- Huggingface 模型
文章目录
- 论文速读
- 模型 demo
- 一些其他的细节
- 1)WikiChat 的通用性
- 2)模型蒸馏
- 3)文本索引阶段
- 4)检索召回阶段
- 总结
- 摘抄
这篇论文的题目具有一定争议性,尽管论文题目说“Stopping the Hallucination”,但在实际体验时仍然会存在很多幻觉。但本文提出的思路确实也提高了 LLM 回答的事实准确性,其思路值得学习。
论文速读
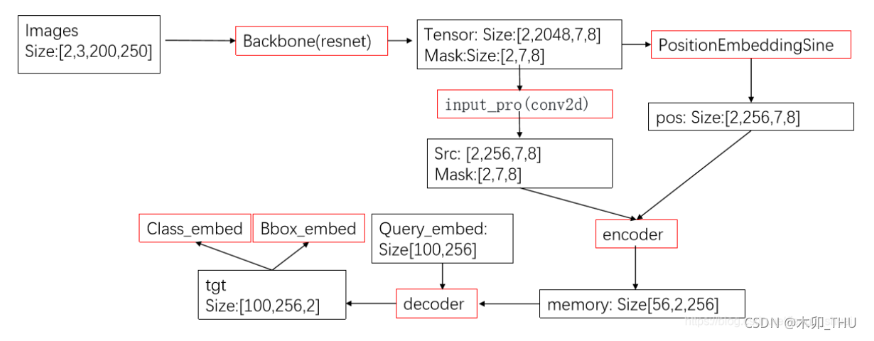
WikiChat 在想生成用户问题时,会经过 7 个过程来生成最终的答案,如下图所示:
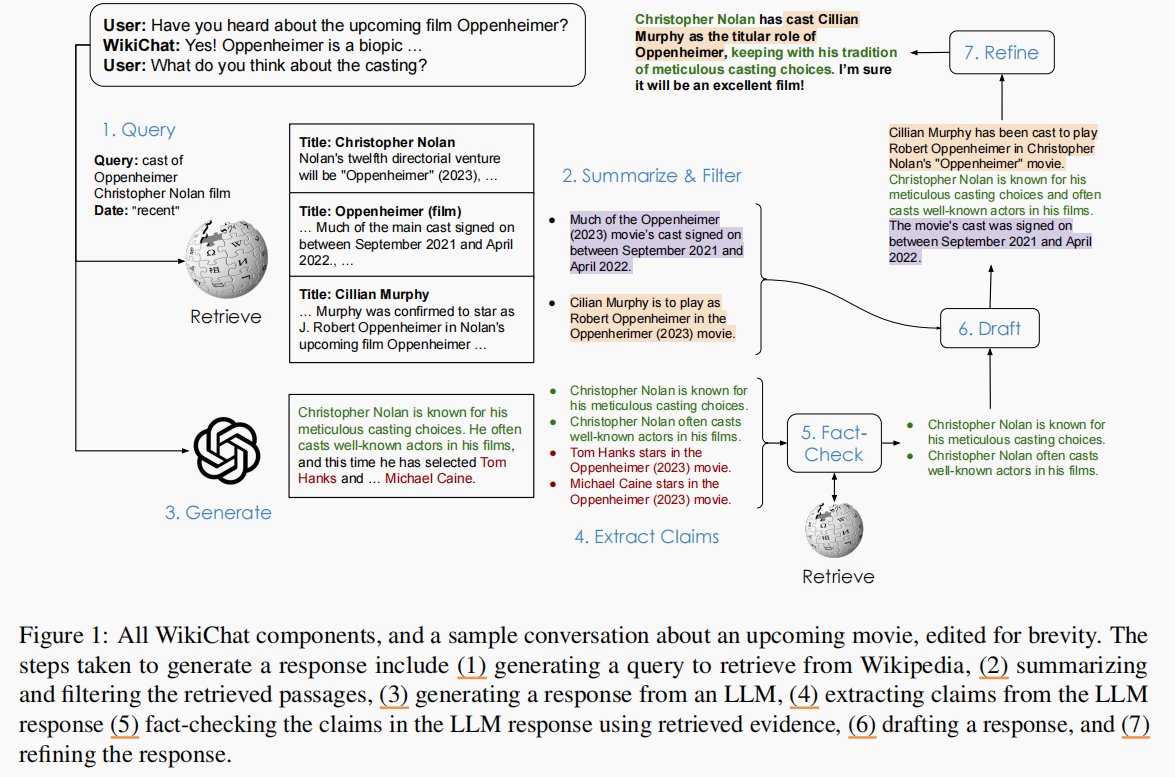
这 7 个步骤形成一个 RAG pipeline,其中每一步都专门设计了对应的 prompt 来实现相关的目的:
- step 1 - Query:WikiChat 会根据用户的问题生成一个用于检索 Wikipedia 的 search query,并交由 retriever 检索出
N
I
R
N_{IR}
NIR 个 passages。另外这个 search query 中会带上推断出的用户需求的查询时间,这个查询时间可以是
recent、year=xxxx或者none,这个查询时间可用于辅助检索文档 - step 2 - Summarize & Filter:从检索到的 passages 中过滤掉不相关的部分,抽取出有用的章节,并将它们总结为多个要点。
- step 3 - Generate:提示 LLM 让它生成对话历史的 response。
- step 4 - Extract Claims:将 LLM 的 response 拆分为多个 claim,并使用 IR(Information Retrieve)从知识库中为每个 claim 检索出 N e v i d e n c e N_{evidence} Nevidence 个 passages 作为 证据。
- step 5 - Fact Check:过滤掉没有证据支持的 claim。这里在具体操作时会使用 CoT。
- step 6 - Draft:根据前面得到的要点清单和对话历史生成 response 的草稿(draft)
- step 7 - Refine:LLM 根据我们期望的 relevance、naturalness、non-repetitiveness 以及 temporal correctness 等多个指标来对 draft 生成反馈,并进一步完善 draft,得到最终的 response。另外,由于 LLM 很难说“I don’t know”,所以这里规定当 stage 1-5 这个 curation stage 没有返回到相关信息的特殊情况下,会跳过 draft 的生成,并直接向最后一个阶段发送一个 “Sorry, I’m not sure”。
其中, N e c u d e n c e = 2 N_{ecudence} = 2 Necudence=2, N I R = 3 N_{IR}=3 NIR=3,这是一个经验参数,为了在 development set 上获得更高的 recall。
模型 demo
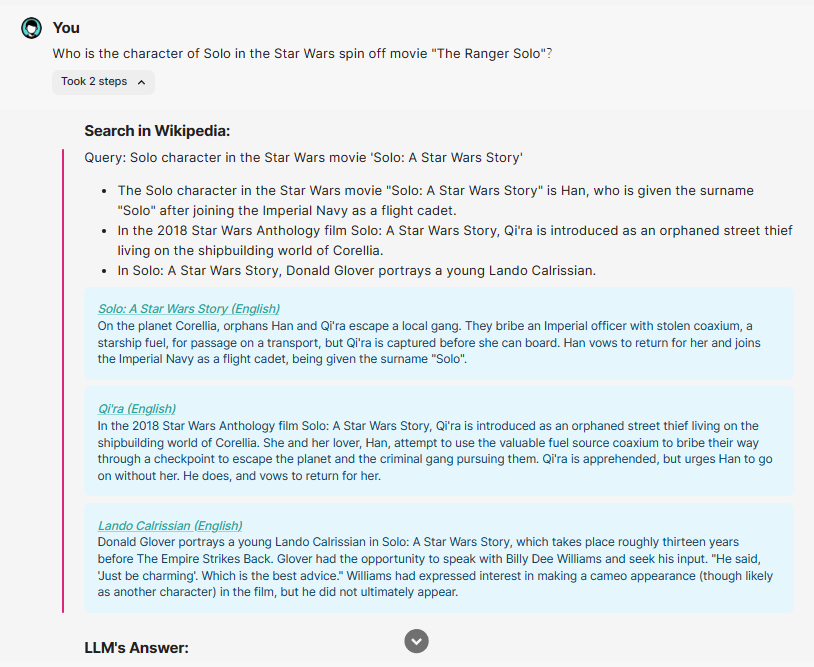
在上图中,是原论文演示了询问最近上映的电影 奥本海默 时 WikiChat 的 7 个过程所做的具体事情。下面,我们看一下在实际运行的 WikiChat 中,问出一个问题后会有怎样的回复。这里,我们问它关于星球大战系列电影的外传《游侠索罗》的主角 Solo 的扮演者,在问题中,我们故意说错了电影名,而是用了一个同义表达,看看 WikiChat 是如何应对的:

可以看到,它成功回答了这个问题,主角 Solo 的扮演者是 Alden Ehrenreich,而且它意识到了电影名称的错误。在这里,我们可以展开看看 WikiChat 的中间处理过程:
- WikiChat 首先在 Wikipedia 中进行检索,得到多个 passages:
- LLM 的原生 answer 以及从中抽取出来的 claims:
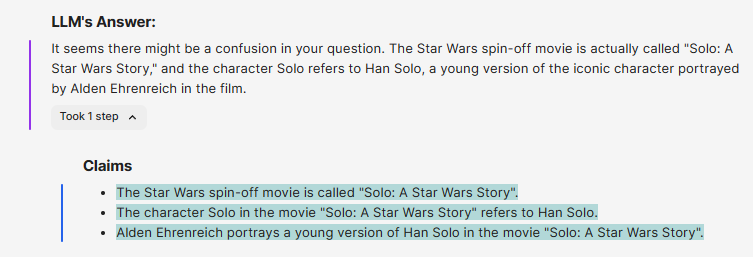
这契合了论文提到的 WikiChat 的 RAG pipeline。
一些其他的细节
1)WikiChat 的通用性
WikiChat 的构建思路是具有通用性的:
- 这里的知识库不局限于 Wikipedia,它可以是本地私有知识库
- 使用的 LLM 不局限于特定的 LLM
2)模型蒸馏
以上我们介绍的过程是使用 ChatGPT 或 GPT 来完成的,但当我们部署时,为了降低模型运行的延迟和代价,同时为了本地部署时数据的私密性,我们进行了模型蒸馏,得到了一个较小的基于 LLaMA 的语言模型来实现 WikiChat 的问答。
具体的做法就是:让 WikiChat based on GPT-4 作为 teacher model,让公开可用的 LLaMA 作为 student model,去进行模型蒸馏。我们让一个 user simulator 去与 teacher model 使用 instruction 和多个 examples 进行对话,得到一堆 input-output paris,然后拿这些 instruction 和 input-output pairs 去微调 student LLM,让 LLaMA-based WikiChat 能够执行 pipeline 中各个 stages 的特定任务。
在具体数据上,本工作总共从 750 篇 Wikipedia 的文章中获得训练数据,一个 user simulator 与 GPT-4 针对每个 topic 进行 10 轮 QA 对话,共产生 37499 个 (instruction, input, output) pairs 作为微调数据对,用于对 LLaMA 进行微调。
根据实验,蒸馏后的 LLaMA-based WikiChat 可以达到 GPT4-based WikiChat 的 91% 的事实准确率,而且在延迟和消耗代价上低了很多很多。
3)文本索引阶段
在文本索引方面,使用 WikiExtractor 工具(https://github.com/attardi/wikiextractor) 从2023年4月28日获得的英文维基百科转储中提取纯文本,与ColBERT一样,将每篇文章(忽略表格和信息框)划分为不同的文本块作为段落,并在段落前加上文章标题,将段落和标题的总长度限制在120字以内。
4)检索召回阶段
在检索召回方面,在维基百科上使用 ColBERTv2(https://github.com/stanford-futuredata/ColBERT/) 和 PLAID(https://arxiv.org/abs/2205.09707) 作为检索工具。
总结
WikiChat 的七步 RAG pipeline 的思想,在每一步都设计对应的 prompt 是实现的关键。
它在整个 RAG 流程中,主要强化的是召回内容的后处理阶段,整体会很慢,所以为了改善延迟、成本和隐私,本工作使用对 GPT4-based 进行模型蒸馏得到一个 LLaMA-based WikiChat。
摘抄
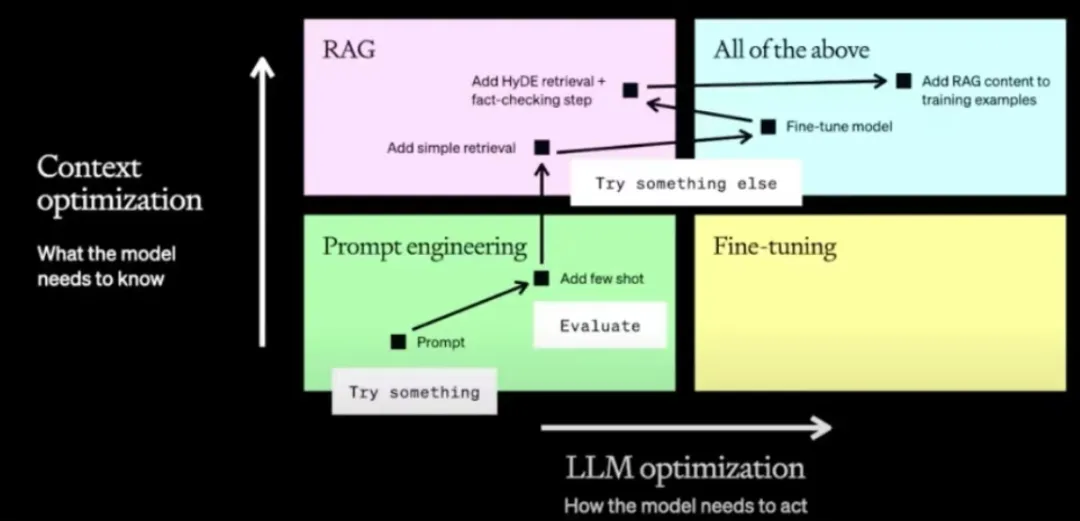
另外,觉得刘老师的下面这段话很有启发,在此摘抄:
RAG这条路,跟prompt工程,ICL有很紧密的联系,下面这张图很清晰地描述了当前大模型回复的优化路线。
先写个prompt,效果不行,加fewshot,然后出现了一堆怎么选fewshot的工作。
fewshot效果也不够,那就借助外部知识,简单做个搜索,结果还不好,那就再加上微调一把。
微调难免会有错误,对召回的处理不够好,这个时候再做下事实性验证,比如rethink,self critique。
这样可能效果还不好,那么,就对齐下任务,把RAG的过程加到微调里,最终将RAG,微调。prompt工程融为一体。
参考文章:
- https://mp.weixin.qq.com/s/UsZy6TdnUaqQ3PtSq6F4yA
- https://baijiahao.baidu.com/s?id=1787053518998130102

![[StartingPoint][Tier2]Base](https://img-blog.csdnimg.cn/img_convert/792e2e325c957c4b39a88568d45ddfcf.jpeg)





![[Meachines][Easy]Devvortex](https://img-blog.csdnimg.cn/img_convert/6caf72b10e8042863400dc0aba60b624.jpeg)