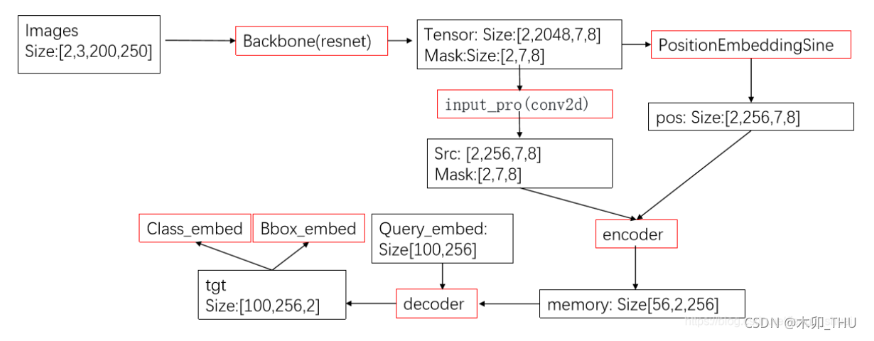
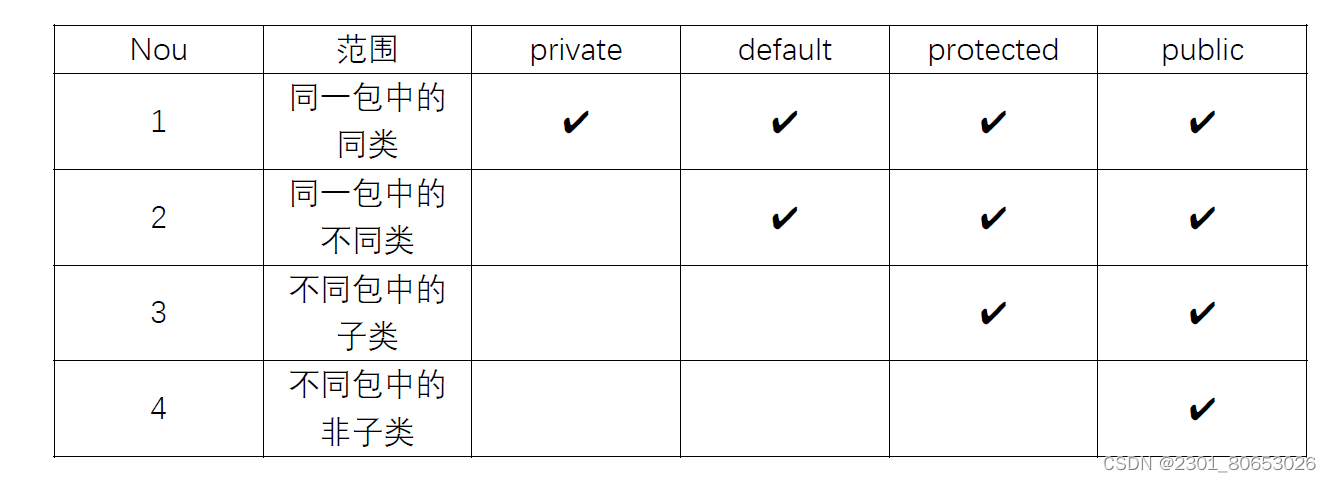
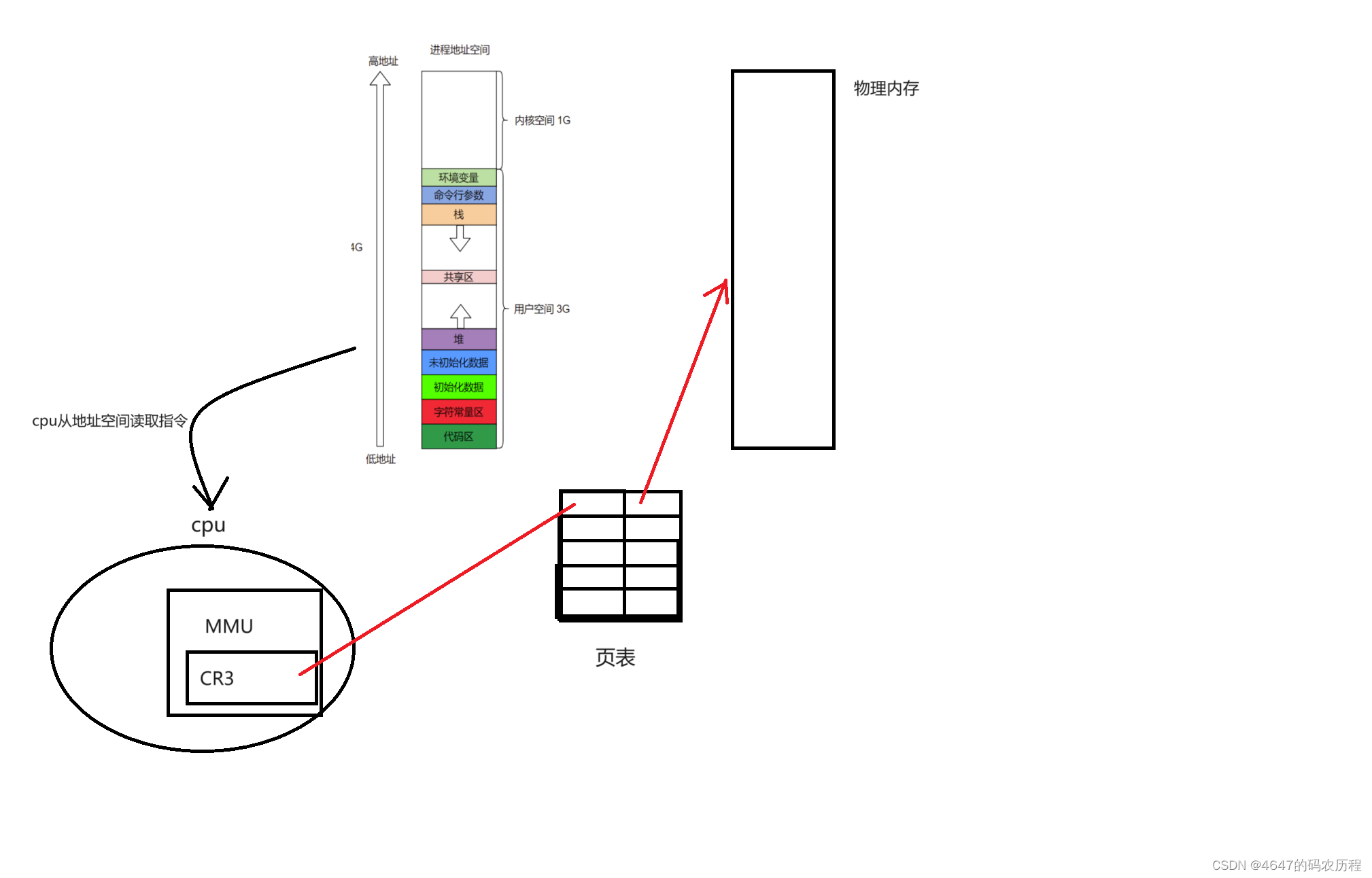
0 介绍
NLP任务最初,就是在于如何处理文本。无论从TFIDF到word2Vec的过程,还是BERT都是想找到文本的向量表达,如何表示更好处理我们的下游任务。那么,这个过程是如何做的呢,本文主要就是介绍这一个过程,还是代码为主,你要知道所有的大模型都干了这个。
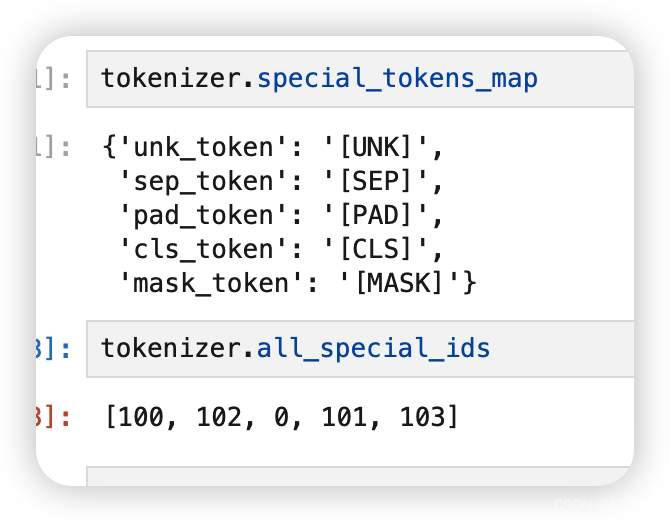
面对这么多的字,以及字之间的组合这是一个指数级别的增长。再者现在的网络文化无时无刻不再增加新的词汇,“提灯定损”,你懂的!VOF。那么模型具有一定的延时性,不可能包好所有的词,一个典型的没见过的用一个统一的符号代表。引入新的特殊含义字符:
tokenizer.special_tokens_map:
1 简单分词
from transformers import AutoTokenizer
sen = "欲买桂花同载酒,终不似少年游!"
# 从HuggingFace加载,输入模型名称,即可加载对于的分词器
tokenizer = AutoTokenizer.from_pretrained("./dianping")
tokens = tokenizer.tokenize(sen)
tokens
['欲', '买', '桂', '花', '同', '载', '酒', ',', '终', '不', '似', '少', '年', '游', '!']
inputs = tokenizer.encode_plus(sen, padding="max_length", max_length=25)
inputs{'input_ids': [101, 3617, 743, 3424, 5709, 1398, 6770, 6983, 8024, 5303, 679, 849, 2208, 2399, 3952, 106, 102, 0, 0, 0, 0, 0, 0, 0, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]}
input_ids:词索引;
token_type_ids: 第一个句子的索引;
attention_mask: 词索引掩码,用于指示模型在处理输入序列时应该关注哪些部分。位置是0的不需要关注,因为是填充值。
现在大概知道了训练的时候,需要喂给模型什么了。
✊坚持住。





![[Meachines][Easy]Devvortex](https://img-blog.csdnimg.cn/img_convert/6caf72b10e8042863400dc0aba60b624.jpeg)