every blog every motto: You can do more than you think.
https://blog.csdn.net/weixin_39190382?type=blog
0. 前言
detr
detr
1. 引言
论文: https://arxiv.org/pdf/2005.12872v3.pdf
时间: 2020.5.26
作者: Nicolas Carion?, Francisco Massa?, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko Facebook AI
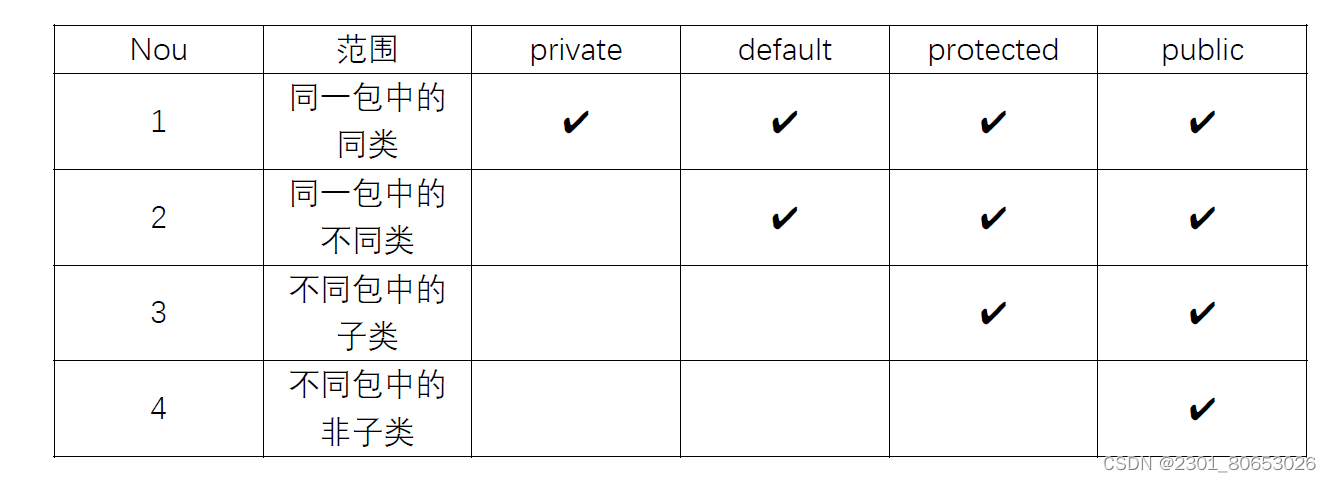
最大的特点是不需要预定义anchor,也不需要NMS,就可以实现端到端的目标检测。
在大目标上检测性能较好,而小目标较差。
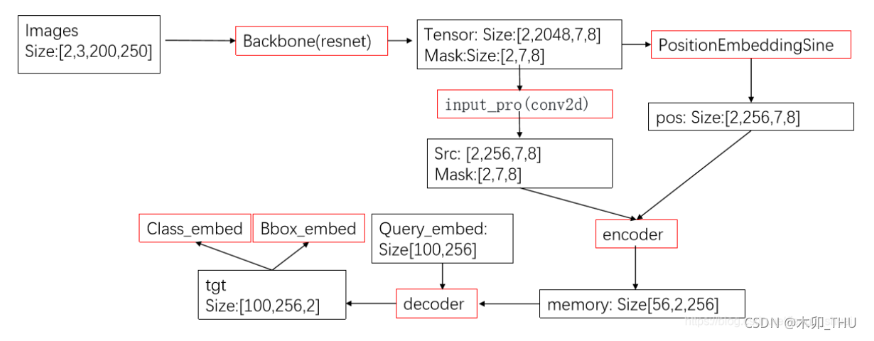
2. 整体结构
整体结构如下
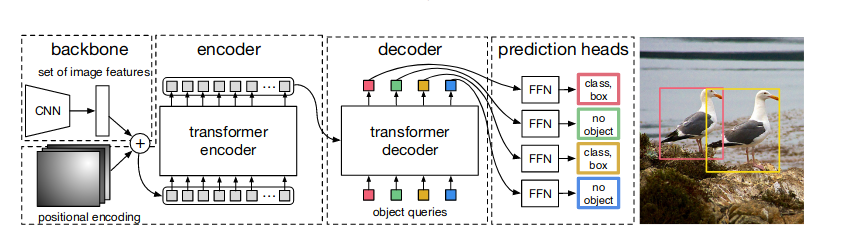
目标检测的图片一般都比较大,直接用Transformer计算量比较大,在SWin出现之前一般都是用CNN进行特征提取和尺寸缩放。
主要分三部分:
- backbone
- transformer
- head
3. Backbone
主要是使用resnet50作为backbone,特征图进行了缩小,即(h/32,w/32)
其中还有一个位置编码,计算x和y方向的位置编码。位置编码长度为256,前128代表y方向,后128代表x方向。
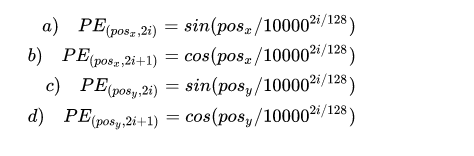
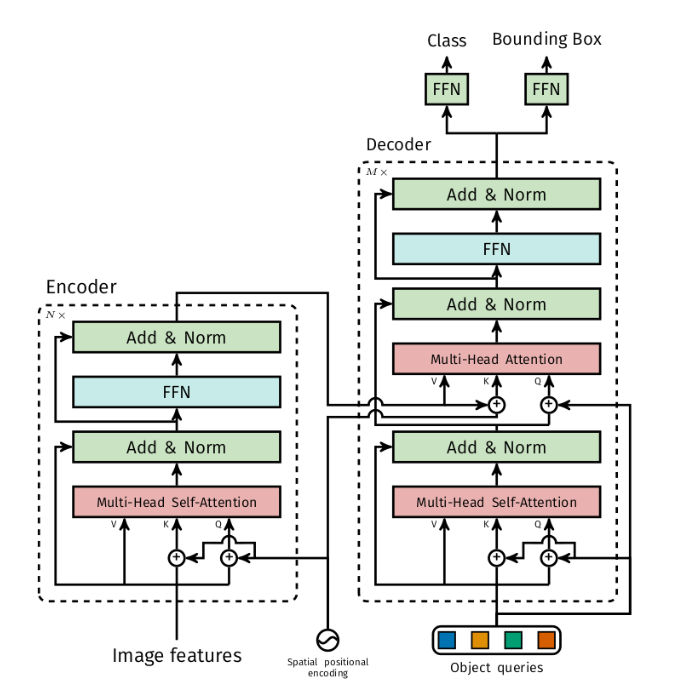
4. Transformer
网络结构图如下:
4.1 关于输入shape
其中的输入shape变化: (b,c,h,w) -> (b,c,hw) -> (hw,b,c)
其中c是通道,表示token的维度,b为batch,表示token的个数,
按照参考文献所说,将像素作为一个token,但这种shape应该不是单个像素作为token。
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1)
而vit中的shape变化:(b,c,h,w) -> (b,c,hw) -> (b,hw,c),
这样的shape应该是单个像素作为一个token。
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
x = self.proj(x).flatten(2).transpose(1, 2)
4.2 关于Encoder位置编码
在Encoder部分,输入都加入了位置编码,并且只对q和k使用。
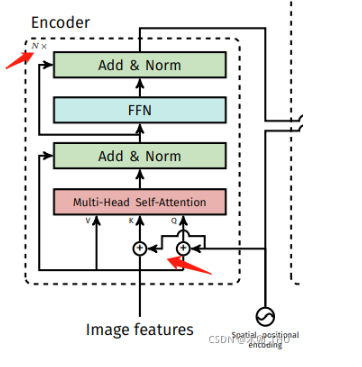
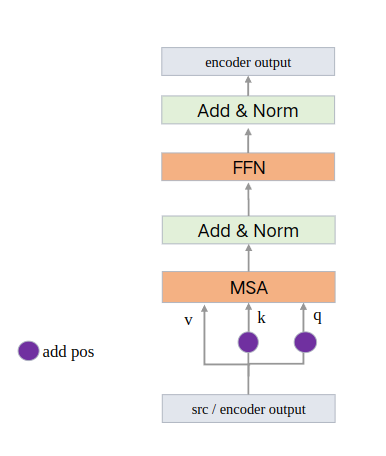
更清晰的图:
4.3 关于Decoder
4.3.1 理解1
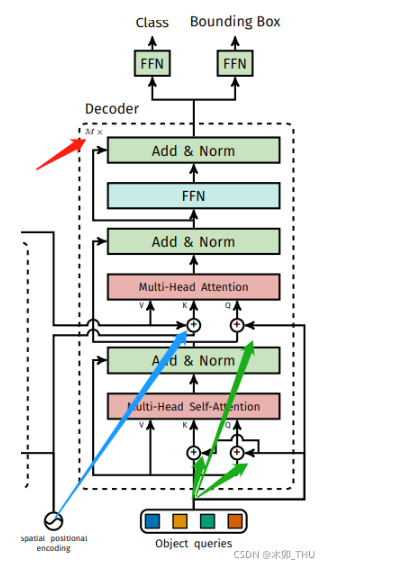
Decoder包含多个DecoderLayer串联,而每个DecoderLayer中又包含两个串联的MultiheadAttention。
从Transformer局部代码中我们得到:
- tgt:全0向量
- memory:encoder的输出
DecoderLayer的输入:
- tgt:第一个Decoder中该变量为为全0向量,后续该变量为上个Decoder的输出
- memory:一直为encoder最后的输出。
-
对于Decoder中第一个MultiheadAttention
- q: tgt,加上query_pos
- k: tgt,加上query_pos
- v: tgt
-
对于Decoder中第二个MultiheadAttention,
- q: 第一个MultiheadAttention的输出(经过dropout和norm),加上query_pos
- k: memory,加了pos位置信息,来源于Encoder输出
- v: memory,来源于Encoder的输出
4.3.1 理解2-简化
更清晰的DecoderLayer图如下:
Decoder的最开始的输入一个一个全0的向量,所以:
q = query pos
k = query pos
v = 0
后续的DecodeLayer的输入是上一个DecodeLayer的输出。
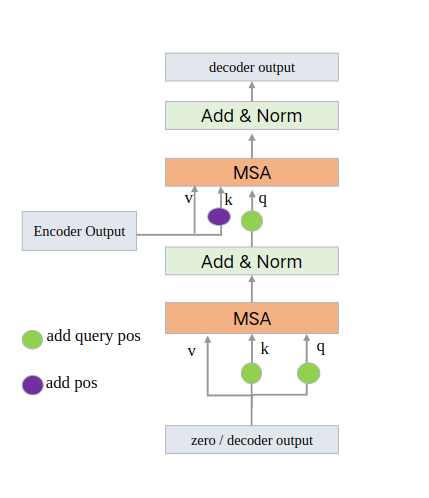
4.4 小结
Encoder的输出shape:(hw,batch,256)
Decoder的输入和输出shape:(batch,100,256)
整个transformer的输出shape:(batch,100,256)
object queries 维度为 [100, batch, 256] ,类型为 nn.Embedding 说明这个张量是学习得到的, Object queries 充当的其实是位置编码的作用,只不过它是可以学习的位置编码。
Transformer局部:
def forward(self, src, mask, query_embed, pos_embed):
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1)
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
mask = mask.flatten(1)
tgt = torch.zeros_like(query_embed)
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
DecoderLayer 局部:
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
# 第一个MultiheadAttention
q = k = self.with_pos_embed(tgt, query_pos)
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
# 第二个MultiheadAttention
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
DecoderLayer 整体:
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
# 第一个MultiheadAttention
q = k = self.with_pos_embed(tgt, query_pos)
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
# 第二个MultiheadAttention
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
def forward_pre(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
tgt2 = self.norm1(tgt)
q = k = self.with_pos_embed(tgt2, query_pos)
tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt2 = self.norm2(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt2 = self.norm3(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
tgt = tgt + self.dropout3(tgt2)
return tgt
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
return self.forward_post(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
Transformer整体代码如下:
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False):
super().__init__()
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, src, mask, query_embed, pos_embed):
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1)
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
mask = mask.flatten(1)
tgt = torch.zeros_like(query_embed)
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
5. Head
Head部分是使用一个简单的MLP进行分类和回归。
参考
- https://blog.csdn.net/baidu_36913330/article/details/120495817
- https://blog.csdn.net/m0_48086806/article/details/132155312
- https://zhuanlan.zhihu.com/p/348060767
- https://feizaipp.github.io/2021/04/27/transformer-%E5%9C%A8-CV-%E4%B8%AD%E7%9A%84%E5%BA%94%E7%94%A8(%E4%BA%8C)-DETR-%E7%9B%AE%E6%A0%87%E6%A3%80%E6%B5%8B%E7%BD%91%E7%BB%9C/