机器学习笔记
第一章 机器学习简介
第二章 感知机
第三章 支持向量机
第四章 朴素贝叶斯分类器
第五章 Logistic回归
第六章 线性回归和岭回归
第七章 多层感知机与反向传播【Python实例】
第八章 主成分分析【PCA降维】
第九章 隐马尔可夫模型
第十章 奇异值分解
第十一章 熵、交叉熵、KL散度
第十二章 什么是范数【向量范数、矩阵范数】
第十三章 熵、交叉熵、KL散度
第十四章 极大似然估计、最大后验估计、贝叶斯估计
第十五章 高斯过程回归模型
文章目录
- 机器学习笔记
- 高斯过程回归
- 一、 一元高斯分布
- 二、多元高斯分布
- 三、 高斯过程
- 四、高斯过程回归
- 五、核函数
- 六、超参数的优化
- 参考资料
高斯过程回归
高斯过程回归(Gaussian Process Regression,简称GPR)是一种非参数的回归方法,它基于高斯过程(Gaussian Process)理论。在机器学习中,高斯过程是一种强大的工具,用于建模连续型的函数关系,特别适用于小样本的情况。在进行预测时,高斯过程回归会计算给定输入下目标函数的后验分布,这个后验分布也是一个高斯分布,它的均值给出了预测值,方差则表示了预测的不确定性。由于高斯过程回归是基于贝叶斯推断的,因此它能够提供预测结果的不确定性估计,这对于许多应用场景非常有用,尤其是在决策制定中需要考虑风险的情况下。
高斯过程回归的优点包括:
- 能够灵活地处理非线性关系,适用于各种类型的函数逼近。
- 能够提供预测的不确定性,有利于进行决策制定。
- 不需要事先指定复杂的模型结构,减轻了参数调节的负担。
一、 一元高斯分布
若随机变量
x
x
x 服从一个位置参数为
μ
\mu
μ 、尺度参数为
σ
\sigma
σ 的概率分布, 且其概率密度函数为 :
f
(
x
)
=
1
2
π
σ
exp
(
−
(
x
−
μ
)
2
2
σ
2
)
f(x)=\frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{(x-\mu)^2}{2 \sigma^2}\right)
f(x)=2πσ1exp(−2σ2(x−μ)2)
则这个随机变量就称为正态随机变量, 正态随机变量服从的分布就称为正态分布(也称为高斯分布), 记作
x
∼
N
(
μ
,
σ
2
)
x \sim N\left(\mu, \sigma^2\right)
x∼N(μ,σ2)。当
μ
=
0
,
σ
=
1
\mu=0, \sigma=1
μ=0,σ=1 时, 正态分布就成为标准正态分布:
f
(
x
)
=
1
2
π
exp
(
−
x
2
2
)
f(x)=\frac{1}{\sqrt{2 \pi}} \exp\left(-\frac{x^2}{2}\right)
f(x)=2π1exp(−2x2)
一元高斯分布有很多很好的性质,比如两个高斯分布的线性组合仍然是高斯分布,而多个一元高斯分布的联合分布则可以导出多元高斯分布。
二、多元高斯分布
若一个多维随机向量具有同一元高斯分布类似的概率规律时, 称此随机向量遵从多元高斯(multivariate Gaussian)分布。多元高斯分布可以从一元高斯分布导出,对于
D
D
D 维的随机变量量
x
=
(
x
1
,
…
,
x
D
)
T
\mathbf{x}=\left(x_1, \ldots, x_D\right)^T
x=(x1,…,xD)T , 多元高斯分布形式为:
N
(
x
∣
μ
,
Σ
)
=
1
(
2
π
)
D
/
2
1
∣
Σ
∣
1
/
2
exp
{
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
}
N(\mathbf{x} \mid \mu, \boldsymbol{\Sigma})=\frac{1}{(2 \pi)^{D / 2}} \frac{1}{|\mathbf{\Sigma}|^{1 / 2}} \exp \left\{-\frac{1}{2}(\mathbf{x}-\mu)^T \mathbf{\Sigma}^{-1}(\mathbf{x}-\mu)\right\}
N(x∣μ,Σ)=(2π)D/21∣Σ∣1/21exp{−21(x−μ)TΣ−1(x−μ)}
式中的
μ
\mu
μ 是
D
D
D 维的均值向量,
Σ
\Sigma
Σ 是
D
×
D
D \times D
D×D 的协方差矩阵 (covariance matrix),
∣
Σ
∣
|\Sigma|
∣Σ∣是
Σ
\Sigma
Σ的行列式。多元正态分布也有很好的性质, 例如, 多元正态分布的边缘分布仍为正态分布,它经任何线性变换得到的随机向量仍为多维正态分布,它的线性组合为一元正态分布。在后面高斯过程回归的推导中会用到多元高斯分布的条件概率分布,所以这里我们给出多元高斯分布条件概率分布的定理:
定理(多元高斯分布条件概率分布)
设 y ∼ N ( μ , Σ ) \boldsymbol{y} \sim \mathcal{N}(\boldsymbol{\mu}, \Sigma) y∼N(μ,Σ), 将 y , μ \boldsymbol{y}, \boldsymbol{\mu} y,μ 和 Σ \Sigma Σ 分割成如下形式:
y = [ y 1 y 2 ] n 1 n 2 μ = [ μ 1 μ 2 ] n 1 n 2 Σ = [ Σ 11 Σ 12 Σ 21 Σ 22 ] n 1 n 2 \begin{aligned} & \boldsymbol{y}=\left[\begin{array}{l} \boldsymbol{y}_1 \\ \boldsymbol{y}_2 \end{array}\right]\begin{array}{l} n_1 \\ n_2 \end{array} \quad \quad \boldsymbol{\mu}=\left[\begin{array}{l} \boldsymbol{\mu}_1 \\ \boldsymbol{\mu}_2 \end{array}\right]\begin{array}{l} n_1 \\ n_2 \end{array} \\ & \Sigma=\left[\begin{array}{cc} \Sigma_{11} & \Sigma_{12} \\ \Sigma_{21} & \Sigma_{22} \end{array}\right] \begin{array}{l} n_1 \\ n_2 \end{array} \end{aligned} y=[y1y2]n1n2μ=[μ1μ2]n1n2Σ=[Σ11Σ21Σ12Σ22]n1n2
其中 y , μ ∈ R n \boldsymbol{y}, \boldsymbol{\mu} \in \mathbb{R}^n y,μ∈Rn 且 Σ ∈ R n × n \Sigma \in \mathbb{R}^{n \times n} Σ∈Rn×n。那么我们可以知道 y 1 ∼ N ( μ 1 , Σ 11 ) \boldsymbol{y}_1 \sim \mathcal{N}\left(\boldsymbol{\mu}_1, \Sigma_{11}\right) y1∼N(μ1,Σ11) ,进一步可以推出条件概率分布:
y 2 ∣ y 1 ∼ N ( μ 2 + Σ 21 Σ 11 − 1 ( y 1 − μ 1 ) , Σ 22 − Σ 21 Σ 11 − 1 Σ 12 ) \boldsymbol{y}_2 \mid \boldsymbol{y}_1 \sim \mathcal{N}\left(\boldsymbol{\mu}_2+\Sigma_{21} \Sigma_{11}^{-1}\left(\boldsymbol{y}_1-\boldsymbol{\mu}_1\right), \Sigma_{22}-\Sigma_{21} \Sigma_{11}^{-1} \Sigma_{12}\right) y2∣y1∼N(μ2+Σ21Σ11−1(y1−μ1),Σ22−Σ21Σ11−1Σ12)
三、 高斯过程
高斯过程是概率论和数理统计中随机过程的一种,是一系列服从高斯分布的随机变量在一指数集内的组合。高斯过程中任意个随机变量的线性组合都服从多元高斯分布,每个有限维分布都是联合高斯分布。对一个任意集合
X
\mathcal{X}
X, 一个定义在
X
\mathcal{X}
X上的高斯过程
(
G
P
)
(\mathrm{GP})
(GP) 是一个随机变量的集合
(
f
(
x
)
,
x
∈
X
)
(f(x), x \in \mathcal{X})
(f(x),x∈X) ,使得对任意的
n
∈
N
n \in \mathbb{N}
n∈N 且
x
1
,
…
,
x
n
∈
X
x_1, \ldots, x_n \in \mathcal{X}
x1,…,xn∈X,满足
(
f
(
x
1
)
,
…
,
f
(
x
n
)
)
\left(f\left(x_1\right), \ldots, f\left(x_n\right)\right)
(f(x1),…,f(xn)) 是一个多元高斯分布。由于高斯分布由均值向量和协方差矩阵指定,因此,高斯过程也完全由均值函数
μ
(
x
)
\mu (x)
μ(x)和协方差函数(或者叫核函数)
k
(
x
,
x
′
)
k(x,x')
k(x,x′)共同唯一确定,常表示为如下形式:
f
(
x
)
∼
G
P
(
μ
(
x
)
,
k
(
x
,
x
′
)
)
f(\mathbf{x}) \sim \mathcal{G} \mathcal{P}\left(\mu(\mathbf{x}), k\left(\mathbf{x}, \mathbf{x}^{\prime}\right)\right)
f(x)∼GP(μ(x),k(x,x′))
其中均值函数反映了函数在输入点x处的均值:
μ
(
x
)
=
E
(
f
(
x
)
)
\mu(x) = \mathbb{E}(f(\mathbf{x}))
μ(x)=E(f(x))
核函数
k
(
x
,
x
′
)
k(x,x')
k(x,x′)刻画了函数值在
x
x
x和
x
′
x'
x′处的关系:
k
(
x
,
x
′
)
=
E
[
(
f
(
x
)
−
μ
(
x
)
(
f
(
x
′
)
−
μ
(
x
′
)
)
]
k\left(\mathbf{x}, \mathbf{x}^{\prime}\right)=\mathbb{E}\left[(f(\mathbf{x})-\mu(\mathbf{x})\left(f\left(\mathbf{x}^{\prime}\right)-\mu\left(\mathbf{x}^{\prime}\right)\right)\right]
k(x,x′)=E[(f(x)−μ(x)(f(x′)−μ(x′))]
高斯过程的性质与其核函数有密切联系,不同的核函数可以赋予高斯过程不同的平滑性、各向同性、周期性和平稳性。核函数的选择要求满足Mercer定理(Mercer’s theorem),即核函数在样本空间内的任意格拉姆矩阵为半正定矩阵。
四、高斯过程回归
我们知道在机器学习中,监督学习可以分为回归问题和分类问题。分类问题的输出是离散的类标签,而回归是关于连续量的预测。而本文,我们主要是讨论多任务高斯过程在回归问题中的应用,所以这里首先介绍一下高斯过程回归的基本原理。
高斯过程回归模型通常可以从权重空间视角和函数空间视角去推导,这里我们从函数空间的视角进行介绍。通过刚才对高斯过程的介绍,我们可以发现回归模型能用高斯过程来表示,比如贝叶斯线性回归模型
f
(
x
)
=
ϕ
(
x
)
T
w
f(\boldsymbol{x})=\boldsymbol{\phi}(\boldsymbol{x})^{\mathrm{T}} \boldsymbol{w}
f(x)=ϕ(x)Tw ,其中
w
∼
N
(
0
,
Σ
p
)
\boldsymbol{w} \sim \mathcal{N}\left(\mathbf{0}, \Sigma_p\right)
w∼N(0,Σp)、
ϕ
(
x
)
\boldsymbol{\phi}(\boldsymbol{x})
ϕ(x)表示经过某种变换后的输入,于是可以得到:
μ
(
x
)
=
E
[
f
(
x
)
]
=
ϕ
(
x
)
T
E
[
w
]
=
0
k
(
x
,
x
′
)
=
E
[
f
(
x
)
f
(
x
′
)
]
=
ϕ
(
x
)
T
E
[
w
w
T
]
ϕ
(
x
′
)
=
ϕ
(
x
)
T
Σ
p
ϕ
(
x
′
)
\begin{aligned} \mu(\boldsymbol{x}) & =\mathbb{E}[f(\boldsymbol{x})]=\boldsymbol{\phi}(\boldsymbol{x})^{\mathrm{T}} \mathbb{E}[\boldsymbol{w}]=0 \\ k\left(\boldsymbol{x}, \boldsymbol{x}^{\prime}\right) & =\mathbb{E}\left[f(\boldsymbol{x}) f\left(\boldsymbol{x}^{\prime}\right)\right]=\boldsymbol{\phi}(\boldsymbol{x})^{\mathrm{T}} \mathbb{E}\left[\boldsymbol{w} \boldsymbol{w}^{\mathrm{T}}\right] \boldsymbol{\phi}\left(\boldsymbol{x}^{\prime}\right)=\boldsymbol{\phi}(\boldsymbol{x})^{\mathrm{T}} \Sigma_p \boldsymbol{\phi}\left(\boldsymbol{x}^{\prime}\right) \end{aligned}
μ(x)k(x,x′)=E[f(x)]=ϕ(x)TE[w]=0=E[f(x)f(x′)]=ϕ(x)TE[wwT]ϕ(x′)=ϕ(x)TΣpϕ(x′)
所以
f
(
x
)
∼
G
P
(
0
,
ϕ
(
x
)
T
Σ
p
ϕ
(
x
′
)
)
f(\boldsymbol{x}) \sim \mathcal{G P}\left(0, \boldsymbol{\phi}(\boldsymbol{x})^{\mathrm{T}} \Sigma_p \boldsymbol{\phi}\left(\boldsymbol{x}^{\prime}\right)\right)
f(x)∼GP(0,ϕ(x)TΣpϕ(x′))。
进一步,我们可以考虑一个一般的带噪声的的回归模型:
y
=
f
(
x
)
+
ε
f
(
x
)
∼
G
P
(
μ
,
k
)
y=f(\boldsymbol{x})+\varepsilon \qquad f(\boldsymbol{x}) \sim \mathcal{G} \mathcal{P}(\mu, k)
y=f(x)+εf(x)∼GP(μ,k)其中,
f
(
x
)
f(\boldsymbol{x})
f(x)是参数待定的高斯过程,噪声满足
ε
∼
N
(
0
,
σ
n
2
)
\varepsilon \sim \mathcal{N}\left(0, \sigma_n^2\right)
ε∼N(0,σn2).现在我们假设数据集
D
=
{
(
x
i
,
y
i
)
∣
i
=
1
,
…
,
n
}
\mathcal{D}=\left\{\left(\boldsymbol{x}_i, y_i\right) \mid i=1, \ldots, n\right\}
D={(xi,yi)∣i=1,…,n},其中
x
i
∈
R
d
,
y
i
∈
R
\boldsymbol{x}_i \in \mathbb{R}^d, y_i \in \mathbb{R}
xi∈Rd,yi∈R。可以表示为矩阵形式
D
=
(
X
,
y
)
\mathcal{D}=(\mathrm{X},\boldsymbol{y})
D=(X,y),其中
X
∈
R
n
×
d
,
y
∈
R
n
\mathrm{X}\in \mathbb{R}^{n\times d},\boldsymbol{y}\in\mathbb{R}^n
X∈Rn×d,y∈Rn。当观测点满足回归模型时,按照高斯过程的定义,这些点的联合分布
[
f
(
x
1
)
,
…
,
f
(
x
n
)
]
\left[f\left(\boldsymbol{x}_1\right), \ldots, f\left(\boldsymbol{x}_n\right)\right]
[f(x1),…,f(xn)] 需要满足一个多维高斯分布, 即:
[
f
(
x
1
)
,
f
(
x
2
)
,
…
,
f
(
x
n
)
]
T
∼
N
(
μ
,
K
)
\left[f\left(\boldsymbol{x}_1\right), f\left(\boldsymbol{x}_2\right), \ldots, f\left(\boldsymbol{x}_n\right)\right]^{\mathrm{T}} \sim \mathcal{N}(\boldsymbol{\mu}, K)
[f(x1),f(x2),…,f(xn)]T∼N(μ,K)这里
μ
=
[
μ
(
x
1
)
,
…
,
μ
(
x
n
)
]
T
\boldsymbol{\mu}=\left[\mu\left(\boldsymbol{x}_1\right), \ldots, \mu\left(\boldsymbol{x}_n\right)\right]^{\mathrm{T}}
μ=[μ(x1),…,μ(xn)]T 是均值向量,
K
K
K 是
n
×
n
n \times n
n×n 的矩阵, 其中第
(
i
,
j
)
(i, j)
(i,j) 个元素是
K
i
j
=
k
(
x
i
,
x
j
)
K_{i j}=k\left(\boldsymbol{x}_i, \boldsymbol{x}_j\right)
Kij=k(xi,xj).
为了预测在新的点处的函数值
f
∗
=
f
(
Z
)
f_*=f(Z)
f∗=f(Z), 其中
Z
=
[
z
1
,
⋯
,
z
m
]
T
Z=\left[\boldsymbol{z}_1, \cdots, \boldsymbol{z}_m\right]^{\mathrm{T}}
Z=[z1,⋯,zm]T, 根据高斯分布的性质, 训练点和预测点的联合分布仍然为高斯分布,即:
[
y
f
∗
]
∼
N
(
[
μ
(
X
)
μ
(
Z
)
]
,
[
K
(
X
,
X
)
+
σ
n
2
I
K
(
Z
,
X
)
T
K
(
Z
,
X
)
K
(
Z
,
Z
)
]
)
\left[\begin{array}{c} \boldsymbol{y} \\ f_* \end{array}\right] \sim \mathcal{N}\left(\left[\begin{array}{c} \boldsymbol{\mu}(X) \\ \boldsymbol{\mu}(Z) \end{array}\right],\left[\begin{array}{cc} K(X, X)+\sigma_n^2 \mathbf{I} & K(Z, X)^{\mathrm{T}} \\ K(Z, X) & K(Z, Z) \end{array}\right]\right)
[yf∗]∼N([μ(X)μ(Z)],[K(X,X)+σn2IK(Z,X)K(Z,X)TK(Z,Z)])
其中:
- μ ( X ) = μ , μ ( Z ) = [ μ ( z 1 ) , … , μ ( z m ) ] T , K ( X , X ) = K \boldsymbol{\mu}(X)=\boldsymbol{\mu}, \boldsymbol{\mu}(Z)=\left[\mu\left(\boldsymbol{z}_1\right), \ldots, \mu\left(\boldsymbol{z}_m\right)\right]^{\mathrm{T}}, K(X, X)=K μ(X)=μ,μ(Z)=[μ(z1),…,μ(zm)]T,K(X,X)=K;
- K ( Z , X ) K(Z, X) K(Z,X)是个 m × n m \times n m×n 的矩阵, 其中第 ( i , j ) (i, j) (i,j) 个元素 [ K ( Z , X ) ] i j = k ( z i , x j ) [K(Z, X)]_{i j}=k\left(\boldsymbol{z}_i, \boldsymbol{x}_j\right) [K(Z,X)]ij=k(zi,xj) ;
-
K
(
Z
,
Z
)
K(Z, Z)
K(Z,Z)是个
m
×
m
m \times m
m×m 的 矩阵, 其中第
(
i
,
j
)
(i, j)
(i,j) 个元素
[
K
(
Z
,
Z
)
]
i
j
=
k
(
z
i
,
z
j
)
[K(Z, Z)]_{i j}=k\left(\boldsymbol{z}_i, \boldsymbol{z}_j\right)
[K(Z,Z)]ij=k(zi,zj) .
最后利用高斯分布的条件分布性质, 我们可以得到关于预测值的条件概率分布:
p ( f ∗ ∣ X , y , Z ) = N ( μ ^ , Σ ^ ) p\left(f_* \mid X, \boldsymbol{y}, Z\right)=\mathcal{N}(\hat{\boldsymbol{\mu}}, \hat{\Sigma}) p(f∗∣X,y,Z)=N(μ^,Σ^)其中:
μ ^ = K ( Z , X ) ( K ( X , X ) + σ n 2 I ) − 1 ( y − μ ( X ) ) + μ ( Z ) Σ ^ = K ( Z , Z ) − K ( Z , X ) ( K ( X , X ) + σ n 2 I ) − 1 K ( Z , X ) T \begin{aligned} &\hat{\boldsymbol{\mu}}=K(Z, X)\left(K(X, X)+\sigma_n^2 \mathbf{I}\right)^{-1}(\boldsymbol{y}-\boldsymbol{\mu}(X))+\boldsymbol{\mu}(Z) \\ &\hat{\Sigma}=K(Z, Z)-K(Z, X)\left(K(X, X)+\sigma_n^2 \mathbf{I}\right)^{-1} K(Z, X)^{T} \end{aligned} μ^=K(Z,X)(K(X,X)+σn2I)−1(y−μ(X))+μ(Z)Σ^=K(Z,Z)−K(Z,X)(K(X,X)+σn2I)−1K(Z,X)T如果将预测值的噪声考虑进来,条件概率分布如下:
p ( y ∗ ∣ X , y , Z ) = N ( μ ^ , Σ ^ + σ n 2 I ) p\left(\boldsymbol{y}_* \mid X, \boldsymbol{y}, Z\right)=\mathcal{N}\left(\hat{\boldsymbol{\mu}}, \hat{\Sigma}+\sigma_n^2 \mathbf{I}\right) p(y∗∣X,y,Z)=N(μ^,Σ^+σn2I)在实际应用中,我们通常将令均值函数 μ ( x ) = 0 \mu(x) = 0 μ(x)=0(本文如无特殊说明,也都采用值为0的均值函数),那么预测的均值函数和预测的协方差函数的结果可以更为简单的表示为:
μ ^ = K ( Z , X ) ( K ( X , X ) + σ n 2 I ) − 1 y Σ ^ = K ( Z , Z ) − K ( Z , X ) ( K ( X , X ) + σ n 2 I ) − 1 K ( Z , X ) T \begin{aligned} \hat{\boldsymbol{\mu}} &= K(Z,X)(K(X,X) + \sigma^2_n \mathbf{I})^{-1}\boldsymbol{y}\\ \hat{\Sigma} &= K(Z,Z) - K(Z,X)(K(X,X) + \sigma^2_n \mathbf{I})^{-1}K(Z,X)^{\mathrm{T}} \end{aligned} μ^Σ^=K(Z,X)(K(X,X)+σn2I)−1y=K(Z,Z)−K(Z,X)(K(X,X)+σn2I)−1K(Z,X)T
至此,我们便完成了从函数空间视角出发的高斯过程回归模型的推导。观察上式,我们可以发现一些有趣的性质:
- 首先来看均值 μ ^ \hat{\boldsymbol{\mu}} μ^,由于测试数据集一共有m个点,因而 μ ^ \hat{\boldsymbol{\mu}} μ^理应是 m × 1 m \times 1 m×1,而对应等式右边的 y \boldsymbol{y} y应当是 n×1 ,而 μ ^ \hat{\boldsymbol{\mu}} μ^等式右边除了 y \boldsymbol{y} y的其他部分理应为 m×n的,所以预测均值是观测点 y \boldsymbol{y} y的线性组合。
- 再来看协方差 Σ ^ \hat{\boldsymbol{\Sigma}} Σ^,等式右边的第一部分是我们的先验的协方差,减掉的后面的那一项实际上表示了观测到数据后函数分布不确定性的减少,如果第二项非常接近于 0,说明观测数据后我们的不确定性几乎不变,反之如果第二项非常大,则说明不确定性降低了很多。
如果我们再换一种视角来看均值
μ
^
\hat{\boldsymbol{\mu}}
μ^,将
(
K
(
X
,
X
)
+
σ
n
2
I
)
−
1
y
\left(K(X, X)+\sigma_n^2 \mathbf{I}\right)^{-1} \boldsymbol{y}
(K(X,X)+σn2I)−1y 看做整体
α
\alpha
α, 则
μ
^
i
=
∑
j
=
1
n
α
j
k
(
x
j
,
z
i
)
\hat{\boldsymbol{\mu}}_i=\sum_{j=1}^n \alpha_j k\left(\boldsymbol{x}_j, \boldsymbol{z}_i\right)
μ^i=j=1∑nαjk(xj,zi)最终结果表示,预测值
μ
^
i
\hat{\boldsymbol{\mu}}_i
μ^i可以看做是预测点和观测点之间核函数的线性组合,这个方程表明高斯过程回归等价于使用核函数
k
(
x
,
x
′
)
k(x,x')
k(x,x′)将输入投影到特征空间的线性回归模型。为了得到预测点的值,每个输出
μ
i
^
\hat{\boldsymbol{\mu}_i}
μi^被加权为其相关的输入
x
j
x_j
xj与被预测点
z
i
z_i
zi的相似度,这是由核函数诱导的相似度度量。这个加权和表明,高斯过程回归模型取决于选定的核函数和到目前为止观察到的数据,而不需要指定具体的模型函数形式,这就是为什么高斯过程回归是一种非参数方法。
用高斯过程对回归问题进行建模有很多优势。首先,GP利用有限的训练数据点计算核函数,建模复杂度与 x x x的维数无关 ,使得我们能够处理更高维的输入数据,理论上无限维都行。其次,刚刚提到,高斯过程是一种非参数的方法,对回归问题进行建模时,不需要指定模型的形式,这意味着高斯过程可以对任意形式的函数进行建模拟合。
五、核函数
我们看到 k ( x , x ′ ) k(x,x') k(x,x′)对高斯过程回归模型至关重要,可以说核函数是一个高斯过程的核心,核函数决定了一个高斯过程的性质。
定义(核函数)
在 X \mathcal{X} X上的半正定核函数 k k k,需要满足如下条件 k : X × X ↦ R k: \mathcal{X} \times \mathcal{X} \mapsto \mathbb{R} k:X×X↦R, ∀ n ∈ N , ∀ x 1 , … , x n ∈ X \forall n \in \mathbb{N}, \forall x_1, \ldots, x_n \in \mathcal{X} ∀n∈N,∀x1,…,xn∈X, s.t.矩阵 C C C 都是半正定的, 其中 C i j = k ( x i , x j ) C_{i j}=k\left(x_i, x_j\right) Cij=k(xi,xj)
比如,当 X = R d , k ( x , x ′ ) = x T x ′ \mathcal{X}=\mathbb{R}^d, k(\boldsymbol{x}, \boldsymbol{x'})=\boldsymbol{x}^{\mathrm{T}} \boldsymbol{x'} X=Rd,k(x,x′)=xTx′时,可以得到 C = x x T C=\boldsymbol{x}\boldsymbol{x^T} C=xxT. 设 a ∈ R n \boldsymbol{a} \in \mathbb{R}^n a∈Rn, 则 a T C a = a T x x T a = ( a x T ) 2 ≥ 0 \boldsymbol{a}^{\mathrm{T}} \boldsymbol{C} \boldsymbol{a}=\boldsymbol{a}^{\mathrm{T}} \boldsymbol{x} \boldsymbol{x}^{\mathrm{T}} \boldsymbol{a}=\left(\boldsymbol{a} \boldsymbol{x}^{\mathrm{T}}\right)^2 \geq 0 aTCa=aTxxTa=(axT)2≥0. 所以,二元函数 k ( x , y ) = x T y k(\boldsymbol{x}, \boldsymbol{y})=\boldsymbol{x}^{\mathrm{T}} \boldsymbol{y} k(x,y)=xTy 是一个半正定的核函数。
在高斯过程中,核函数用于生成一个协方差矩阵来衡量任意两个点之间的“距离”,一个合理的假设通常是两点之间的相关性随两点之间的距离而衰减。 不同的核函数有不同的衡量方法,得到的高斯过程的性质也不一样。最常用的一个核函数为高斯核函数,也称为平方指数函数(Squared Exponential,SE),其基本形式如下:
k
(
x
i
,
x
j
)
=
s
f
2
e
x
p
(
−
∥
x
i
−
x
j
∥
2
2
2
l
2
)
k(x _ i ,x _ j)=s_f^2 exp(-\frac{\Vert x_i-x_j\Vert_2 ^2}{2l^2})
k(xi,xj)=sf2exp(−2l2∥xi−xj∥22)其中
s
f
s_f
sf和
l
l
l是高斯核的超参数,
s
f
s_f
sf是信号方差(signal variance),控制输出的振幅。
l
l
l是长度尺度(length scale),控制输入方向的振荡频率,下图展示了两个超参数对高斯过程函数性质的影响。
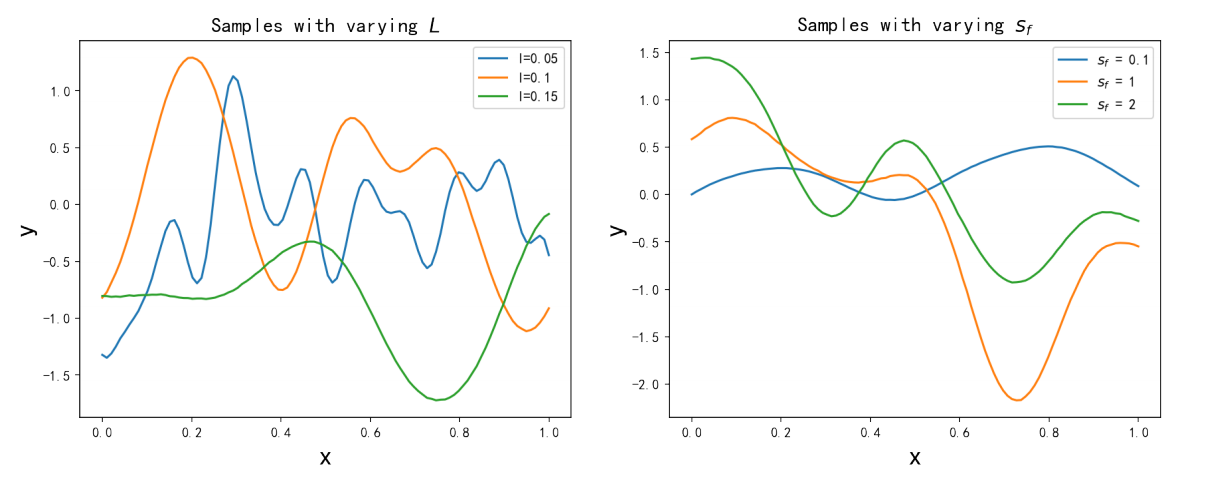 左边图展示了,当
s
f
s_f
sf固定时,长度尺度
l
l
l对高斯过程的影响,可以看到不同的
l
l
l导致高斯过程曲线在水平轴上具有不同的振荡频率。右边图展示了,当
l
l
l固定时,信号方差
s
f
s_f
sf对高斯过程的影响,可以看到不同的
s
f
s_f
sf导致高斯过程曲线在纵轴上有不同的振幅。
左边图展示了,当
s
f
s_f
sf固定时,长度尺度
l
l
l对高斯过程的影响,可以看到不同的
l
l
l导致高斯过程曲线在水平轴上具有不同的振荡频率。右边图展示了,当
l
l
l固定时,信号方差
s
f
s_f
sf对高斯过程的影响,可以看到不同的
s
f
s_f
sf导致高斯过程曲线在纵轴上有不同的振幅。
高斯核函数提供了一个富有表现力的核来建模平滑、平稳的函数,超参数 l l l和 s f s_f sf可以控制点与点之间的先验相关性,从而控制高斯过程的预测性能。
六、超参数的优化
通过前面的介绍,我们已经知道了如何使用给定的核和零均值函数构造高斯过程回归模型。只要从数据中学习所有待定超参数 θ = { θ 1 , θ 2 , ⋯ } \boldsymbol{\theta}=\{\theta_1,\theta_2,\cdots\} θ={θ1,θ2,⋯},就可以得到预测均值和方差。
由于高斯过程回归模型中超参数的后验分布不易获得,因此在实际应用中不经常使用超参数的全贝叶斯推理,通常的做法是通过最大化边际似然来获得超参数的点估计。所以可以采用最大似然估计(Maximum Likelihood Estimation,MLE),通过梯度下降等优化方法进行优化。
高斯过程模型的似然函数可以表示为:
p
(
y
∣
X
,
θ
)
=
∫
p
(
y
∣
f
,
X
,
θ
)
p
(
f
∣
X
,
θ
)
d
f
p(\boldsymbol{y} \mid X, \theta)=\int p(\boldsymbol{y} \mid \boldsymbol{f}, X, \theta) p(\boldsymbol{f} \mid X, \theta) \mathrm{d} \boldsymbol{f}
p(y∣X,θ)=∫p(y∣f,X,θ)p(f∣X,θ)df
在高斯过程回归模型中,先验和似然函数都是高斯分布:
p
(
f
∣
X
,
θ
)
=
N
(
0
,
K
)
,
p
(
y
∣
f
,
X
,
θ
)
=
N
(
f
,
σ
n
2
I
)
.
\begin{aligned} p(f \mid X, \boldsymbol{\theta}) & =\mathcal{N}(\mathbf{0}, K), \\ p(\boldsymbol{y} \mid f, X, \boldsymbol{\theta}) & =\mathcal{N}\left(f, \sigma_n^2 \mathrm{I}\right) . \end{aligned}
p(f∣X,θ)p(y∣f,X,θ)=N(0,K),=N(f,σn2I).于是我们知道边缘似然函数也是服从高斯分布:
p
(
y
∣
X
,
θ
)
=
∫
N
(
f
,
σ
n
2
I
)
N
(
0
,
K
)
d
f
=
N
(
0
,
K
+
σ
n
2
I
)
=
N
(
0
,
Σ
θ
)
,
p(\boldsymbol{y} \mid X, \boldsymbol{\theta})=\int \mathcal{N}\left(f, \sigma_n^2 \mathrm{I}\right) \mathcal{N}(\mathbf{0}, K) \mathrm{d} f=\mathcal{N}\left(\mathbf{0}, K+\sigma_n^2 \mathrm{I}\right)=\mathcal{N}\left(\mathbf{0}, \Sigma_\theta\right),
p(y∣X,θ)=∫N(f,σn2I)N(0,K)df=N(0,K+σn2I)=N(0,Σθ),
其中
Σ
θ
=
K
θ
+
σ
n
2
I
=
K
+
σ
n
2
I
\Sigma_\theta=K_\theta+\sigma_n^2 \mathbf{I}=K+\sigma_n^2 \mathbf{I}
Σθ=Kθ+σn2I=K+σn2I ,
θ
\boldsymbol{\theta}
θ 包含于协方差函数
K
K
K中。而更常用的是负对数边缘似然函数(Negative Log Marginal Likelihood,NLML):
L
(
θ
)
=
−
log
p
(
y
∣
X
,
θ
)
=
1
2
y
T
Σ
θ
−
1
y
+
1
2
log
∣
Σ
θ
∣
+
n
2
log
2
π
\mathcal{L}(\boldsymbol{\theta})=-\log p(\boldsymbol{y} \mid X, \boldsymbol{\theta})=\frac{1}{2} \boldsymbol{y}^{\mathrm{T}} \Sigma_\theta^{-1} \boldsymbol{y}+\frac{1}{2} \log \vert \Sigma_\theta \vert +\frac{n}{2} \log 2 \pi
L(θ)=−logp(y∣X,θ)=21yTΣθ−1y+21log∣Σθ∣+2nlog2π
得到负对数似然函数
L
\mathcal{L}
L后,剩下的就是优化问题了,可以对上式关于
θ
\theta
θ求偏导:
∂
L
∂
θ
i
=
1
2
tr
(
Σ
θ
−
1
∂
Σ
θ
∂
θ
i
)
−
1
2
y
T
Σ
θ
−
1
∂
Σ
θ
∂
θ
i
Σ
θ
−
1
y
.
\frac{\partial \mathcal{L}}{\partial \theta_i}=\frac{1}{2} \operatorname{tr}\left(\Sigma_\theta^{-1} \frac{\partial \Sigma_\theta}{\partial \theta_i}\right)-\frac{1}{2} \boldsymbol{y}^{\mathrm{T}} \Sigma_\theta^{-1} \frac{\partial \Sigma_\theta}{\partial \theta_i} \Sigma_\theta^{-1} \boldsymbol{y}.
∂θi∂L=21tr(Σθ−1∂θi∂Σθ)−21yTΣθ−1∂θi∂ΣθΣθ−1y.
于是,就可以利用梯度下降之类的方法求得超参数 θ \boldsymbol{\theta} θ。不过值得注意的是,MLE方法有一些局限性。对于许多核函数,边际似然函数相对于超参数不是凸的,因此优化算法可能收敛到局部最优点,而不是全局最优点。因此,通过最大似然估计优化超参数,得到的GPR性能取决于优化算法的初始值 ,所以如何对模型参数的初始化十分关键。
参考资料
- 高斯过程的简洁推导
![[移动通讯]【无线感知-P1】[从菲涅尔区模型到CSI模型-3][Mobius transformations-3]](https://img-blog.csdnimg.cn/direct/481ffd01a9bd4f75b53cf4dd21d4a60d.png)