零、important point
1. 缓存双写一致性问题
2. java实现逻辑(对于 QPS <= 1000 可以使用)
public class UserService {
public static final String CACHE_KEY_USER = "user:";
@Resource
private UserMapper userMapper;
@Resource
private RedisTemplate redisTemplate;
/**
* 业务逻辑没有写错,对于小厂中厂(QPS《=1000)可以使用,但是大厂不行
* @param id
* @return
*/
public User findUserById(Integer id)
{
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql
user = (User) redisTemplate.opsForValue().get(key);
if(user == null)
{
//2 redis里面无,继续查询mysql
user = userMapper.selectByPrimaryKey(id);
if(user == null)
{
//3.1 redis+mysql 都无数据
//你具体细化,防止多次穿透,我们业务规定,记录下导致穿透的这个key回写redis
return user;
}else{
//3.2 mysql有,需要将数据写回redis,保证下一次的缓存命中率
redisTemplate.opsForValue().set(key,user);
}
}
return user;
}其中存在的问题是:在高并发的场景下,(加入redis中没有)会有大量请求打在mysql上。
解决策略:
(多个线程同时查询数据库某条数据时)
===》在第一个数据的请求上(加上一个互斥锁)
===》等待第一个线程查询到了数据 , 并做了缓存
===》后面的线程进来发现已经有缓存了
===》直接走缓存
/**
* 加强补充,避免突然key失效了,打爆mysql,做一下预防,尽量不出现击穿的情况。
* @param id
* @return
*/
public User findUserById2(Integer id)
{
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql,
// 第1次查询redis,加锁前
user = (User) redisTemplate.opsForValue().get(key);
if(user == null) {
//2 大厂用,对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysql
synchronized (UserService.class){
//第2次查询redis,加锁后
user = (User) redisTemplate.opsForValue().get(key);
//3 二次查redis还是null,可以去查mysql了(mysql默认有数据)
if (user == null) {
//4 查询mysql拿数据(mysql默认有数据)
user = userMapper.selectByPrimaryKey(id);
if (user == null) {
return null;
}else{
//5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作
redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS);
}
}
}
}
return user;
}3. 数据一致性的理解
(1)如果 redis 中有数据 ===》 需要和 数据库中的值相同
(2)如果 redis 中没有数据 ===》 数据库中的值的是最新值, 回写到redis中
(3)缓存按照操作来分
1.只读缓存(没有回写操作,少数情况下)
2.读写缓存
2.1 同步直写策略
写数据库后也同步写redis缓存(热点数据、VIP重要数据 ==》这一秒填写、下一秒更新)
2.2 异步缓写策略
mysql数据变动了,可以允许业务上一定时间后作用于redis(仓库、物流系统、积分变更等 ==》 允许一定时延后缓存更新)
可能会出现异常,借助kafka 或者 RabbitMQ 等消息中间件 ,实现重试重写
4. 数据库和缓存一致性的 几种策略
目的 : 达到最终的一致性
做法 : 给缓存设置过期时间 定期清理缓存并回写 ==》 保证最终一致性
1.停机
(eg)凌晨升级 先往mysql灌入10000条数据, 在解决与mysql同步问题
2. 4种 更新策略
(1)先更新数据库,在更新缓存
(2)先更新缓存,在更新数据库
(3)先删除缓存,在更新数据库
(4)先更新数据库,在删除缓存
一、4种 更新策略
(1)先更新数据库,在更新缓存
Q1:redis回写失败,读到的是redis的脏数据
1.先更新mysql的某商品的库存,当前商品的库存是100,更新为99个。
2.先更新mysql修改为99成功,然后更新redis。
3.此时假设异常出现,更新redis失败了,这导致mysql里面的库存是99而redis里面的还是100
4.上述发生,会让数据库里面和缓存redis里面数据不一致,读到redis脏数据Q2: 多线程对于同一份数据update, 回写redis出岔子,数据的写入覆盖
最终导致 mysql 80 , redis 100

(2)先更新缓存,在更新数据库(不太推荐)
Q1: 不太推荐 ==》 业务上一般把 mysql 作为底单数据库,保证最后的解释
Q2:多线程对于同一份数据update, 写入mysql出岔子,数据的写入覆盖

(3)先删除缓存,在更新数据库
Q1: 会出现延时

Q2: 此时redis里面的数据是空的,B线程来读取,先去读redis里数据(已经被A线程delete掉了),此处出来2个问题:
2.1 B从mysql获得了旧值
B线程发现redis里没有(缓存缺失)马上去mysql里面读取,从数据库里面读取来的是旧值。
2.2 B会把获得的旧值写回redis
获得旧值数据后返回前台并回写进redis(刚被A线程删除的旧数据有极大可能又被写回了)。

Q3:A线程更新完mysql,发现redis里面的缓存是脏数据,A线程直接懵逼了,o(╥﹏╥)o
两个并发操作,一个是更新操作,另一个是查询操作,
A删除缓存后,B查询操作没有命中缓存,B先把老数据读出来后放到缓存中,然后A更新操作更新了数据库。
于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还一直这样脏下去了。

解决策略
1. 采用延时双删策略

(4)先更新数据库,在删除缓存
1.异常问题

2.业务指导思想
2.1 微软云
2.2 阿里巴巴cache
3.解决方案
1 可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用Kafka/RabbitMQ等)。
2 当程序没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。3 如果能够成功地删除或更新,我们就要把这些值从消息队列中去除,以免重复操作,此时,我们也可以保证数据库和缓存的数据一致了,否则还需要再次进行重试4 如果重试超过的一定次数后还是没有成功,我们就需要向业务层发送报错信息了,通知运维人员。

4.经典分布式事务问题
最终一致性体现案例:
1.流量充值,先下发短信,实际充值滞后5min
2.电商下单,先下发短信,具体物流明天见
(0)如何选择方案
大多数业务场景:
优先使用先更新数库,在删除缓存的方案


四、面试题
1.使用缓存 会涉及到 redis缓存与数据库 双存储双写
双写 ==》 数据库一致性问题 ==》 如何解决呢?
2. 双写一致性, 先去操作 redis or mysql, why?
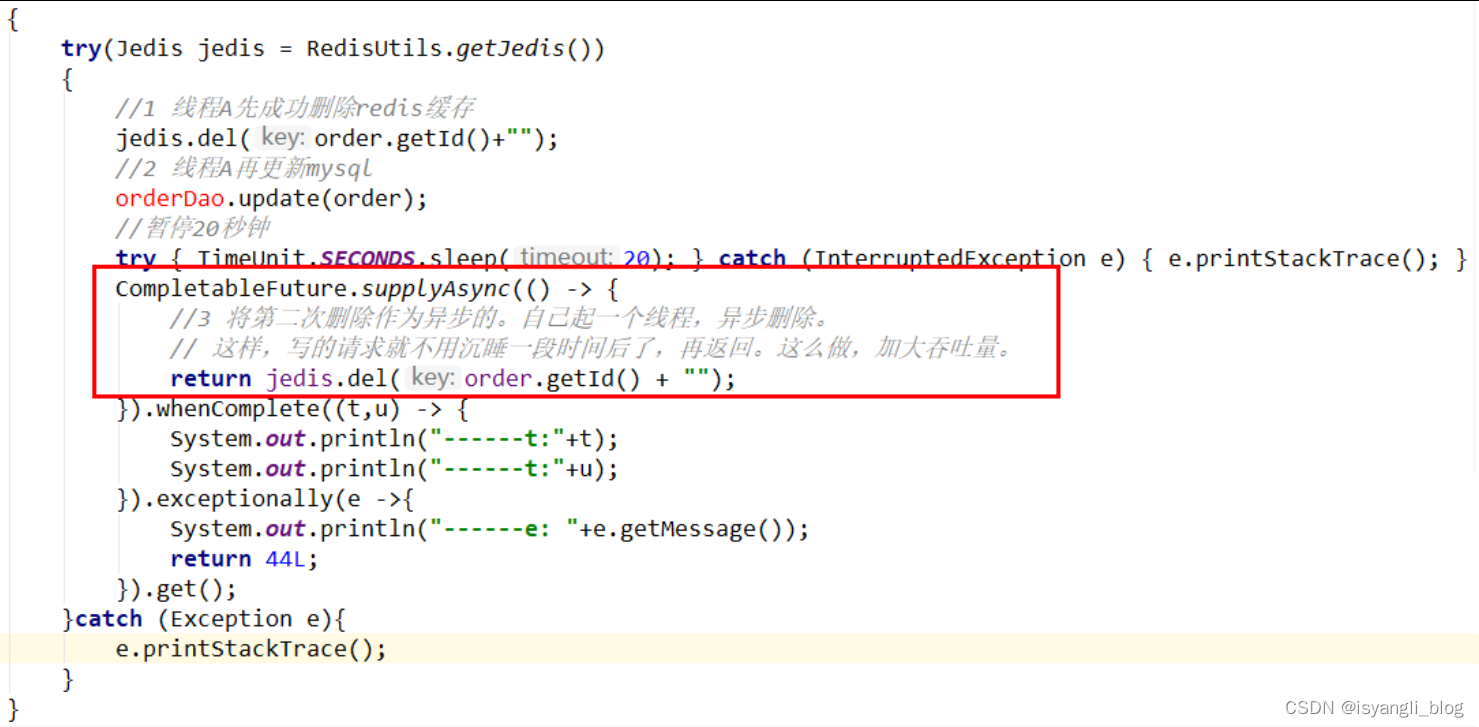
3. 延时双删 怎么说?
应用在需要更新数据时,先删除缓存再更新mysql数据库的策略下,所发生A线程需要更新数据,第一次删除缓存,更新完数据后,再次删除缓存,再将更新后的数据写入缓存。
延时双删会遇到一些问题:
Q1:这个删除需要睡眠多久呢?
一般来说,线程Asleep的时间,就需要大于线程B读取数据再写入缓存的时间。
第一种方法:
在业务程序运行的时候,统计下线程读数据和写缓存的操作时间自行评估自己的项目的读数据业务逻辑的耗时,以此为基础来进行估算。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上加百毫秒即可。
这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
第二种方法:
新启动一个后台监控程序,比如后面讲解的WatchDog监控程序,去加时Q2:这种同步策略,吞吐量降低如何解决?
启动一个线程来监听mysql是否更新完毕
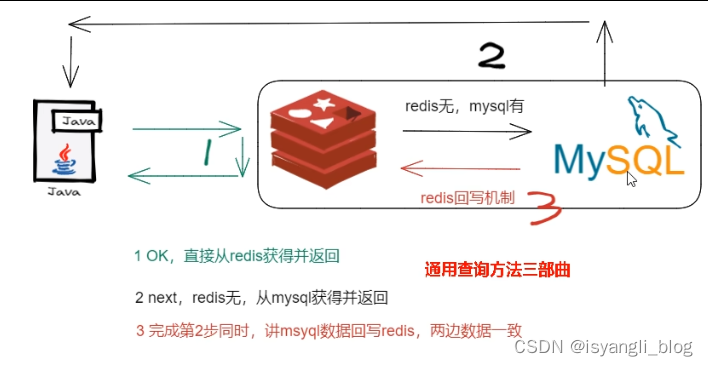
4. 微服务查询 redis无 mysql有, 为保证数据 双写一致性 回写redis 需要注意什么?
==》 双检 加锁 策略
==》 避免 缓存击穿
5. redis 和 mysql 双写100% 会出纰漏, 做不到强一致性, 如何保证 最终一致性?