目录
一,哈希表
1,哈希表概述
2,哈希函数
3,碰撞冲突
二,代码实现
1,哈希函数与素数函数
2,哈希节点与哈希表数据结构
3,构造、析构以及一些简单的功能
4,清空,扩容
5,查找,插入,删除
三,完整代码
一,哈希表
1,哈希表概述
散列表(也称为哈希表(hash table))是一种通过哈希函数来计算数据存储位置的数据结构,使得对数据的插入、删除和查找操作可以非常快速进行。哈希表可以说是一种专门用来查找的数据结构。在最理想的情况下,哈希表的这些操作的时间复杂度为O(1)。那么,它是怎么做到如此高效的呢?
我们先来考虑一下这个:如果我们要查找的键都是小整数,我们可以用一个数组来实现无序的符号表,将键作为数组的索引而数组中下标 i 处储存的就是它对应的值。这样我们就可以快速访问任意键的值。
哈希表就是这种简易方法的扩展,它能够处理更加复杂的类型的键,使用哈希查找算法分为两步。
- 第一步是用哈希函数将被查找的键转化为一个哈希值(数组的一个索引)。理想情况下,不同的键都能转化为不同的哈希值。不过实际上我们需要面对多个键都会散列到相同的哈希值的情况。因此我们就需要进行第二步。
- 哈希查找的第二步就是去处理哈希值的碰撞冲突,碰撞冲突是不可避免的。
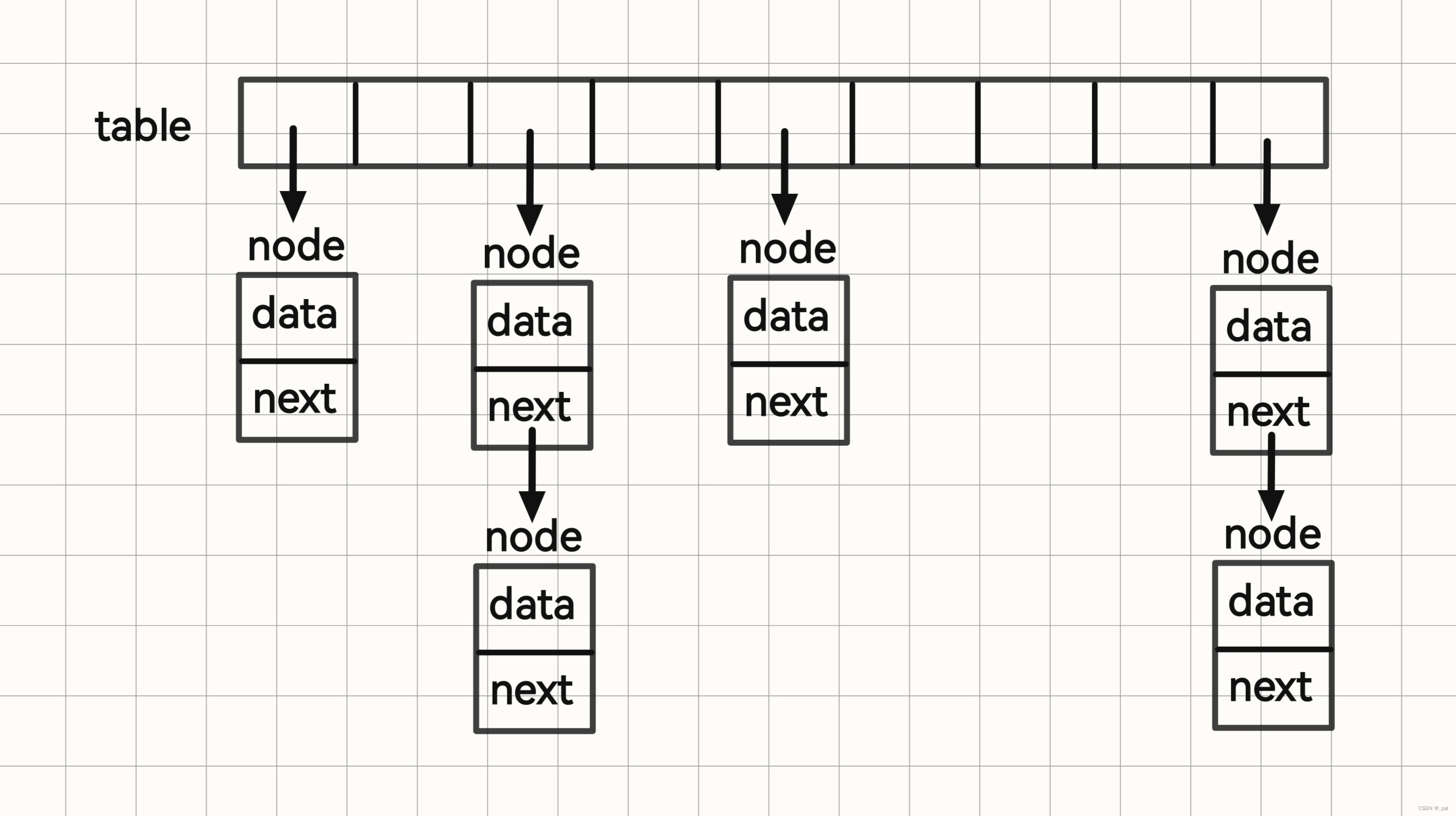
发生碰撞的示意图:

2,哈希函数
使用哈希算法的第一步就是哈希函数的计算,这个过程会将键转化为哈希值。如果我们有一个能够保存 m 个键值对的数组,那么我们就需要一个能够将任意键转化为该数组范围内的索引 [0, m-1] 范围内的整数的散列函数。哈希函数和键的类型有关。严格地说,对于每种类型的键都我们都需要一个与之对应的哈希函数。
我们来看下面几个例子:
Ⅰ 正整数
将整数散列最常用方法是除留余数法。我们选择大小为素数 m 的数组对于任意正整数 k,计算 k % m 就能得到数组的索引。这个函数的计算非常容易并能够有效地将键散布在 [0, m-1] 的范围内。
这里为什么要用素数呢?选择一个素数 m 作为数组的大小有助于减少哈希冲突的可能性。这是因为当使用除留余数法计算索引时,如果 m 是一个非素数,那么某些位置更容易被选中(例如输入的数据恰好是 m 的倍数),这样会增加发生碰撞冲突的可能性。
所以我们在为底层的数组容器分配空间时最好分配素数大小的空间。(不过后文为了方便实现就没有采用这个方式)
Ⅱ 字符串
除留余数法也可以处理较长的键,例如字符串,我们只需要将字符串转为一个正整数之后再用除留余数法就可以了:
size_t k = 0;
// 这一步的处理是为了将字符串转换成正整数的分布更散
int seed = 131;
for (char ch : str) {
k *= seed;
k += ch;
}
size_t idx = k % m;Ⅲ 结构体
如果键的类型含有多个整型变量,我们可以和 string 类型一样将它们混合起来。例如,
假设被查找的键的类型是日期类型 Date,我们可以这样计算它的散列值:
struct Data {
int day;
int month;
int year;
};
size_t k = ((day * 131 + month) * 131 + year);
size_t idx = k % m;要为一个数据类型设计一个优秀的哈希函数需要满足三个条件:
① 一致性:相同的键必须得到相同的哈希值
② 高效性:计算简单
③ 均匀性:均匀的散列说有的键
不过设计专门的哈希函数就是专家们的事情了。
3,碰撞冲突
哈希算法的第二步是碰撞处理,也就是处理多个键的哈希值相同的情况。解决碰撞问题的方法有很多种,例如:线性探测,二次探测,开链法等等,这些方法会在不同的情况下有着不同的效率。
Ⅰ线性探测
当哈希计算出某个元素的插入位置,而该位置上的空间已不再可用时,最简单的处理办法就是循序往下一一寻找(如果到达尾端,就绕到头部继续寻找),直到找到一个可用空间为止。只要数组足够大就肯定能够找到一个空间,但是要花多少时间就很难说了。
进行元素查找操作时,道理也相同,如果哈希函数计算出来的位置上的元素值与我们的搜寻目标不符,就循序往下一一寻找,直到找到吻合者,或直到遇上空格元素。
至于元素的删除,必须采用惰性删除,也就是只标记删除记号,实际删除操作则等底层数组重新开辟空间时再进行。这是因为使用线性探测法的哈希表中的每个元素不仅表述它自己,也关系到其它元素的排列。
Ⅱ 二次探测
二次探测与线性探测十分相似,仅仅只是搜寻新空间的方式不同:如果哈希函数计算出新元素的位置为 idx,而该位置实际上已被使用,那么我们就依序尝试 idx + 1^2,idx + 2^2,idx + 3^2,idx + 4^2 … idx + n^2,而不是像线性探测那样依序尝试 idx + 1,idx + 2,idx + 3,idx + 4 …. idx + n。
Ⅲ 开链法
这种办法是将大小为 m 的数组中的每个元素都指向一条链表,链表中的每个结点都存储了散列值为该元素的索引的值。发生冲突的元素都被存储在链表中。这个方法的基本思想就是选择足够大的m ,使得所有链表都尽可能短以保证高效的查找。这种查找方式分为两步:① 根据哈希值找到对应的链表;② 沿着链表顺序查找相应的键。(在后文中实现的哈希表将基于开链法来实现)
开链法示意图:
二,代码实现
1,哈希函数与素数函数
首先是哈希函数
// 这里的哈希函数只是将数据类型转换为正整数, 将正整数转换为数组索引的工作交给哈希表内部去完成
// 哈希函数族
template<class Key>
struct hash_func {
size_t operator()(const Key& key)const {
return key;
}
};
template<>
struct hash_func<std::string> {
// 将字符串转换为数字
size_t operator()(const std::string& str)const {
size_t res = 0;
int seed = 131;
for (char ch : str) {
res *= seed;
res += ch;
}
return res;
}
};因为我们在对底层的 vector 扩容时选择素数大小可以减少发生碰撞冲突的可能,所以这里提供了一些关于素数的函数(我们也可以提前将素数列表给罗列出来,这样就不用进行查找):
// 寻找并返回不小于 n 的最小素数的函数
size_t prime(int n) {
// 检查一个数是否为素数的函数
std::function<bool(int)> is_prime = [](int num) {
if (num <= 1) return false; // 处理非正整数
if (num <= 3) return true; // 2 和 3 是素数
if (num % 2 == 0 or num % 3 == 0) return false; // 排除能被 2 或 3 整除的数
for (int i = 5; i * i <= num; i += 6) {
if (num % i == 0 or num % (i + 2) == 0) return false;
}
return true;
};
if (n <= 2) return 2; // 特殊处理小于等于 2 的情况
if ((n & 1) == 0) n++; // 如果 n 是偶数,从下一个奇数开始检查
while (not is_prime(n)) n += 2; // 只检查奇数
return n;
}2,哈希节点与哈希表数据结构
template<class T>
struct hash_node {
T data;
hash_node* next;
hash_node(const T& _data = T()) :data(_data), next(nullptr) {}
};template<class Key, class HashFunc = hash_func<Key>>
class hash_table {
// ...
private:
typedef hash_node<Key> Node;
HashFunc _hf;
private:
size_t _size;
std::vector<Node*> _table;
// ...
};3,构造、析构以及一些简单的功能
public:
// 构造与析构
hash_table() :_size(0), _table(11, nullptr) {} // 默认预留11个空间
~hash_table() { if (not empty()) clear(); }
public:
// 一些简单的功能
bool empty()const { return _size == 0; }
size_t size()const { return _size; }
size_t table_size()const { return _table.size(); }
void swap(hash_table& ht) {
std::swap(_size, ht._size);
_table.swap(ht._table);
}
// 为了便于扩展,这里将 prime 函数在 hash_table 内部再封装一层
size_t next_size(size_t size)const { return prime(size); }
// 为了方便找到索引而设计的函数
size_t table_index(const Key& key)const { return _hf(key) % table_size(); }
size_t table_index(const Key& key, size_t table_size)const { return _hf(key) % table_size; }4,清空,扩容
因为 hash_table 中底层容器 vector 中存放的是单向链表,所以我们在进行清空,扩容操作时需要特别注意内存的开辟与释放问题。
public:
// 清空
void clear() {
for (int i = 0;i < _table.size();++i) {
Node* node = _table[i];
while (node) {
Node* next = node->next;
delete node;
node = next;
}
_table[i] = nullptr;
}
_size = 0;
}
// 扩容 table
void resize(size_t size) {
size = next_size(size);
if (size <= _size) return;
std::vector<Node*> newTable(size, nullptr);
for (Node* node : _table) {
while (node) {
// int idx = _hf(node->data) % newTable.size();
int idx = table_index(node->data, newTable.size());
Node* next = node->next;
node->next = newTable[idx];
newTable[idx] = node;
node = next;
}
}
// _table = std::move(newTable);
_table.swap(newTable);
}
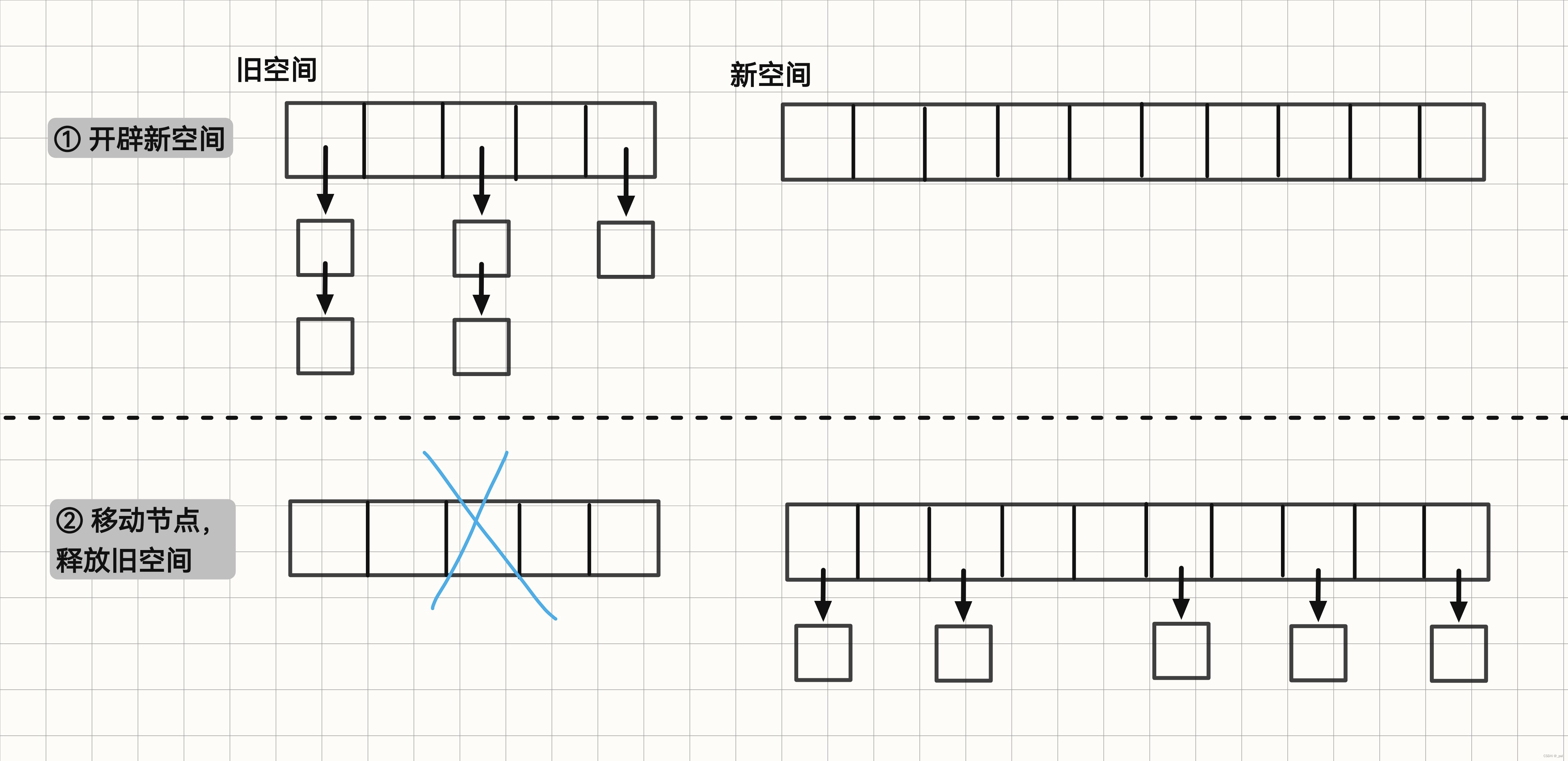
这里特别说明一下 resize 操作的步骤:
① 新开辟一个 vector 来当作存放哈希节点的新空间
② 将原 vector 中的所有节点通过 table_index 函数重新计算索引后移动到新的 vector 中(注意,这里并不是拷贝,而是移动)
③ 将新的 vector 作为新的底层容器
扩容示意图:
5,查找,插入,删除
hash table 的查找十分高效,不过 hash table 中存放的元素并不是有序的,如果我们想按照范围来查找数据,我们因该选择 AVL 或者红黑树来当作我们的容器。
public:
Node* find(const Key& key)const {
// int idx = _hf(key) % _table.size();
int idx = table_index(key);
for (Node* node = _table[idx];node;node = node->next) {
if (node->data == key) return node;
}
return nullptr;
}
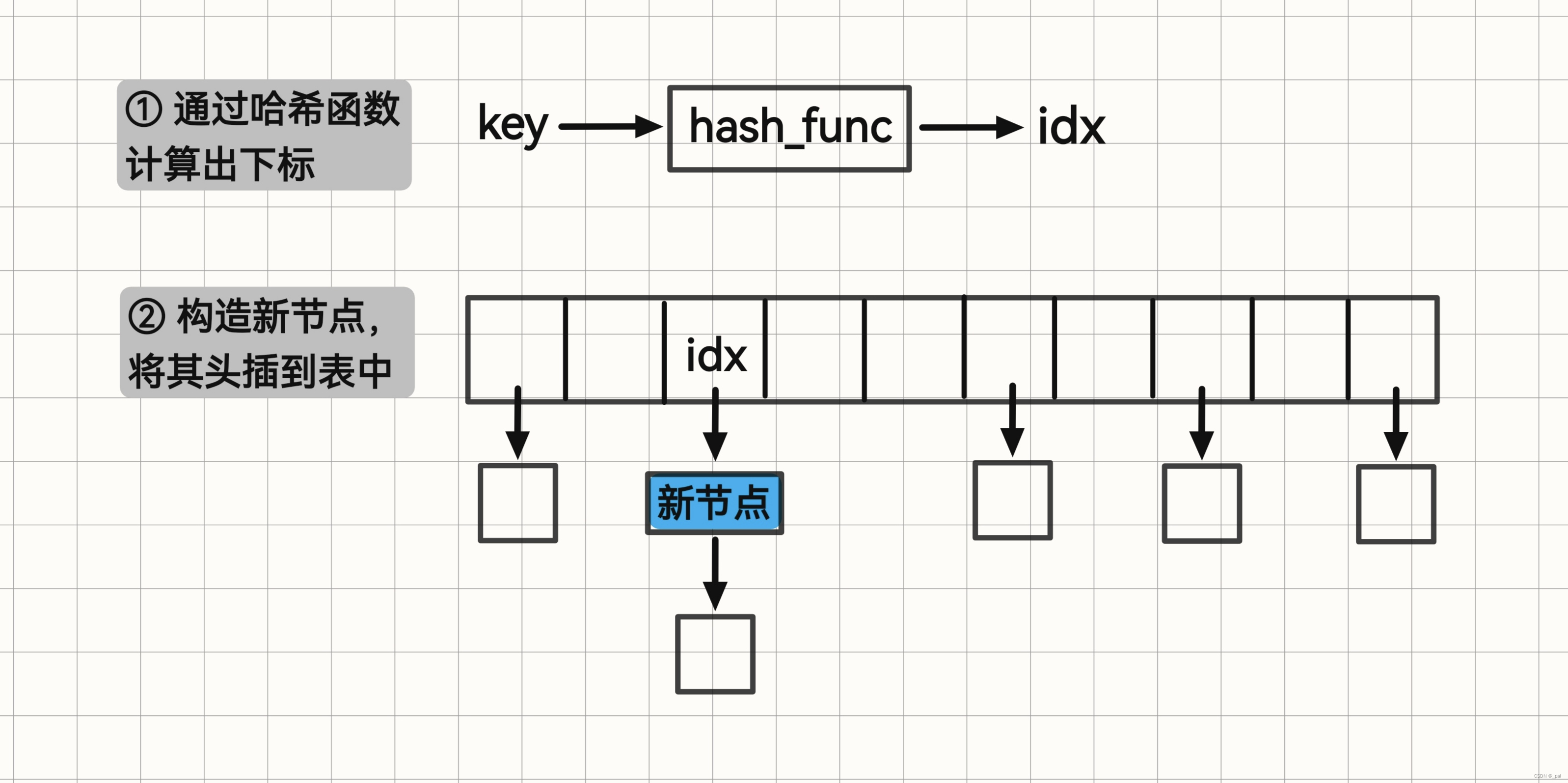
pair<Node*, bool> insert(const Key& key) {
if (_size == _table.size()) {
//扩容table
resize(_size * 2);
}
// 取得下标
// int idx = _hf(key) % _table.size();
int idx = table_index(key);
if (_table[idx] == nullptr) {
_table[idx] = new Node(key);
}
else {
for (Node* node = _table[idx];node != nullptr;node = node->next) {
// key已经存在就直接返回
if (node->data == key) return make_pair(node, false);
}
Node* node = new Node(key);
// 头插
node->next = _table[idx];
_table[idx] = node;
}
++_size;
return make_pair(_table[idx], true);
}
void erase(const Key& key) {
// int idx = _hf(key) % _table.size();
int idx = table_index(key);
Node* dummy = new Node;
dummy->next = _table[idx];
Node* pre = dummy, * cur = dummy->next;
while (cur) {
if (cur->data == key) {
pre->next = cur->next;
_table[idx] = dummy->next;
delete cur;
--_size;
break;
}
pre = cur;
cur = cur->next;
}
delete dummy;
}
因为右值引用版的插入与左值引用版的插入代码基本一致,这里就不详细实现了。
插入示意图:
三,完整代码
template<class T>
struct hash_node {
T data;
hash_node* next;
hash_node(const T& _data = T()) :data(_data), next(nullptr) {}
};
// 这里的哈希函数只是将数据类型转换为正整数, 将正整数转换为数组索引的工作交给哈希表内部去完成
// 哈希函数族
template<class Key>
struct hash_func {
size_t operator()(const Key& key)const {
return key;
}
};
template<>
struct hash_func<std::string> {
// 将字符串转换为数字
size_t operator()(const std::string& str)const {
size_t res = 0;
int seed = 131;
for (char ch : str) {
res *= seed;
res += ch;
}
return res;
}
};
// 寻找并返回不小于 n 的最小素数的函数
size_t prime(int n) {
// 检查一个数是否为素数的函数
std::function<bool(int)> is_prime = [](int num) {
if (num <= 1) return false; // 处理非正整数
if (num <= 3) return true; // 2和3是素数
if (num % 2 == 0 || num % 3 == 0) return false; // 排除能被2或3整除的数
for (int i = 5; i * i <= num; i += 6) {
if (num % i == 0 || num % (i + 2) == 0) return false;
}
return true;
};
if (n <= 2) return 2; // 特殊处理小于等于2的情况
if ((n & 1) == 0) n++; // 如果n是偶数,从下一个奇数开始检查
while (not is_prime(n)) n += 2; // 只检查奇数
return n;
}
template<class Key, class HashFunc = hash_func<Key>>
class hash_table {
private:
typedef hash_node<Key> Node;
HashFunc _hf;
private:
size_t _size;
std::vector<Node*> _table;
public:
// 构造与析构
hash_table() :_size(0), _table(11, nullptr) {} // 默认预留11个空间
~hash_table() { if (not empty()) clear(); }
public:
// 一些简单的功能
bool empty()const { return _size == 0; }
size_t size()const { return _size; }
size_t table_size()const { return _table.size(); }
void swap(hash_table& ht) {
std::swap(_size, ht._size);
_table.swap(ht._table);
}
// 为了便于扩展,这里将 prime 函数在 hash_table 内部再封装一层
size_t next_size(size_t size)const { return prime(size); }
// 为了方便找到索引而设计的函数
size_t table_index(const Key& key)const { return _hf(key) % table_size(); }
size_t table_index(const Key& key, size_t table_size)const { return _hf(key) % table_size; }
public:
// 清空
void clear() {
for (int i = 0;i < _table.size();++i) {
Node* node = _table[i];
while (node) {
Node* next = node->next;
delete node;
node = next;
}
_table[i] = nullptr;
}
_size = 0;
}
// 扩容 table
void resize(size_t size) {
size = next_size(size);
if (size <= _size) return;
std::vector<Node*> newTable(size, nullptr);
for (Node* node : _table) {
while (node) {
// int idx = _hf(node->data) % newTable.size();
int idx = table_index(node->data, newTable.size());
Node* next = node->next;
node->next = newTable[idx];
newTable[idx] = node;
node = next;
}
}
// _table = std::move(newTable);
_table.swap(newTable);
}
// 拷贝
hash_table(const hash_table& ht) {
_size = ht.size();
_table.resize(ht.table_size());
Node* dummy = new Node;
for (int i = 0;i < _table.size();++i) {
Node* pre = dummy;
Node* node = ht._table[i];
while (node != nullptr) {
pre->next = new Node(node->data);
node = node->next;
pre = pre->next;
}
_table[i] = dummy->next;
dummy->next = nullptr;
}
delete dummy;
}
hash_table(hash_table&& ht) {
std::swap(_size, ht._size);
_table.swap(ht._table);
}
hash_table& operator=(hash_table ht) {
swap(ht);
return *this;
}
public:
Node* find(const Key& key)const {
// int idx = _hf(key) % _table.size();
int idx = table_index(key);
for (Node* node = _table[idx];node;node = node->next) {
if (node->data == key) return node;
}
return nullptr;
}
pair<Node*, bool> insert(const Key& key) {
if (_size == _table.size()) {
//扩容table
resize(_size * 2);
}
// 取得下标
// int idx = _hf(key) % _table.size();
int idx = table_index(key);
if (_table[idx] == nullptr) {
_table[idx] = new Node(key);
}
else {
for (Node* node = _table[idx];node != nullptr;node = node->next) {
// key已经存在就直接返回
if (node->data == key) return make_pair(node, false);
}
Node* node = new Node(key);
// 头插
node->next = _table[idx];
_table[idx] = node;
}
++_size;
return make_pair(_table[idx], true);
}
void erase(const Key& key) {
// int idx = _hf(key) % _table.size();
int idx = table_index(key);
Node* dummy = new Node;
dummy->next = _table[idx];
Node* pre = dummy, * cur = dummy->next;
while (cur) {
if (cur->data == key) {
pre->next = cur->next;
_table[idx] = dummy->next;
delete cur;
--_size;
break;
}
pre = cur;
cur = cur->next;
}
delete dummy;
}
public:
void print()const {
int idx = 0;
for (Node* node : _table) {
cout << idx++ << ": ";
while (node) {
cout << node->data << " -> ";
node = node->next;
}
cout << "null" << endl;
}
cout << endl;
}
};