目录
一、AlertManager概述
1.1 alertmanager简介
1.2 AlertManager核心概念
1.2.1 分组
1.2.2 抑制
1.2.3 静默
1.2.4 客户的行为
1.2.5 高可用性
二、Alertmanager部署邮箱告警
2.1 邮箱配置
2.2 Alertmanager global和route路由配置
2.3 部署prometheus和alertManager
三、alertmanager部署发送钉钉告警
3.1 创建钉钉机器人
3.2 下载钉钉插件并启动
一、AlertManager概述
1.1 alertmanager简介
Prometheus的报警功能主要是利用Alertmanager这个组件。当Alertmanager接收到 Prometheus 端发送过来的 Alerts 时,Alertmanager 会对 Alerts 进行去重复,分组,按标签内容发送不同报警组,包括:邮件,微信,webhook。
使用prometheus进行告警分为两部分:Prometheus Server中的告警规则会Alertmanager发送。然后,Alertmanager管理这些告警,包括进行重复数据删除,分组和路由,以及告警的静默和抑制。
官网地址:Configuration | Prometheus
1.2 AlertManager核心概念
Alertmanager处理由Prometheus服务器等客户端应用程序发送的警报。它负责重复数据删除、分组并将它们路由到正确的接收器集成(如email、PagerDuty或OpsGenie)。它还负责静音和抑制警报。
下面描述了Alertmanager实现的核心概念。
1.2.1 分组
分组将性质相似的警报分类为单个通知。当许多系统同时发生故障并且可能同时触发数百到数千个警报时,这在较大的中断期间特别有用。
示例:当网络分区发生时,集群中正在运行数十或数百个服务实例。一半的服务实例不能再访问数据库。Prometheus中的警报规则被配置为在每个服务实例无法与数据库通信时向其发送警报。因此,数百个警报被发送到Alertmanager。
作为用户,人们只希望获得一个页面,同时仍然能够准确地看到哪些服务实例受到了影响。因此,可以将Alertmanager配置为按集群和alertname对警报进行分组,从而发送单个紧凑通知。
警报分组、分组通知的定时以及这些通知的接收者由配置文件中的路由树进行配置。
1.2.2 抑制
抑制是一个概念,如果某些警报已经触发,则抑制某些警报的通知。
示例:正在触发警报,通知整个集群不可访问。可以将Alertmanager配置为在触发特定警报时静音与该集群相关的所有其他警报。这可以防止数百或数千个与实际问题无关的警报发出通知。
抑制是通过Alertmanager的配置文件配置的。
1.2.3 静默
静默是一种简单的方法,可以在给定时间内将警报静音。静默是基于匹配器配置的,就像路由树一样。检查传入警报是否与活动静默的所有相等或正则表达式匹配器匹配。如果他们这样做,则不会为该警报发送通知。
静音是在Alertmanager的web界面中配置的。
1.2.4 客户的行为
Alertmanager对其客户端的行为有特殊的要求。这些仅与不使用Prometheus发送警报的高级用例相关。
1.2.5 高可用性
Alertmanager支持通过配置创建集群来实现高可用性。这可以使用——cluster-*标志进行配置。
二、Alertmanager部署邮箱告警
2.1 邮箱配置
进入163邮箱设置SMTP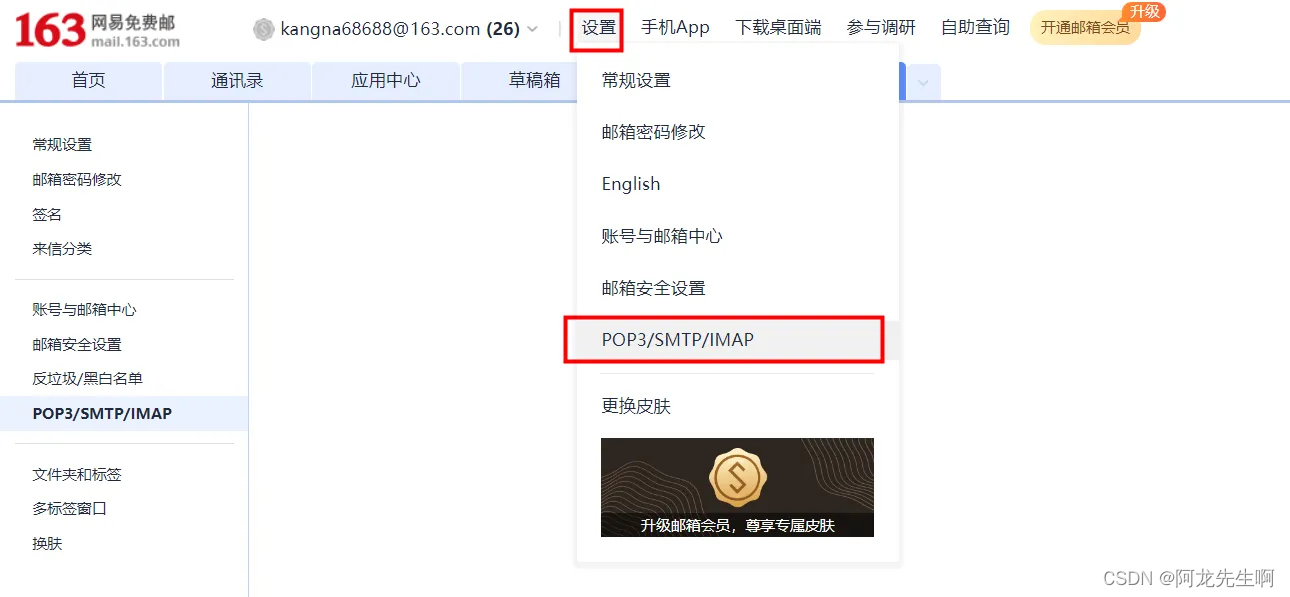
我们选择开启
开启后按照提示完成验证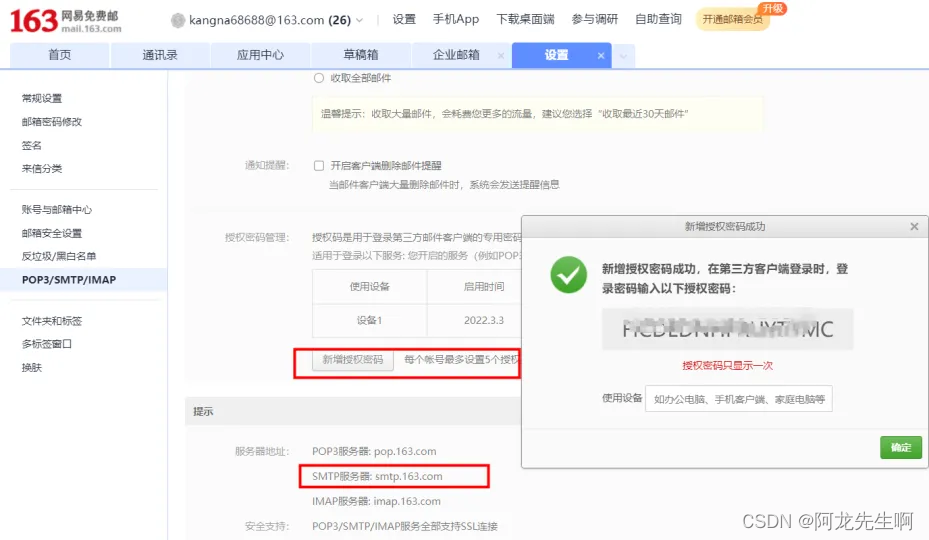
2.2 Alertmanager global和route路由配置
alertmanager-cm.yaml ConfigMap配置邮箱信息
kind: ConfigMap
apiVersion: v1
metadata:
name: alertmanager
namespace: monitor-sa
data:
alertmanager.yml: |-
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '1501157****@163.com'
smtp_auth_username: '1501157****'
smtp_auth_password: 'BDBPRMLNZGKWRFJP'
smtp_require_tls: false
route: # 配置告警分发策略
group_by: [alertname] # 告警分组
group_wait: 10s # 产生告警后等待发送时间
group_interval: 10s # 不同组告警间隔时间
repeat_interval: 10m # 重复告警间隔时间
receiver: default-receiver # 指定设置默认的告警接收人,在receivers下配置
receivers:
- name: 'default-receiver'
email_configs:
- to: '308913180@qq.com'
send_resolved: true
创建配置

2.3 部署prometheus和alertManager
创建configmanp定义告警规则 prometheus-alertmanager-cfg.yaml
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitor-sa
data:
prometheus.yml: |
rule_files:
- /etc/prometheus/rules.yml
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs:
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-node-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
- job_name: 'kubernetes-schedule'
scrape_interval: 5s
static_configs:
- targets: ['192.168.40.130:10251']
- job_name: 'kubernetes-controller-manager'
scrape_interval: 5s
static_configs:
- targets: ['192.168.40.130:10252']
- job_name: 'kubernetes-kube-proxy'
scrape_interval: 5s
static_configs:
- targets: ['192.168.40.130:10249','192.168.40.131:10249']
- job_name: 'kubernetes-etcd'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crt
cert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crt
key_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.key
scrape_interval: 5s
static_configs:
- targets: ['192.168.40.130:2379']
rules.yml: |
groups:
- name: example
rules:
- alert: kube-proxy的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: kube-proxy的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: scheduler的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: scheduler的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: controller-manager的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: controller-manager的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 0
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: apiserver的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: apiserver的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: etcd的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: etcd的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: kube-state-metrics的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"
value: "{{ $value }}%"
threshold: "80%"
- alert: kube-state-metrics的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 0
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"
value: "{{ $value }}%"
threshold: "90%"
- alert: coredns的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"
value: "{{ $value }}%"
threshold: "80%"
- alert: coredns的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"
value: "{{ $value }}%"
threshold: "90%"
- alert: kube-proxy打开句柄数>600
expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kube-proxy打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-schedule打开句柄数>600
expr: process_open_fds{job=~"kubernetes-schedule"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-schedule打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-schedule"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-controller-manager打开句柄数>600
expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-controller-manager打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-apiserver打开句柄数>600
expr: process_open_fds{job=~"kubernetes-apiserver"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-apiserver打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-etcd打开句柄数>600
expr: process_open_fds{job=~"kubernetes-etcd"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-etcd打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-etcd"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: coredns
expr: process_open_fds{k8s_app=~"kube-dns"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600"
value: "{{ $value }}"
- alert: coredns
expr: process_open_fds{k8s_app=~"kube-dns"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000"
value: "{{ $value }}"
- alert: kube-proxy
expr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: scheduler
expr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kubernetes-controller-manager
expr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kubernetes-apiserver
expr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kubernetes-etcd
expr: process_virtual_memory_bytes{job=~"kubernetes-etcd"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kube-dns
expr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: HttpRequestsAvg
expr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000"
value: "{{ $value }}"
threshold: "1000"
- alert: Pod_restarts
expr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor-sa"} > 0
for: 2s
labels:
severity: warnning
annotations:
description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的"
value: "{{ $value }}"
threshold: "0"
- alert: Pod_waiting
expr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1
for: 2s
labels:
team: admin
annotations:
description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中"
value: "{{ $value }}"
threshold: "1"
- alert: Pod_terminated
expr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1
for: 2s
labels:
team: admin
annotations:
description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除"
value: "{{ $value }}"
threshold: "1"
- alert: Etcd_leader
expr: etcd_server_has_leader{job="kubernetes-etcd"} == 0
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader"
value: "{{ $value }}"
threshold: "0"
- alert: Etcd_leader_changes
expr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变"
value: "{{ $value }}"
threshold: "0"
- alert: Etcd_failed
expr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败"
value: "{{ $value }}"
threshold: "0"
- alert: Etcd_db_total_size
expr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G"
value: "{{ $value }}"
threshold: "10G"
- alert: Endpoint_ready
expr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1
for: 2s
labels:
team: admin
annotations:
description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用"
value: "{{ $value }}"
threshold: "1"
- name: 物理节点状态-监控告警
rules:
- alert: 物理节点cpu使用率
expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90
for: 2s
labels:
severity: ccritical
annotations:
summary: "{{ $labels.instance }}cpu使用率过高"
description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理"
- alert: 物理节点内存使用率
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90
for: 2s
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }}内存使用率过高"
description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理"
- alert: InstanceDown
expr: up == 0
for: 2s
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }}: 服务器宕机"
description: "{{ $labels.instance }}: 服务器延时超过2分钟"
- alert: 物理节点磁盘的IO性能
expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"
description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"
- alert: 入网流量带宽
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 流入网络带宽过高!"
description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"
- alert: 出网流量带宽
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 流出网络带宽过高!"
description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"
- alert: TCP会话
expr: node_netstat_Tcp_CurrEstab > 1000
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"
description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"
- alert: 磁盘容量
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"
description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"部署
kubectl delete -f prometheus-alertmanager-cfg.yaml
kubectl apply -f prometheus-alertmanager-cfg.yaml
部署prometheus需要生成一个etcd-certs
kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crtprometheus-alertmanager-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-server
namespace: monitor-sa
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
component: server
template:
metadata:
labels:
app: prometheus
component: server
annotations:
prometheus.io/scrape: 'false'
spec:
nodeName: node1
serviceAccountName: monitor
containers:
- name: prometheus
image: prom/prometheus:v2.2.1
imagePullPolicy: IfNotPresent
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention=24h"
- "--web.enable-lifecycle"
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: /etc/prometheus
name: prometheus-config
- mountPath: /prometheus/
name: prometheus-storage-volume
- name: k8s-certs
mountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/
- name: alertmanager
image: prom/alertmanager:v0.14.0
imagePullPolicy: IfNotPresent
args:
- "--config.file=/etc/alertmanager/alertmanager.yml"
- "--log.level=debug"
ports:
- containerPort: 9093
protocol: TCP
name: alertmanager
volumeMounts:
- name: alertmanager-config
mountPath: /etc/alertmanager
- name: alertmanager-storage
mountPath: /alertmanager
- name: localtime
mountPath: /etc/localtime
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
- name: prometheus-storage-volume
hostPath:
path: /data
type: Directory
- name: k8s-certs
secret:
secretName: etcd-certs
- name: alertmanager-config
configMap:
name: alertmanager
- name: alertmanager-storage
hostPath:
path: /data/alertmanager
type: DirectoryOrCreate
- name: localtime
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai通过kubectl apply更新yaml文件
kubectl apply -f prometheus-alertmanager-deploy.yaml
kubectl get pods -n monitor-sa | grep prometheus显示如下,可看到pod状态是running,说明prometheus部署成功

alertmanager-svc.yaml
---
apiVersion: v1
kind: Service
metadata:
labels:
name: prometheus
kubernetes.io/cluster-service: 'true'
name: alertmanager
namespace: monitor-sa
spec:
ports:
- name: alertmanager
nodePort: 30066
port: 9093
protocol: TCP
targetPort: 9093
selector:
app: prometheus
sessionAffinity: None
type: NodePort
执行部署命令
kubectl apply -f alertmanager-svc.yaml
kubectl get svc -n monitor-sa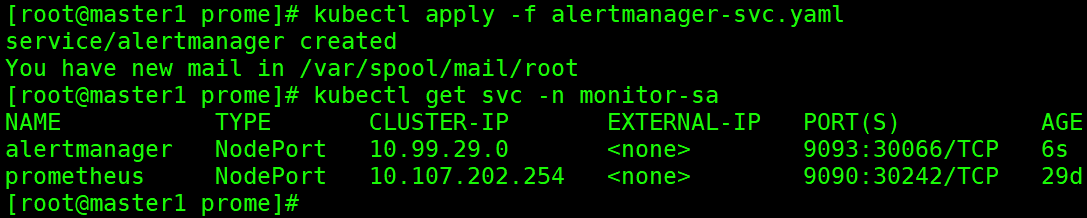
登录AlertManager http://192.168.2.139:30066/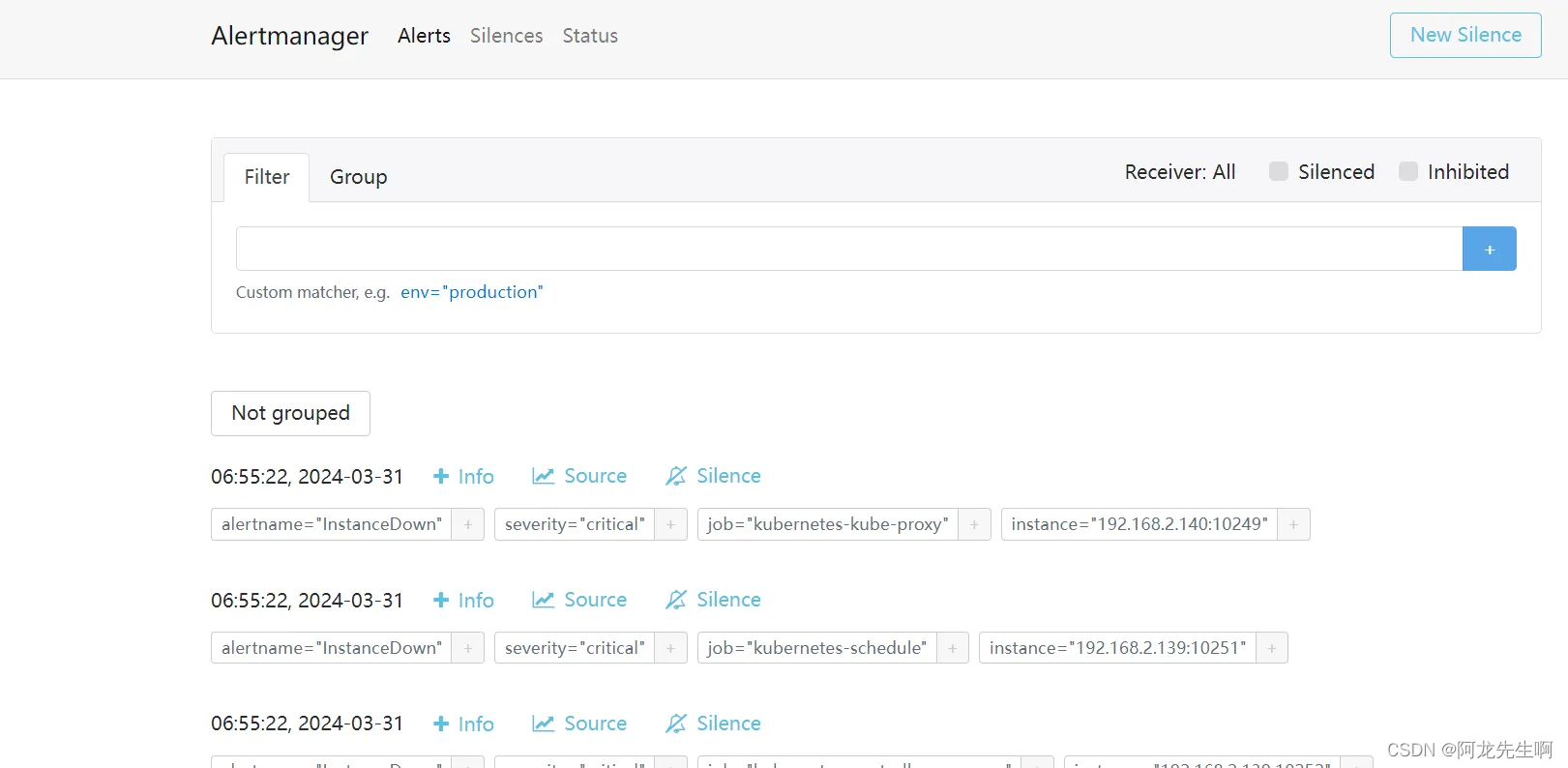
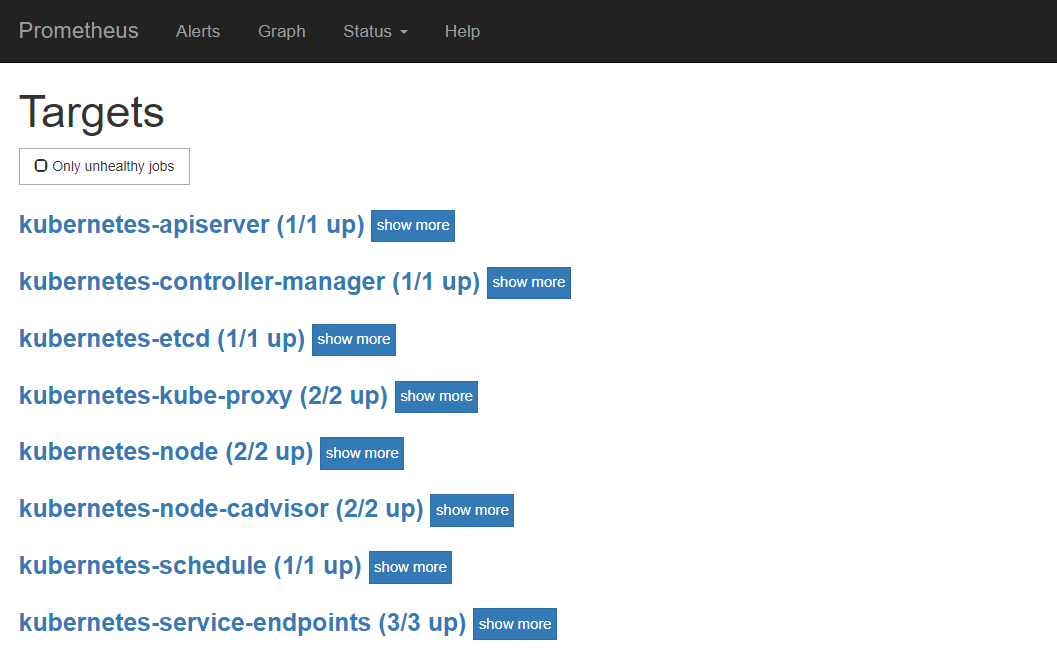
访问prometheus的web界面
Alertmanger 告警触发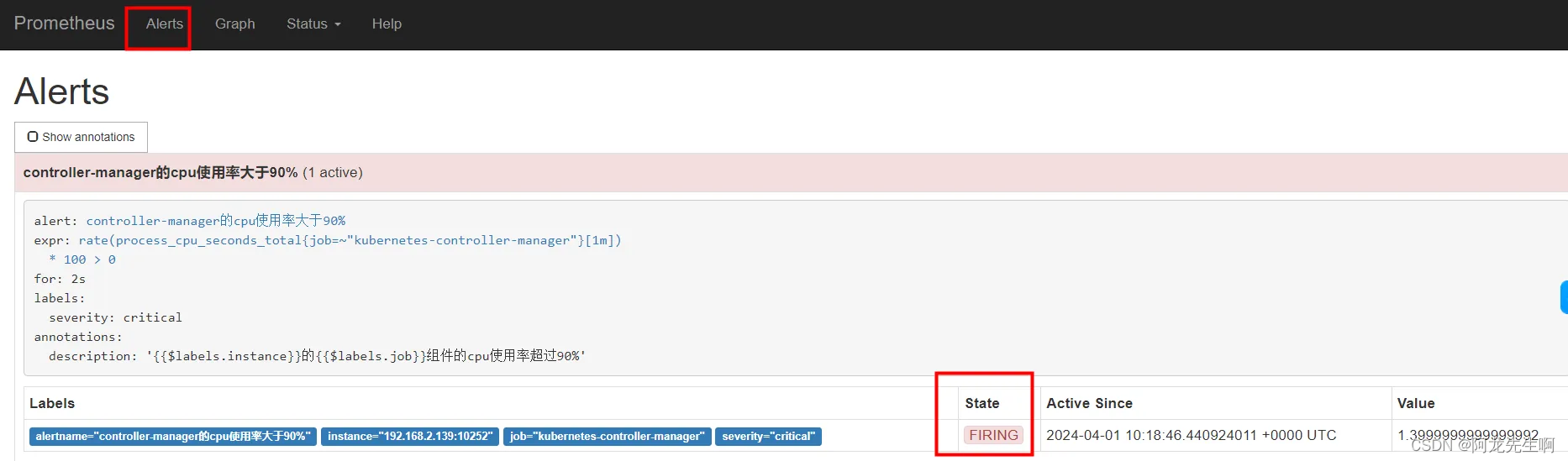
查看邮件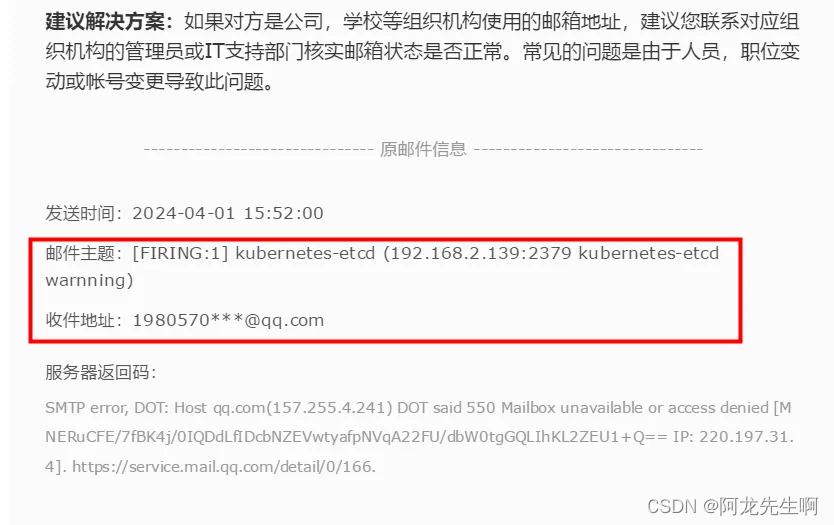
可能是发送太多
三、alertmanager部署发送钉钉告警
3.1 创建钉钉机器人
打开电脑版钉钉,创建一个群,创建自定义机器人。
3.2 下载钉钉插件并启动
prometheus-webhook-dingtalk
# 下载钉钉插件 prometheus-webhook-dingtalk
二进制下载地址: https://github.com/timonwong/prometheus-webhook-dingtalk/releases
tar zxvf prometheus-webhook-dingtalk-0.3.0.linux-amd64.tar.gz
cd prometheus-webhook-dingtalk-0.3.0.linux-amd64
# 启动
nohup ./prometheus-webhook-dingtalk --web.listen-address="0.0.0.0:8060" --ding.profile="cluster1=https://oapi.dingtalk.com/robot/send?access_token=749b2f448e357b7ffc1bff7b01d3c26a750dfaec75651680fdc8703152837f65" &修改alertmanager-cm.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: alertmanager
namespace: monitor-sa
data:
alertmanager.yml: |-
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '1501157****@163.com'
smtp_auth_username: '1501157****'
smtp_auth_password: 'BDBPRMLNZGK****'
smtp_require_tls: false
route:
group_by: [alertname]
group_wait: 10s
group_interval: 10s
repeat_interval: 10m
receiver: cluster1
receivers:
- name: cluster1
webhook_configs:
- url: 'http://192.168.2.139:8060/dingtalk/cluster1/send'
send_resolved: true 重修部署prometheus-alertmanager-deploy
kubectl apply -f prometheus-alertmanager-cfg.yaml
kubectl apply -f prometheus-alertmanager-deploy.yaml
kubectl logs -f prometheus-server-55cd9cb6d7-h8ntr -n monitor-sa -c alertmanageralertmanager日志
钉钉告警发送成功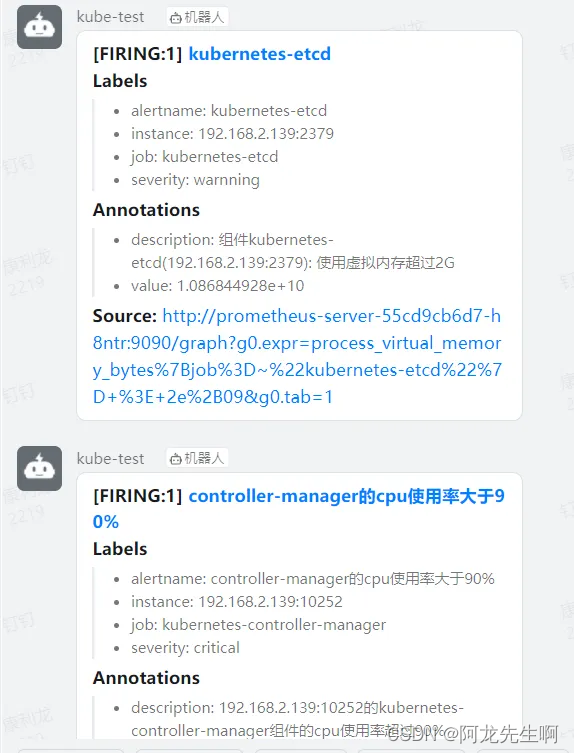
Alertmanager 两个告警发送成功
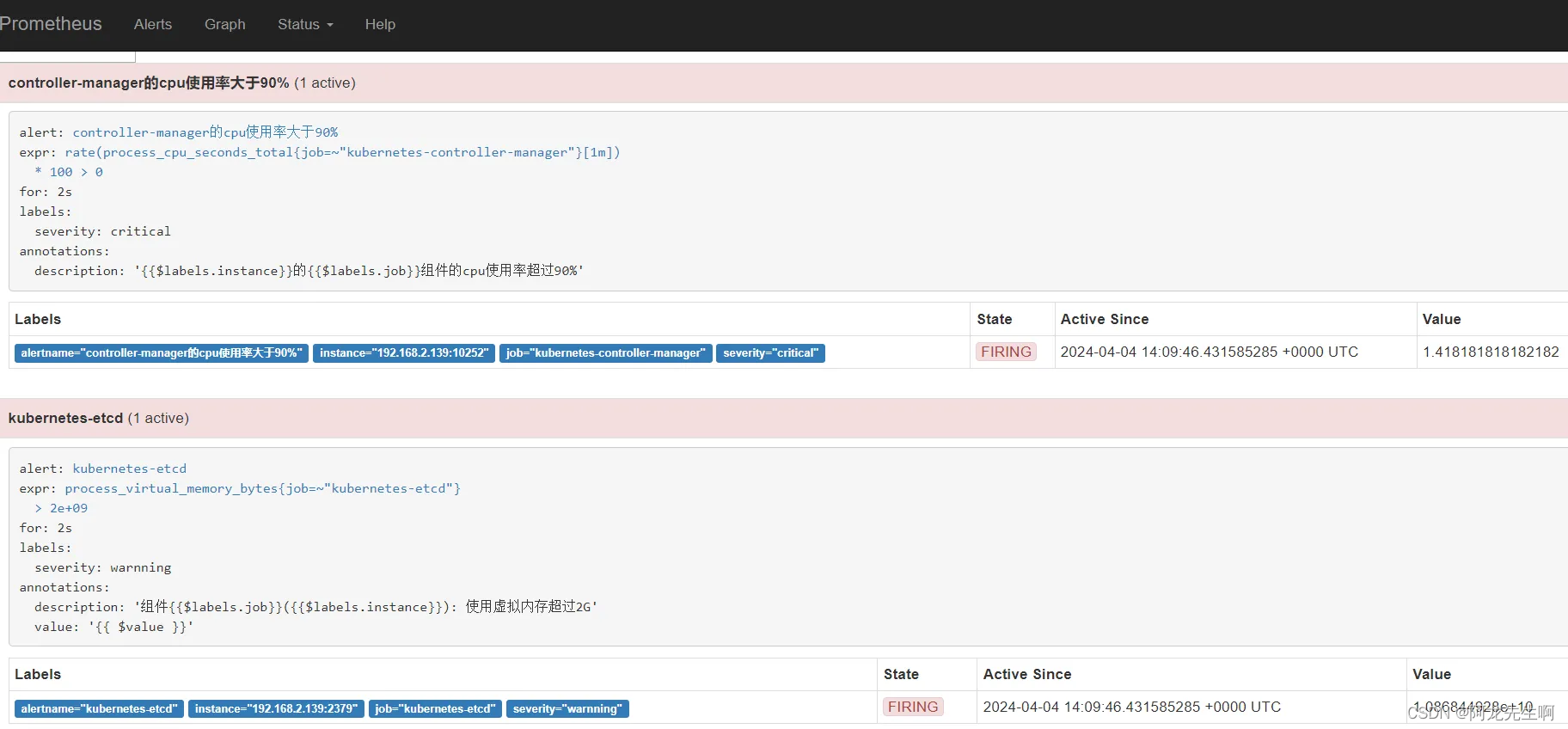
参考:Prometheus监控实战系列十三:告警管理_prometheus系统监控报警-CSDN博客