TOPSIS法,全称 Technique for Order Preference by Similarity to an Ideal Solution,是由C.L.Hwang和K.Yoon于1981年首次提出的 。这是一种多目标决策分析中常用的有效方法,也被称作优劣解距离法 。 TOPSIS法的基本原理是通过检测评价对象与最优解、最劣解的距离来进行排序。如果一个方案距离理想最优解越近,距离最劣解越远,我们就认为这个方案更好 。
TOPSIS法的主要适用场景包括:
土地利用规划:在土地资源管理和规划中,TOPSIS法可以用来评估不同土地利用方案的优劣,帮助决策者选择最佳的土地利用策略 。
物料选择评估:在供应链管理和物料采购中,TOPSIS法可以用来评估不同供应商提供的物料质量,帮助企业选择性价比最高的物料 。
项目投资:在金融管理和投资决策中,TOPSIS法可以用来评估不同投资项目的风险和收益,帮助投资者选择最有利的投资方案 。
医疗卫生:在医疗管理和健康政策制定中,TOPSIS法可以用来评估不同治疗方案的效果,帮助医生和患者选择最佳的治疗方案。
指标类型:
| 极大型(效益型) | 期望取值越大越好 |
| 极小型 | 期望取值越小越好 |
| 中间型 | 期望取值为适当的中间值最好 |
| 区间型 | 期望取值落在某一个确定的区间内最好 |
一致化处理(正向化):所谓一致化处理就是将评价指标的类型进行统一;使得表中任意属性下性能越优的方案变换后的属性值越大(极大型)。
无量纲化处理:不同指标,不同单位。
归一化:不同指标,不同数值大小。
构造计算评分公式:

TOPSIS法符号说明:
设:多属性决策方案集A={a1,a2,……,am},即有m个可行方案;
衡量方案优劣的属性变量(指标)为x1,x2,……,xn,即有n个评价指标这时方案集A中的方案ai(i=1,2,……,m)的n个属性值构成了向量[ai1,ai2,……,ain]它作为n维空间中的一个点,则每个方案依照其各项指标的值就对应n维空间中一个坐标点。
举个栗子:以下是五所高校(ai)的基本情况,我们要根据“人均专著”(x1)、“逾期毕业率”(x2)两个方面来为这五所高校进行一个排名。
| 序号 | 人均专著/(本/人) | 逾期毕业率/% |
| 1 | 0.1 | 4.1 |
| 2 | 0.3 | 5.1 |
| 3 | 0.4 | 6.8 |
| 4 | 0.8 | 0.3 |
| 5 | 1.2 | 1.7 |
正理想解C+是设想各指标属性都达到最满意值的解[1.2,0.3]
负理想解C-是设想各指标属性都达到最不满意值的解 [0.1,6.8]
在n维空间中,算出方案集D中的各备选方案ai与正理想解C+和负理想解C-的距离:
d*:备选方案di(i=1,2,……,m)到正理想解的距离;
d-:备选方案di(i=1,2,……,m)到负理想解的距离。
理论介绍:
第一步:将n个评价指标x1,x2,……,xn,看成n条坐标轴,由此可以构造出一个n维空间,则每个方案依照其各项指标的数据就对应n维空间中每一个坐标点。
第二步:针对各项指标从所有待评价方案中选出该指标的最优值(正理想解,对应最有坐标点)和最差值(负理想解,对应最差标点),依次求出各个待评价方案的坐标点分别最优坐标点和最差坐标点的距离d*和d-。
第三步:构造相对贴进度(评价参考值)f:
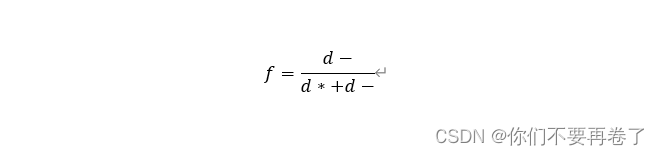
则f值越大代表评价结果越优。
算法步骤:
(1)构造决策矩阵A=(aij)m×n,每一列是一个评价指标,每一行是一个待评价方案;
为了去掉量纲的影响,为了方便比较,做规范化处理得到B=(bij)m×n,其中:
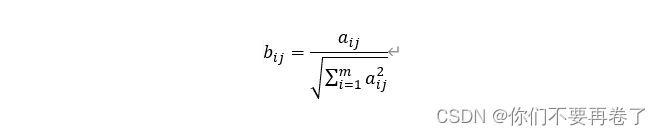
注:该规范化(向量归一化法)处理后,各评价方案的同一评价指标的平方和为1.
(2)根据每个评价指标对评价结果的贡献程度不同,指定不同的权重:
W=[w1,w2,……,wn],将B的第j列乘以其权重wj,得到带权的规范矩阵C=(cij)m×n。
(3)确定正理想解C+和负理想解C-:
C+=[c1+,c2+,……,cn+];C-=[c1-,c2-, ……,cn-];
 (4)计算每个待评价方案到正理想解和负理想解的距离:
(4)计算每个待评价方案到正理想解和负理想解的距离:
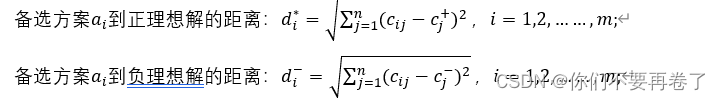 (5)计算每个待评价方案的相对贴进度(评价参考值):
(5)计算每个待评价方案的相对贴进度(评价参考值):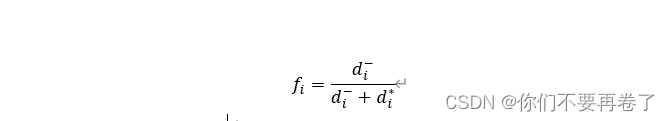
再将![]() 从大到小排列 ,得到各备选方案的优先序。
从大到小排列 ,得到各备选方案的优先序。
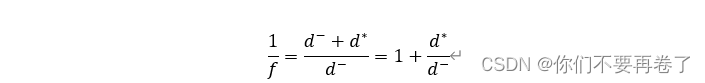
案例分析:以下是五所高校的基本情况,我们要根据“人均专著”、“师生比”、“科研经费”、“逾期毕业率”四个方面围着五所高校进行一个评估。
| 序号 | 人均专著/(本/人) | 师生比 | 科研经费/(万元/年) | 逾期毕业率/% |
| 1 | 0.1 | 4 | 5000 | 4.1 |
| 2 | 0.3 | 5 | 7000 | 5.1 |
| 3 | 0.4 | 9 | 6000 | 6.8 |
| 4 | 0.8 | 11 | 10000 | 2.6 |
| 5 | 1.2 | 2 | 800 | 1.7 |
第一步:导入数据、数据预处理、构建决策矩阵
先把数据规范化,规范化的作用:
a.正向化 b.无量纲化 c.归一化
方法
法1.线性变换法:将原始决策矩阵A =(aij)m×n,进行线性比例变换
若x为极大型(效益型)属性: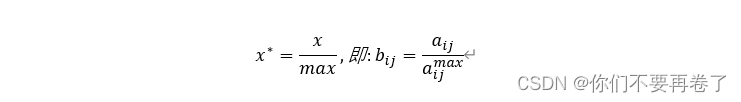
若x为极小型(成本型)属性: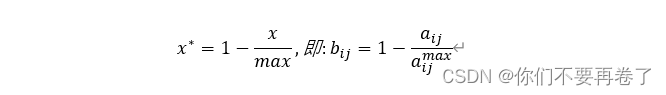
注:经过该变换之后的bij最优值不一定是1,最差值不一定为0.
0<=bij<=1;所有指标均为正向指标。
法二、极差变换法(使变换后的每个属性的最优值为1,最差为0)
若x为极大型(效益型)属性: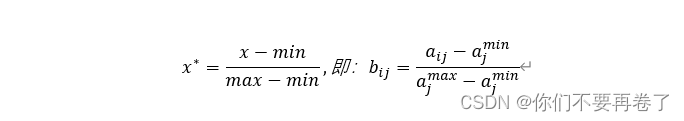 若x为极小型(成本型)属性:
若x为极小型(成本型)属性:
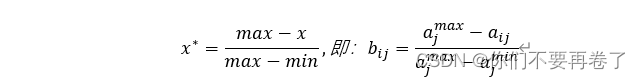
法三、区间型属性的变换:若x区间型属性
假设给定最优属性区间为[c,d],![]() 为无法容忍下限,
为无法容忍下限,![]() 为无法容忍下限
为无法容忍下限

若以该案列为例:假设2某地高校师生比的最有区间为[5,9],且a2-=1;a2*=12.
| 序号 | 师生比 |
| 1 | 4 |
| 2 | 5 |
| 3 | 9 |
| 4 | 11 |
| 5 | 2 |
数据处理——>
| 序号 | 师生比 | 变换后的师生比 |
| 1 | 4 | 0.75 |
| 2 | 5 | 1 |
| 3 | 9 | 1 |
| 4 | 11 | 0.3333333 |
| 5 | 2 | 0.25 |
法四、中间属性的变换
若x为中间型属性,且假设最优值为k,那么:
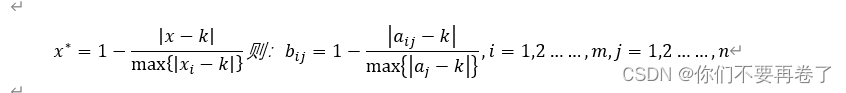 比如:
比如:
| 生产线 | 零件长/cm |
| 1 | 12 |
| 2 | 11 |
| 3 | 13 |
| 4 | 15 |
假设零件在12cm为最佳,则处理后的矩阵为
| 生产线 | 零件长/cm | 变换后的零件长/cm |
| 1 | 12 | 1 |
| 2 | 11 | 1/3 |
| 3 | 13 | 2/3 |
| 4 | 15 | 0 |
法五、向量归一化(使得每列平方和为1)
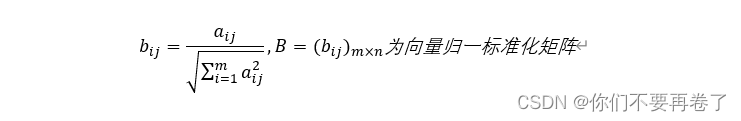 注:向量归一标准化后:
注:向量归一标准化后:
1、0<=bij<=1;
2、正、负向指标的方向没有发生变化
法六、标准样本变换法(大数定律):
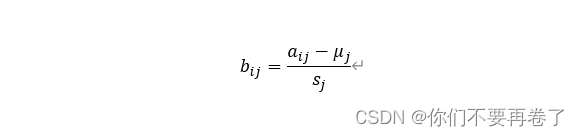
| 序号 | 人均专著/(本/人) | 师生比 | 科研经费/(万元/年) | 逾期毕业率/% |
| 1 | 0.1 | 4 | 5000 | 4.1 |
| 2 | 0.3 | 5 | 7000 | 5.1 |
| 3 | 0.4 | 9 | 6000 | 6.8 |
| 4 | 0.8 | 11 | 10000 | 2.6 |
| 5 | 1.2 | 2 | 800 | 1.7 |
称B=(bij)m×n 为向量标准样本变换矩阵。
注:经标准样本变换后标准化矩阵的样本均值为0,方差为1.
先对第二列进行区间型属性的变换,再对所有属性进行规范化(向量归一法)
| 序号 | 人均专著/(本/人) | 师生比 | 科研经费/(万元/年) | 逾期毕业率/% |
| 1 | 0. 065372045 | 0.45341345 | 0.344508214 | 0.412670364 |
| 2 | 0. 196116135 | 0.604551266 | 0. 4823115 | 0.513321672 |
| 3 | 0. 26148818 | 0.604551266 | 0. 413409857 | 0.684428896 |
| 4 | 0. 52297636 | 0.201517089 | 0. 689016428 | 0.261693401 |
| 5 | 0. 784464541 | 0.151137817 | 0. 055121314 | 0.171107224 |

确定正理想解和负理想解
正理想解C+=[0.235339362,0.1209102531,0.275606571,0.017110722]
负理想解C-=[0.019611614,0.030227563,0.022048526,0.06844289]
计算各方案到正理想解和负理想解的距离
d*:备选方案ai(i=1,2,……,m)到正理想解的距离;
d-:备选方案ai(i=1,2,……,m)到负理想解的距离
| 序号 | d* | d- |
| 1 | 0.258892719 | 0.133388582 |
| 2 | 0.197892046 | 0.198124257 |
| 3 | 0. 198503937 | 0. 179510995 |
| 4 | 0. 11284222 | 0. 291592888 |
| 5 | 0. 269286154 | 0. 22175088 |
计算各方案的相近贴进度
| 序号 | fi | 排行 |
| 4 | 0.72098807 | 1 |
| 2 | 0.500293184 | 2 |
| 3 | 0.474878053 | 3 |
| 5 | 0.451597059 | 4 |
| 1 | 0.340032985 | 5 |
在实际应用中,TOPSIS法因其简便、直观和易于理解的特性,已经被广泛应用于各个领域。然而,需要注意的是,TOPSIS法也有其局限性,比如对数据敏感性高、对样本容量的要求、以及对权重确定的主观性等问题 。因此,在使用TOPSIS法时,应结合实际情况和具体需求,合理考虑其适用性和局限性.
看代码部分:
%% 第一步:把数据复制到工作区,并将这个矩阵命名为X
% (1)在工作区右键,点击新建(Ctrl+N),输入变量名称为X
% (2)在Excel中复制数据,再回到Excel中右键,点击粘贴Excel数据(Ctrl+Shift+V)
% (3)关掉这个窗口,点击X变量,右键另存为,保存为mat文件(下次就不用复制粘贴了,只需使用load命令即可加载数据)
% (4)注意,代码和数据要放在同一个目录下哦,且Matlab的当前文件夹也要是这个目录。
clear;clc
load data_water_quality.mat
%% 注意:如果提示: 错误使用 load,无法读取文件 'data_water_quality.mat'。没有此类文件或目录。
% 那么原因是因为你的Matlab的当前文件夹中不存在这个文件
% 可以使用cd函数修改Matlab的当前文件夹
% 比如说,我的代码和数据放在了: D:第2讲.TOPSIS法(优劣解距离法)\代码和例题数据
% 那么我就可以输入命令:
% cd 'D:第2讲.TOPSIS法(优劣解距离法)\代码和例题数据'
% 也可以看我更新的视频:“更新9_Topsis代码为什么运行失败_得分结果怎么可视化以及权重的确定如何更加准确”,里面有介绍
%% 第二步:判断是否需要正向化
[n,m] = size(X);
disp(['共有' num2str(n) '个评价对象, ' num2str(m) '个评价指标'])
Judge = input(['这' num2str(m) '个指标是否需要经过正向化处理,需要请输入1 ,不需要输入0: ']);
if Judge == 1
Position = input('请输入需要正向化处理的指标所在的列,例如第2、3、6三列需要处理,那么你需要输入[2,3,6]: '); %[2,3,4]
disp('请输入需要处理的这些列的指标类型(1:极小型, 2:中间型, 3:区间型) ')
Type = input('例如:第2列是极小型,第3列是区间型,第6列是中间型,就输入[1,3,2]: '); %[2,1,3]
% 注意,Position和Type是两个同维度的行向量
for i = 1 : size(Position,2) %这里需要对这些列分别处理,因此我们需要知道一共要处理的次数,即循环的次数
X(:,Position(i)) = Positivization(X(:,Position(i)),Type(i),Position(i));
% Positivization是我们自己定义的函数,其作用是进行正向化,其一共接收三个参数
% 第一个参数是要正向化处理的那一列向量 X(:,Position(i)) 回顾上一讲的知识,X(:,n)表示取第n列的全部元素
% 第二个参数是对应的这一列的指标类型(1:极小型, 2:中间型, 3:区间型)
% 第三个参数是告诉函数我们正在处理的是原始矩阵中的哪一列
% 该函数有一个返回值,它返回正向化之后的指标,我们可以将其直接赋值给我们原始要处理的那一列向量
end
disp('正向化后的矩阵 X = ')
disp(X)
end
%% 第三步:对正向化后的矩阵进行标准化
Z = X ./ repmat(sum(X.*X) .^ 0.5, n, 1);
disp('标准化矩阵 Z = ')
disp(Z)
%% 第四步:计算与最大值的距离和最小值的距离,并算出得分
D_P = sum([(Z - repmat(max(Z),n,1)) .^ 2 ],2) .^ 0.5; % D+ 与最大值的距离向量
D_N = sum([(Z - repmat(min(Z),n,1)) .^ 2 ],2) .^ 0.5; % D- 与最小值的距离向量
S = D_N ./ (D_P+D_N); % 未归一化的得分
disp('最后的得分为:')
stand_S = S / sum(S)
[sorted_S,index] = sort(stand_S ,'descend')
% A = magic(5) % 幻方矩阵
% M = magic(n)返回由1到n^2的整数构成并且总行数和总列数相等的n×n矩阵。阶次n必须为大于或等于3的标量。
% sort(A)若A是向量不管是列还是行向量,默认都是对A进行升序排列。sort(A)是默认的升序,而sort(A,'descend')是降序排序。
% sort(A)若A是矩阵,默认对A的各列进行升序排列
% sort(A,dim)
% dim=1时等效sort(A)
% dim=2时表示对A中的各行元素升序排列
% A = [2,1,3,8]
% Matlab中给一维向量排序是使用sort函数:sort(A),排序是按升序进行的,其中A为待排序的向量;
% 若欲保留排列前的索引,则可用 [sA,index] = sort(A,'descend') ,排序后,sA是排序好的向量,index是向量sA中对A的索引。
% sA = 8 3 2 1
% index = 4 3 1 2
% % 注意:代码文件仅供参考,一定不要直接用于自己的数模论文中
% % 国赛对于论文的查重要求非常严格,代码雷同也算作抄袭
% % 视频中提到的附件可在售后群(购买后收到的那个无忧自动发货的短信中有加入方式)的群文件中下载。包括讲义、代码、我视频中推荐的资料等。
% % 关注我的微信公众号《数学建模学习交流》,后台发送“软件”两个字,可获得常见的建模软件下载方法;发送“数据”两个字,可获得建模数据的获取方法;发送“画图”两个字,可获得数学建模中常见的画图方法。另外,也可以看看公众号的历史文章,里面发布的都是对大家有帮助的技巧。
% % 购买更多优质精选的数学建模资料,可关注我的微信公众号《数学建模学习交流》,在后台发送“买”这个字即可进入店铺(我的微店地址:https://weidian.com/?userid=1372657210)进行购买。
% % 视频价格不贵,但价值很高。单人购买观看只需要58元,三人购买人均仅需46元,视频本身也是下载到本地观看的,所以请大家不要侵犯知识产权,对视频或者资料进行二次销售。
% % 如何修改代码避免查重的方法:https://www.bilibili.com/video/av59423231(必看)






![FileNotFoundError: [Errno 2] No such file or directory: ‘llvm-config‘](https://img-blog.csdnimg.cn/direct/ba8556612b334d8c94a656517bf6e4f1.png)