论文笔记:Context-aware multi-head self-attentional neural network model fornext location prediction-CSDN博客
对应命令行里
python preprocessing/geolife.py 20这一句
1 读取geolife数据
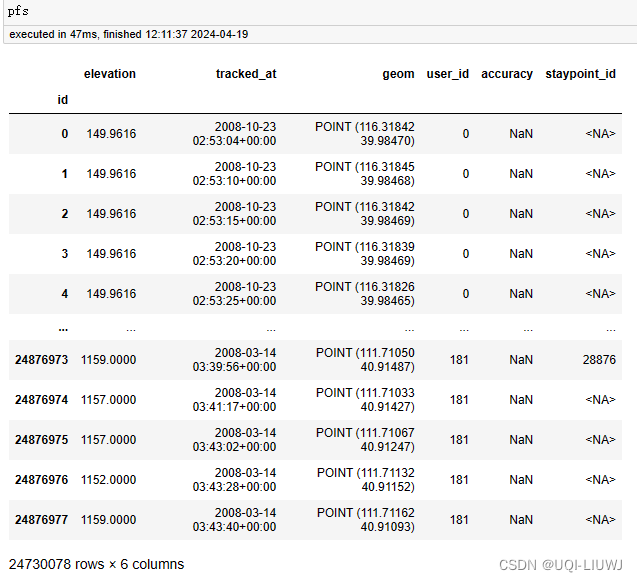
pfs, _ = read_geolife(config["raw_geolife"], print_progress=True)
2 生成staypoint 数据
根据geolife数据,使用滑动窗口的方法获取staypoint
同时geolife DataFrame加一列staypoint
pfs, sp = pfs.as_positionfixes.generate_staypoints(
gap_threshold=24 * 60,
include_last=True,
print_progress=True,
dist_threshold=200,
time_threshold=30,
n_jobs=-1
) 

2.1 判断staypoint是否是活动对应的staypoint
sp = sp.as_staypoints.create_activity_flag(
method="time_threshold",
time_threshold=25)如果staypoint停留时间>25min,那么是为一个活跃的staypoint

3 在两个stypoint之间的部分创建行程段
在两个stypoint之间的部分创建行程段
【如果两个非staypoint之间的时间间隔大于阈值的话,视为两个行程段】
pfs, tpls = pfs.as_positionfixes.generate_triplegs(sp)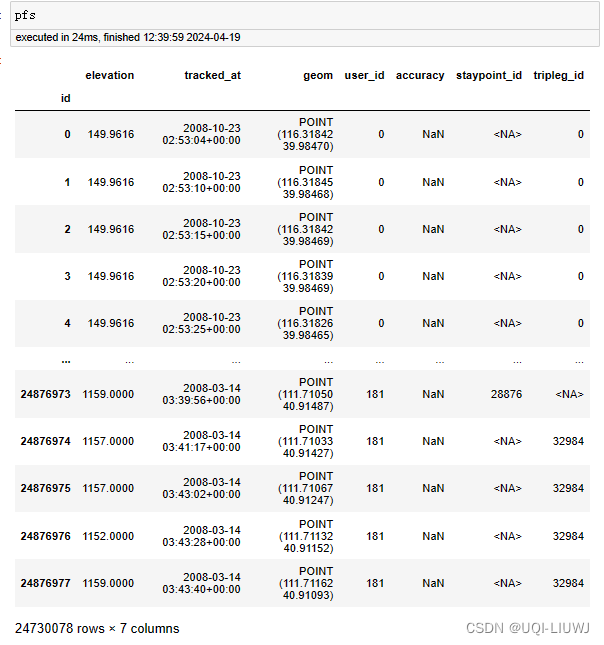
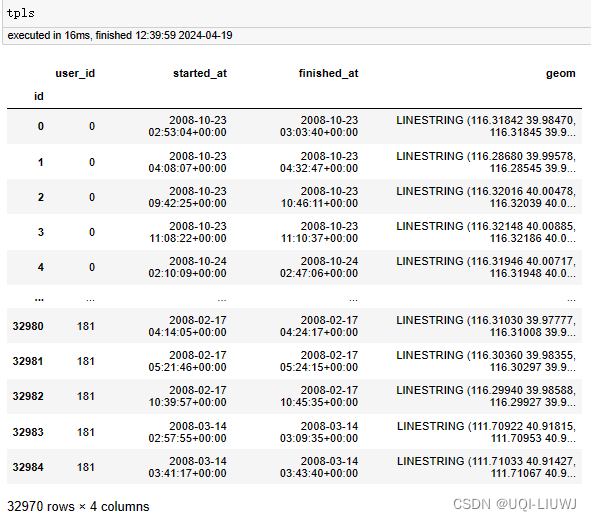
4 根据停留点和行程段创建trip数据集
sp, tpls, trips = generate_trips(sp, tpls, add_geometry=False)
staypoint之前的trip_id,之后的trip_id
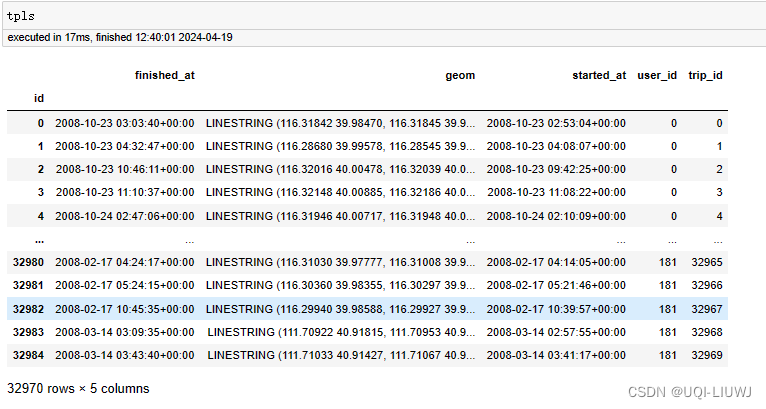
行程和行程的trip_id
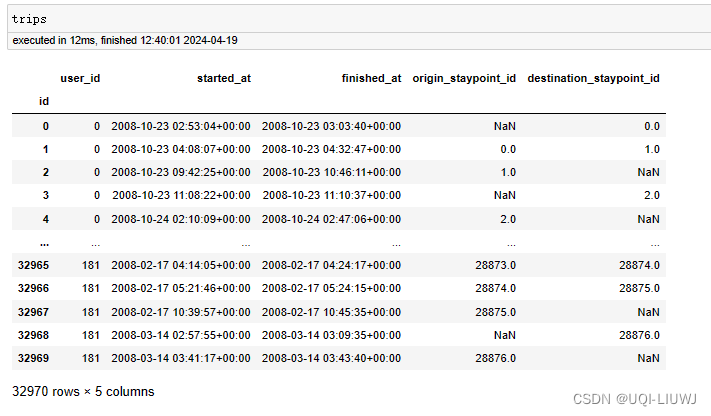
行程和行程的始末staypoint_id
5 每个用户时间跟踪质量相关内容
quality_path = os.path.join(".", "data", "quality")
quality_file = os.path.join(quality_path, "geolife_slide_filtered.csv")
quality_filter = {"day_filter": 50, "window_size": 10}
valid_user = calculate_user_quality(
sp.copy(),
trips.copy(),
quality_file,
quality_filter)
'''
array([ 0, 2, 3, 4, 5, 10, 11, 12, 13, 14, 15, 17, 20,
22, 24, 25, 26, 28, 30, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 50, 51, 52, 55, 56, 58, 59,
62, 63, 65, 66, 67, 68, 71, 73, 74, 78, 81, 82, 83,
84, 85, 89, 91, 92, 95, 96, 97, 99, 101, 102, 104, 110,
111, 112, 114, 115, 119, 122, 125, 126, 128, 130, 131, 132, 133,
134, 140, 142, 144, 147, 153, 155, 163, 167, 168, 172, 174, 179,
181], dtype=int64)
'''
'''
valid_user——有记录天数大于day_filter天的那些user_id
这个函数同时返回了一个csv文件,记录了这些user_id的的时间跟踪质量
'''这个函数的原理如下:
5.0 准备部分
trips["started_at"] = pd.to_datetime(trips["started_at"]).dt.tz_localize(None)
trips["finished_at"] = pd.to_datetime(trips["finished_at"]).dt.tz_localize(None)
sp["started_at"] = pd.to_datetime(sp["started_at"]).dt.tz_localize(None)
sp["finished_at"] = pd.to_datetime(sp["finished_at"]).dt.tz_localize(None)
sp["type"] = "sp"
trips["type"] = "tpl"
df_all = pd.concat([sp, trips])
5.1 横跨多天的staypoint/行程段进行拆分
df_all = _split_overlaps(df_all, granularity="day")
'''
如果一个trips/staypoint横跨多天了,那么就拆分成两个trips/staypoint
'''
5.2 更新每个trips/staypoint的持续时
df_all["duration"] = (df_all["finished_at"] - df_all["started_at"]).dt.total_seconds()5.3 计算每个用户的时间跟踪质量
trackintel 笔记:generate_staypoints,create_activity_flag-CSDN博客
total_quality = temporal_tracking_quality(df_all, granularity="all")
某一用户从第一条记录~最后一条记录 这一段时间内,有多少比例的时间是在staypoint/trip的范围内的
【但这个好像没啥用?】
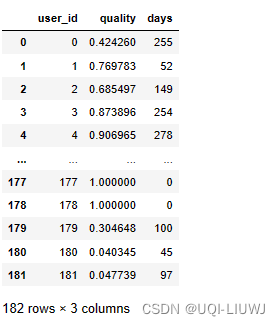
5.4 计算每个用户第一条&最后一条记录之间的天数跨度
total_quality["days"] = (
df_all.groupby("user_id").apply(lambda x: (x["finished_at"].max() - x["started_at"].min()).days).values
)
5.5 筛选时间跨度>阈值的user id
user_filter_day = (
total_quality.loc[(total_quality["days"] > quality_filter["day_filter"])]
.reset_index(drop=True)["user_id"]
.unique()
)
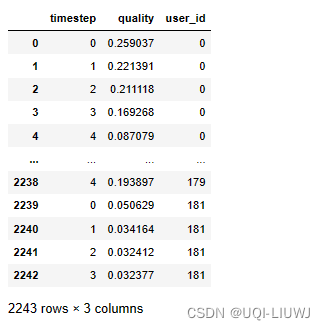
5.6 user_id,每window_size周的时间跟踪质量
sliding_quality = (
df_all.groupby("user_id")
.apply(_get_tracking_quality, window_size=quality_filter["window_size"])
.reset_index(drop=True)
) 
5.6.1 _get_tracking_quality
def _get_tracking_quality(df, window_size):
weeks = (df["finished_at"].max() - df["started_at"].min()).days // 7
'''
一个user有几周有数据
'''
start_date = df["started_at"].min().date()
quality_list = []
# construct the sliding week gdf
for i in range(0, weeks - window_size + 1):
curr_start = datetime.datetime.combine(start_date + datetime.timedelta(weeks=i), datetime.time())
curr_end = datetime.datetime.combine(curr_start + datetime.timedelta(weeks=window_size), datetime.time())
#这里window_size=10,也即10周
# the total df for this time window
cAll_gdf = df.loc[(df["started_at"] >= curr_start) & (df["finished_at"] < curr_end)]
#这10周这个用户的记录
if cAll_gdf.shape[0] == 0:
continue
total_sec = (curr_end - curr_start).total_seconds()
quality_list.append([i, cAll_gdf["duration"].sum() / total_sec])
#这10周有记录的比例
ret = pd.DataFrame(quality_list, columns=["timestep", "quality"])
ret["user_id"] = df["user_id"].unique()[0]
return ret5.7 有记录天数大于50天的那些user_id,每window_size周的时间跟踪质量
filter_after_day = sliding_quality.loc[sliding_quality["user_id"].isin(user_filter_day)]
filter_after_day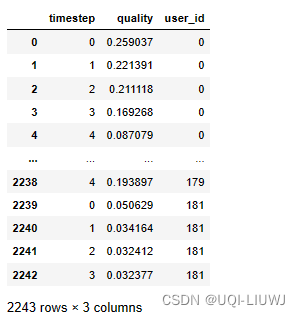
5.8 每个筛选后的user_id的平均滑动时间跟踪质量
filter_after_user_quality = filter_after_day.groupby("user_id", as_index=False)["quality"].mean()
5.9 函数结束
filter_after_user_quality.to_csv(file_path, index=False)
#平均滑动时间跟踪质量保存至本地
return filter_after_user_quality["user_id"].values
#返回持续时间大于50天的数据6 筛选staypoint
6.1 筛选在valid_user里面的
sp = sp.loc[sp["user_id"].isin(valid_user)]6.2 筛选活跃的
sp = sp.loc[sp["is_activity"] == True]
sp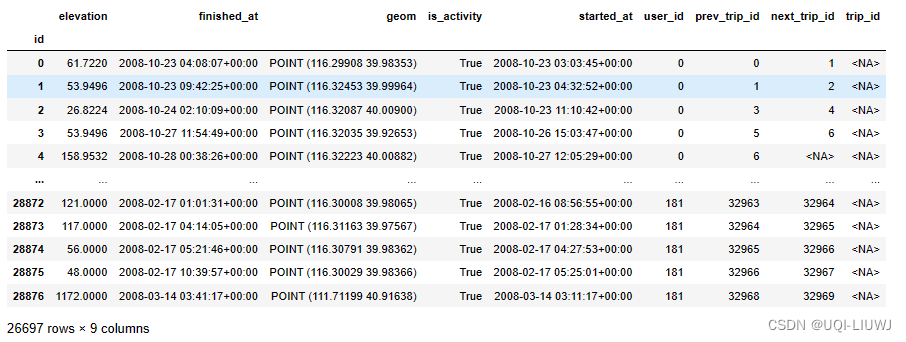
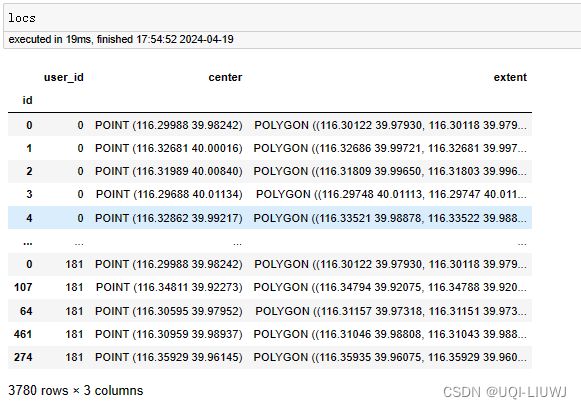
7 聚合staypoint(成为station)
sp, locs = sp.as_staypoints.generate_locations(
epsilon=50,
num_samples=2,
distance_metric="haversine",
agg_level="dataset",
n_jobs=-1
)

7.1 去除不在station里面的staypoint(因为这个任务是next station prediction)
sp = sp.loc[~sp["location_id"].isna()].copy()
7.2 station去重
不同user 可能共享一个location,相同位置的location只保留一个
locs = locs[~locs.index.duplicated(keep="first")]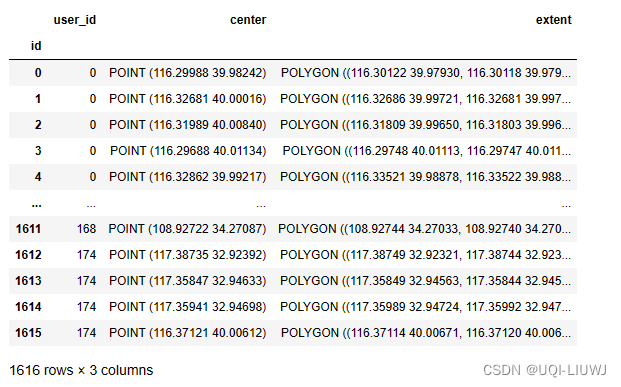

7.2 将station信息保存至locations_geolife.csv
8 合并时间阈值内的staypoint
sp_merged = sp.as_staypoints.merge_staypoints(
triplegs=pd.DataFrame([]),
max_time_gap="1min",
agg={"location_id": "first"}
)如果两个停留点之间的最大持续时间小于1分钟,则进行合并

9 每个staypoint的持续时间
sp_merged["duration"] = (sp_merged["finished_at"] - sp_merged["started_at"]).dt.total_seconds() // 60
10 添加和计算新的时间相关字段
sp_time = enrich_time_info(sp_merged)
sp_time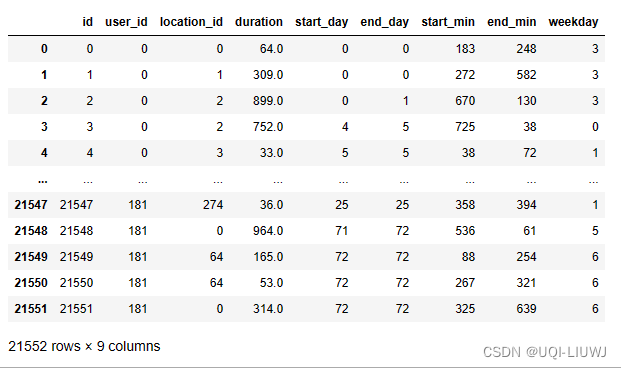
10.1 enrich_time_info(sp)
def enrich_time_info(sp):
sp = sp.groupby("user_id", group_keys=False).apply(_get_time)
#使用 groupby 根据 user_id 对数据进行分组,并应用辅助函数 _get_time 处理每个组的数据。
sp.drop(columns={"finished_at", "started_at"}, inplace=True)
#删除 finished_at 和 started_at 列
sp.sort_values(by=["user_id", "start_day", "start_min"], inplace=True)
#对数据进行排序
sp = sp.reset_index(drop=True)
#
sp["location_id"] = sp["location_id"].astype(int)
sp["user_id"] = sp["user_id"].astype(int)
# final cleaning, reassign ids
sp.index.name = "id"
sp.reset_index(inplace=True)
return sp10.2 _get_time(df)
def _get_time(df):
min_day = pd.to_datetime(df["started_at"].min().date())
#将 started_at 的最小日期(min_day)作为基准点,用于计算其他时间点相对于此日期的差异
df["started_at"] = df["started_at"].dt.tz_localize(tz=None)
df["finished_at"] = df["finished_at"].dt.tz_localize(tz=None)
df["start_day"] = (df["started_at"] - min_day).dt.days
df["end_day"] = (df["finished_at"] - min_day).dt.days
#计算 start_day 和 end_day 字段,这两个字段表示相对于 min_day 的天数差异。
df["start_min"] = df["started_at"].dt.hour * 60 + df["started_at"].dt.minute
df["end_min"] = df["finished_at"].dt.hour * 60 + df["finished_at"].dt.minute
#计算 start_min 和 end_min 字段,这些字段表示一天中的分钟数,用于精确到分钟的时间差异计算
df.loc[df["end_min"] == 0, "end_min"] = 24 * 60
#如果 end_min 等于 0,表示结束时间为午夜,为了避免计算错误,手动将其设置为 1440(即24小时*60分钟)
df["weekday"] = df["started_at"].dt.weekday
#计算 weekday 字段,表示 started_at 所在的星期几(0代表星期一,6代表星期日)
return df11 sp_time 存入sp_time_temp_geolife.csv
12 _filter_sp_history(sp_time)
这一部分写的有点繁琐,有一些语句都是没有必要的,我精简一下
12.0 辅助函数
12.0.1 split_dataset
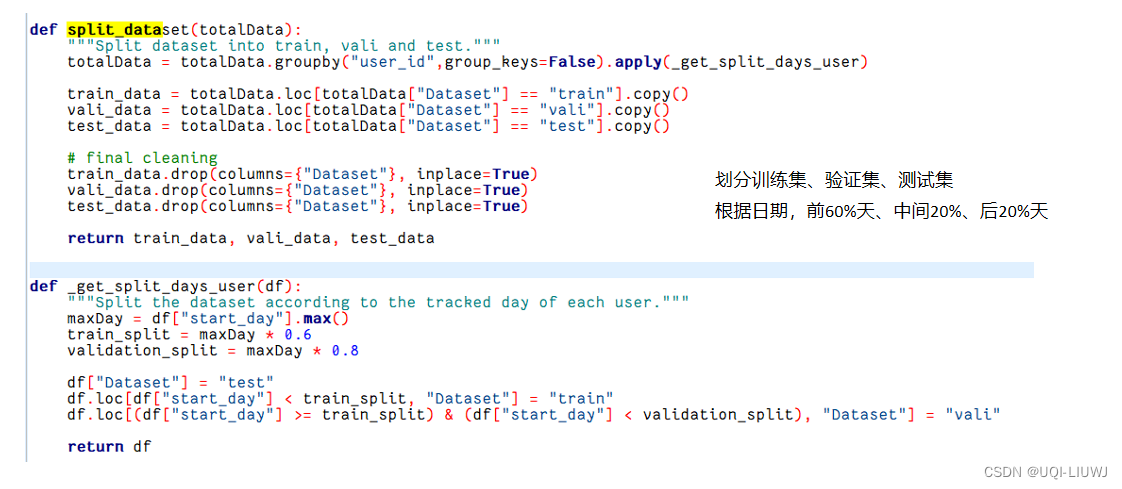
12.0.2 get_valid_sequence
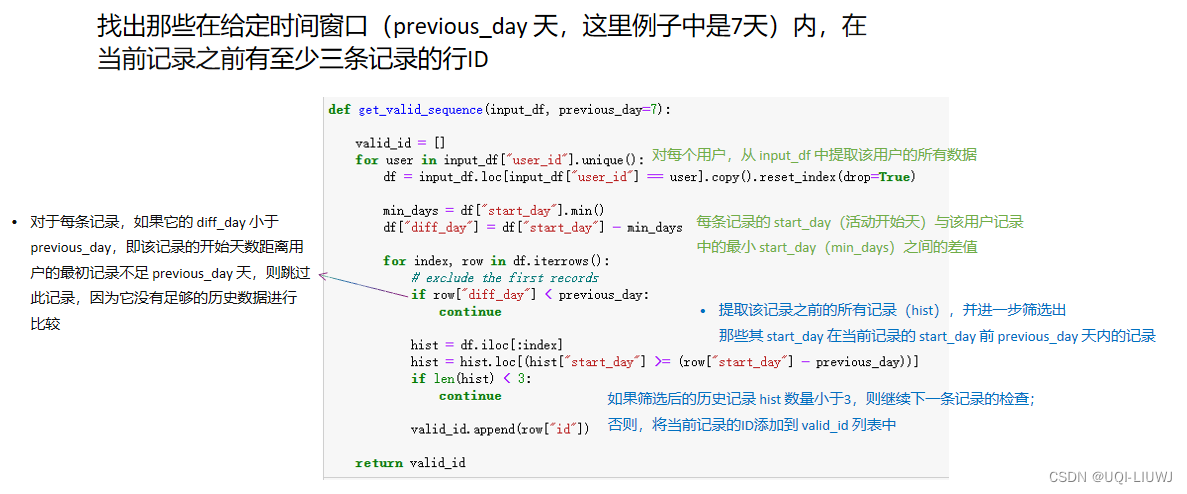
12.1 划分训练、验证、测试集
train_data, vali_data, test_data = split_dataset(sp_time)每一个user 前60%天 训练,中间20%天验证,后20%天测试



12.2 获取所有“valid”的行id
所谓valid,指的是那些在给定时间窗口(previous_day 天,这里例子中是7天)内,在当前记录之前有至少三条记录的行ID
previous_day_ls = [7]
all_ids = sp[["id"]].copy()
for previous_day in previous_day_ls:
valid_ids = get_valid_sequence(train_data, previous_day=previous_day)
valid_ids.extend(get_valid_sequence(vali_data, previous_day=previous_day))
valid_ids.extend(get_valid_sequence(test_data, previous_day=previous_day))
all_ids[f"{previous_day}"] = 0
all_ids.loc[all_ids["id"].isin(valid_ids), f"{previous_day}"] = 1all_ids.set_index("id", inplace=True)
final_valid_id = all_ids.loc[all_ids.sum(axis=1) == all_ids.shape[1]].reset_index()["id"].values
#这一行写的很复杂,其实就是
'''
all_ids[all_ids['7']==1].index.values
'''筛选所有valid的行id
12.3 筛选train、valid、test中valid的行对应的user_id
valid_users_train = train_data.loc[train_data["id"].isin(final_valid_id), "user_id"].unique()
valid_users_vali = vali_data.loc[vali_data["id"].isin(final_valid_id), "user_id"].unique()
valid_users_test = test_data.loc[test_data["id"].isin(final_valid_id), "user_id"].unique()
valid_users_train12.4 在train、test、valid上都有的user
valid_users = set.intersection(set(valid_users_train), set(valid_users_vali), set(valid_users_test))
len(valid_users)
#4712.5 筛选对应的staypoint
filtered_sp = sp_time.loc[sp_time["user_id"].isin(valid_users)].copy()12.5 valid_user_id和staypoint 分别保存
data_path = f"./data/valid_ids_geolife.pk"
with open(data_path, "wb") as handle:
pickle.dump(final_valid_id, handle, protocol=pickle.HIGHEST_PROTOCOL)
filtered_sp.to_csv(f"./data/dataset_geolife.csv", index=False)