非关系型数据库简述
关系型数据库(SQL):Mysql,oracle
特点:数据和数据之间、表和字段之间,表和表之间是存在关系的。
优点:数据之间有关系、进行数据的增删改查时非常方便、关系型数据库有事务操作,保证数据的完整性。
缺点:因为数据和数据之间是有关系的,关系是由底层大量算法保证,会拉低系统运行速度,消耗系统资源;海量数据时增删改查很可能宕机,维护/扩展也会不好。
适合处理一般量级数据,安全。
非关系型数据库(NOSQL):Redis
非关系数据库设计之初是为了替代关系型数据库的。
优点:海量数据的增删改查和维护非常轻松。
缺点:数据和数据之间没有关系,不能一目了然;没有事务保证数据的完整和安全。
适合处理海量数据,效率。不一定安全。
主流NOSQL数据库

NoSQL数据库的四大分类如下:
1键值(Key-Value)存储数据库
相关产品:Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB
典型应用:内容缓存,主要用于处理大量数据的高访问负载。
数据模型:一系列键值对
优势:优秀的快速查询,稳定性强。
劣势:存储的数据缺少结构化
2列存储数据库
相关产品:Cassandra、HBase,Riak
典型应用:分布式的文件系统
数据模型:以列簇式存储,将同一列数据存在一起
优势:查找速度快,可扩展性强,更容易进行分布式扩展
劣势:功能相对局限,使用极大的内存才可调配,且系统处理算法时将有数秒甚至更长时间的不可用,导致大量处理超时
3文档型数据库(淘汰)
相关产品:CouchDB、MongoDb
典型应用:Web应用(与Key-Value类似,Value是结构化的)
数据模型:一系列键值对
优势:数据结构要求不严格
劣势:查询性能不高,而且缺乏统一的查询语法
4图形(Graph)数据库
相关数据库:Neo4J、infoGrid、infinite、Graph
典型应用:社交网络【关系网】
数据模型:图结构
优势:利用图结构相关算法
劣势:需要对整个图做计算才能得出结果,不容易做分布式的集群方案。局限性过强
Redis概述
Redis由来
2008年,意大利的一家创业公司Merzia推出了一款基于MySQL的网站实时统计系统 LLOOGG,然而没过多久该公司的创始人 Salvatore Sanfilippo 便对MySQL 的性能感到失望,于是他决定亲自为 LLOOGG 量身定做一个 数据库,并并于 2009 年开发完成,这个数据库就是Redis。不过Salvatore Sanfilippo并不满足只将 Redis 用于LLOOGG这一款产品,而是希望更多的人使用它,于是在同一年 Salvatore Sanfilippo 将 Redis 开源发布,并开始和 Redis 的另一名主要的代码贡献者 Pieter Noordhuis 一起继续着 Redis 的开发,直到今天。
Salvatore Sanfilippo 自己也没有想到,短短的几年时间,Redis就拥有了庞大的用户群体。Hacker News 在 2012 年发布了一份数据库的使用情况调查,结果显示有近 12% 的公司在使用 Redis。国内如 新浪微博、街旁网、知乎网,国外如GitHub、Stack Overflow、Flickr等都是Redis的用户。
VMware 公司从2010年开始赞助 Redis 的开发,Salvatore Sanfilippo和 Pieter Noordhuis 也分别在3月和5月加入VMware,全职开发Redis。
什么是 Redis
Redis 是用 C 语言开发的一个开源的高性能键值对(key-value)数据库。它通过提供多种键值数据类型来适应不同场景下的存储需求,目前为止 Redis 支持的键值数据类型如下:
1. 字符串类型
2. 散列类型
3. 列表类型
4. 集合类型
5. 有序集合类型。
官方提供测试数据:50 个并发执行 100000 个请求,读的速度是 110000 次/s,写的速度是 81000 次/s。数据仅供参考,根据服务器配置会有不同结果。
Redis 的应用场景
缓存(数据查询、短连接、新闻内容、商品内容等等)。(最多使用)
聊天室的在线好友列表。
任务队列。(秒杀、抢购、12306等等)
应用排行榜。
网站访问统计。
数据过期处理(可以精确到毫秒)
分布式集群架构中的session分离。
Redis安装和启动
参考博客:http://localhost:8080/zjblog/toDetail?articleId=1903011210191700007
redis数据类型
redis使用的是键值对 保存数据(map)
key:全部都是字符串
value:有五种类型
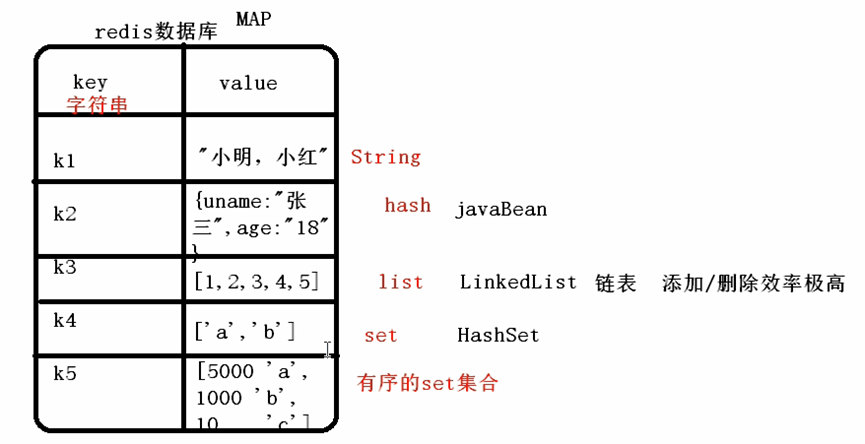
Key名称:自定义,理论上不要过长否则影响使用效率(长度从小到大查询)。也不要太短,要有意义的。
Redis命令-String命令
概述:字符串类型是Redis中最为基础的数据存储类型,它在Redis中是二进制安全的,这便意味着该类型存入和获取的数据将相同。在Redis中字符串类型的Value最多可以容纳的数据长度是512M。
二进制安全和数据安全是没有关系的。
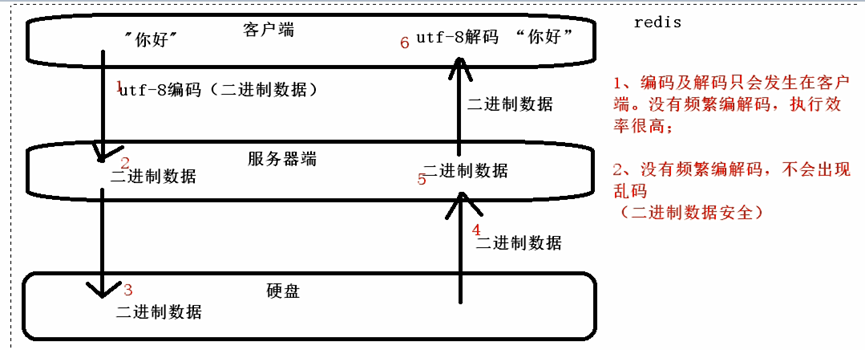
MySQL-关系型数据库,二进制不安全。【乱码、丢失数据】
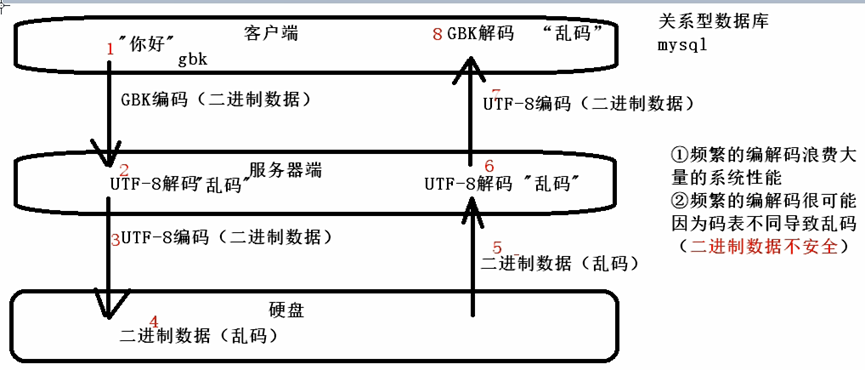
赋值(相当于map.put)
set key value:设定key持有指定的字符串value,如果该key存在则进行覆盖操作,总是返回“OK”。

取值(相当于map.get)
get key:获取key的value。如果与该key关联的value是不string类型的,Redis将返回错误信息,因为get命令只能用于获取String value;如果该key不存在,返回(nil)。
![]()

get key value:先获取该key的值,然后在设置该key的值,新的value会覆盖老的value。
删除(相当于map.remove)
del key:删除指定key,返回受影响行数。
其他:
获取并修改值
getset key value:先获取该key的值,然后在设置该key的值。
递增
incr key:将指定的key的value原子性的递增1,如果该key不存在,其初始值为0,在incr之后其值为1.如果value的值不能转成整形,如hello,该操作将执行失败并返回相应的错误信息。相当于i++
递减
decr key:将指定的key的value原子性的递减1,如果该key不存在,其初始值为0,在decr之后其值为-1,如果value的值不能转成整形,如hello,该操作失败并返回相应错误。相当于i—
拼接字符串
append key value:拼接字符串。如果该key存在,则在原有的value后追加该值,如果不存在,则重新创建一个key/value
将数值自增任意值
incrby key increment:将指定的key的value原子性增加increment,如果该key不存在,其初始值为0,在incrby后,该值为increment。如果该值不能转成整形,则失败并报错。
将数值递减任意值
decrby key decrement:将指定的key的value原子性增加decrement,如果该key不存在,其初始值为0,在incrby后,该值为-decrement。如果该值不能转成整形,则失败并报错。
String使用环境:主要用于保存json格式的字符串
Redis命令-hash命令
概述:Redis中的Hash类型可以看成具有String Key和String Value的map容器。所以该类型非常适合用于存储值对象的信息。如Username、Password等。如果Hash中包含很少的字段,那么该类型的数据也将仅占用很少的磁盘空间。每一个Hash可以存储4294967295个键值对。
赋值
hset key field value:为指定的key设定field/value对(键值对)。
hmset key field value field2 value2 …:设置key中的多个filed/value
取值
hget key field:返回指定的key中的field的值。
hmget key filed1 filed2 …:获取key中的多个filed的值
hgetall key:获取key中的所有filed-value
删除
hdel key field field..:可删除一个或者多个字段,返回值是被删除的字段个数。
del key:删除整个
增加数字
hincrby key field increment:设置key中filed的值增加increment
其他命令
hexists key field:判断指定的key中的filed是否存在
hlen key:获取key所包含的filed的数量
hkeys kye:获取所有的字段
hvals key:获取所有的value
keys * 查询所有的key
Redis命令-list命令
概述:dis中,List类型是按照插入顺序排序的字符串链表。和数据结构中的普通链表一样,我们可以在其头部(left)和尾部(right)添加新的元素。在插入时,如果该键并不存在,Redis将为该键创建一个新的链表。与此相反,如果链表中所有的元素均被移除,那么该键也将会被从数据库中删除。List中可以包含的最大元素数量是4294967295。
从元素插入和删除的效率视角来看,如果我们是在链表的两头插入或删除元素,这将会是非常高效的操作,即使链表中已经存储了百万条记录,该操作也可以在常量时间内完成。然而需要说明的是,如果元素插入或删除操作是作用于链表中间,那将会是非常低效的。相信对于有良好数据结构基础的开发者而言,这一点并不难理解。
赋值(两端添加)
lpush key values1 values2 …:在指定的key所关联的list头部插入所有的values。如果该key不存在,该命令在插入的之前创建一个与该key关联的空链表,之后再向该链表的头部插入数据。插入成功,返回元素的个数。
rpush key values1 values2…:在该list的尾部添加元素。
取值(查看列表)
lrange key start end:获取链表中从start到end的元素的值,start、end从0开始计数,也可以为负数,若为-1则标识链表尾部的元素。-2则表示倒数第二个,以此类推..
删除(两端弹出)
lpop key:返回并弹出指定的key关联的链表中的第一个元素,即头部元素。如果该key不存在,返回nil;若存在则返回链表中的头部元素
rpop key:从尾部单出元素。
获取列表中的元素个数
llen key:返回指定的key关联的链表中的元素的数量。
删除某种元素(效率低)
lrem key count value:删除count个值为value的元素,如果count大于0,从头向尾遍历并删除count个值为value的元素,如果count小于0,则从尾向头遍历并删除。如果count等于0,则删除链表中所有等于value的元素。
通过索引替换元素(效率低)
lset key index value:设置链表中的index的脚标的元素值,0代表链表的头元素,-1代表链表的尾元素。操作链表的脚标不存在则抛异常。
在索引前/后插入元素(效率低)
linsert key before|after pivot value:在pivot元素前后插入value这个元素。
扩展命令
rpoplpush resource destination:将resource链表中的尾部元素弹出并添加到destination头部。
rpoplpush resource resource:将resource链表中的尾部元素弹出并添加到resource头部。(循环操作)
Redis命令-set命令
概述:Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。集合中最大的成员数为232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
添加/删除元素
sadd key value value1…:向set中添加数据,如果该key的值已有则不会重复添加。
srem key members members1..:删除set中指定的成员。
取值
smembers key:获取set中所有元素
sismember key member:判断参数中指定的元素是否存在,1表示存在,0表示不存在或者该key本身就不存在。(无论集合中有多少元素都可以极速的返回结果).
集合运算
sdiff key1 key2 …:差集运算,返回kye1与key2中相差的成员,而且与key的顺序有关。即返回差集。

sinter key1 key2 …:返回交集
sunion key1 key2 ..:返回并集。

扩展命令
scard key:获取set中元素数量
srandmember key:随机返回一个元素
sdiffstore destination key1 key2..:将key1、key2相差的成员存储在destination上
sinterstore destination key1 key2..:将返回的交际存储在destination上
sunionstore destination key1 key2..:将返回的并集存储在destination上
Redis命令-有序set命令(zset)
概述:Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
有序set集合: 有序,不重复。专门用来做排行榜
添加元素
zadd key score member score2 member2 …:将所有成员以及该成员的分数放到sorted-set中。如果该元素已经存在则会用新的分数替换原有的分数。返回值是新加入到集合中的元素个数,不包含之前已经存在的元素。
获取元素
zscore key member:返回指定成员的分数。
删除元素
zrem key member member…:移除集合中指定成员,可以指定多个。
范围查询(顺序查看)
zrange key start end [withscores] : 获取集合中脚标为start-end的成员,withscores参数表明返回的成员包含其分数。(分数有小到大排列)
zrevrange key start end [withscores] : 获取集合中脚标为start-end的成员,withscores参数表明返回的成员包含其分数。(分数大到小排列)
zremrangebyrank key start stop:按照排名范围删除元素
zremrangebyscore key min max : 按照分数范围删除元素
扩展命令
zrangebyscore key min max [withscores] [limit offset count]: 返回分数在[min,max]的成员并按照分数从低到高排序。[withscores]:显示分数;[limit offset count]:offset,表明脚标为offset的元素开始并返回count个成员。
zincrby key increment member:设置指定成员的增加的分数。返回值时更改后的分数。
zcount key min max:获取分数在[min,max]之间的成员。
zrank key member:返回成员在集合中的排名。索引(从小到大)。
zrevrank key member:返回成员在集合中的排名。索引(从大到小)。
Redis命令-通用命令
keys pattern:获取所有与pattern匹配的key,返回所有与该key匹配的keys。*表示任意一个或多个字符,?表示任意一个字符。
del key1 key2 ..:删除指定的key。
exists key:判断该key是否存在,1代表存在,0代表不存在。
rename key newkey:为当前的key重命名
expire key time:设置过期时间,单位:秒。过期即删除。
ttl key:获取该key所剩的超时时间,如果没有设置超时,返回-1.如果返回-2表示超时不存在。
type key:获取指定key的类型。该命令将以字符串的格式返回。返回的字符串为string、list、set、Hash、zset。如果key不存在返回none。
redis服务器命令
ping:测试连接是否存活。ping成功返回PONG;
echo:在命令行打印一些东西。echo “HELLO WORLD!”;
select:选择数据库。redis数据库编号【0-15】,选择16是报错;
quit:退出连接;
dbsize:返回当前数据库中key的数目;
info:获取服务器的信息和统计;
消息订阅与发布
subscriber channel:订阅频道,例:subscribe mychat,订阅mychat这个频道
psubscribe channel*:批量订阅频道,例:psubscribe s*,订阅“s”开头的频道
publish channel content:在指定的频道中发布消息,如publish mychat ‘today is a newday’
多数据库
一个Redis实例可以包括多个数据库,客户端可以指定连接某个redis实例的哪个数据库,就好比一个mysql中创建多个数据库,客户端连接时指定连接哪个数据库。
一个redis实例最多可提供16个数据库,下标从0到15,客户端默认连接第0号数据库,也可以通过select选择连接哪个数据库,select 1 切换到1数据库。
move newkey 1:将当前库的key移植到1号库中。
清空当前数据库:flushdb
清空redis服务器数据:flushall (所有数据库数据清空)
注意问题:在0号数据库存储数据,在1号数据库执行清空数据命令却把0号数据库的数据给清空的。
redis批量操作-事务
Redis-事务:目的为了进行redis语句的批量化执行
MULTI、EXEC、DISCARD和WATCH命令是Redis事务功能的基础。Redis事务允许在一次单独的步骤中执行一组命令,并且可以保证如下两个重要事项:
>Redis会将一个事务中的所有命令序列化,然后按顺序执行。Redis不可能在一个Redis事务的执行过程中插入执行另一个客户端发出的请求。这样便能保证Redis将这些命令作为一个单独的隔离操作执行。
> 在一个Redis事务中,Redis要么执行其中的所有命令,要么什么都不执行。因此,Redis事务能够保证原子性。EXEC命令会触发执行事务中的所有命令。因此,当某个客户端正在执行一次事务时,如果它在调用MULTI命令之前就从Redis服务端断开连接,那么就不会执行事务中的任何操作;相反,如果它在调用EXEC命令之后才从Redis服务端断开连接,那么就会执行事务中的所有操作。当Redis使用只增文件(AOF:Append-only File)时,Redis能够确保使用一个单独的write(2)系统调用,这样便能将事务写入磁盘。然而,如果Redis服务器宕机,或者系统管理员以某种方式停止Redis服务进程的运行,那么Redis很有可能只执行了事务中的一部分操作。Redis将会在重新启动时检查上述状态,然后退出运行,并且输出报错信息。使用redis-check-aof工具可以修复上述的只增文件,这个工具将会从上述文件中删除执行不完全的事务,这样Redis服务器才能再次启动。
从2.2版本开始,除了上述两项保证之外,Redis还能够以乐观锁的形式提供更多的保证,这种形式非常类似于“检查再设置”(CAS:Check And Set)操作。本文稍后会对Redis的乐观锁进行描述。
命令解释
multi:开启事务用于标记事务的开始,其后执行的命令都将被存入命令队列,知道执行EXEC时,这些命令才会被原子的执行,类似与关系型数据库中的:begin transaction
exec:提交事务,类似与关系型数据库中的:commit
discard:事务回滚,类似与关系型数据库中的:rollback
redis持久化
内存:高效、断电后数据就会消失。
硬盘:读写速度慢与内存,断电数据还在。
关系型数据库MySQL持久化 :任何增删改,都是在硬盘上操作的,断电后,硬盘上的数据还在。
非关系型数据库redis:默认情况下,所有的增删改,数据都是在内存中进行操作。断电后,内存中数据不存在。
断电后,redis的部分数据会丢失,丢失的数据是保存在内存中的数据。
Redis存在持久化操作。
RDB持久化机制优点
- 一旦采用该方式,那么你的整个Redis数据库将只包含一个文件,这对于文件备份而言是非常完美的。比如,你可能打算每个小时归档一次最近24小时的数据,同时还要每天归档一次最近30天的数据。通过这样的备份策略,一旦系统出现灾难性故障,我们可以非常容易的进行恢复。
- 对于灾难恢复而言,RDB是非常不错的选择。因为我们可以非常轻松的将一个单独的文件压缩后再转移到其它存储介质上
- 性能最大化。对于Redis的服务进程而言,在开始持久化时,它唯一需要做的只是fork(分叉)出子进程,之后再由子进程完成这些持久化的工作,这样就可以极大的避免服务进程执行IO操作了。
相比于AOF机制,如果数据集很大,RDB的启动效率会更高
特点:只会将最终的数据持久化到本地。
RDB持久化机制缺点
- 如果你想保证数据的高可用性,即最大限度的避免数据丢失,那么RDB将不是一个很好的选择。因为系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。
- 由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟
RDB持久化机制的配置
在redis.windows.conf配置文件中有如下配置:
```confSNAPSHOTTING
Save the DB on disk:
save
Will save the DB if both the given number of seconds and the given
number of write operations against the DB occurred.
In the example below the behaviour will be to save:
after 900 sec (15 min) if at least 1 key changed
after 300 sec (5 min) if at least 10 keys changed
after 60 sec if at least 10000 keys changed
Note: you can disable saving at all commenting all the "save" lines.
It is also possible to remove all the previously configured save
points by adding a save directive with a single empty string argument
like in the following example:
save ""save 900 1 save 300 10 save 60 10000 ```
其中,上面配置的是RDB方式数据持久化时机:
| 关键字 | 时间(秒) | key修改数量 | 解释 | | ------ | -------- | ----------- | ----------------------------------------------------- | | save | 900 | 1 | 每900秒(15分钟)至少有1个key发生变化,则dump内存快照 | | save | 300 | 10 | 每300秒(5分钟)至少有10个key发生变化,则dump内存快照 | | save | 60 | 10000 | 每60秒(1分钟)至少有10000个key发生变化,则dump内存快照 |
AOF持久化机制
AOF持久化机制优点
- 该机制可以带来更高的数据安全性,即数据持久性。Redis中提供了3中同步策略,即每秒同步、每修改同步和不同步。事实上,每秒同步也是异步完成的,其效率也是非常高的,所差的是一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢失。而每修改同步,我们可以将其视为同步持久化,即每次发生的数据变化都会被立即记录到磁盘中。可以预见,这种方式在效率上是最低的。至于无同步,无需多言,我想大家都能正确的理解它。
- 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。
- 如果日志过大,Redis可以自动启用rewrite机制。即Redis以append模式不断的将修改数据写入到老的磁盘文件中,同时Redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行rewrite切换时可以更好的保证数据安全性。
- AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建
持久化机制缺点
- 对于相同数量的数据集而言,AOF文件通常要大于RDB文件
- 根据同步策略的不同,AOF在运行效率上往往会慢于RDB。总之,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效。
6 AOF持久化机制配置
开启AOF持久化
```conf
APPEND ONLY MODE
By default Redis asynchronously dumps the dataset on disk. This mode is
good enough in many applications, but an issue with the Redis process or
a power outage may result into a few minutes of writes lost (depending on
the configured save points).
The Append Only File is an alternative persistence mode that provides
much better durability. For instance using the default data fsync policy
(see later in the config file) Redis can lose just one second of writes in a
dramatic event like a server power outage, or a single write if something
wrong with the Redis process itself happens, but the operating system is
still running correctly.
AOF and RDB persistence can be enabled at the same time without problems.
If the AOF is enabled on startup Redis will load the AOF, that is the file
with the better durability guarantees.
Please check http://redis.io/topics/persistence for more information.appendonly no ```
将appendonly修改为yes,开启aof持久化机制,默认会在目录下产生一个appendonly.aof文件
AOF持久化时机
```
appendfsync always
appendfsync everysec
appendfsync no
```
上述配置为aof持久化的时机,解释如下:
| 关键字 | 持久化时机 | 解释 | | ----------- | ---------- | ------------------------------ | | appendfsync | always | 每执行一次更新命令,持久化一次 | | appendfsync | everysec | 每秒钟持久化一次 | | appendfsync | no | 不持久化 |
Jedis
概述
Redis不仅是使用命令来操作,现在基本上主流的语言都有客户端支持。在官方网站里列一些java的客服端,有Jedis、Redisson、Jredis、JDBC-Redis等。其中官方推荐使用Jedis和Redisso。在企业中用的最多的就是Jedis。
Jedis托管在GitHub上,地址:GitHub - redis/jedis: Redis Java client designed for performance and ease of use.
Redis有什么命令,Jedis就有什么方法。
Java连接Redis
导入jar包
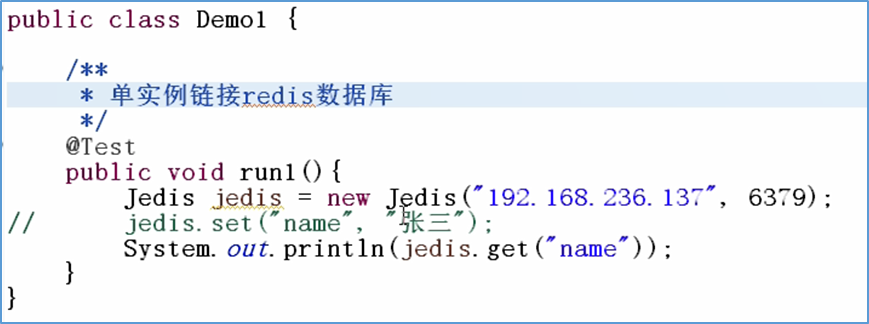
注意这里连接不上可能是防火墙拦截了端口号,可以上Linux设置允许访问端口或直接关闭防火墙。
关闭了防火墙还没用。打开redis.conf配置文件
把bind 的配置项注释
# IF YOU ARE SURE YOU WANT YOUR INSTANCE TO LISTEN TO ALL THE INTERFACES
# JUST COMMENT THE FOLLOWING LINE.
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#bind 127.0.0.1
问题得到解决
注意:当前我的redis服务端设置的密码访问
如果没设置密码的话,通过以上处理,还是连接不上,可尝试一下操作
# By default protected mode is enabled. You should disable it only if
# you are sure you want clients from other hosts to connect to Redis
# even if no authentication is configured, nor a specific set of interfaces
# are explicitly listed using the "bind" directive.
#protected-mode yes
注释 保护模式,之后重启
、若还是不行、可注释一下配置
# By default Redis does not run as a daemon. Use 'yes' if you need it.
# Note that Redis will write a pid file in /var/run/redis.pid when daemonized.
#daemonize yes
该项配置 Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程,设置为no
最后重启redis-server
src/redis-server redis.conf
这样还是不行,设置密码登录就OK了。
设置密码的流程如下:
vim /etc/redis.conf
#requirepass foobared去掉注释,foobared改为自己的密码,我在这里改为
requirepass 123456
然后保存,重启服务
cd /usr/local/bin
./redis-server /etc/redis.conf
测试连接:./redis-cli
输入命令 会提示(error) NOAUTH Authentication required. 这是属于正常现象。
我们输入 auth 123456#你刚才设置的密码
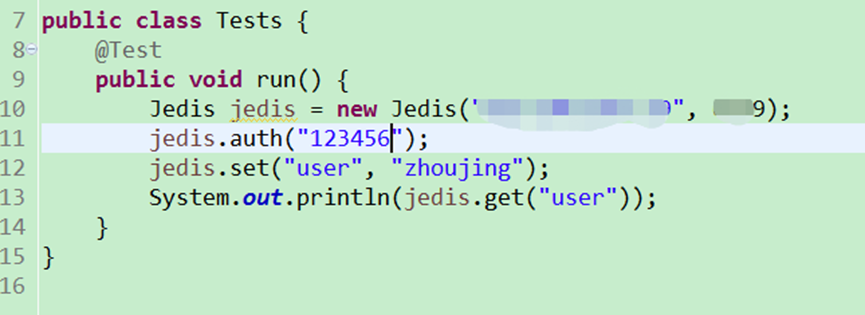
这样就可以访问了
Jedis连接池

Jedis连接池工具类
public class JedisUtils {
// 定义一个连接池对象
private final static JedisPool POOL;
static {
// 初始化操作
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(50);
poolConfig.setMaxIdle(10);
POOL = new JedisPool(poolConfig, "123.000.00.0", 6009);
}
/**
* 从池中获取连接
*/
public static Jedis getJedis() {
return POOL.getResource();
}
}