ReduceTask 是 Hadoop 中的一个重要组件,负责对 MapTask 的输出进行合并、排序和归并,最终生成最终的输出结果。
ReduceTask 的工作机制
1. 分组(Shuffle)阶段:
- 在分组阶段,ReduceTask 会从多个 Mapper 的输出中获取数据,并根据它们的键进行分组。具体步骤如下:
- 每个 Mapper 将输出数据分割成多个分区(partition),每个分区对应一个 Reducer。
- 每个分区内的数据按照键进行排序。
- ReduceTask 根据键的哈希值确定每条记录属于哪个分区,并将数据发送给相应的 Reducer。
- 数据在传输过程中,可能会经过 combiner 阶段,用于在 Mapper 和 Reducer 之间进行本地合并。
2. 排序(Sort)阶段:
- 在排序阶段,ReduceTask 将收到的数据进行排序,以便后续的归并操作。排序通常是在内存中进行的,但如果内存不足以容纳所有数据,则会使用磁盘进行排序。
- 排序的目标是确保相同键的记录相邻,并按照键的自然顺序进行排序(或者根据用户指定的排序逻辑进行排序)。
3. 归并(Merge)阶段:
- 在归并阶段,ReduceTask 将排序后的数据进行归并,合并相同键的记录,并调用用户定义的 Reduce 函数进行处理。具体步骤如下:
- 将排序后的数据按照键进行分组。
- 对每个键的记录调用用户定义的 Reduce 函数进行处理,生成最终的输出。
4. 输出(Output)阶段:
- 在输出阶段,ReduceTask 将 Reduce 函数的输出写入到指定的输出目标中,通常是分布式文件系统(如 HDFS)的文件中。
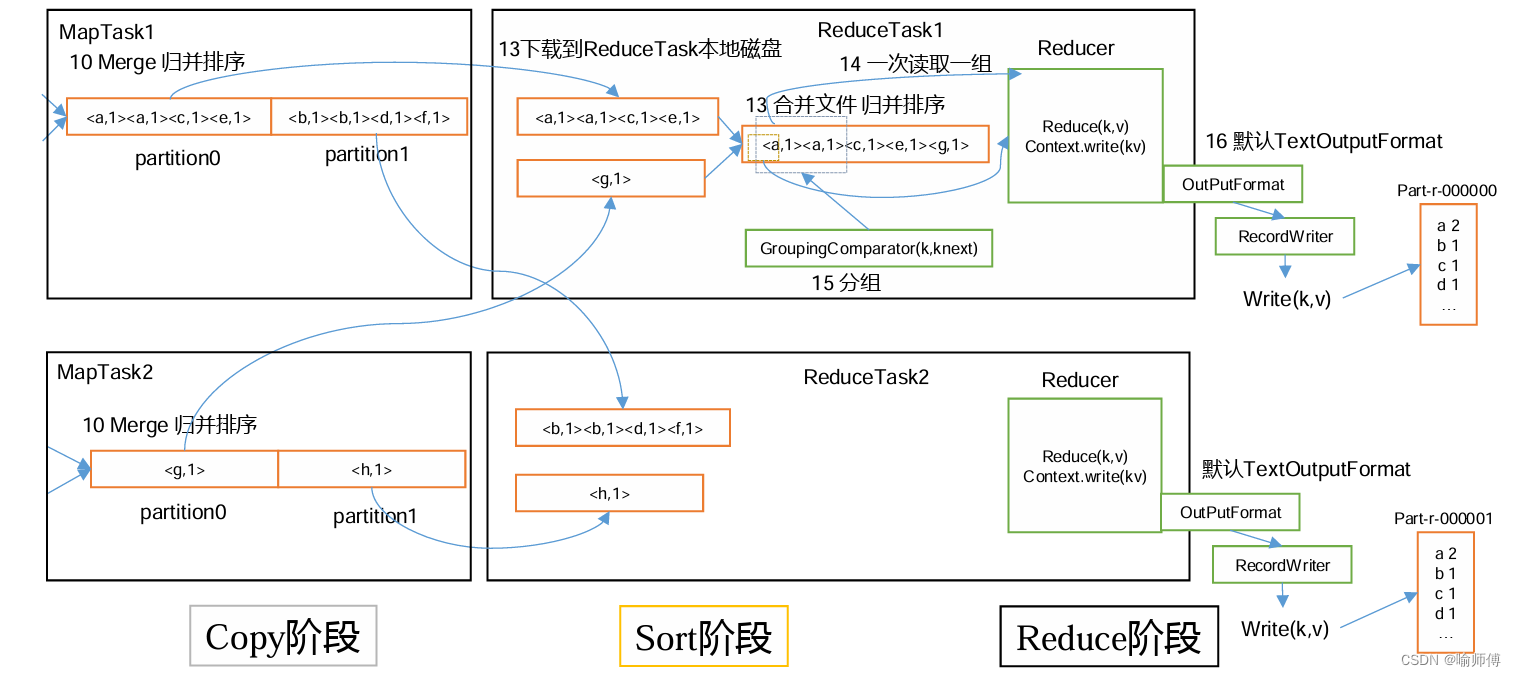
ReduceTask 的工作机制可以总结为分组、排序、归并和输出这四个阶段。在每个阶段中,ReduceTask 都会对输入数据进行不同的处理,最终生成最终的输出结果。


![new[]与delete[]](https://img-blog.csdnimg.cn/direct/538e525a35a44247871b720b4983e301.png)