一、本文介绍
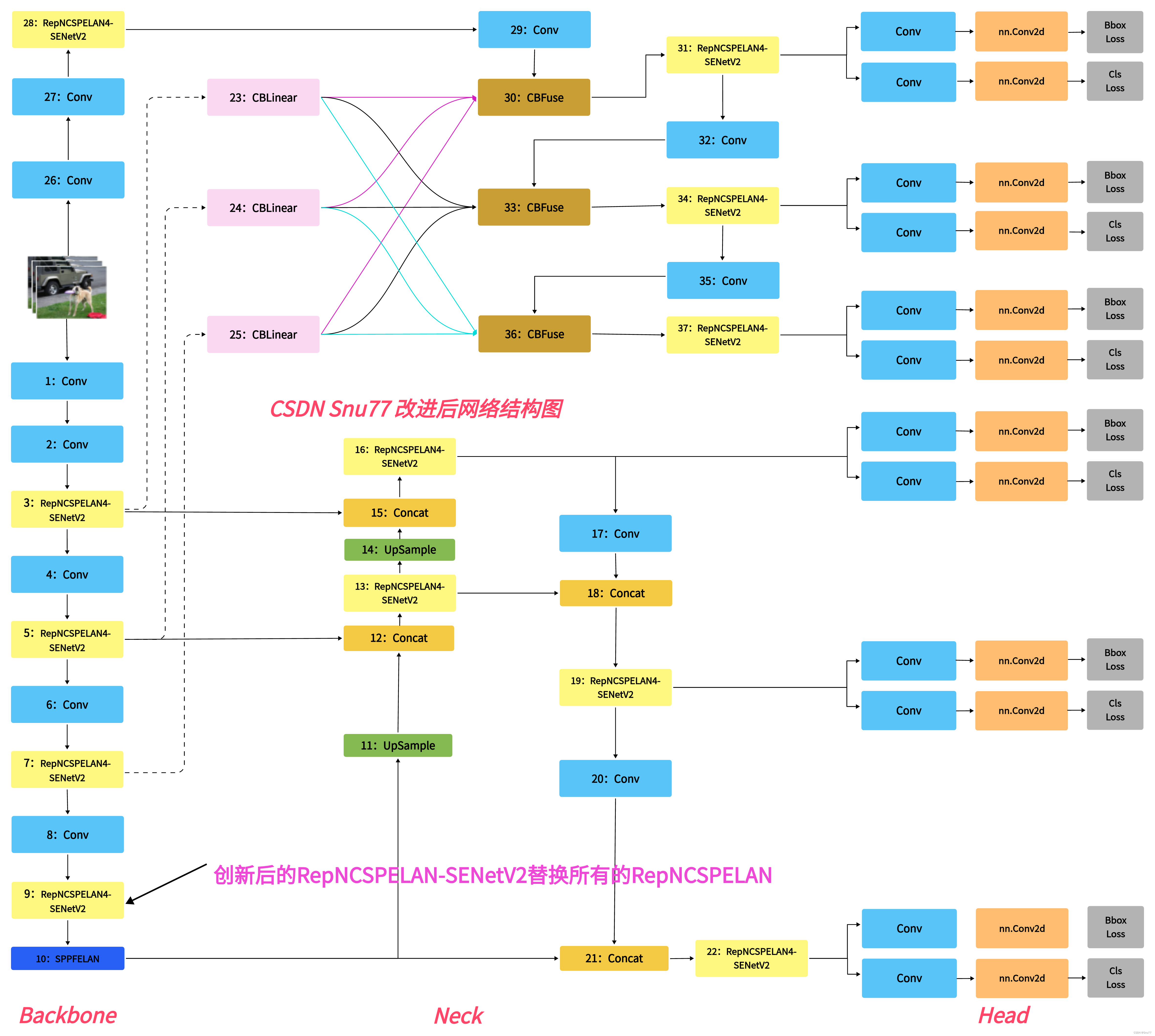
本文给大家带来的改进机制是SENetV2,其是一种通过调整卷积网络中的通道关系来提升性能的网络结构。SENet并不是一个独立的网络模型,而是一个可以和现有的任何一个模型相结合的模块(可以看作是一种通道型的注意力机制但是相对于SENetV1来说V2又在全局的角度进行了考虑)。在SENet中,所谓的挤压和激励(Squeeze-and-Excitation)操作是作为一个单元添加到传统的卷积网络结构中,亲测大中小三中目标检测上都有一定程度的涨点效果。同时欢迎大家订阅本专栏,本专栏每周更新3-5篇最新机制,更有包含我所有改进的文件和交流群提供给大家。同时本专栏目前改进基于yolov9.yaml文件,后期如果官方放出轻量化版本,专栏内所有改进也会同步更新,请大家放心,本文提供三种使用方式,下面图片为yaml1对应的结构图。

专栏地址:YOLOv9有效涨点专栏-持续复现各种顶会内容-有效涨点-全网改进最全的专栏
目录
一、本文介绍
二、SENetV2框架原理
三、SENetV2核心代码
四、手把手教你添加SENetV2网络结构
4.1 细节修改教程
4.1.1 修改一
4.1.2 修改二
4.1.3 修改三
4.1.4 修改四
4.2 SENetV2的yaml文件
4.2.1 SENetV2的yaml文件一
4.2.2 SENetV2的yaml文件二
4.2.3 SENetV2的yaml文件三
4.3 SENetV2运行成功截图
五、本文总结
二、SENetV2框架原理

论文地址:官方论文地址点击即可跳转
代码地址:官方代码地址点击即可跳转

SENetV2介绍了一种改进的SENet架构,该架构通过引入一种称为Squeeze aggregated excitation(SaE)的新模块来提升网络的表征能力。这个模块结合了挤压和激励(SENetV1)操作,通过多分支全连接层增强了网络的全局表示学习。在基准数据集上的实验结果证明了SENetV2模型相较于现有模型在分类精度上的显著提升。这一架构尤其强调在仅略微增加模型参数的情况下,如何有效地提高模型的性能。
挤压和激励模块大家可以看我发的SENetV1文章里面有介绍。

图中展示了三种不同的神经网络模块对比:
a) ResNeXt模块:采用多分支CNN结构,不同分支的特征图通过卷积操作处理后合并(concatenate),再进行额外的卷积操作。
b) SENet模块:标准卷积操作后,利用全局平均池化来挤压特征,然后通过两个尺寸为1x1的全连接层(FC)和Sigmoid激活函数来获取通道权重,最后对卷积特征进行缩放(Scale)。
c) SENetV2模块:结合了ResNeXt和SENet的特点,采用多分支全连接层(FC)来挤压和激励操作,最后进行特征缩放。
其中SENetV2的设计旨在通过多分支结构进一步提升特征表达的精细度和全局信息的整合能力。
前面我们提到了SaE,就是SENetV2相对于SENetV1的主要改进机制,下面的图片介绍了其内部工作原理。

SENet V2中所提出的SaE(Squeeze-and-Excitation)模块的内部工作机制。挤压输出后,被输入到多分支的全连接(FC)层,然后进行激励过程。分割的输入在最后被传递以恢复其原始形状。这种设计能够让网络更有效地学习到输入数据的不同特征,并且在进行特征转换时考虑到不同通道之间的相互依赖性。
三、SENetV2核心代码
下面的代码是SENetV2的核心代码,我们将其复制导'ultralytics/nn/modules'目录下,在其中创建一个文件,我这里起名为SENetV2然后粘贴进去,其余使用方式看章节四。
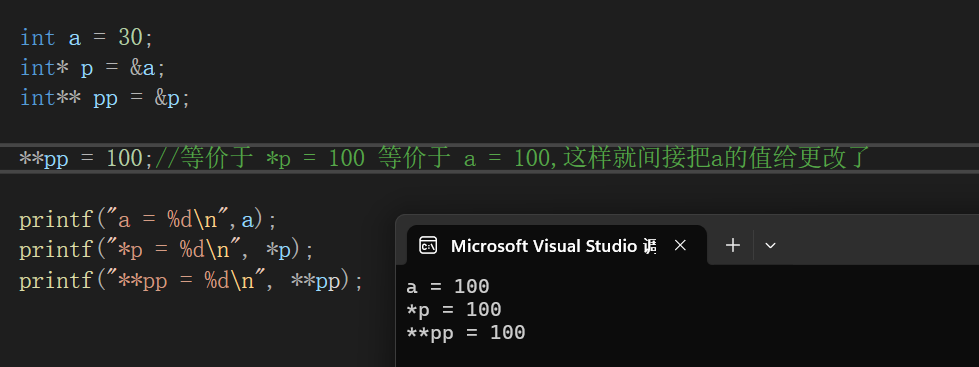
import torch
from torch import nn
import numpy as np
__all__ = ['SELayerV2', 'RepNCSPELAN4_SENetV2' ]
class SELayerV2(nn.Module):
def __init__(self, in_channel, reduction=32):
super(SELayerV2, self).__init__()
assert in_channel >= reduction and in_channel % reduction == 0, 'invalid in_channel in SaElayer'
self.reduction = reduction
self.cardinality = 4
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# cardinality 1
self.fc1 = nn.Sequential(
nn.Linear(in_channel, in_channel // self.reduction, bias=False),
nn.ReLU(inplace=True)
)
# cardinality 2
self.fc2 = nn.Sequential(
nn.Linear(in_channel, in_channel // self.reduction, bias=False),
nn.ReLU(inplace=True)
)
# cardinality 3
self.fc3 = nn.Sequential(
nn.Linear(in_channel, in_channel // self.reduction, bias=False),
nn.ReLU(inplace=True)
)
# cardinality 4
self.fc4 = nn.Sequential(
nn.Linear(in_channel, in_channel // self.reduction, bias=False),
nn.ReLU(inplace=True)
)
self.fc = nn.Sequential(
nn.Linear(in_channel // self.reduction * self.cardinality, in_channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y1 = self.fc1(y)
y2 = self.fc2(y)
y3 = self.fc3(y)
y4 = self.fc4(y)
y_concate = torch.cat([y1, y2, y3, y4], dim=1)
y_ex_dim = self.fc(y_concate).view(b, c, 1, 1)
return x * y_ex_dim.expand_as(x)
class RepConvN(nn.Module):
"""RepConv is a basic rep-style block, including training and deploy status
This code is based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
"""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=3, s=1, p=1, g=1, d=1, act=True, bn=False, deploy=False):
super().__init__()
assert k == 3 and p == 1
self.g = g
self.c1 = c1
self.c2 = c2
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
self.bn = None
self.conv1 = Conv(c1, c2, k, s, p=p, g=g, act=False)
self.conv2 = Conv(c1, c2, 1, s, p=(p - k // 2), g=g, act=False)
def forward_fuse(self, x):
"""Forward process"""
return self.act(self.conv(x))
def forward(self, x):
"""Forward process"""
id_out = 0 if self.bn is None else self.bn(x)
return self.act(self.conv1(x) + self.conv2(x) + id_out)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
kernelid, biasid = self._fuse_bn_tensor(self.bn)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _avg_to_3x3_tensor(self, avgp):
channels = self.c1
groups = self.g
kernel_size = avgp.kernel_size
input_dim = channels // groups
k = torch.zeros((channels, input_dim, kernel_size, kernel_size))
k[np.arange(channels), np.tile(np.arange(input_dim), groups), :, :] = 1.0 / kernel_size ** 2
return k
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, Conv):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
elif isinstance(branch, nn.BatchNorm2d):
if not hasattr(self, 'id_tensor'):
input_dim = self.c1 // self.g
kernel_value = np.zeros((self.c1, input_dim, 3, 3), dtype=np.float32)
for i in range(self.c1):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def fuse_convs(self):
if hasattr(self, 'conv'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.conv = nn.Conv2d(in_channels=self.conv1.conv.in_channels,
out_channels=self.conv1.conv.out_channels,
kernel_size=self.conv1.conv.kernel_size,
stride=self.conv1.conv.stride,
padding=self.conv1.conv.padding,
dilation=self.conv1.conv.dilation,
groups=self.conv1.conv.groups,
bias=True).requires_grad_(False)
self.conv.weight.data = kernel
self.conv.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('conv1')
self.__delattr__('conv2')
if hasattr(self, 'nm'):
self.__delattr__('nm')
if hasattr(self, 'bn'):
self.__delattr__('bn')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
def autopad(k, p=None, d=1): # kernel, padding, dilation
# Pad to 'same' shape outputs
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class RepNBottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, kernels, groups, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = RepConvN(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class RepNCSP(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(RepNBottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
class RepNCSPELAN4_SENetV2(nn.Module):
# csp-elan
def __init__(self, c1, c2, c3, c4, c5=1): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = c3//2
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = nn.Sequential(RepNCSP(c3//2, c4, c5), SELayerV2(c4), Conv(c4, c4, 3, 1))
self.cv3 = nn.Sequential(RepNCSP(c4, c4, c5), SELayerV2(c4), Conv(c4, c4, 3, 1))
self.cv4 = Conv(c3+(2*c4), c2, 1, 1)
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend((m(y[-1])) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
if __name__ == '__main__':
x1 = torch.randn(1, 32, 16, 16)
x2 = torch.randn(1, 32, 16, 16)
model = RepNCSPELAN4_SENetV2(32, 32, 32, 32)
x = model(x1)
print(x.shape)四、手把手教你添加SENetV2网络结构
4.1 细节修改教程
4.1.1 修改一
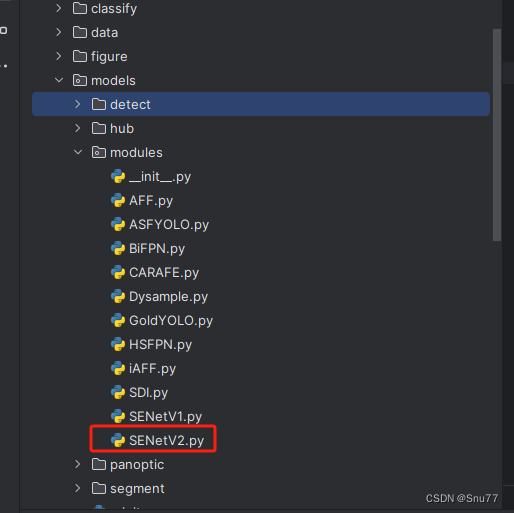
我们找到如下的目录'yolov9-main/models'在这个目录下创建一个文件目录(注意是目录,因为我这个专栏会出很多的更新,这里用一种一劳永逸的方法)文件目录起名modules,然后在下面新建一个文件,将我们的代码复制粘贴进去。
4.1.2 修改二
然后新建一个__init__.py文件,然后我们在里面添加一行代码。注意标记一个'.'其作用是标记当前目录。

4.1.3 修改三
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加)
注意的添加位置要放在common的导入上面!!!!!

4.1.4 修改四
然后我们找到parse_model方法,按照如下修改->
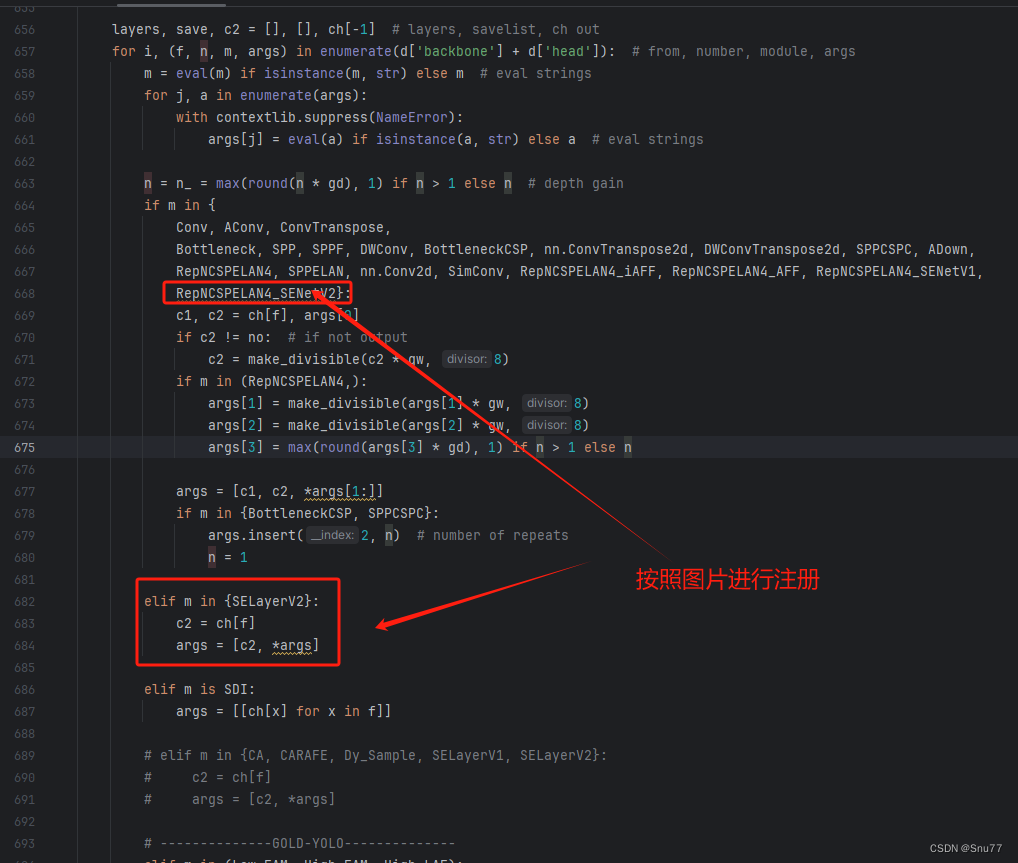
到此就修改完成了,复制下面的ymal文件即可运行。
4.2 SENetV2的yaml文件
4.2.1 SENetV2的yaml文件一
下面的配置文件为我修改的SENetV2的位置,参数的位置里面什么都不用添加空着就行,大家复制粘贴我的就可以运行,同时我提供多个版本给大家,根据我的经验可能涨点的位置。
# YOLOv9
# parameters
nc: 80 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()
# anchors
anchors: 3
# YOLOv9 backbone
backbone:
[
[-1, 1, Silence, []],
# conv down
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3
# conv down
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5
# conv down
[-1, 1, Conv, [512, 3, 2]], # 6-P4/16
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7
# conv down
[-1, 1, Conv, [512, 3, 2]], # 8-P5/32
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9
]
# YOLOv9 head
head:
[
[-1, 1, SELayerV2, []], # 添加一行我们的改进机制
# elan-spp block
[-1, 1, SPPELAN, [512, 256]], # 11
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 7], 1, Concat, [1]], # cat backbone P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 14
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P3
# elan-2 block
[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 17 (P3/8-small)
# conv-down merge
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 20 (P4/16-medium)
# conv-down merge
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 23 (P5/32-large)
# routing
[5, 1, CBLinear, [[256]]], # 24
[7, 1, CBLinear, [[256, 512]]], # 25
[9, 1, CBLinear, [[256, 512, 512]]], # 26
# conv down
[0, 1, Conv, [64, 3, 2]], # 27-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 28-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 29
# conv down fuse
[-1, 1, Conv, [256, 3, 2]], # 30-P3/8
[[24, 25, 26, -1], 1, CBFuse, [[0, 0, 0]]], # 31
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 32
# conv down fuse
[-1, 1, Conv, [512, 3, 2]], # 33-P4/16
[[25, 26, -1], 1, CBFuse, [[1, 1]]], # 34
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 35
# conv down fuse
[-1, 1, Conv, [512, 3, 2]], # 36-P5/32
[[26, -1], 1, CBFuse, [[2]]], # 37
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 38
# detect
[[32, 35, 38, 17, 20, 23], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)
]
4.2.2 SENetV2的yaml文件二
# YOLOv9
# parameters
nc: 80 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()
# anchors
anchors: 3
# YOLOv9 backbone
backbone:
[
[-1, 1, Silence, []],
# conv down
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3
# conv down
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5
# conv down
[-1, 1, Conv, [512, 3, 2]], # 6-P4/16
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7
# conv down
[-1, 1, Conv, [512, 3, 2]], # 8-P5/32
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9
]
# YOLOv9 head
head:
[
# elan-spp block
[-1, 1, SPPELAN, [512, 256]], # 10
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 7], 1, Concat, [1]], # cat backbone P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P3
# elan-2 block
[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 16 (P3/8-small)
[-1, 1, SELayerV2, []], # 17 添加一行我们的改进机制
# conv-down merge
[-1, 1, Conv, [256, 3, 2]],
[[-1, 13], 1, Concat, [1]], # cat head P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 20 (P4/16-medium)
[-1, 1, SELayerV2, []], # 21 添加一行我们的改进机制
# conv-down merge
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 24 (P5/32-large)
[-1, 1, SELayerV2, []], # 25 添加一行我们的改进机制
# routing
[5, 1, CBLinear, [[256]]], # 26
[7, 1, CBLinear, [[256, 512]]], # 27
[9, 1, CBLinear, [[256, 512, 512]]], # 28
# conv down
[0, 1, Conv, [64, 3, 2]], # 29-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 30-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 31
# conv down fuse
[-1, 1, Conv, [256, 3, 2]], # 32-P3/8
[[26, 27, 28, -1], 1, CBFuse, [[0, 0, 0]]], # 33
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 34
[-1, 1, SELayerV2, []], # 35 添加一行我们的改进机制
# conv down fuse
[-1, 1, Conv, [512, 3, 2]], # 36-P4/16
[[27, 28, -1], 1, CBFuse, [[1, 1]]], # 37
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 38
[-1, 1, SELayerV2, []], # 39 添加一行我们的改进机制
# conv down fuse
[-1, 1, Conv, [512, 3, 2]], # 40-P5/32
[[28, -1], 1, CBFuse, [[2]]], # 41
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 42
[-1, 1, SELayerV2, []], # 43 添加一行我们的改进机制
# detect
[[35, 39, 43, 17, 21, 25], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)
]
4.2.3 SENetV2的yaml文件三
注意此版本的我再大目标,小目标,中目标三个曾的后面添加了一个注意力机制,此版本需要显存较大,可以根据自己的需求增删,如果修改大家要注意修改Detect里面的检测层数。
# YOLOv9
# parameters
nc: 80 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()
# anchors
anchors: 3
# YOLOv9 backbone
backbone:
[
[-1, 1, Silence, []],
# conv down
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4_SENetV2, [256, 128, 64, 1]], # 3
# conv down
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
# elan-2 block
[-1, 1, RepNCSPELAN4_SENetV2, [512, 256, 128, 1]], # 5
# conv down
[-1, 1, Conv, [512, 3, 2]], # 6-P4/16
# elan-2 block
[-1, 1, RepNCSPELAN4_SENetV2, [512, 512, 256, 1]], # 7
# conv down
[-1, 1, Conv, [512, 3, 2]], # 8-P5/32
# elan-2 block
[-1, 1, RepNCSPELAN4_SENetV2, [512, 512, 256, 1]], # 9
]
# YOLOv9 head
head:
[
# elan-spp block
[-1, 1, SPPELAN, [512, 256]], # 10
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 7], 1, Concat, [1]], # cat backbone P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P3
# elan-2 block
[-1, 1, RepNCSPELAN4_SENetV2, [256, 256, 128, 1]], # 16 (P3/8-small)
# conv-down merge
[-1, 1, Conv, [256, 3, 2]],
[[-1, 13], 1, Concat, [1]], # cat head P4
# elan-2 block
[-1, 1, RepNCSPELAN4_SENetV2, [512, 512, 256, 1]], # 19 (P4/16-medium)
# conv-down merge
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
# elan-2 block
[-1, 1, RepNCSPELAN4_SENetV2, [512, 512, 256, 1]], # 22 (P5/32-large)
# routing
[5, 1, CBLinear, [[256]]], # 23
[7, 1, CBLinear, [[256, 512]]], # 24
[9, 1, CBLinear, [[256, 512, 512]]], # 25
# conv down
[0, 1, Conv, [64, 3, 2]], # 26-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 27-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4_SENetV2, [256, 128, 64, 1]], # 28
# conv down fuse
[-1, 1, Conv, [256, 3, 2]], # 29-P3/8
[[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30
# elan-2 block
[-1, 1, RepNCSPELAN4_SENetV2, [512, 256, 128, 1]], # 31
# conv down fuse
[-1, 1, Conv, [512, 3, 2]], # 32-P4/16
[[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33
# elan-2 block
[-1, 1, RepNCSPELAN4_SENetV2, [512, 512, 256, 1]], # 34
# conv down fuse
[-1, 1, Conv, [512, 3, 2]], # 35-P5/32
[[25, -1], 1, CBFuse, [[2]]], # 36
# elan-2 block
[-1, 1, RepNCSPELAN4_SENetV2, [512, 512, 256, 1]], # 37
# detect
[[31, 34, 37, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)
]
4.3 SENetV2运行成功截图
附上我的运行记录确保我的教程是可用的。

五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv5改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏地址:YOLOv9有效涨点专栏-持续复现各种顶会内容-有效涨点-全网改进最全的专栏