【深度学习】wandb模型训练可视化工具使用方法
- wandb简介
- 功能介绍
- 登陆注册以及API keys
- project和runs
- project和runs的关系
- wandb的配置
- 实验跟踪
- 版本管理
- Case可视化分析
- 可视化自动调参(wandb.sweep)
- 配置wandb.sweep
- 1.配置 sweep_config
- 2.初始化 sweep controller
- 3.启动 Sweep agent
本文参考的教程来自B站大学:wandb我最爱的炼丹伴侣操作指南
在此感谢UP主分享的教程~
wandb官方文档链接
wandb简介
- Wandb(Weights & Biases)是一款专为机器学习和深度学习设计的可视化工具,旨在帮助开发者更高效地跟踪、可视化和共享实验结果
- 提供在线平台,可以轻松记录实验的超参数、输出指标以及模型的变化,并通过直观的仪表盘展示这些信息
- 与tensorboard类似,均是机器学习可视化分析工具
- wandb相较于Tensorboard的优势:
1.wandb的日志文件上传云端存储,可永久保存,tensorboard存储在本地
2.wandb存储代码,数据集,模型,并进行版本管理(wandb.Artifact 自动完成),同时版本与日志关联
3.wandb.Artifact 是 Weights & Biases (W&B) 提供的一个灵活且轻量级的构建块,用于数据集和模型的版本控制。通过使用 wandb.Artifact,用户可以轻松地跟踪和管理机器学习项目中的数据集、模型和其他重要文件
4.可使用交互式表格进行模型评估(wandb.Table),excel表格的单元格中无法存储图像,视频,音频等内容,而wandb提供的Table可以实现上述功能
5.可视化自动模型调参(wandb.sweep),可并行调参,相当优雅
功能介绍
- 本文将介绍wandb以下4个功能:实验跟踪,版本管理,case分析(模型评估),参数调优

登陆注册以及API keys
- 登陆注册就不进行介绍啦,很简单,wandb官网注册链接
- wandb的API keys是一种用于身份验证的密钥,它允许用户连接和认证他们的机器学习项目与wandb平台
- API keys作为一种访问控制机制,确保了用户能够安全地访问和管理在wandb平台上的项目、实验和运行
- API keys的获取:登陆后右上角头像–>User Settings–>Danger Zone API keys–> 点击reveal即可看到
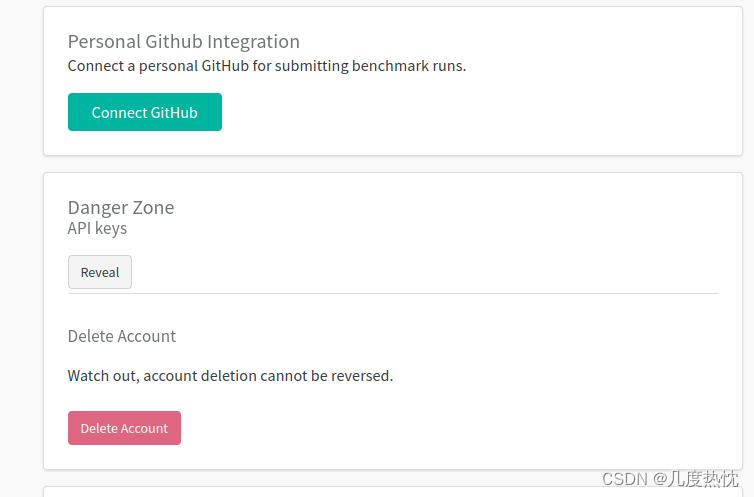
- 另一种查看API keys的方法:访问https://wandb.ai/authorize需要先注册登录,链接直达
project和runs
- 在使用wandb进行机器学习项目管理和跟踪时,项目(project)和运行(runs)是两个核心概念
- 项目(Project):项目是在wandb中创建的一个容器,用于组织和管理相关的运行
- 项目可以将不同的运行分组在一起,以便更好地跟踪和比较实验结果

- 点击Project会进入项目空间
- 运行代表了单个实验或模型训练的实例
- 每次启动一个新的训练任务或实验时,都会创建一个新的运行
- 运行会记录实验的所有详细信息,包括代码版本、数据集、超参数、日志数据和模型性能指标

project和runs的关系
- 一个项目可以包含多个运行。每个运行都是项目下的一个子项,它们共享相同的配置和上下文
- 运行可以被视为项目中的一个实验或迭代。通过比较同一项目下的不同运行,您可以分析不同超参数或方法的效果
- 项目为运行提供了一个命名空间,使得您可以轻松地查找和比较相关的运行
- 可以在项目中设置共享的配置和超参数,然后在创建运行时覆盖特定的值,这样可以进行有针对性的实验
- 个人理解:一个项目就对应一个模型,一个运行对应该模型的一次执行(训练或测试)
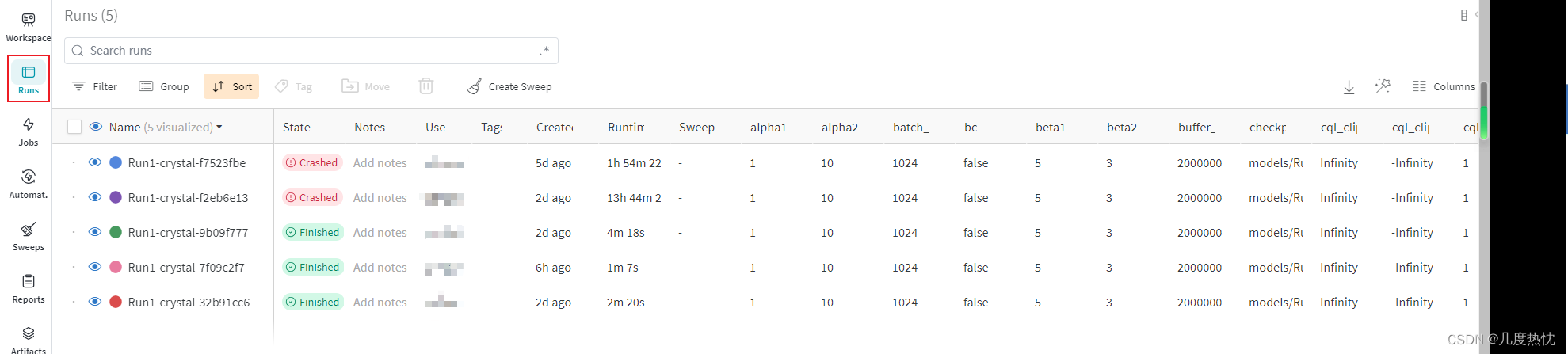
在project中点击侧边栏的Runs会以Table形式显示多次run的结果
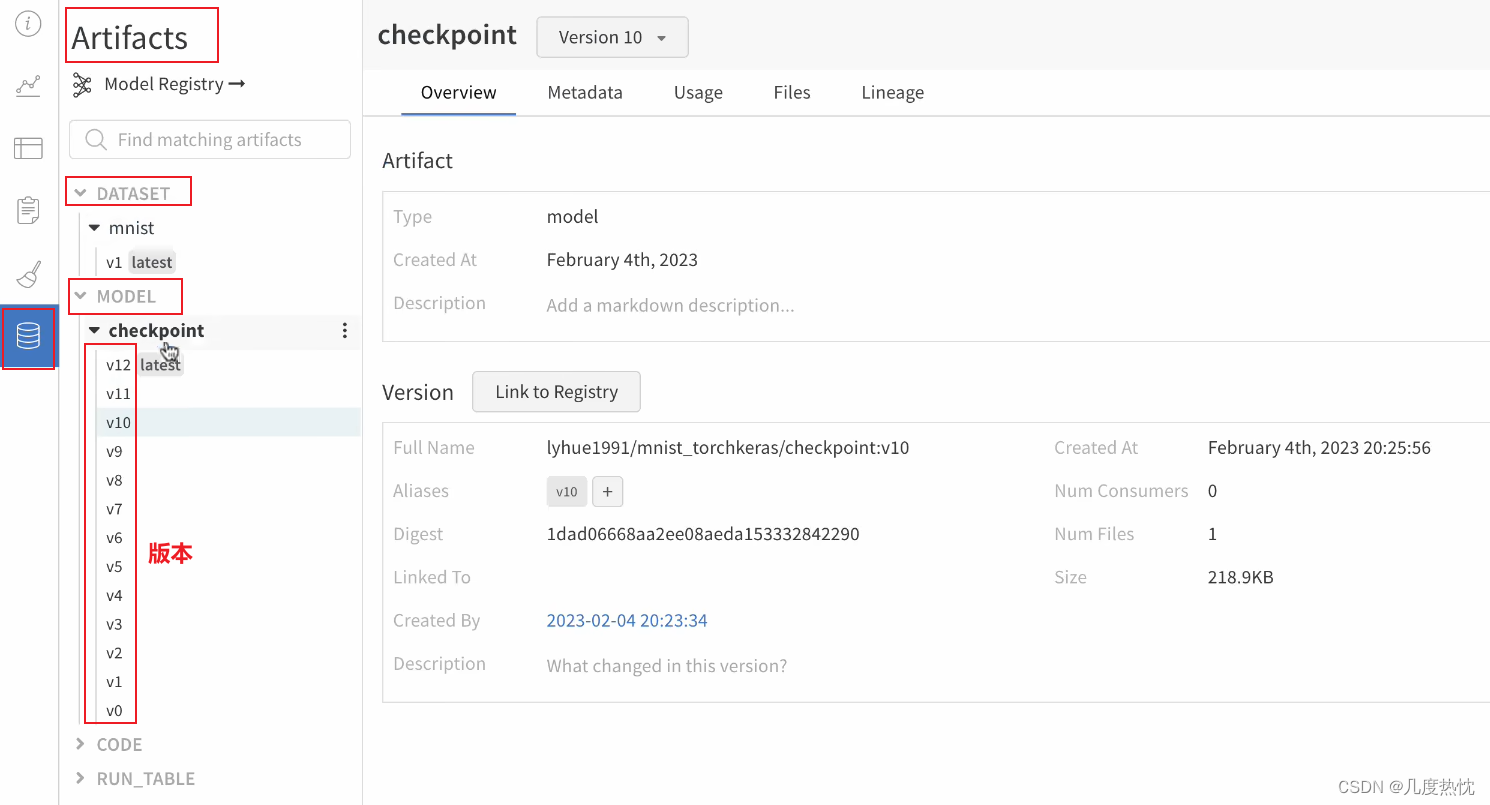
在project中点击侧边栏的Artifacts记录数据集,模型的版本
wandb的配置
- 首先要安装pip install wandb哦
- 在代码中进行身份验证,通过调用wandb.login函数,能够使用API key 来连接本地脚本与wandb服务
import wandb
wandb.login(key='你的API keys')
实验跟踪

- 代码来自B站up主:一个有毅力的吃货,30分钟吃掉wandb模型训练可视化,再次感谢
- 下面的代码涉及的数据集的划分,模型的搭建,以及训练和评估,在此省略不谈
- 涉及到wandb的使用主要集中在def train(config = config)这个函数中
- 涉及到使用wandb.init函数初始化wandb项目
- 在每个epoch结束时,使用wandb.log函数记录当前的epoch数、验证准确率val_acc和最佳验证准确率model.best_metric。这些信息将被上传到wandb的云端,可以在wandb的仪表板上进行可视化
- 在训练所有epoch后,使用wandb.finish函数标记当前运行完成
- 对于wandb的函数具体方法需要查阅一下官方文档或其他教程
import wandb
wandb.login(key='你的API keys')
import os,PIL
import numpy as np
from torch.utils.data import DataLoader, Dataset
import torch
from torch import nn
import torchvision
from torchvision import transforms
import datetime
import wandb
from argparse import Namespace
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
config = Namespace(
project_name = 'wandb_demo',
batch_size = 512,
hidden_layer_width = 64,
dropout_p = 0.1,
lr = 1e-4,
optim_type = 'Adam',
epochs = 15,
ckpt_path = 'checkpoint.pt'
)
def create_dataloaders(config):
transform = transforms.Compose([transforms.ToTensor()])
ds_train = torchvision.datasets.MNIST(root="./mnist/",train=True,download=True,transform=transform)
ds_val = torchvision.datasets.MNIST(root="./mnist/",train=False,download=True,transform=transform)
ds_train_sub = torch.utils.data.Subset(ds_train, indices=range(0, len(ds_train), 5))
dl_train = torch.utils.data.DataLoader(ds_train_sub, batch_size=config.batch_size, shuffle=True,
num_workers=2,drop_last=True)
dl_val = torch.utils.data.DataLoader(ds_val, batch_size=config.batch_size, shuffle=False,
num_workers=2,drop_last=True)
return dl_train,dl_val
def create_net(config):
net = nn.Sequential()
net.add_module("conv1",nn.Conv2d(in_channels=1,out_channels=config.hidden_layer_width,kernel_size = 3))
net.add_module("pool1",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("conv2",nn.Conv2d(in_channels=config.hidden_layer_width,
out_channels=config.hidden_layer_width,kernel_size = 5))
net.add_module("pool2",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("dropout",nn.Dropout2d(p = config.dropout_p))
net.add_module("adaptive_pool",nn.AdaptiveMaxPool2d((1,1)))
net.add_module("flatten",nn.Flatten())
net.add_module("linear1",nn.Linear(config.hidden_layer_width,config.hidden_layer_width))
net.add_module("relu",nn.ReLU())
net.add_module("linear2",nn.Linear(config.hidden_layer_width,10))
net.to(device)
return net
def train_epoch(model,dl_train,optimizer):
model.train()
for step, batch in enumerate(dl_train):
features,labels = batch
features,labels = features.to(device),labels.to(device)
preds = model(features)
loss = nn.CrossEntropyLoss()(preds,labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
return model
def eval_epoch(model,dl_val):
model.eval()
accurate = 0
num_elems = 0
for batch in dl_val:
features,labels = batch
features,labels = features.to(device),labels.to(device)
with torch.no_grad():
preds = model(features)
predictions = preds.argmax(dim=-1)
accurate_preds = (predictions==labels)
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.long().sum()
val_acc = accurate.item() / num_elems
return val_acc
def train(config = config):
dl_train, dl_val = create_dataloaders(config)
model = create_net(config);
optimizer = torch.optim.__dict__[config.optim_type](params=model.parameters(), lr=config.lr)
#======================================================================
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
wandb.init(project=config.project_name, config = config.__dict__, name = nowtime, save_code=True)
model.run_id = wandb.run.id
#======================================================================
model.best_metric = -1.0
for epoch in range(1,config.epochs+1):
model = train_epoch(model,dl_train,optimizer)
val_acc = eval_epoch(model,dl_val)
if val_acc>model.best_metric:
model.best_metric = val_acc
torch.save(model.state_dict(),config.ckpt_path)
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(f"epoch【{epoch}】@{nowtime} --> val_acc= {100 * val_acc:.2f}%")
#======================================================================
wandb.log({'epoch':epoch, 'val_acc': val_acc, 'best_val_acc':model.best_metric})
#======================================================================
#======================================================================
wandb.finish()
#======================================================================
return model
model = train(config)
-
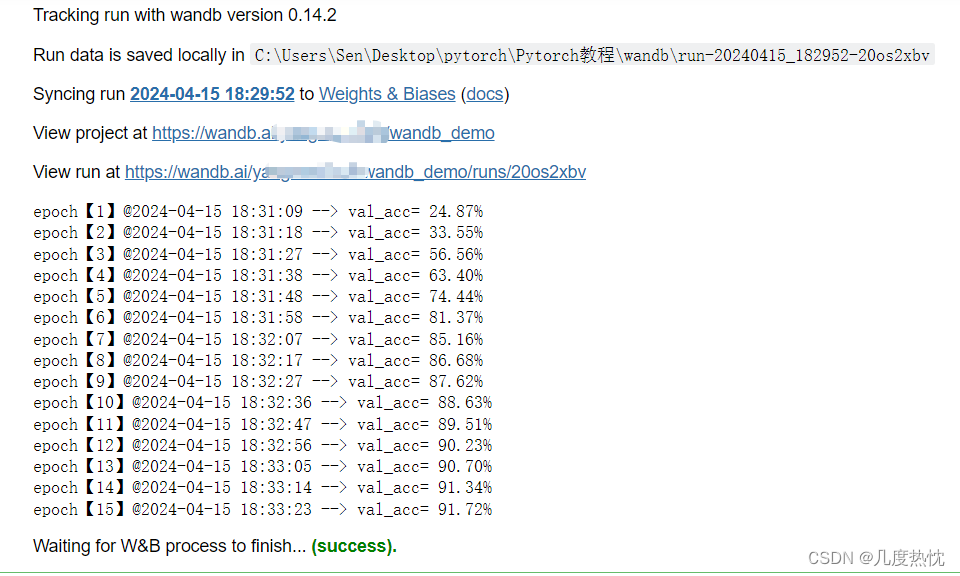
如遇到CommError: Run initialization has timed out after 60.0 sec,wandb.init处报错,可尝试一下关闭代理后重新执行
-
点击链接进入runs,可查看训练过程,默认的横坐标为step,每调用一次wandb.log,step就会+1
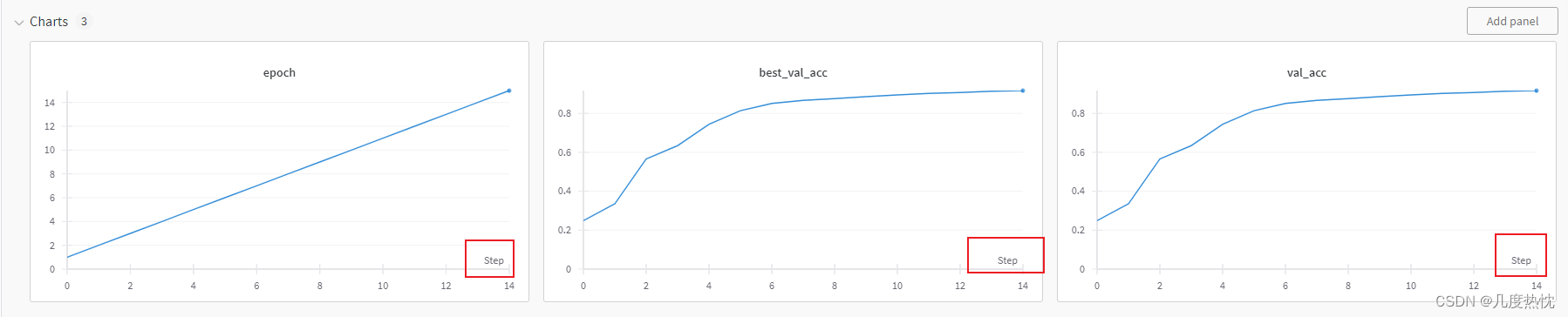
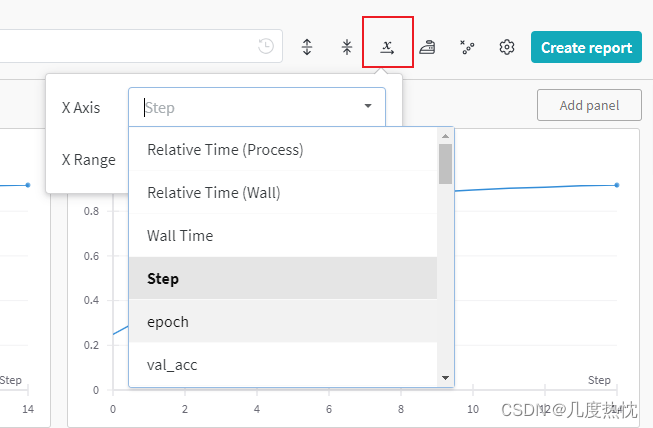
- 点击
x
→
\underset{\rightarrow}{\text{x}}
→x可修改横坐标
点击delete可以将图放在hidden panels中
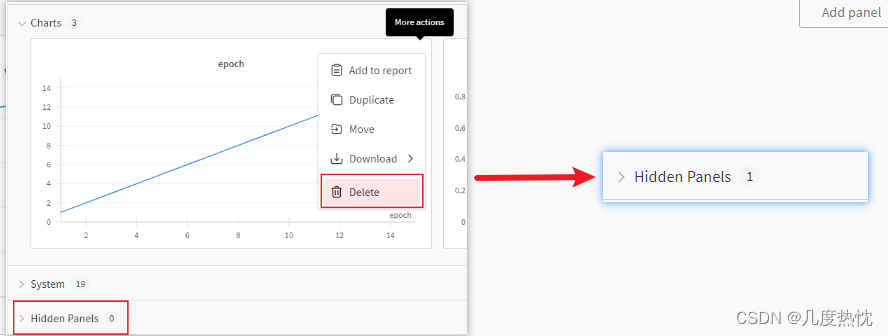
- 点击add panel可以添加各种可视化图
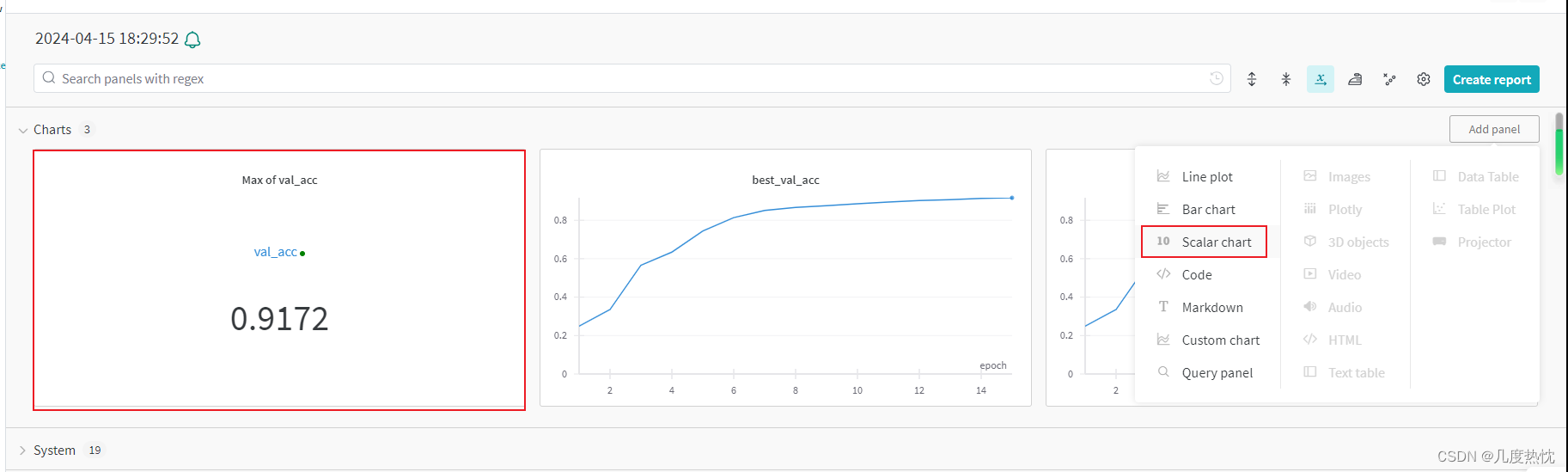
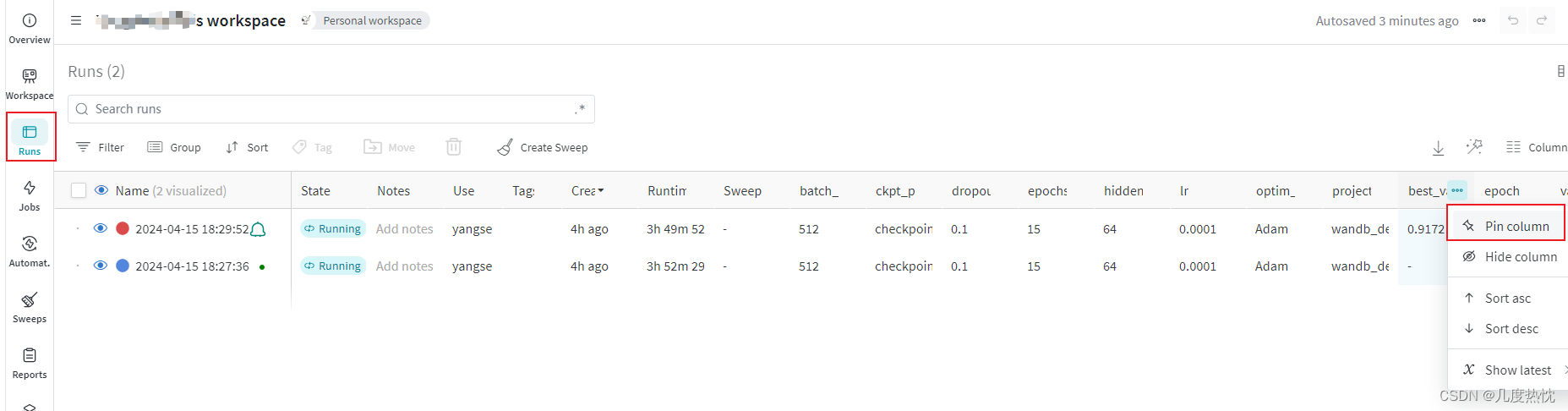
- 在Table(左侧runs)中,可对指标的进行pin column(置顶)

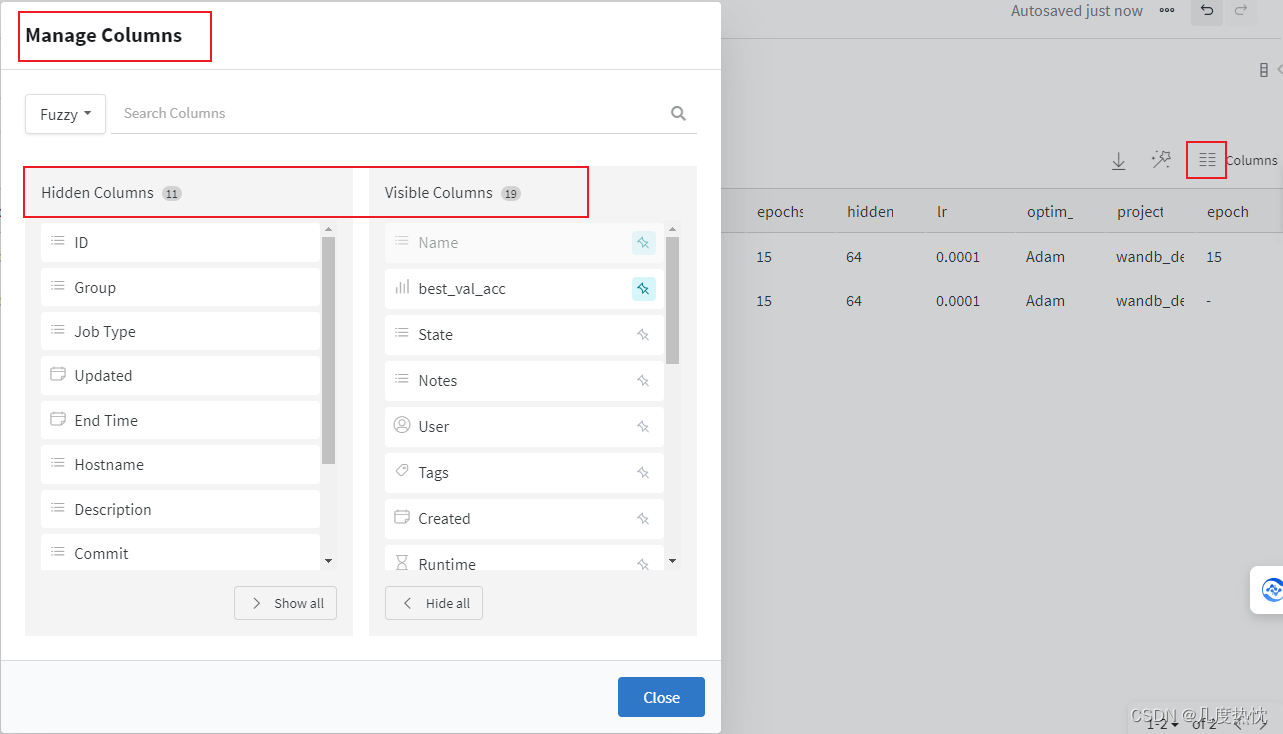
- 点击右侧Manage Columns,可控制可见与不可见的变量
版本管理

- wandb.Artifact 可以创建一个新的 artifact 对象,这个对象可以包含模型、数据集、代码片段等,它们可以一起被上传到 Wandb 的云端存储中
- 通过调用 add_file 方法,可以将文件或目录添加到 artifact 中。这使得用户可以将训练好的模型、数据处理脚本、以及其他相关文件打包到一个 artifact 中,方便后续的分享和复现
- wandb.log_artifact 方法,可以将 artifact 记录到当前的运行中。这样,每次实验的输出都可以与特定的运行相关联,便于跟踪和比较不同实验的结果
- 使用 wandb.log_artifact 方法,可以将 Artifact 实例记录到当前的 W&B 运行(run)中。这允许用户在 W&B 的仪表板中查看和共享这些工件
import wandb
run = wandb.init(project='wandb_demo', id= model.run_id, resume='must')
# save dataset
arti_dataset = wandb.Artifact('mnist', type='dataset')
arti_dataset.add_dir('mnist/')
wandb.log_artifact(arti_dataset)
# save code
arti_code = wandb.Artifact('ipynb', type='code')
arti_code.add_file('./30分钟吃掉wandb可视化模型分析.ipynb')
wandb.log_artifact(arti_code)
# save model
arti_model = wandb.Artifact('cnn', type='model')
arti_model.add_file(config.ckpt_path)
wandb.log_artifact(arti_model)
wandb.finish() #finish时会提交保存
- 一直没上传成功,试了很多方法,比如设置为offline模式,之后再同步,未成功
- 解决方法请看这里:执行wandb sync同步命令报错wandb: Network error (SSLError), entering retry loop
-
这里我就不进行演示啦,没上传成功,不然是可以在下图中找到代码和数据集的
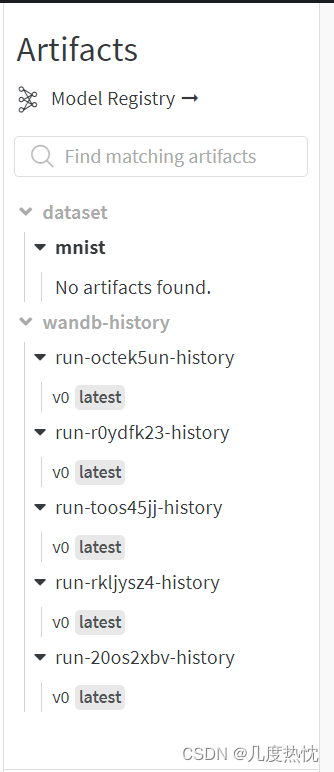
-
类似下面这样:
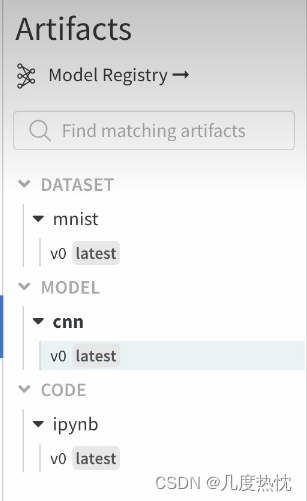
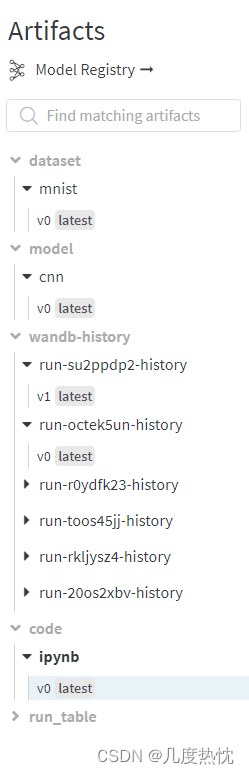
- 按照上面的方法,我上传成功啦
Case可视化分析

- wandb.Table 是用于创建表格的 Wandb 类,它可以将多个数据点以表格的形式展示。这对于比较不同模型的性能或者展示数据集的某些特征非常有用
- wandb.Image 类用于上传和记录图像数据,可以用于展示模型输入、输出或中间结果的图像
- 最后进行wandb.log,记录各种数据到当前运行,它可以记录标量、图像、表格、文本等多种类型的数据
#resume the run
import wandb
run = wandb.init(project=config.project_name, id= model.run_id, resume='must')
import matplotlib.pyplot as plt
transform = transforms.Compose([transforms.ToTensor()])
ds_train = torchvision.datasets.MNIST(root="./mnist/",train=True,download=True,transform=transform)
ds_val = torchvision.datasets.MNIST(root="./mnist/",train=False,download=True,transform=transform)
# visual the prediction
device = None
for p in model.parameters():
device = p.device
break
plt.figure(figsize=(8,8))
for i in range(9):
img,label = ds_val[i]
tensor = img.to(device)
y_pred = torch.argmax(model(tensor[None,...]))
img = img.permute(1,2,0)
ax=plt.subplot(3,3,i+1)
ax.imshow(img.numpy())
ax.set_title("y_pred = %d"%y_pred)
ax.set_xticks([])
ax.set_yticks([])
plt.show()
def data2fig(data):
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot()
ax.imshow(data)
ax.set_xticks([])
ax.set_yticks([])
return fig
def fig2img(fig):
import io,PIL
buf = io.BytesIO()
fig.savefig(buf)
buf.seek(0)
img = PIL.Image.open(buf)
return img
from tqdm import tqdm
good_cases = wandb.Table(columns = ['Image','GroundTruth','Prediction'])
bad_cases = wandb.Table(columns = ['Image','GroundTruth','Prediction'])
# 找到50个good cases 和 50 个bad cases
plt.close()
for i in tqdm(range(1000)):
features,label = ds_val[i]
tensor = features.to(device)
y_pred = torch.argmax(model(tensor[None,...]))
# log badcase
if y_pred!=label:
if len(bad_cases.data)<50:
data = features.permute(1,2,0).numpy()
input_img = wandb.Image(fig2img(data2fig(data)))
bad_cases.add_data(input_img,label,y_pred)
# log goodcase
else:
if len(good_cases.data)<50:
data = features.permute(1,2,0).numpy()
input_img = wandb.Image(fig2img(data2fig(data)))
good_cases.add_data(input_img,label,y_pred)
wandb.log({'good_cases':good_cases,'bad_cases':bad_cases})
wandb.finish()

- 然后根据提示的同步命令将日志文件上传至wandb服务器
- 在wandb官网打开对应的runs,可以看到这两个表格,按道理应该显示出图片的
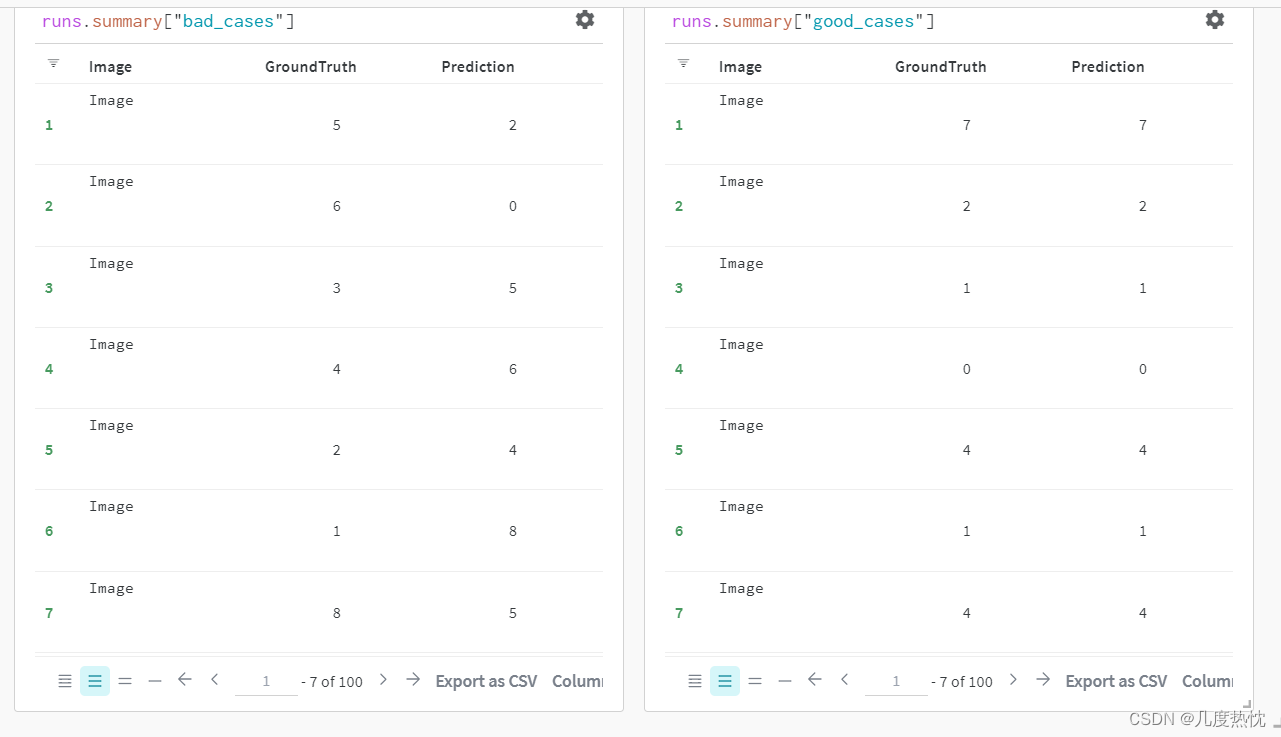
-
不知道为什么图片没显示,按道理应该是这个样子的
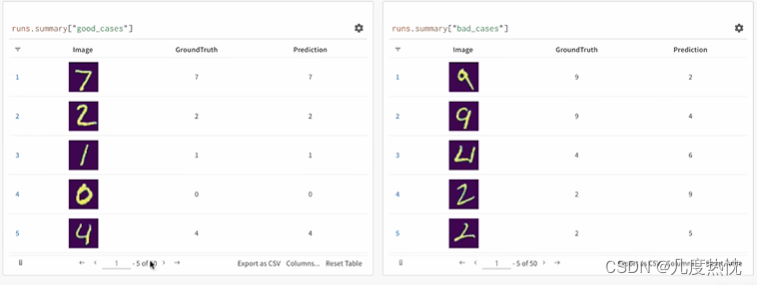
-
不知道是不是因为上传的文件太大了
-
在表格中可对各列进行升序降序显示
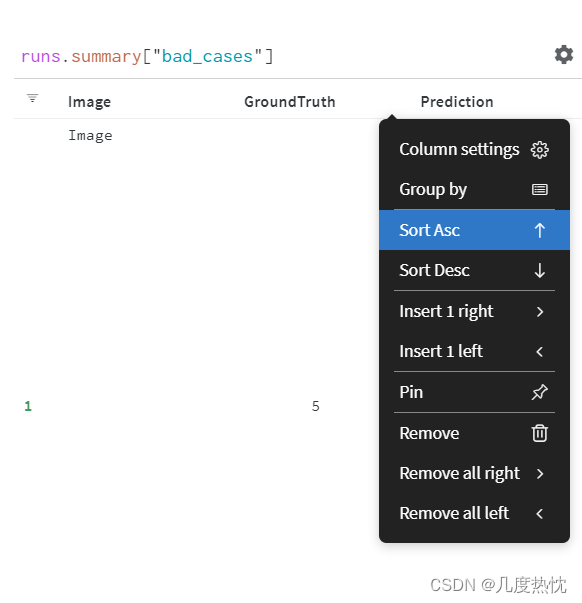
-
在表格中可进行聚合Group by
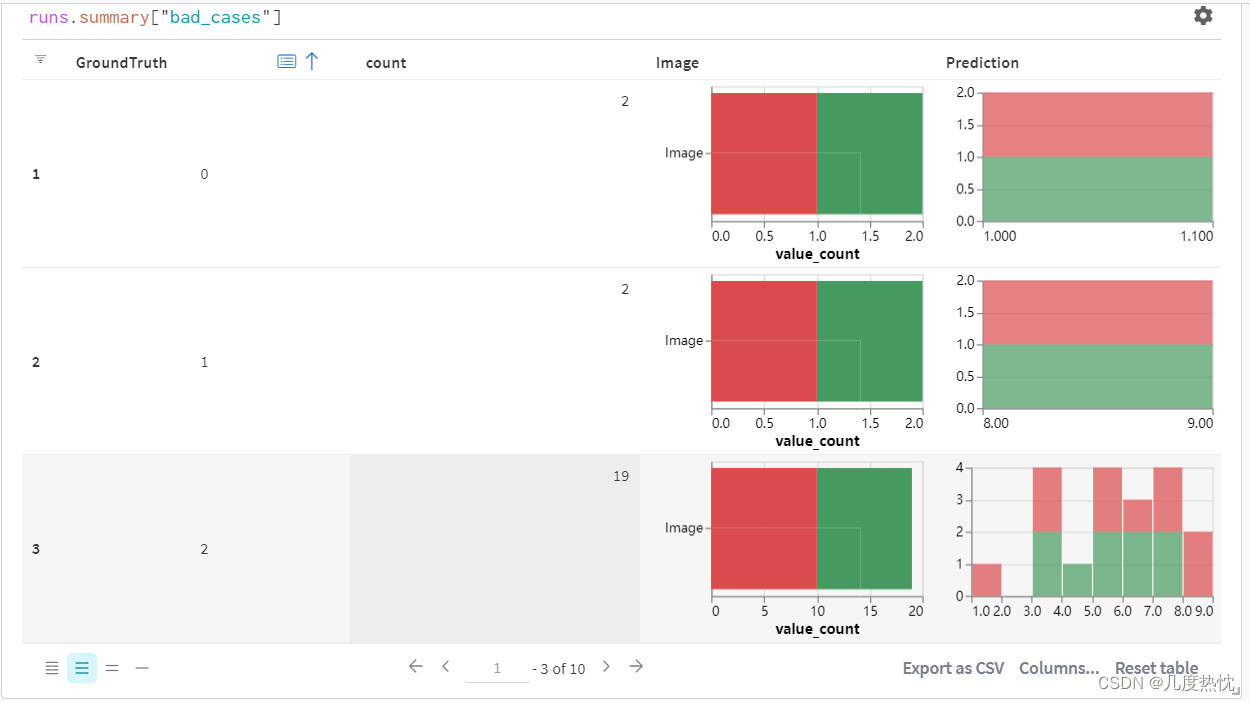
-
可对列进行编辑,类似excel的公式,十分灵活
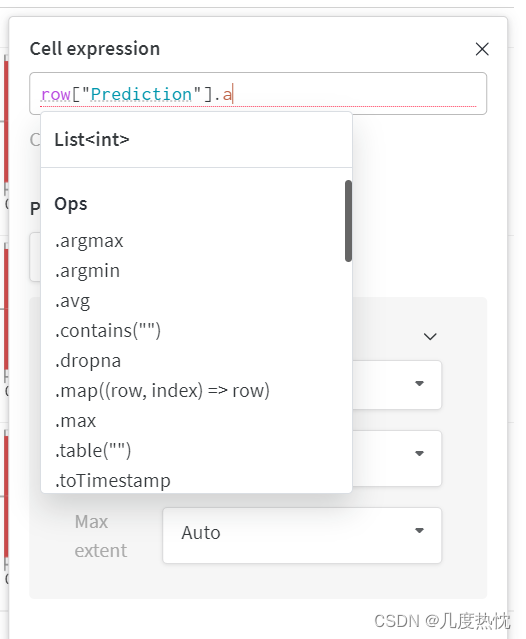

可视化自动调参(wandb.sweep)

下面的图来自的原作者30分钟吃掉wandb可视化自动调参
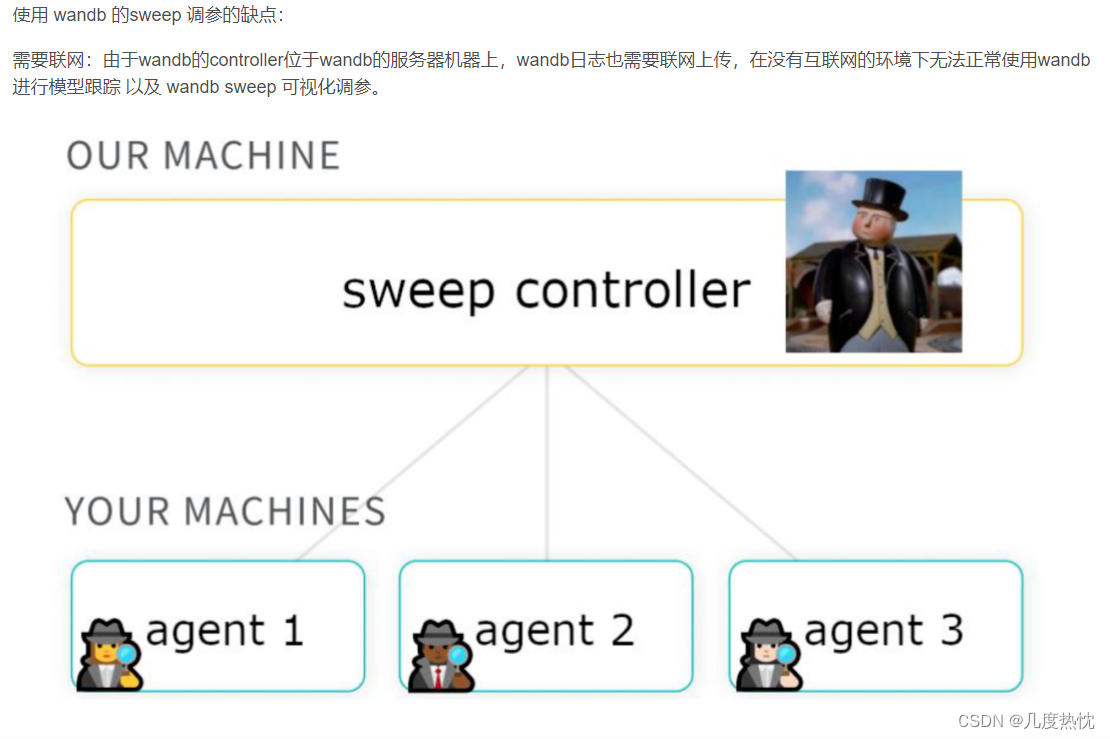
- wandb.sweep使用流程

配置wandb.sweep
from argparse import Namespace
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#初始化参数配置
config = Namespace(
project_name = 'wandb_demo',
batch_size = 512,
hidden_layer_width = 64,
dropout_p = 0.1,
lr = 1e-4,
optim_type = 'Adam',
epochs = 15,
ckpt_path = 'checkpoint.pt'
)
1.配置 sweep_config
- 1.选择调优算法

- 2.定义调优目标,设置优化指标,以及优化方向
sweep agents 通过 wandb.log 的形式向 sweep controller 传递优化目标的值 - 3.定义超参空间,超参空间可以分成 固定型,离散型和连续型

- 4.定义剪枝策略 (可选),定义剪枝策略,提前终止那些没有希望的任务
在使用 wandb.sweep 进行超参数调优时,可以通过定义剪枝策略来提前终止那些表现不佳的任务,从而节省资源并加速寻找最佳超参数的过程。
early_terminate 配置允许你指定一个早期终止策略,下面的代码使用的是 hyperband 算法。
以下是 hyperband 早期终止策略的参数解释:
‘type’: 指定使用的早期终止算法的类型。在这个例子中,我们使用 ‘hyperband’,这是一种基于成功率的早期终止策略,它在多个性能水平上并行运行实验,并根据性能结果动态调整资源分配。
‘min_iter’: 每个实验的最小迭代次数。即使实验表现不佳,也会运行足够多次以收集有意义的数据。
‘eta’: 性能水平之间的资源比例。例如,eta=2 意味着每次迭代,实验的资源会减半。这通常与 ‘s’ 参数一起使用,以确定每个性能水平的资源分配。
‘s’: 性能水平的数量。这是一个整数,指定算法在早期终止过程中使用的资源级别数。s 越大,算法在早期阶段就越保守,因为它会尝试更多的性能水平。
通过设置这些参数,你可以定制 hyperband 算法的行为,以平衡资源使用效率和找到最佳超参数配置的可能性。例如,如果你希望在早期阶段快速淘汰表现不佳的实验,可以增加 s 的值并减小 eta 的值。
- 上述步骤代码汇总:
from argparse import Namespace
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#初始化参数配置
config = Namespace(
project_name = 'wandb_demo',
batch_size = 512,
hidden_layer_width = 64,
dropout_p = 0.1,
lr = 1e-4,
optim_type = 'Adam',
epochs = 15,
ckpt_path = 'checkpoint.pt'
)
#选择一个调优算法
sweep_config = {
'method': 'random'
}
#定义调优目标 设置优化指标,以及优化方向
metric = {
'name': 'val_acc',
'goal': 'maximize'
}
sweep_config['metric'] = metric
#定义超参空间
sweep_config['parameters'] = {}
# 固定不变的超参
sweep_config['parameters'].update({
'project_name':{'value':'wandb_demo'},
'epochs': {'value': 10},
'ckpt_path': {'value':'checkpoint.pt'}})
# 离散型分布超参
sweep_config['parameters'].update({
'optim_type': {
'values': ['Adam', 'SGD','AdamW']
},
'hidden_layer_width': {
'values': [16,32,48,64,80,96,112,128]
}
})
# 连续型分布超参
sweep_config['parameters'].update({
'lr': {
'distribution': 'log_uniform_values',
'min': 1e-6,
'max': 0.1
},
'batch_size': {
'distribution': 'q_uniform',
'q': 8,
'min': 32,
'max': 256,
},
'dropout_p': {
'distribution': 'uniform',
'min': 0,
'max': 0.6,
}
})
#定义剪枝策略,提前终止那些没有希望的任务
sweep_config['early_terminate'] = {
'type':'hyperband',
'min_iter':3,
'eta':2,
's':3
} #在step=3, 6, 12 时考虑是否剪枝
from pprint import pprint
pprint(sweep_config)

2.初始化 sweep controller
- 调用 wandb.sweep() 并传入一个函数,该函数将使用 wandb.init() 初始化每个实验的配置
sweep_id = wandb.sweep(sweep_config, project=config.project_name)

- 点击链接查看sweep

- 或者在侧边栏的Sweeps
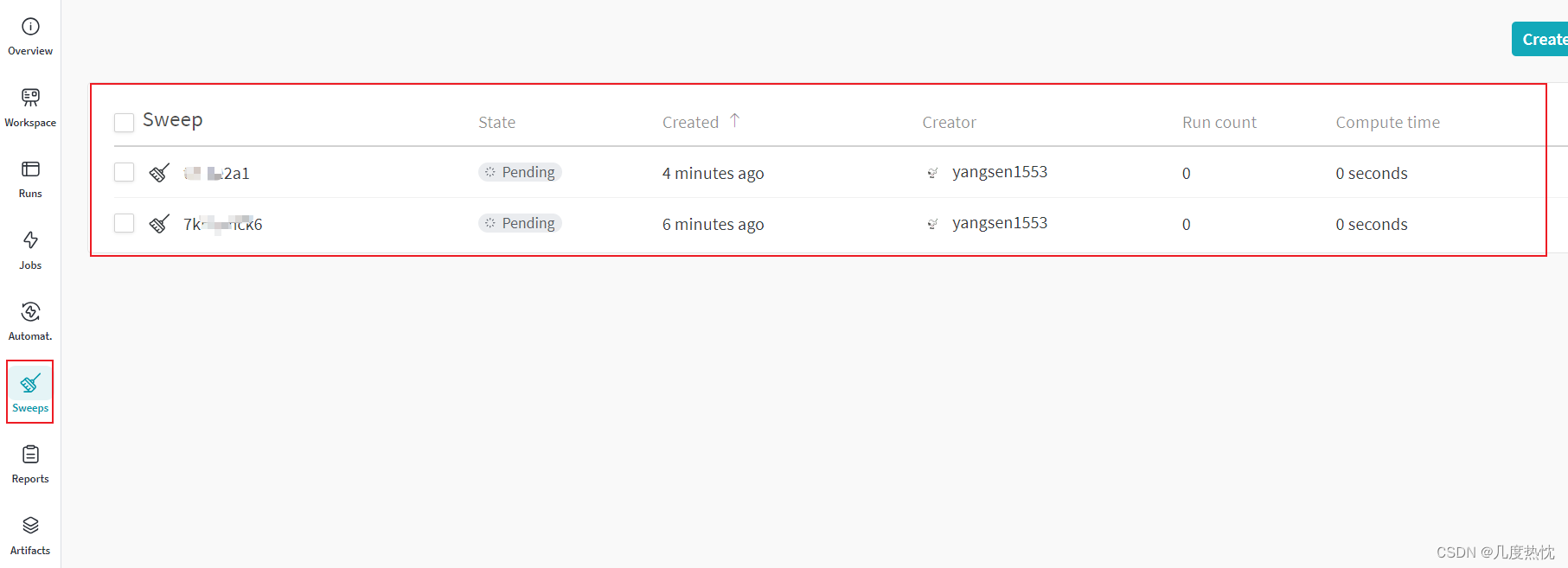
3.启动 Sweep agent
- 把模型训练相关的全部代码整理成一个 train函数
- 让agent执行训练,搜索超参数
#把模型训练相关的全部代码整理成一个 train函数
def create_dataloaders(config):
transform = transforms.Compose([transforms.ToTensor()])
ds_train = torchvision.datasets.MNIST(root="./mnist/",train=True,download=True,transform=transform)
ds_val = torchvision.datasets.MNIST(root="./mnist/",train=False,download=True,transform=transform)
ds_train_sub = torch.utils.data.Subset(ds_train, indices=range(0, len(ds_train), 5))
dl_train = torch.utils.data.DataLoader(ds_train_sub, batch_size=config.batch_size, shuffle=True,
num_workers=2,drop_last=True)
dl_val = torch.utils.data.DataLoader(ds_val, batch_size=config.batch_size, shuffle=False,
num_workers=2,drop_last=True)
return dl_train,dl_val
def create_net(config):
net = nn.Sequential()
net.add_module("conv1",nn.Conv2d(in_channels=1,out_channels=config.hidden_layer_width,kernel_size = 3))
net.add_module("pool1",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("conv2",nn.Conv2d(in_channels=config.hidden_layer_width,
out_channels=config.hidden_layer_width,kernel_size = 5))
net.add_module("pool2",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("dropout",nn.Dropout2d(p = config.dropout_p))
net.add_module("adaptive_pool",nn.AdaptiveMaxPool2d((1,1)))
net.add_module("flatten",nn.Flatten())
net.add_module("linear1",nn.Linear(config.hidden_layer_width,config.hidden_layer_width))
net.add_module("relu",nn.ReLU())
net.add_module("linear2",nn.Linear(config.hidden_layer_width,10))
return net
def train_epoch(model,dl_train,optimizer):
model.train()
for step, batch in enumerate(dl_train):
features,labels = batch
features,labels = features.to(device),labels.to(device)
preds = model(features)
loss = nn.CrossEntropyLoss()(preds,labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
return model
def eval_epoch(model,dl_val):
model.eval()
accurate = 0
num_elems = 0
for batch in dl_val:
features,labels = batch
features,labels = features.to(device),labels.to(device)
with torch.no_grad():
preds = model(features)
predictions = preds.argmax(dim=-1)
accurate_preds = (predictions==labels)
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.long().sum()
val_acc = accurate.item() / num_elems
return val_acc
def train(config = config):
dl_train, dl_val = create_dataloaders(config)
model = create_net(config);
model = model.to(device)
optimizer = torch.optim.__dict__[config.optim_type](params=model.parameters(), lr=config.lr)
#======================================================================
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
wandb.init(project=config.project_name, config = config.__dict__, name = nowtime, save_code=True)
model.run_id = wandb.run.id
#======================================================================
model.best_metric = -1.0
for epoch in range(1,config.epochs+1):
model = train_epoch(model,dl_train,optimizer)
val_acc = eval_epoch(model,dl_val)
if val_acc>model.best_metric:
model.best_metric = val_acc
torch.save(model.state_dict(),config.ckpt_path)
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(f"epoch【{epoch}】@{nowtime} --> val_acc= {100 * val_acc:.2f}%")
#======================================================================
wandb.log({'epoch':epoch, 'val_acc': val_acc, 'best_val_acc':model.best_metric})
#======================================================================
#======================================================================
wandb.finish()
#======================================================================
return model
# 该agent 随机搜索 尝试5次
wandb.agent(sweep_id, train, count=5)
-
上面的代码会将完整的训练过程执行5遍
-
注意每一遍的超参数是不同的
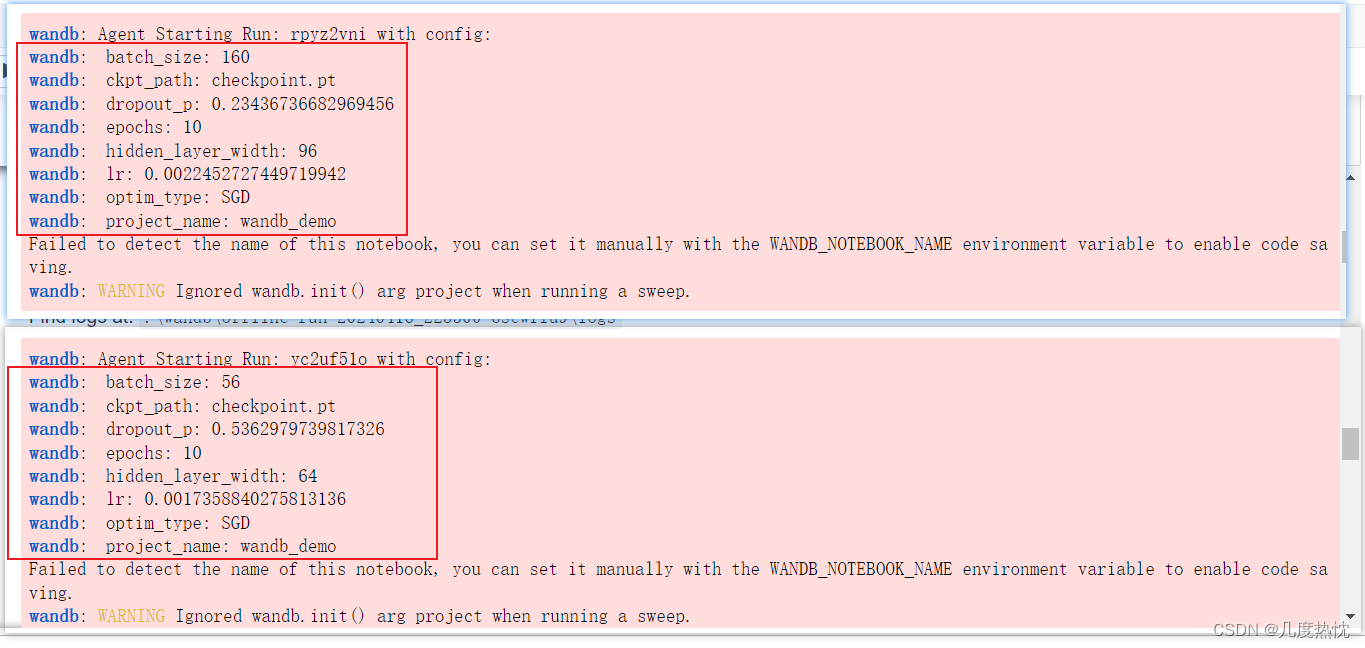
-
wandb.agent(sweep_id, train, count=5) 是 Weights & Biases (Wandb) 提供的一个函数,用于启动一个或多个超参数调优任务(称为 “sweep agents”),这些任务会根据指定的超参数范围(由 sweep_id 指定)来执行训练函数 train 多次。count 参数指定了要运行的实验次数
-
可以在多个 Jupyter notebook 中使用相同的 sweep_id 执行 wandb.agent 来并行化超参数调优任务。这样做可以利用多台机器的计算资源来加速超参数搜索过程,每个 Jupyter notebook都会作为一个独立的 “agent” 运行,它们会向 Wandb 的服务器请求任务并执行相应的超参数调优实验

-
在侧边栏的controls中可对sweeo进行控制,比如暂停,继续,关闭或者杀死controller,若关闭则无法重新启动
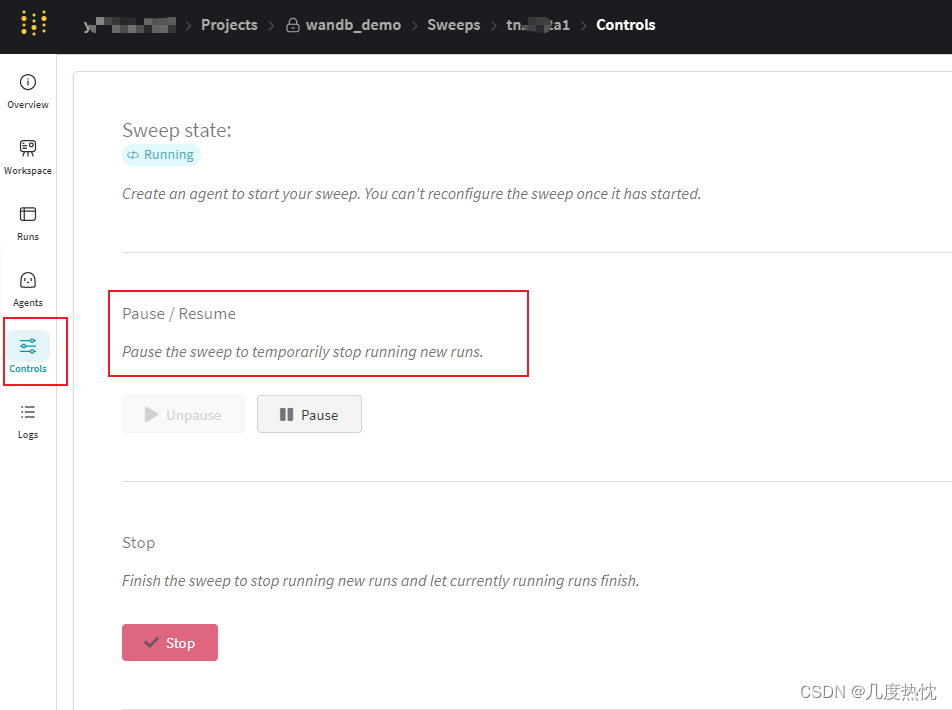
-
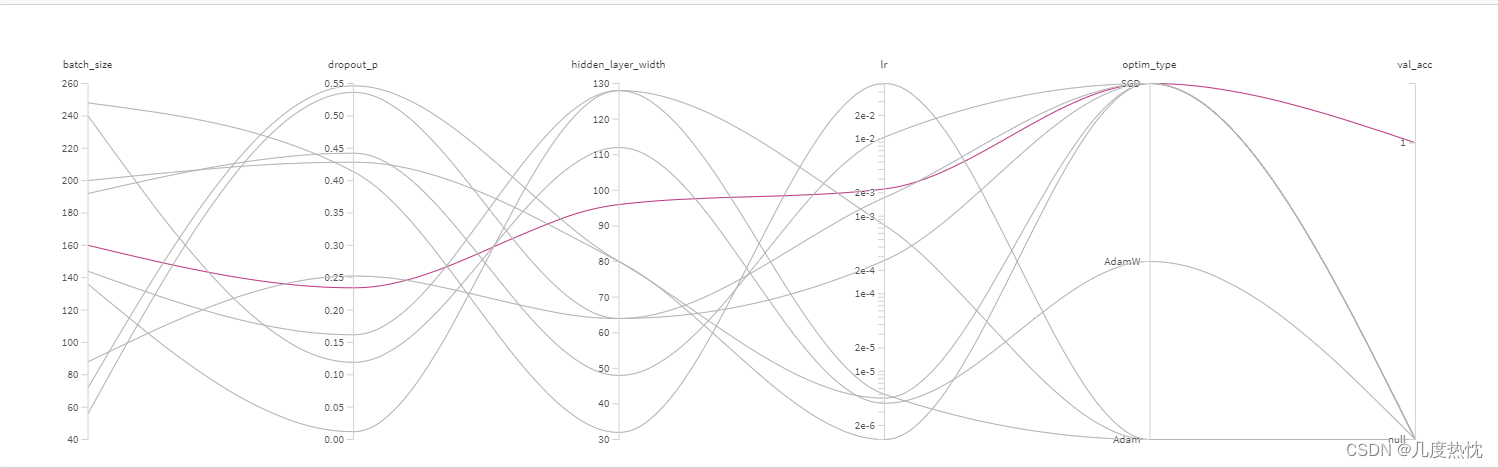
在官网侧边栏的sweep可视化查看调参:
-
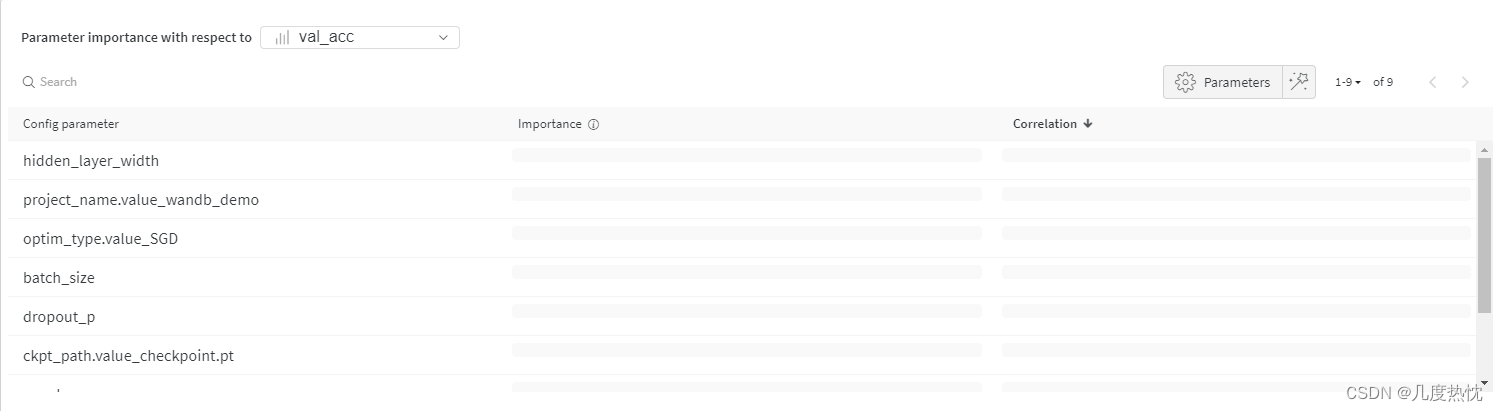
超参数重要性图:

-
但我这里又没显示…
就介绍到这里啦,完结撒花~



![[BT]BUUCTF刷题第19天(4.19)](https://img-blog.csdnimg.cn/direct/7ac7428ed6914ff399b89c699ee81837.png)


![VScode配置launch+tasks[自己备用]](https://img-blog.csdnimg.cn/direct/2c0e0018446c4b9caecd303bdca2980b.jpeg)