原文:https://bernsteinbear.com/blog/python-parallel-output/
代码:https://gist.github.com/tekknolagi/4bee494a6e4483e4d849559ba53d067b
Python 并行输出
使用进程和锁并行输出多个任务的状态。

注:以下代码在linux下可用,windows下可能要进行修改。
假设你有一个程序,它对列表进行一些处理:
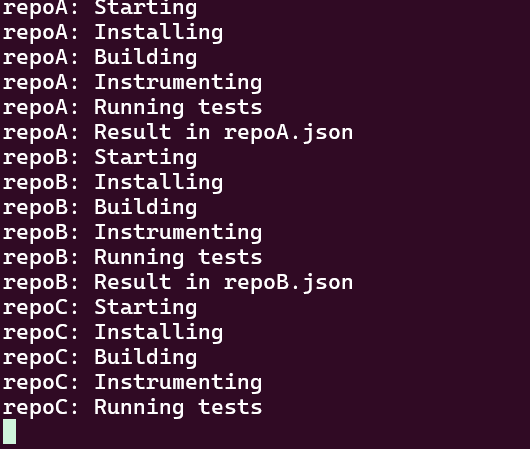
def log(repo_name, *args):
print(f"{repo_name}:", *args)
def randsleep():
import random
import time
time.sleep(random.randint(1, 5))
def func(repo_name):
log(repo_name, "Starting")
randsleep() # Can be substituted for actual work
log(repo_name, "Installing")
randsleep()
log(repo_name, "Building")
randsleep()
log(repo_name, "Instrumenting")
randsleep()
log(repo_name, "Running tests")
randsleep()
log(repo_name, f"Result in {repo_name}.json")
repos = ["repoA", "repoB", "repoC", "repoD"]
for repo in repos:
func(repo)
这很好。它有效。有点吵,但有效。但随后你发现了一件好事:你的程序是数据并行。也就是说,您可以并行处理:
import multiprocessing
# ...
with multiprocessing.Pool() as pool:
pool.map(func, repos, chunksize=1)
不幸的是,输出有点笨拙。虽然每行仍然很好输出一个 repo,但它正在左右喷出行,并且这些行是混合的。
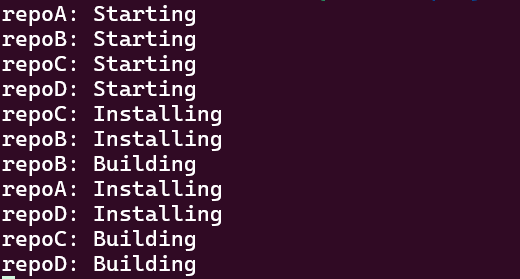
幸运的是,StackOverflow 用户 Leedehai是终端专业用户,知道如何在控制台中一次重写多行。我们可以根据自己的需要调整这个答案:
def fill_output():
to_fill = num_lines - len(last_output_per_process)
for _ in range(to_fill):
print()
def clean_up():
for _ in range(num_lines):
print("\x1b[1A\x1b[2K", end="") # move up cursor and delete whole line
def log(repo_name, *args):
with terminal_lock:
last_output_per_process[repo_name] = " ".join(str(arg) for arg in args)
clean_up()
sorted_lines = last_output_per_process.items()
for repo_name, last_line in sorted_lines:
print(f"{repo_name}: {last_line}")
fill_output()
def func(repo_name):
# ...
with terminal_lock:
del last_output_per_process[repo_name]
# ...
repos = ["repoA", "repoB", "repoC", "repoD"]
num_procs = multiprocessing.cpu_count()
num_lines = min(len(repos), num_procs)
with multiprocessing.Manager() as manager:
last_output_per_process = manager.dict()
terminal_lock = manager.Lock()
fill_output()
with multiprocessing.Pool() as pool:
pool.map(func, repos, chunksize=1)
clean_up()
这会将每个项目的状态(一次一行)打印到终端。它将按项目添加到的 last_output_per_process 顺序打印,但您可以通过(例如)按字母数字排序来更改它: sorted(last_output_per_process.items()) 。
请注意,我们必须锁定数据结构和终端输出,以避免事情被破坏;它们在过程之间共享(pickled,via Manager )。
如果日志输出有多行长,或者其他人正在用 stdout / stderr (也许是流浪的 print )搞砸,我不确定这会做什么。如果您发现或有整洁的解决方案,请写信。
这种技术对于任何具有线程和锁的编程语言来说可能是相当可移植的。关键的区别在于这些实现应该使用线程而不是进程;我做进程是因为它是 Python。
最终版
import multiprocessing
import random
import time
class Logger:
def __init__(self, num_lines, last_output_per_process, terminal_lock):
self.num_lines = num_lines
self.last_output_per_process = last_output_per_process
self.terminal_lock = terminal_lock
def fill_output(self):
to_fill = self.num_lines - len(self.last_output_per_process)
for _ in range(to_fill):
print()
def clean_up(self):
for _ in range(self.num_lines):
print("\x1b[1A\x1b[2K", end="") # move up cursor and delete whole line
def log(self, repo_name, *args):
with self.terminal_lock:
self.last_output_per_process[repo_name] = " ".join(str(arg) for arg in args)
self.clean_up()
sorted_lines = self.last_output_per_process.items()
for repo_name, last_line in sorted_lines:
print(f"{repo_name}: {last_line}")
self.fill_output()
def done(self, repo_name):
with self.terminal_lock:
del self.last_output_per_process[repo_name]
class MultiprocessingLogger(Logger):
def __init__(self, num_lines, manager):
super().__init__(num_lines, manager.dict(), manager.Lock())
class FakeLock:
def __enter__(self):
pass
def __exit__(self, exc_type, exc_value, traceback):
pass
class SingleProcessLogger(Logger):
def __init__(self, num_lines):
super().__init__(num_lines, {}, FakeLock())
def randsleep():
time.sleep(random.randint(1, 2) / random.randint(1, 5))
def func(repo_name):
logger.log(repo_name, "Starting")
randsleep()
logger.log(repo_name, "Installing")
randsleep()
logger.log(repo_name, "Building")
randsleep()
logger.log(repo_name, "Instrumenting")
randsleep()
logger.log(repo_name, "Running tests")
randsleep()
logger.log(repo_name, f"Result in {repo_name}.json")
randsleep()
logger.done(repo_name)
def multi_process_demo():
ascii_uppercase = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
repos = [f"repo{letter}" for letter in ascii_uppercase]
num_procs = multiprocessing.cpu_count()
num_lines = min(len(repos), num_procs)
with multiprocessing.Manager() as manager:
global logger
logger = MultiprocessingLogger(num_lines, manager)
# Make space for our output
logger.fill_output()
with multiprocessing.Pool(num_procs) as pool:
pool.map(func, repos, chunksize=1)
logger.clean_up()
def single_process_demo():
repo = "repoA"
num_lines = 1
global logger
logger = SingleProcessLogger(num_lines)
logger.fill_output()
func(repo)
logger.clean_up()
if __name__ == "__main__":
multi_process_demo()
# single_process_demo()

![VScode配置launch+tasks[自己备用]](https://img-blog.csdnimg.cn/direct/2c0e0018446c4b9caecd303bdca2980b.jpeg)