大语言模型隐私防泄漏:差分隐私、参数高效化
- 写在最前面
- 题目6:大语言模型隐私防泄漏
- Differentially Private Fine-tuning of Language Models
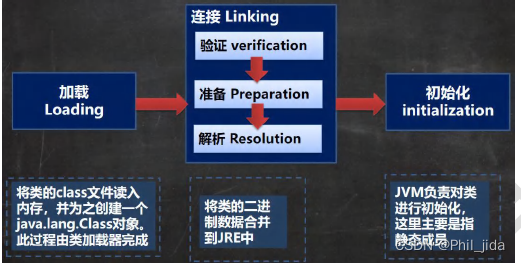
- 其他
- 初步和之前的基线
- 微调模型1
- 微调模型2
- 通过低秩自适应进行微调( 实例化元框架1)
- 在隐私数据集小的情况下,为什么参数高效化有效
- 实例化元框架
- 通过适配器进行微调
- 通过Compacter进行微调
- 论文模型对比基线模型

写在最前面
草稿箱翻到了,去年九月的比赛笔记
十分感谢学长学姐带我参加比赛,一次有趣的经历。
虽然最后由于时间原因没有获奖,但是学习了相关知识。
希望能通过这次比赛,学习一些网安相关的技术
比赛链接:https://cpipc.acge.org.cn//cw/detail/2c90800c8093eef401809d33b36f0652/2c90801787f062ab018871a92ff078ba
选题:六
主要涉及:差分隐私
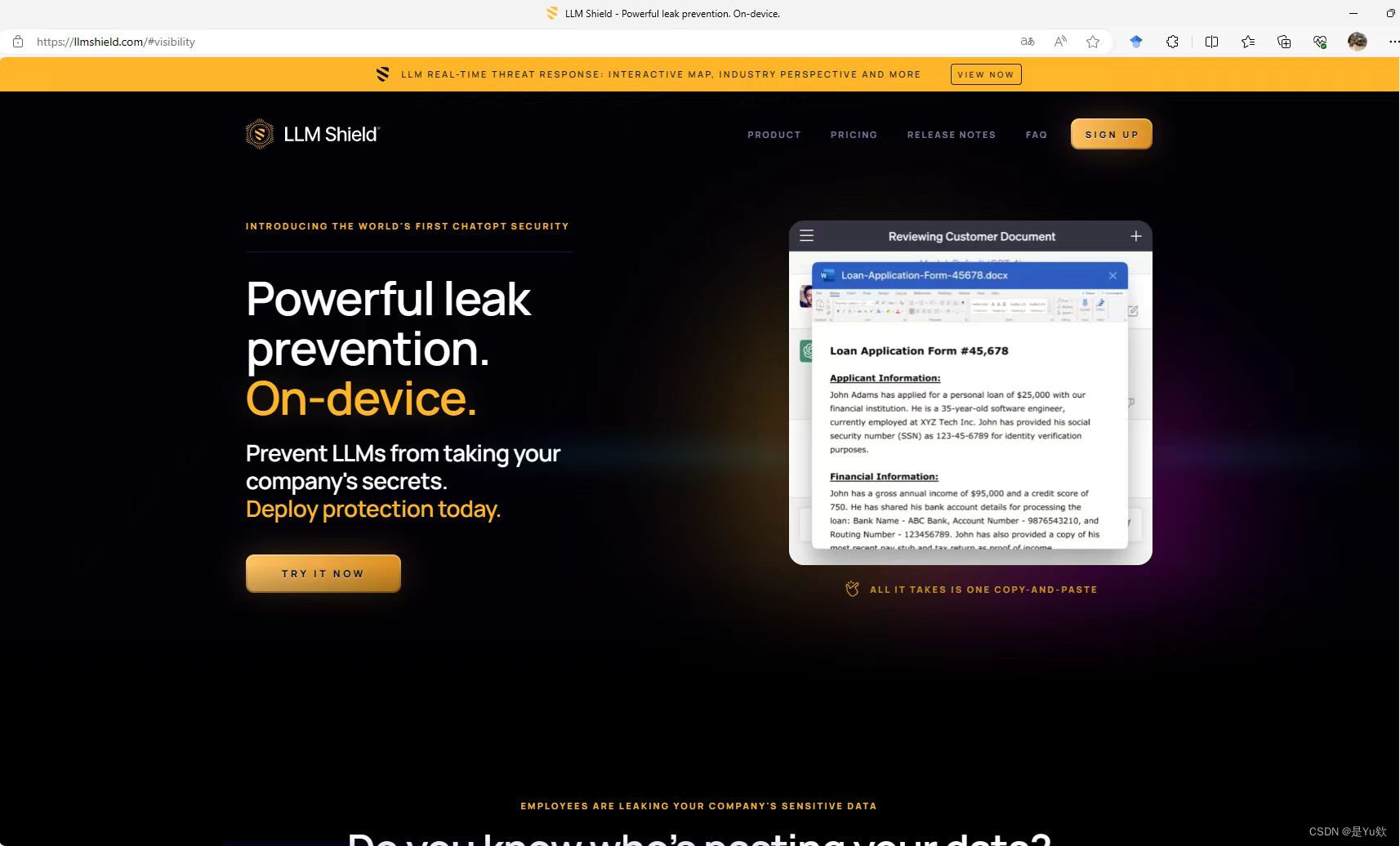
夺冠作品:白泽智能团队的LLM Shield则根据大语言模型的生命周期以及数据传输过程中各个环节的特点,针对性的设计和优化了相应的隐私防泄漏解决方案。作品LLM Shield在大模型隐私安全赛道上荣获一等奖
https://llmshield.com/#visibility
题目6:大语言模型隐私防泄漏
一、题目背景:
ChatGPT的火爆让AIGC走进大众的视野,成为历史上增长最快的消费应用。随着活跃用户的快速增长,ChatGPT也在持续收集用户的真实反馈数据用于提升大模型生成能力。由于大语言模型可能记忆训练数据中的敏感信息,存在泄露用户隐私的风险,如何防止大语言模型泄露隐私的诉求越来越迫切。
二、题目描述:
给定一个预训练大语言模型(如GPT-2)和微调数据集(包含公开的或合成的虚拟个人身份信息),基于开源深度学习框架MindSpore设计并实现一种高可用的大语言模型隐私防泄漏方案,在保证模型可用性和训练性能的前提下,防止敌手从微调后的模型中恢复个人身份信息(包括姓名、邮箱、电话号码、居住/工作住址)。微调后的模型通过黑盒API部署,敌手仅能获取下一个token的预测向量,而无法获取模型参数和中间特征。比赛提供基于MindSpore实现的预训练模型和微调数据集。
三、评价方式:
1)模型可用性:评估模型防泄漏技术对模型可用性的影响,使用困惑度(perplexity)指标衡量
2)训练性能:评估模型防泄漏技术对训练性能的影响,使用训练所需的内存开销和训练时长指标衡量,推理时长增加小于20%。
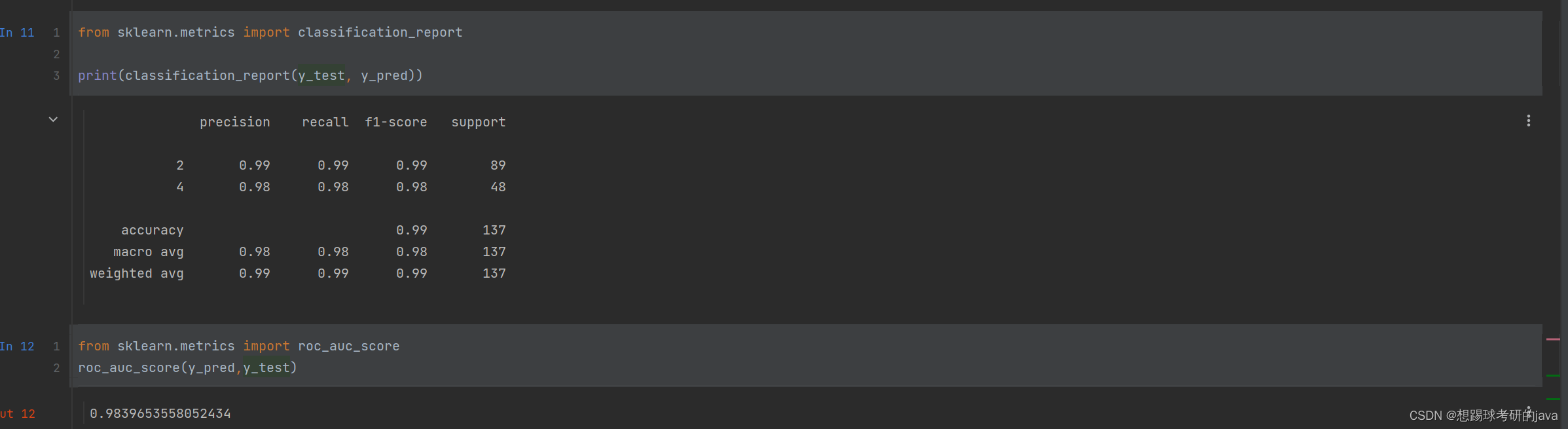
3)安全性:评估模型防泄露技术的保护效果,对比模型保护前后隐私攻击的成功率,其中成员推理攻击通过ROC AUC衡量,隐私数据提取攻击通过Recall和Precision指标衡量
四、参考信息:
1)开源深度学习框架MindSpore, https://www.mindspore.cn/
2)安全与隐私保护工具开源MindSpore Armour,https://www.mindspore.cn/mindarmour/docs/zh-CN/r2.0/index.html
3)Extracting Training Data from Large Language Models,https://arxiv.org/abs/2012.07805
4)Analyzing Leakage of Personally Identifiable Information in Language Models,https://arxiv.org/abs/2302.00539
5)预训练模型:GPT2-small,https://gitee.com/mindspore/mindformers/blob/r0.3/docs/model_cards/gpt2.md
6)部署环境:在启智社区(https://openi.org.cn)申请计算资源, 可选硬件Ascend/GPU:https://openi.pcl.ac.cn/docs/index.html#/
五、交付件:
1)源代码
2)可执行文件和部署测试方法
3)设计和测试文档
六、答疑邮箱:yangyuan24@huawei.com
题目六附件链接如下:
https://cpipc.acge.org.cn/sysFile/downFile.do?fileId=261dcd40f2e54398924deb2c363fdf4c
下面是这次比赛的一些备赛记录~
希望能给自己之后的学习带来一些灵感
Differentially Private Fine-tuning of Language Models
https://arxiv.org/pdf/2110.06500.pdf
论文前面都是介绍他们的模型多么的好,主要好在轻量、准确率降低的不多
和比赛相关的,主要就这一节

但是呢,重点是:

微调数据集:DART
代码:https://github.com/huseyinatahaninan/Differentially-Private-Fine-tuning-of-Language-Models/tree/main/Language-Generation-GPT-2
其他
研究贡献
-
在MNLI数据集上私下微调RoBERTa-Large,隐私预算为 (ε = 6.7, δ = 1e-6)。实现了87.8%的准确率,隐私预算为(ε=6.7,δ=1e-6)。在没有隐私保证的情况下,RoBERTa-Large的准确率为90.2%(已知GPT-3的准确率为91.7%(Hu等人,2021));
私人自然语言生成任务,在E2E数据集上微调GPT-2模型(Novikova等人,2017)。同样,该实用程序接近非私有水平:在GPT-2-Large和(ε=6.0,δ=1e-5)的情况下实现了ROUGE-L得分67.8,而在没有隐私的情况下为72.0。 -
大模型可能具有更高的容量,但需要引入更多的噪声。
-
更简单,更稀疏、更快。DP需求还会导致计算和内存使用方面的大量开销,在隐私下情况会将训练时间增加多达两个数量级(Carlinietal.,2019;Subramanietal.,2021)。
我们采用的参数高效方法部分抵消了这个问题:由于我们只更新参数总数的一小部分,训练变得相当高的计算和内存效率。
此外,与在非隐私环境中一样,该框架导致了模块化设计,其中单个大型预训练模型可以通过对每个单独的下游任务的轻量级修改来增强。

初步和之前的基线


微调模型1


微调模型2

通过低秩自适应进行微调( 实例化元框架1)


在隐私数据集小的情况下,为什么参数高效化有效

除了在精度上有实质性的提升,其他优点:
- 单一pre-trained模型如BERT或GPT通常应用于数百下游任务通过微调。使用以前的方法进行私有微调需要更新所有参数,并为每个任务存储微调模型的不同副本。这就产生了相当大的存储开销和部署,可以在实践中是非常昂贵的。
另一方面,重新参数化(1)意味着我们只需要存储一个可以跨许多下游任务共享的单一预训练模型。每个下游任务只需要少量可以插入的新参数。
- 差分私有训练需要计算和存储每个示例的梯度,这增加了内存占用。然而,在我们的方法中,学习是在一个低得多的维度中完成的,因此与之前的工作相比,节省了内存成本。
- 最后,我们预计(1)还提供了一种在分布式设置(如联邦学习)中通信效率更高的微调方法,因为在微调过程中学习的参数数量明显更少。

实例化元框架
通过适配器进行微调

通过Compacter进行微调

论文模型对比基线模型

欢迎大家添加好友,持续发放粉丝福利!