1.1 图形建模指南
图形数据建模是用户将任意域描述为节点的连接图以及与属性和标签关系的过程。Neo4j 图数据模型旨在以 Cypher 查询的形式回答问题,并通过组织图数据库的数据结构来解决业务和技术问题。
1.1.1 图形数据模型介绍
图形数据模型通常被称为对白板友好的模型。通常,在设计数据模型时,人们在白板上绘制示例数据,并将其连接到绘制的其他数据,以显示不同项目如何连接。然后,对白板模型进行重新格式化和结构化,以适合关系模型的规范化表。
图数据建模中也存在类似的过程。但是,图形数据模型不会修改数据模型以适应规范化的表结构,而是完全保持在白板上绘制的状态。这就是图形数据模型因对白板友好而得名的地方。
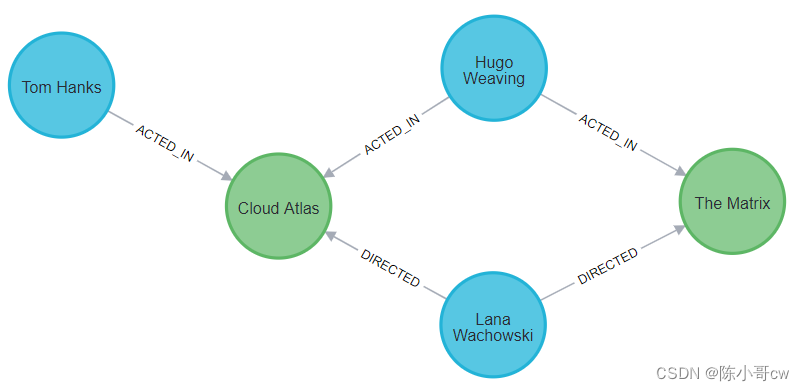
让我们看一个例子来证明这一点。在下面的白板图中,我们有一个关于电影《黑客帝国》的数据集。
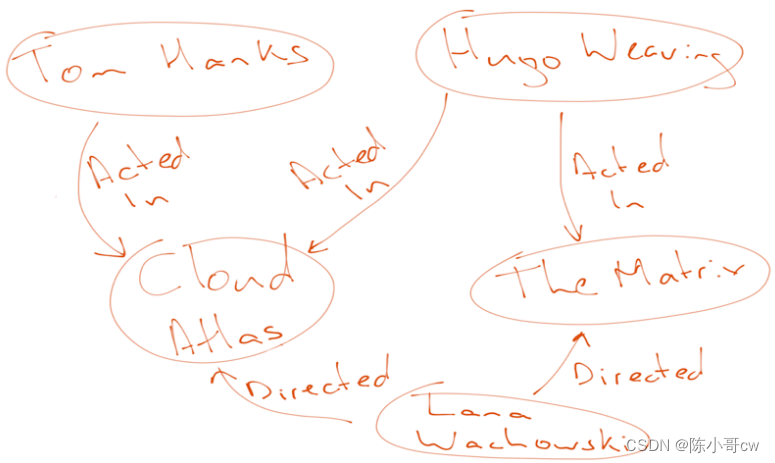
接下来,我们对实体进行一些形式化,并匹配关系类型的预期语法,以创建属性图模型的节点/关系视图。
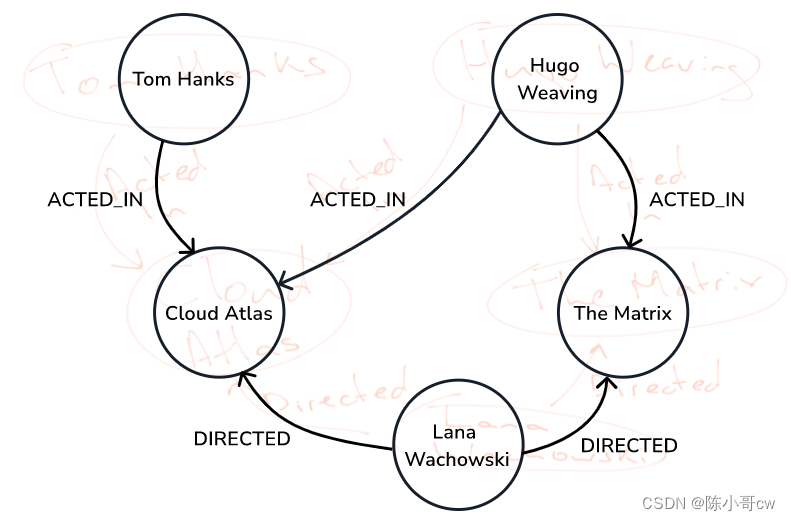
下一步,我们将添加标签并确定节点的属性以及属性图模型的关系。
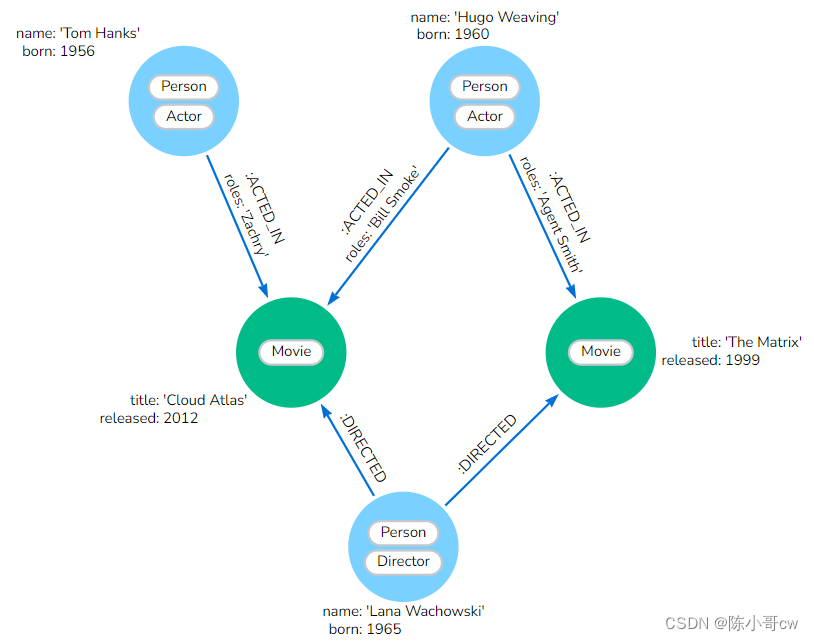
最后,您可以在 Neo4j 浏览器中查看此数据模型,并确保它与白板上绘制的内容相匹配。另外,请注意它与我们最初设计的白板模型几乎相同。
为了更好地理解设计图数据模型的过程,以一小组数据为例,并逐步了解如何从中创建图数据模型的每个步骤。请考虑以下描述示例数据实体和连接的方案。
两个人,Sally 和John,是朋友。John 和 Sally 都读过《图形数据库》一书。
我们可以使用此语句中的信息通过将组件标识为标签、节点和关系来构建我们的模型。让我们将场景分成几部分,并将它们定义为属性图模型的一部分。但是,首先,我们简化了模型。
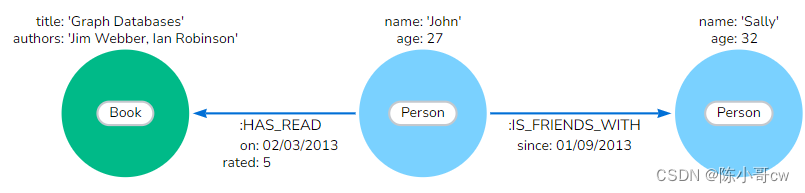
可以看到:
- Nodes (circles) : 表示对象。
- 节点可以具有属性(名称/值对)。
- 关系(箭头)连接节点并表示操作。
- 关系是定向的,可以具有属性(名称/值对)。
1.1.2 节点Nodes
在域中标识的第一个实体是节点。节点是构成图形的两个基本单元之一(另一个基本单元是关系 )。
可以通过识别域中的名词来查找图模型的节点。汽车、个人、客户、公司、资产和其他类似实体可以定义为良好起点的节点。
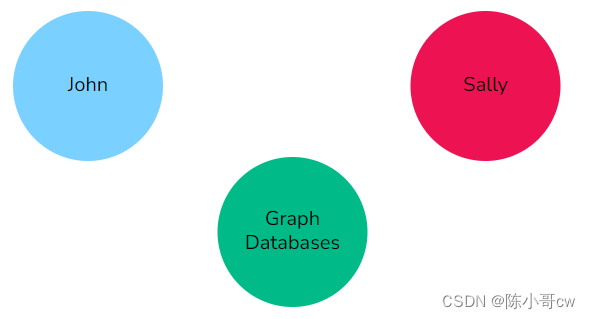
可以将节点识别为具有唯一概念标识的实体。在我们的场景中,我们从 Sally 和 John 开始,这些实体在下面以粗体列出。
两个人,Sally 和John,是朋友。John 和 Sally 都读过**《Graph Databases》**一书。
可以提取出以下节点
- John
- Sally
- Graph Databases
请记住,图形数据库将实体的每个实例视为一个单独的节点(John 和 Sally 将是两个独立的节点,即使他们都是人),而图形数据库将是与另一本书不同的节点。
1.1.3 标签Labels
现在,当我们了解我们的节点是什么时,我们可以决定将哪些标签(如果有的话)分配给我们的节点来对它们进行分组或分类。让我们提醒一下标签的作用以及它们在图数据模型中的使用方式的定义。
标签是一种命名的图形构造,用于将节点分组为集合。所有标有相同标签的节点都属于同一集合。
许多数据库查询可以使用这些集合而不是整个图形,从而使查询更易于编写和更高效。一个节点可以用任意数量的标签进行标记,包括无标签,使标签成为图形的可选补充。
类似于我们通过识别场景中的名词来查找图模型的节点,您可以通过通用名词或人员、地点或事物组来识别标签。适合项目组(如车辆、人员、客户、公司、资产)和类似术语的通用名词可以用作图表中的标签。
为了确定我们是否可以在 Sally 和 John 场景中对对象进行分组,我们首先确定语句中提到的节点(John、Sally、图形数据库)的角色。我们可以在语句中找到两种不同类型的对象,下面将重点介绍它们。
两个人,Sally 和John,是朋友。John 和 Sally 都读过**《Graph Databases》**一书。
可以提取出以下标签
- Person
- Book
现在我们已经确定了节点和标签,我们可以更新我们的图形数据模型,将标签分配给它们所描述的节点。对于 John 和 Sally,我们应用了 Person 标签。对于图形数据库,我们应用标签 Book。
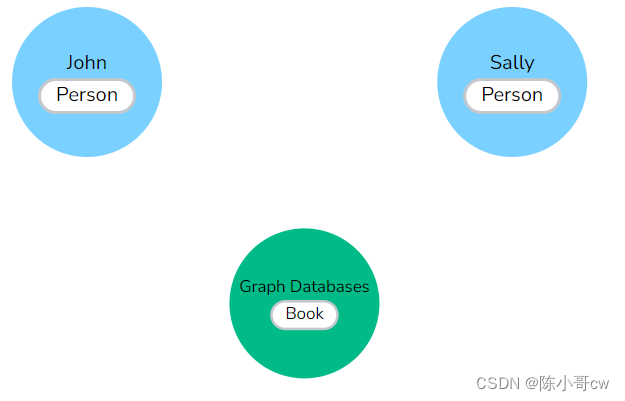
1.1.4 关系Relationships
我们现在有了我们的主要实体和一种对它们进行分组的方法,但我们仍然缺少图数据库模型的一个重要部分——数据之间的关系!
关系连接两个节点,并允许我们查找相关的数据节点。它有一个源节点和一个显示箭头方向的目标节点。虽然您必须在特定方向上存储关系,但 Neo4j 在任一方向上都具有相同的遍历性能,因此您可以在不指定方向的情况下查询关系。
图形数据库中一个核心的一致规则是“没有断开的链接”,确保现有关系永远不会指向不存在的端点。由于关系始终具有起始节点和结束节点,因此在不删除其关联关系的情况下,无法删除节点。
正如我们通过查找名词来找到节点和标签一样,您通常可以通过识别域中的动作或动词来找到图模型的关系。DRIVES、HAS_READ、MANAGES、ACTED_IN 等操作可以定义为节点之间存在的不同类型的关系。
让我们确定 John、Sally 和 Graph Database 节点之间的交互(在下面的方案中下划线)。
两个人,Sally 和John,是朋友。John 和 Sally 都读过《Graph Databases》一书。
节点之间的关系:
- John是Sally的朋友
- Sally是John的朋友
- John读过Graph Databases
- Sally读过Graph Databases
总结一下我们的发现,我们的 John 和 Sally 节点(标记为 Person)可以通过 is friends关系相互连接。John 和 Sally 都读过 Graph Databases 一书,因此我们可以将他们的每个节点(每个标记为 Person)连接到具有 has read 关系的 Graph Databases 节点(标记为 Book)。
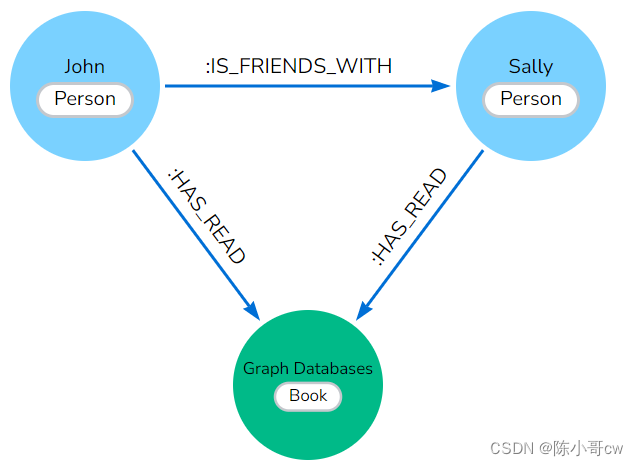
1.1.5 属性Properties
属性是可以存储在节点或关系上的名称/值数据对。大多数标准数据类型都支持作为属性,您可以在图形数据库概念部分找到有关此类型的信息。
属性允许您存储有关节点或与其描述的实体的关系的相关数据。通常可以通过了解您的用例需要对数据提出什么样的问题来找到它们。
对于 John 和 Sally 的场景,我们可以列出一些我们可能想要回答的有关数据的问题。
关于我们的 John 和 Sally 数据模型的问题:
- 约翰和莎莉什么时候成为朋友的?或者他们做朋友多久了?
- 谁是《Graph Databases》一书的作者?
- Graph Databases 这本书的平均评分是多少?
- 约翰和莎莉几岁了?
- 谁年长,莎莉还是约翰?
- 谁先读了《Graph Databases》这本书,Sally 还是 John?
从此问题列表中,您可以确定我们需要存储在数据模型中实体上的属性,以便回答这些问题。
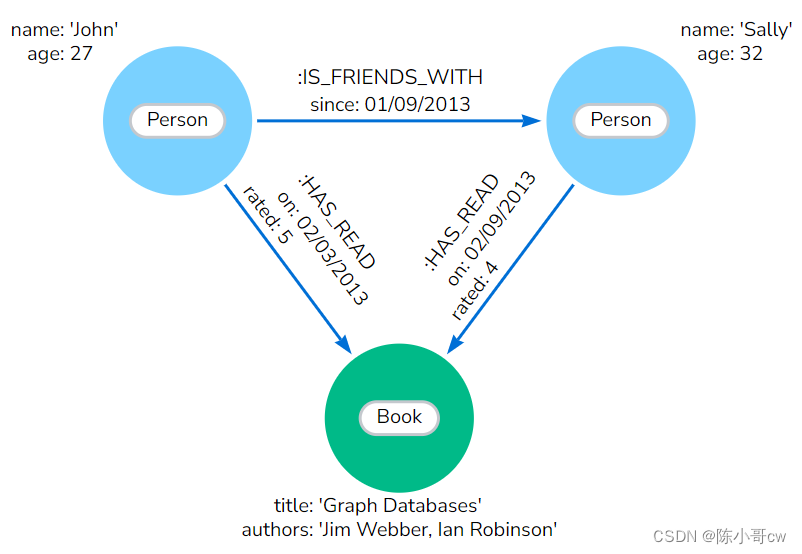
1.1.6 实现模型
可以使用 Cypher 语句创建图形。有很多方法可以将数据加载到图形中。在这里,我们使用 MERGE 子句来创建数据模型。
运行以下代码,为此数据模型创建图形:
MERGE (j:Person {name: 'John'})
ON CREATE set j.age = 27
MERGE (s:Person {name: 'Sally'})
ON CREATE set s.age = 32
MERGE (b:Book {title: 'Graph Databases'})
ON CREATE set b.authors = ['Jim Webber', 'Ian Robinson']
MERGE (j)-[rel1:IS_FRIENDS_WITH]->(s)
ON CREATE SET rel1.since = '01/09/2013'
MERGE (j)-[rel2:HAS_READ]->(b)
ON CREATE SET rel2.on = '02/03/2013', rel2.rated = 5
MERGE (s)-[rel3:HAS_READ]->(b)
ON CREATE SET rel3.on = '02/09/2013', rel3.rated = 4
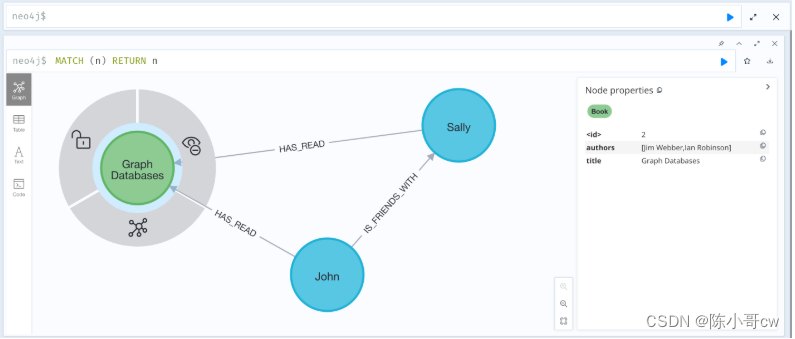
创建图形后,可以使用以下 Cypher 语句查看它:
MATCH (n) RETURN n
在 Neo4j 浏览器中,您可以将鼠标悬停在图中的每个节点和关系上以查看其属性。
1.2 建模:关系数据到图数据
1.2.1 介绍
关系数据库依赖于索引查找和表join来连接不同的实体。这很快就会成为性能问题,尤其是当连接了多个表、表上有数百万行或通过子查询遍历各个级别的复杂查询时。
在示例中,要查找 Alice 为哪些部门工作,您需要查询 Person 表以查找表示 Alice 的行,该行绑定到作为主键的唯一 ID。然后,您的查询将转到关联实体表 ( Person_Dept ),以查找其 ID 与一个或多个部门 ID 绑定的位置。最后,查询将检查 Department 表,以查找在关联实体表中找到的那些部门 ID 的实际值。
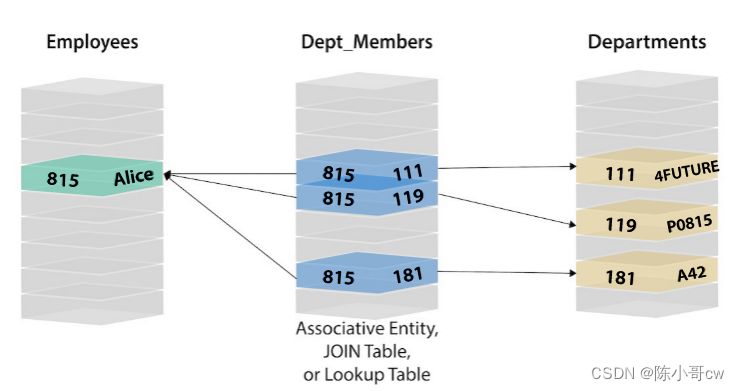
在图形中,您无需担心表连接和索引查找,因为图形数据是由每个单个实体及其与其他单个实体的关系构成的。
1.2.2 数据模型转换技巧
让我们看一下关系数据模型中的一些关键组件,并将它们转换为图数据模型的组件。下面列出了帮助您转换关系图的步骤。
- 表到节点标签: 关系模型中的每个实体表都成为图形模型中节点上的标签。
- 行到节点: 关系实体表中的每一行都将成为图形中的一个节点
- 列到节点属性:关系表上的列(字段)成为图形中的节点属性。
- 仅限业务主键:删除技术主键,保留业务主键。
- 添加约束/索引:为业务主键添加唯一约束,为频繁查找的属性添加索引。
- 外键到关系:将另一个表的外键替换为关系,然后删除它们。
- 无默认值:删除具有默认值的数据,无需存储这些值。
- 清理数据:可能需要将非规范化表中的重复数据拉出到单独的节点中,以获得更清晰的模型。
- 列索引到数组 :索引列名称(如 email1、email2、email3)可能指示数组属性。
- 关联表到关系:关联表转换为关系,这些表上的列将成为关系属性
如果您将上面列表中的项目应用于我们查找 Alice 部门的示例,我们可以得出如下所示的图表。
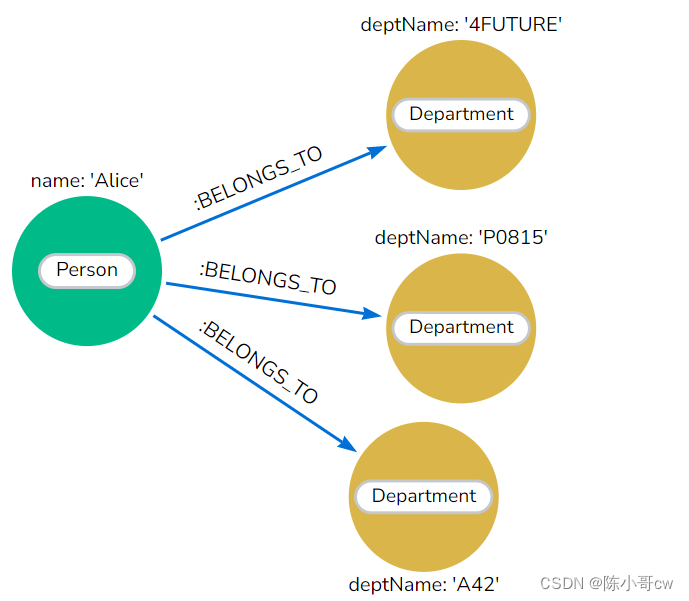
尽管这两个模型具有相似之处,例如使用表结构或标签对数据进行分类,但图形模型不会将数据限制在预定义的严格表/列布局中。我们将在下一节中查看另一个示例。
为了给我们另一个练习的机会,我们将使用一个标准的组织域,并展示如何在关系数据库和图形数据库中对其进行建模。为了给自己一个额外的挑战,请尝试自己创建图形数据模型,然后看看它有多紧密。
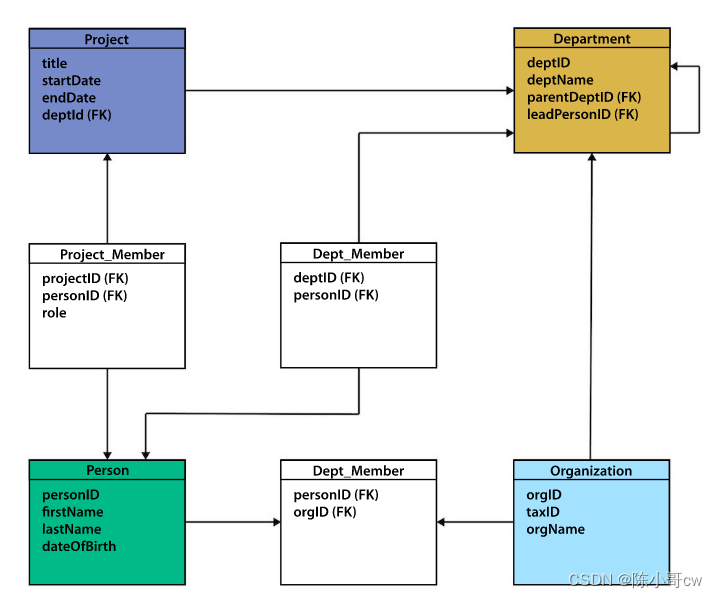
首先,我们可以按主域表对表进行分类,按颜色对关联实体表进行分类。然后,我们可以将表名转换为节点标签。在本例中, Project 、Person、 Department 和 Organization 成为图模型中的标签。
表上的行成为它们自己的节点,这些行中的列成为这些节点上的属性。例如, Person 表上的行将成为一个节点,姓名和出生日期作为节点上的属性。任何允许多个相似值的索引列都将成为数组(例如 skill1、skill2、skill3 列转换为存储在节点上的数组属性中的三个值)。
如果存在任何技术主键(换言之,创建主键只是为了使行唯一,例如project_id,以防有多个具有相同标题的项目),则删除这些主键,仅保留业务需求所需的属性。您还需要为业务主键添加唯一的约束,以确保数据库不允许重复。
有助于关系联接查找的外键被转换为关系,因为它们显示了节点之间的链接。关联实体表也将成为关系,关联实体表的列都转换为关系的属性。
由于您在 Neo4j 中存储所需的属性,因此不需要存储 null 值和空值,因此可以删除可能在关系模型中创建的任何默认值。
最后,为了简单起见,为规范化表或反规范化而创建的任何重复数据都需要删除,因为在图形中不需要这些数据。
完成此过程后,图形数据模型应如下图所示。
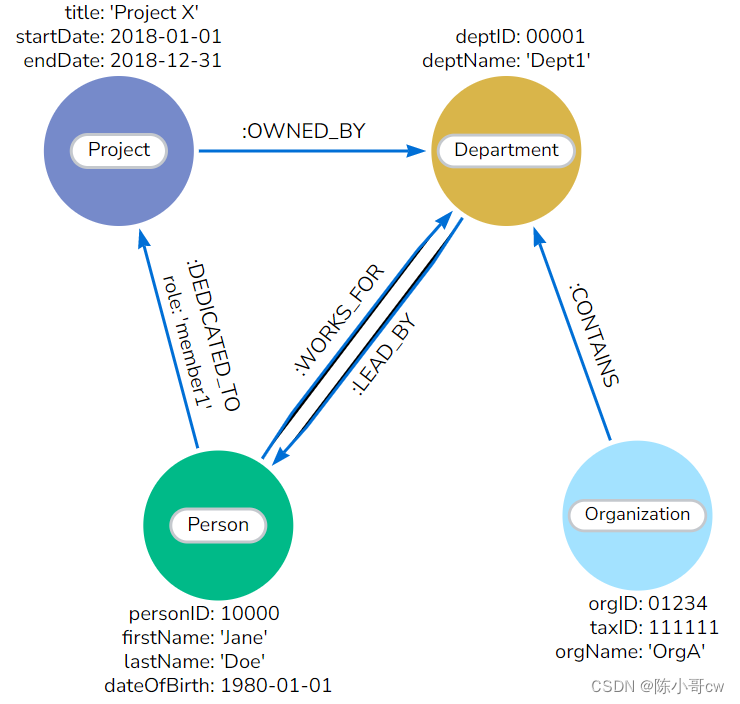
1.2.3 图模型重构
1.2.3.1 初始模型
本指南使用包含 2008 年 1 月美国机场之间连接的机场数据集。数据以 CSV 文件的形式显示。下面你可以看到数据库的图模型:
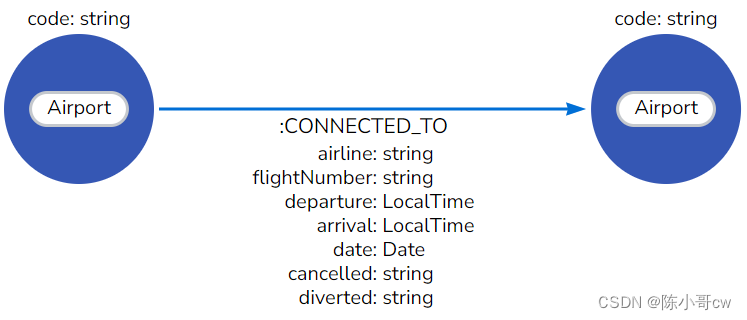
在导入任何数据之前,应在 Airport 标签和 code 属性上创建唯一约束,以确保不会意外导入重复的机场。以下查询创建约束:
CREATE CONSTRAINT airport_id
FOR (airport:Airport) REQUIRE airport.code IS UNIQUE
以下查询使用该 LOAD CSV 工具从 CSV 文件加载数据:
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/neo4j-contrib/training/master/modeling/data/flights_1k.csv" AS row
MERGE (origin:Airport {code: row.Origin})
MERGE (destination:Airport {code: row.Dest})
MERGE (origin)-[connection:CONNECTED_TO {
airline: row.UniqueCarrier,
flightNumber: row.FlightNum,
date: date({year: toInteger(row.Year), month: toInteger(row.Month), day: toInteger(row.DayofMonth)}),
cancelled: row.Cancelled,
diverted: row.Diverted}]->(destination)
ON CREATE SET connection.departure = localtime(apoc.text.lpad(row.CRSDepTime, 4, "0")),
connection.arrival = localtime(apoc.text.lpad(row.CRSArrTime, 4, "0"))
上述查询:
- 创建一个带有
Airport标签的节点,该code标签的属性具有 CSV 文件中列Origin中的值。 - 创建一个带有
Airport标签的节点,该code标签的属性具有 CSV 文件中列Dest中的值。 - 根据 CSV 文件中的列创建具有多个属性的类型
CONNECTED_TO关系。
这是一个起始模型,但您可以进行一些改进。
1.2.3.2 将属性转换为布尔值
CONNECTED_TO 关系的 diverted and cancelled 属性包含 和 0 的 1 字符串值。由于这些值表示布尔值,因此可以使用该 apoc.refactor.normalizeAsBoolean 程序将值从字符串转换为布尔值。
以下查询对 diverted 属性进行转换:
MATCH (:Airport)-[connectedTo:CONNECTED_TO]->(:Airport)
CALL apoc.refactor.normalizeAsBoolean(connectedTo, "diverted", ["1"], ["0"])
RETURN count(*)
apoc.refactor.normalizeAsBoolean(entity ANY, propertyKey STRING, trueValues LIST<ANY>, falseValues LIST<ANY>)将给定属性重构为BOOLEAN

以下查询执行 cancelled 属性的转换:
MATCH (origin:Airport)-[connectedTo:CONNECTED_TO]->(departure)
CALL apoc.refactor.normalizeAsBoolean(connectedTo, "cancelled", ["1"], ["0"])
RETURN count(*)
如果要更新大量关系,则在尝试在一个事务中重构所有关系时可能会遇到 OutOfMemory 异常。因此,您可以使用该 apoc.periodic.iterate 过程批量处理关系。以下查询对同一查询中的 cancelled and reverted 属性执行此操作:
UNWIND ["cancelled", "reverted"] AS propertyToDelete
CALL apoc.periodic.iterate(
"MATCH (:Airport)-[connectedTo:CONNECTED_TO]->(:Airport) RETURN connectedTo",
"CALL apoc.refactor.normalizeAsBoolean(connectedTo, $propertyToDelete, ['1'], ['0'])
RETURN count(*)",
{params: {propertyToDelete: propertyToDelete}, batchSize: 100})
YIELD batches
RETURN propertyToDelete, batches
apoc.periodic.iterate(cypherIterate STRING, cypherAction STRING, config MAP):为第一条语句返回的每个项目运行第二条语句。此过程返回批数和已处理行总数。
完成此操作后,可以编写以下查询以返回所有已取消的连接:
MATCH (origin:Airport)-[connectedTo:CONNECTED_TO]->(destination)
WHERE connectedTo.cancelled
RETURN origin.code AS origin,
destination.code AS destination,
connectedTo.date AS date,
connectedTo.departure AS departure,
connectedTo.arrival AS arrival
1.2.3.3 从关系创建节点
使用现有数据模型,编写查找特定航班的查询可能会成为一项复杂的任务。那是因为这里的航班表示为关系。但是,您可以通过从 CONNECTED_TO 存储在关系上的属性创建 Flight 节点来更改模型:
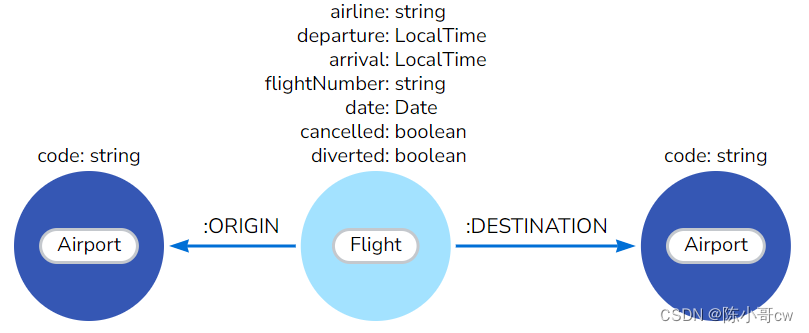
以下查询执行此重构:
CALL apoc.periodic.iterate(
"MATCH (origin:Airport)-[connected:CONNECTED_TO]->(destination:Airport) RETURN origin, connected, destination",
"CREATE (flight:Flight {
date: connected.date,
airline: connected.airline,
number: connected.flightNumber,
departure: connected.departure,
arrival: connected.arrival,
cancelled: connected.cancelled,
diverted: connected.diverted
})
MERGE (origin)<-[:ORIGIN]-(flight)
MERGE (flight)-[:DESTINATION]->(destination)
DELETE connected",
{batchSize: 100})
此查询使用 apoc.periodic.iterate 程序,以便批量执行重构,而不是在单个事务中执行重构。该过程采用三个参数:
- 一个外部 Cypher 查询,用于查找并返回关系流
CONNECTED_TO,以及需要处理的始发地和目的地机场。 - 处理这些实体的内部 Cypher 查询,创建带有标签
Flight的节点,并创建从该节点到始发地和目的地机场的关系。 batchSize配置,设置为100在单个事务中运行的内部语句数。
您也可以使用该 apoc.refactor.extractNode 过程执行此重构。
CALL apoc.periodic.iterate(
"MATCH (origin:Airport)-[connected:CONNECTED_TO]->(destination:Airport)
RETURN origin, connected, destination",
"CALL apoc.refactor.extractNode([connected], ['Flight'], 'DESTINATION', 'ORIGIN')
YIELD input, output, error
RETURN input, output, error",
{batchSize: 100});
apoc.refactor.extractNode(rels ANY, labels LIST, outType STRING, inType STRING):将给定RELATIONSHIP的 VALUES 扩展为中间NODE值。中间NODE值由给定outType的 和inType连接。
这与上一个查询相同,但外部 Cypher 查询使用该 apoc.refactor.extractNode 过程创建 Flight 节点并创建与始发地和目的地机场的关系。如果我们运行此查询,我们将看到以下输出:
1.2.3.4 从属性创建节点
目前,航空公司名称存储在 Flight 节点上的 airline 属性中。这意味着,如果您想返回所有航空公司的流,您必须扫描每个航班并检查每个航班上的 airline 属性。
您可以通过为每个航空公司创建一个带有 Airline 标签的节点来使此任务更简单、更高效:
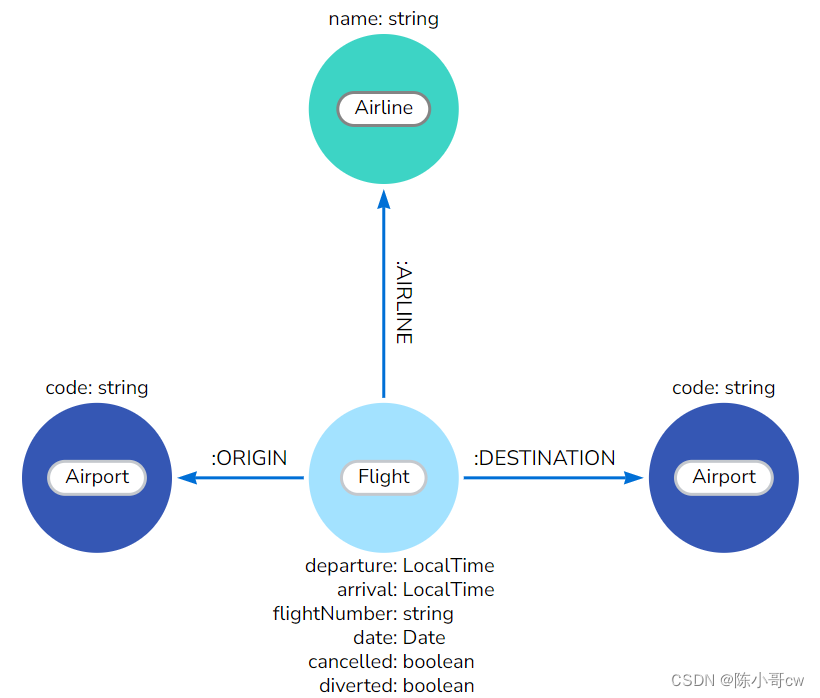
首先,在 Airline 标签和 name 属性上创建约束,以避免重复的航空公司节点:
CREATE CONSTRAINT airline_id
FOR (airline:Airline) REQUIRE airline.name IS UNIQUE
现在,可以运行以下查询来执行重构:
CALL apoc.periodic.iterate(
'MATCH (flight:Flight) RETURN flight',
'MERGE (airline:Airline {name:flight.airline})
MERGE (flight)-[:AIRLINE]->(airline)
REMOVE flight.airline',
{batchSize:10000, iterateList:true, parallel:false}
)
上述查询同样使用具有以下参数的程序 apoc.periodic.iterate :
- 一个外部 Cypher 语句,返回要处理的
Flight节点流。 - 一个内部 Cypher 语句,用于处理
Flight节点并基于airline属性创建Airline节点。它还创建从Flight节点到Airline节点AIRLINE的关系。然后从Flight节点中删除该airline属性。
然后,您可以编写以下查询来查找涉及每个航空公司的航空公司和航班数:
MATCH (airline:Airline)<-[:AIRLINE]-(:Flight)
RETURN airline.name AS airline, count(*) AS numberOfFlights






![[阅读笔记15][Orca]Progressive Learning from Complex Explanation Traces of GPT-4](https://img-blog.csdnimg.cn/direct/c78e94ba2acf40b1ba5908fab310f097.png)