我们知道链表其实有很多种,什么带头,什么双向啊,我们今天来介绍双向带头循环链表,了解了这个其他种类的链表就很简单了。冲冲冲!!!

链表的简单分类
链表有很多种,什么带头循环链表,我们先看这一个图就十分了解了。
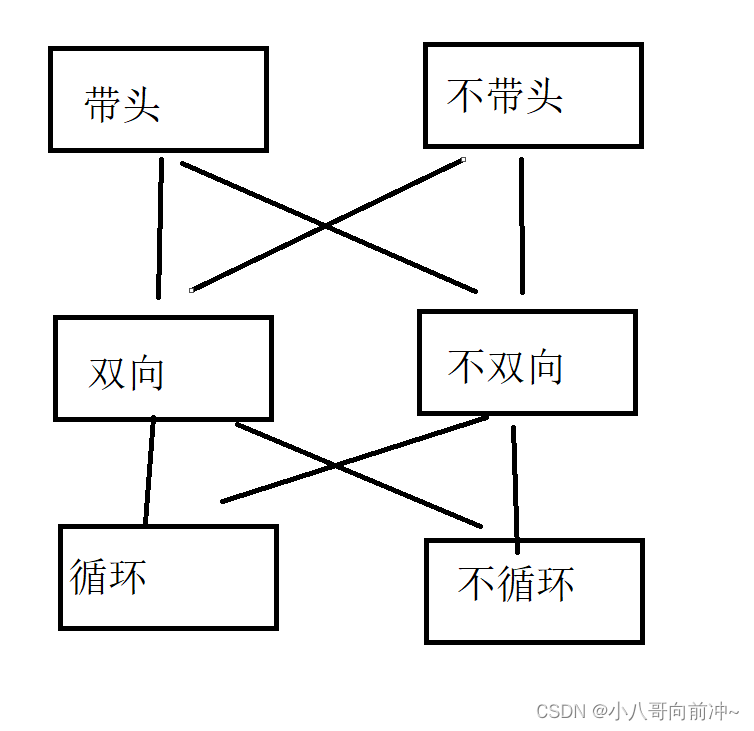
我们只需要知道链表的底层逻辑,那么不管什么链表都能说出个大概。
双链表的简要概述
带头双向循环链表(以下都称双链表)和顺序表一样它是一个连着一个,但有一个哨兵位(充当头节点,注意里面没有有效数据),它的特点通俗的讲每个节点都能找到邻位,这个好处是循环用的少。我们带图来理解一下。
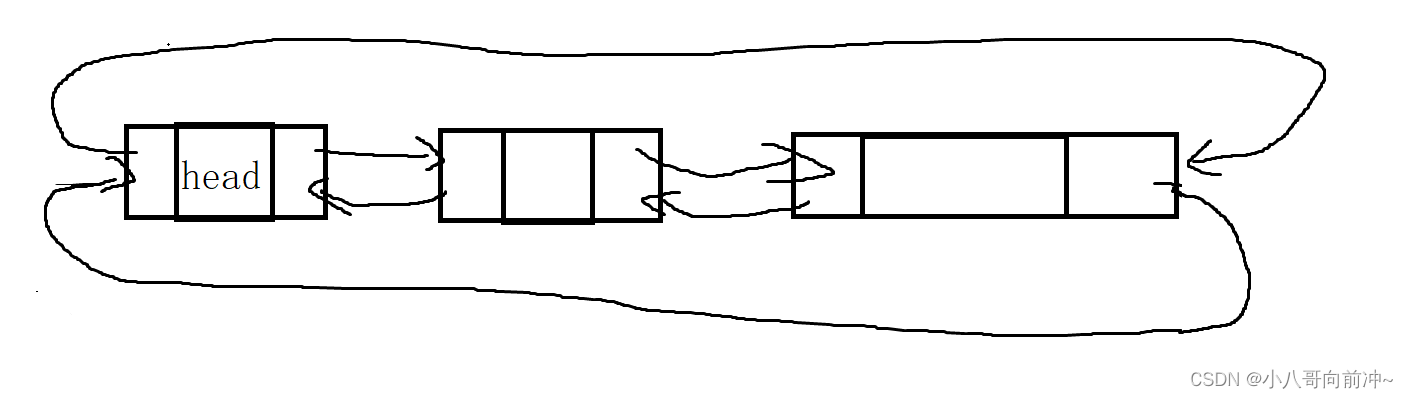
双链表的实现
我们创建一个List.h文件放双链表增删查改函数的声明,一个List.c文件放增删查改函数的实现。而链表节点的声明:
typedef int LDataType;
//双链表节点
typedef struct ListNode
{
LDataType x;
struct ListNode* prev;
struct ListNode* next;
}LNode;初始化函数的实现
这个函数的作用是创建一个哨兵位节点,以后的增删查改函数都基于这个哨兵位上面。既然是要创建节点,那么我们得先开辟一个节点空间,不如我们将开辟空间封装成一个函数,后续开辟空间调用这个函数即可。
//链表节点申请
LNode* LBuyNode(LDataType x)
{
LNode* node = (LNode*)malloc(sizeof(LNode));
if (node == NULL)
{
perror("LBuyNode::malloc!");
return NULL;
}
node->x = x;
node->prev = node;
node->next = node;
return node;
}
//链表的初始化
void InitList(LNode** pphead)
{
//将第一个节点设为哨兵位
*pphead = LBuyNode(-1);
}尾插函数的实现
在尾插之前我们首先要开辟节点然后再插入,进行一系列操作。
//尾插
void LpushBack(LNode* phead, LDataType x)
{
assert(phead);
LNode* newnode = LBuyNode(x);
phead->prev->next = newnode;
newnode->prev = phead->prev;
newnode->next = phead;
phead->prev = newnode;
}打印函数的实现
注意我们这个函数的打印和顺序表,单链表打印完全不同,稍不注意就会陷入死循环。
//链表打印
void LPrint(LNode* phead)
{
assert(phead);
LNode* cur = phead->next;
while (cur != phead)
{
printf("%d->", cur->x);
cur = cur->next;
}
printf("\n");
}头插函数的实现
和尾插函数一样,插入之前要先开辟节点空间再进行一系列操作。
//头插
void LpushFront(LNode* phead, LDataType x)
{
//插入之前哨兵位不能没有哨兵位
assert(phead);
LNode* newnode = LBuyNode(x);
newnode->next = phead->next;
phead->next->prev = newnode;
phead->next = newnode;
newnode->prev = phead;
}查找函数的实现
这个函数还是和打印函数一样,注意别陷入死循环。
//查找某个值
LNode* LFind(LNode* phead, LDataType x)
{
LNode* cur = phead->next;
while (cur != phead)
{
if (cur->x == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}在指定位置之后插入函数的实现
这个函数一般配合上面的查找函数一起合作完成。
//在pos位置之后插入
void InsertAfter(LNode* pos, LDataType x)
{
//插入的位置不能为空
assert(pos);
LNode* newnode = LBuyNode(x);
newnode->next = pos->next;
pos->next->prev = newnode;
pos->next = newnode;
newnode->prev = pos;
}在指定位置之前插入函数的实现
这个函数仍然要和查找函数配合完成。
//在pos位置之前插入
void InsertBefore(LNode* pos, LDataType x)
{
assert(pos);
LNode* newnode = LBuyNode(x);
pos->prev->next = newnode;
newnode->prev = pos->prev;
newnode->next = pos;
pos->prev = newnode;
}尾删函数的实现
//尾删
void LpopBack(LNode* phead)
{
assert(phead);
LNode* del = phead->prev;
del->prev->next = phead;
phead->prev = del->prev;
free(del);
del = NULL;
}头删函数的实现
这个函数还是和上面尾删函数没啥特点,我们自己想几分钟就行。这里不过多介绍。
//头删
void LpopBefore(LNode* phead)
{
assert(phead);
LNode* del = phead->next;
phead->next = del->next;
del->next->prev = phead;
free(del);
del = NULL;
}删除指定位置节点
//删除pos节点
void LDelpos(LNode* pos)
{
assert(pos);
pos->prev->next = pos->next;
pos->next->prev = pos->prev;
free(pos);
pos = NULL;
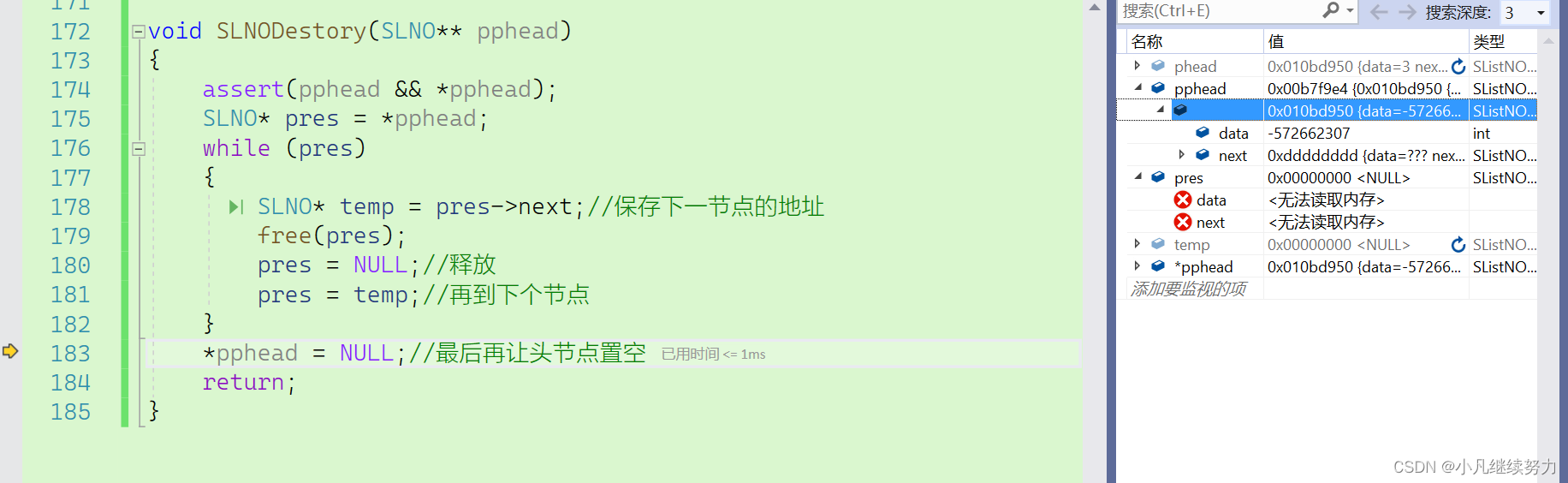
}链表销毁函数的实现
这里销毁函数和其他链表函数销毁不同,这里注意区别,防止陷入死循环。
//链表的销毁
void LDestory(LNode* phead)
{
assert(phead);
LNode* cur = phead->next;
while (cur!=phead)
{
free(cur);
cur = cur->next;
}
cur = NULL;
free(phead);
phead = NULL;
}总代码
List.h文件
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int LDataType;
//双链表节点
typedef struct ListNode
{
LDataType x;
struct ListNode* prev;
struct ListNode* next;
}LNode;
//链表的初始化
void InitList(LNode** pphead);
//链表节点申请
LNode* LBuyNode(LDataType x);
//头插
void LpushFront(LNode* phead, LDataType x);
//链表打印
void LPrint(LNode* phead);
//尾插
void LpushBack(LNode* phead, LDataType x);
//查找某个值
LNode* LFind(LNode* phead, LDataType x);
//在pos位置之后插入
void InsertAfter(LNode* pos, LDataType x);
//在pos位置之前插入
void InsertBefore(LNode* pos, LDataType x);
//尾删
void LpopBack(LNode* phead);
//头删
void LpopBefore(LNode* phead);
//删除pos节点
void LDelpos(LNode* pos);
//链表的销毁
void LDestory(LNode* phead);List.c文件
#include"List.h"
//链表节点申请
LNode* LBuyNode(LDataType x)
{
LNode* node = (LNode*)malloc(sizeof(LNode));
if (node == NULL)
{
perror("LBuyNode::malloc!");
return NULL;
}
node->x = x;
node->prev = node;
node->next = node;
return node;
}
//链表的初始化
void InitList(LNode** pphead)
{
//将第一个节点设为哨兵位
*pphead = LBuyNode(-1);
}
//链表打印
void LPrint(LNode* phead)
{
assert(phead);
LNode* cur = phead->next;
while (cur != phead)
{
printf("%d->", cur->x);
cur = cur->next;
}
printf("\n");
}
//头插
void LpushFront(LNode* phead, LDataType x)
{
//插入之前哨兵位不能没有哨兵位
assert(phead);
LNode* newnode = LBuyNode(x);
newnode->next = phead->next;
phead->next->prev = newnode;
phead->next = newnode;
newnode->prev = phead;
}
//尾插
void LpushBack(LNode* phead, LDataType x)
{
assert(phead);
LNode* newnode = LBuyNode(x);
phead->prev->next = newnode;
newnode->prev = phead->prev;
newnode->next = phead;
phead->prev = newnode;
}
//查找某个值
LNode* LFind(LNode* phead, LDataType x)
{
LNode* cur = phead->next;
while (cur != phead)
{
if (cur->x == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
//在pos位置之后插入
void InsertAfter(LNode* pos, LDataType x)
{
//插入的位置不能为空
assert(pos);
LNode* newnode = LBuyNode(x);
newnode->next = pos->next;
pos->next->prev = newnode;
pos->next = newnode;
newnode->prev = pos;
}
//在pos位置之前插入
void InsertBefore(LNode* pos, LDataType x)
{
assert(pos);
LNode* newnode = LBuyNode(x);
pos->prev->next = newnode;
newnode->prev = pos->prev;
newnode->next = pos;
pos->prev = newnode;
}
//尾删
void LpopBack(LNode* phead)
{
assert(phead);
LNode* del = phead->prev;
del->prev->next = phead;
phead->prev = del->prev;
free(del);
del = NULL;
}
//头删
void LpopBefore(LNode* phead)
{
assert(phead);
LNode* del = phead->next;
phead->next = del->next;
del->next->prev = phead;
free(del);
del = NULL;
}
//删除pos节点
void LDelpos(LNode* pos)
{
assert(pos);
pos->prev->next = pos->next;
pos->next->prev = pos->prev;
free(pos);
pos = NULL;
}
//链表的销毁
void LDestory(LNode* phead)
{
assert(phead);
LNode* cur = phead->next;
while (cur!=phead)
{
free(cur);
cur = cur->next;
}
cur = NULL;
free(phead);
phead = NULL;
}





![[阅读笔记15][Orca]Progressive Learning from Complex Explanation Traces of GPT-4](https://img-blog.csdnimg.cn/direct/c78e94ba2acf40b1ba5908fab310f097.png)