文章目录
- Deep Neural Network
- 1、Deep L-layer Neural Network
- 2、Forward Propagation in a Deep Network
- 3、Getting your matrix dimensions right
- 4、Why deep representations?
- 5、 Building blocks of deep neural networks
- 6、 Forward and Backward Propagation
- 7、Parameters vs Hyperparameters
- 8、 What does this have to do with the brain?
- 9、Quiz
- 10、Homework
- 10.1、Building your Deep Neural Network: Step by Step
- 10.2、Deep Neural Network for Image Classification: Application
- 11、Summary
本部分接续上周的浅层神经网络讲解,对具有多于一个隐藏层的深层神经网络进行介绍并摘要。
本文参考自 Coursera吴恩达《神经网络与深度学习》课程笔记(5)-- 深层神经网络
Deep Neural Network
1、Deep L-layer Neural Network
深层神经网络其实就是包含更多的隐藏层的神经网络。

Notations:
n
[
l
]
n^{[l]}
n[l]表示第
l
l
l层包含的单元个数,第
l
l
l层的激活函数输出用
a
[
l
]
a^{[l]}
a[l]表示,
a
[
l
]
=
g
[
l
]
(
z
[
l
]
)
a^{[l]}=g^{[l]}(z^{[l]})
a[l]=g[l](z[l]),
W
[
l
]
W^{[l]}
W[l] 表示第l层的权重.
2、Forward Propagation in a Deep Network
神经网络里的计算和之前的思路相同,要从单个样本过渡到多个样本,最终整体形式如下:
Z
[
l
]
=
W
[
l
]
A
[
l
−
1
]
+
b
[
l
]
Z^{[l]}=W^{[l]}A^{[l-1]}+b^{[l]}
Z[l]=W[l]A[l−1]+b[l]
A
[
l
]
=
g
[
l
]
(
Z
[
l
]
)
A^{[l]}=g^{[l]}(Z^{[l]})
A[l]=g[l](Z[l])其中
l
=
1
,
…
…
,
L
l = 1,……,L
l=1,……,L
3、Getting your matrix dimensions right
对于单个训练样本:

z
[
1
]
=
W
[
1
]
∗
x
+
b
[
1
]
z^{[1]}=W^{[1]}*x+b^{[1]}
z[1]=W[1]∗x+b[1]
(
3
,
1
)
⟶
(
3
,
2
)
∗
(
2
,
1
)
+
(
3
,
1
)
(3,1) \longrightarrow(3,2)*(2,1)+(3,1)
(3,1)⟶(3,2)∗(2,1)+(3,1)
推广之:
W
[
l
]
:
(
n
[
l
]
,
n
[
l
−
1
]
)
W^{[l]}:(n^{[l]},n^{[l-1]})
W[l]:(n[l],n[l−1])
b
[
l
]
:
(
n
[
l
]
,
1
)
b^{[l]}:(n^{[l]},1)
b[l]:(n[l],1)
且在反向传播过程中:
d
W
[
l
]
=
W
[
l
]
:
(
n
[
l
]
,
n
[
l
−
1
]
)
dW^{[l]}=W^{[l]}:(n^{[l]},n^{[l-1]})
dW[l]=W[l]:(n[l],n[l−1])
d
b
[
l
]
=
b
[
l
]
:
(
n
[
l
]
,
1
)
db^{[l]}=b^{[l]}:(n^{[l]},1)
db[l]=b[l]:(n[l],1)
正向传播中:
z
[
l
]
:
(
n
[
l
]
,
1
)
z^{[l]}:(n^{[l]},1)
z[l]:(n[l],1)
a
[
l
]
:
(
n
[
l
]
,
1
)
a^{[l]}:(n^{[l]},1)
a[l]:(n[l],1)
且
d
z
[
l
]
和
d
a
[
l
]
与
z
[
l
]
,
a
[
l
]
维度一致
dz^{[l]}和da^{[l]}与z^{[l]},a^{[l]}维度一致
dz[l]和da[l]与z[l],a[l]维度一致
对于m个训练样本:
Z
[
1
]
=
W
[
1
]
∗
X
+
b
[
1
]
Z^{[1]}=W^{[1]}*X+b^{[1]}
Z[1]=W[1]∗X+b[1]
其中,
W
[
1
]
,
b
[
1
]
W^{[1]},b^{[1]}
W[1],b[1]的维度不发生变化,
X
X
X是
(
n
[
0
]
,
m
)
(n^{[0]},m)
(n[0],m),这会导致
Z
[
l
]
和
A
[
l
]
Z^{[l]}和A^{[l]}
Z[l]和A[l]尺度变为
(
n
[
l
]
,
m
)
(n^{[l]},m)
(n[l],m),
d
Z
[
l
]
和
d
A
[
l
]
dZ^{[l]}和dA^{[l]}
dZ[l]和dA[l]与之相同。
主要就四个量要记: W , b , Z , A W,b,Z,A W,b,Z,A
4、Why deep representations?

先来看人脸识别的例子,如图所示。
经过训练,神经网络第一层所做的事就是从原始图片中提取出人脸的轮廓与边缘,即边缘检测。这样每个神经元得到的是一些边缘信息。神经网络第二层所做的事情就是将前一层的边缘进行组合,组合成人脸一些局部特征,比如眼睛、鼻子、嘴巴等。第三层,就将这些局部特征组合起来,融合成人脸的模样。可以看出,随着层数由浅到深,神经网络提取的特征也是从边缘到局部特征到整体,由简单到复杂。可见,如果隐藏层足够多,那么能够提取的特征就越丰富、越复杂,模型的准确率就会越高。
语音识别模型也是这个道理。浅层的神经元能够检测一些简单的音调,然后较深的神经元能够检测出基本的音素,更深的神经元就能够检测出单词信息。如果网络够深,还能对短语、句子进行检测。记住一点,神经网络从左到右,神经元提取的特征从简单到复杂。特征复杂度与神经网络层数成正相关。特征越来越复杂,功能也越来越强大。
除了从提取特征复杂度的角度来说明深层网络的优势之外,深层网络还有另外一个优点,就是能够减少神经元个数,从而减少计算量。例如下面这个例子,使用电路理论,计算逻辑输出:
y
=
x
1
⊕
x
2
⊕
x
3
…
…
⊕
x
n
y = x_1\oplus x_2\oplus x_3……\oplus x_n
y=x1⊕x2⊕x3……⊕xn

对于多层神经网络,层数是
O
(
l
o
g
n
)
O(logn)
O(logn),使用的神经元的个数为
1
+
2
+
…
…
+
2
l
o
g
2
(
n
)
−
1
=
n
−
1
1+2+……+2^{log_2(n)-1}=n-1
1+2+……+2log2(n)−1=n−1
如果只用一层网络,需要
2
n
−
1
个神经元
2^{n-1}个神经元
2n−1个神经元
这一节讲的不明所以,大概明白随着层数变深识别的特征越复杂,结果越精确即可。
5、 Building blocks of deep neural networks

对于神经网络中的一层,既需要考虑前向传播的结果计算,也需要考虑反向传播的参数更新,整体的流程如下所示:
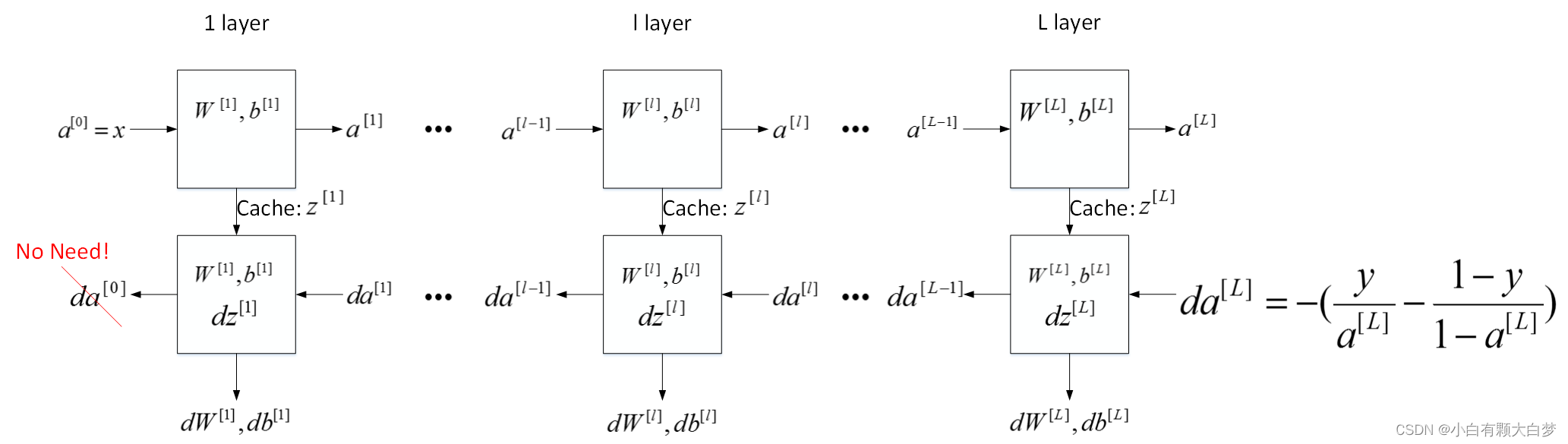
6、 Forward and Backward Propagation
正向传播在第二节讨论过了,比较简单,现在主要看反向传播,结合上一章的两层神经网络看一下计算公式。

两层神经网络公式如上所示,要注意的是
d
z
[
2
]
dz^{[2]}
dz[2]是按照最后一层的sigmoid+loss来计算的,通用的形式应该是
d
z
[
1
]
dz^{[1]}
dz[1]那样。
可总结如下:
d
Z
[
l
]
=
d
A
[
l
]
∗
g
′
(
Z
[
l
]
)
dZ^{[l]} = dA^{[l]} * g'(Z^{[l]})
dZ[l]=dA[l]∗g′(Z[l])
d
W
[
l
]
=
∂
J
∂
W
[
l
]
=
1
m
d
Z
[
l
]
A
[
l
−
1
]
T
dW^{[l]} = \frac{\partial \mathcal{J} }{\partial W^{[l]}} = \frac{1}{m} dZ^{[l]} A^{[l-1] T}
dW[l]=∂W[l]∂J=m1dZ[l]A[l−1]T
d
b
[
l
]
=
∂
J
∂
b
[
l
]
=
1
m
∑
i
=
1
m
d
Z
[
l
]
(
i
)
db^{[l]} = \frac{\partial \mathcal{J} }{\partial b^{[l]}} = \frac{1}{m} \sum_{i = 1}^{m} dZ^{[l](i)}
db[l]=∂b[l]∂J=m1i=1∑mdZ[l](i)
d
A
[
l
−
1
]
=
∂
L
∂
A
[
l
−
1
]
=
W
[
l
]
T
d
Z
[
l
]
dA^{[l-1]} = \frac{\partial \mathcal{L} }{\partial A^{[l-1]}} = W^{[l] T} dZ^{[l]}
dA[l−1]=∂A[l−1]∂L=W[l]TdZ[l]

我们从最后一层出发,给定的输入是
d
A
[
L
]
dA^{[L]}
dA[L],然后我们用
d
Z
[
L
]
dZ^{[L]}
dZ[L]作为一个中介,得出
d
W
[
L
]
,
d
b
[
L
]
,
d
A
[
L
−
1
]
dW^{[L]},db^{[L]},dA^{[L-1]}
dW[L],db[L],dA[L−1],之后重复。
7、Parameters vs Hyperparameters
该部分介绍神经网络中的参数(parameters)和超参数(hyperparameters)的概念。
神经网络中的参数就是我们熟悉的 W [ l ] W^{[l]} W[l]和 b [ l ] b^{[l]} b[l]。而超参数则是例如学习速率 α α α,训练迭代次数 N N N,神经网络层数 L L L,各层神经元个数 n [ l ] n^{[l]} n[l],激活函数 g ( z ) g(z) g(z)等。之所以叫做超参数的原因是它们决定了参数 W [ l ] W^{[l]} W[l]和 b [ l ] b^{[l]} b[l]的值。
如何设置最优的超参数是一个比较困难的、需要经验知识的问题。通常的做法是选择超参数一定范围内的值,分别代入神经网络进行训练,测试cost function随着迭代次数增加的变化,根据结果选择cost function最小时对应的超参数值。
8、 What does this have to do with the brain?
神经网络实际上可以分成两个部分:正向传播过程和反向传播过程。神经网络的每个神经元采用激活函数的方式,类似于感知机模型。这种模型与人脑神经元是类似的,可以说是一种非常简化的人脑神经元模型。如下图所示,人脑神经元可分为树突、细胞体、轴突三部分。树突接收外界电刺激信号(类比神经网络中神经元输入),传递给细胞体进行处理(类比神经网络中神经元激活函数运算),最后由轴突传递给下一个神经元(类比神经网络中神经元输出)。
值得一提的是,人脑神经元的结构和处理方式要复杂的多,神经网络模型只是非常简化的模型。
9、Quiz

这个东西搞的,parameters[“W” + str(i)]表示的是Wi这样一个变量,然后需要从
W
1
W1
W1到
W
L
WL
WL进行初始化
10、Homework
10.1、Building your Deep Neural Network: Step by Step
可以参考一下别人写的DeepLearning.ai作业:(1-4)-深层神经网络
不过还是自己从头写一遍更有收获。
这里结合参考文章重点看一下反向传播过程中的代码实现即可,讲的很清楚了。
主要逻辑就是:
从最后一层出发,给定的输入是 d A [ L ] dA^{[L]} dA[L],然后我们用 d Z [ L ] dZ^{[L]} dZ[L]作为一个中介,利用cache里面的 A p r e v , W , b A_{prev},W,b Aprev,W,b得出 d W [ L ] , d b [ L ] , d A [ L − 1 ] dW^{[L]},db^{[L]},dA^{[L-1]} dW[L],db[L],dA[L−1],之后重复,不同的只有最后一层激活函数与前面不同,要利用的cache逐渐更新即可。
10.2、Deep Neural Network for Image Classification: Application
主函数是这样的(从前往后顺完一个神经网络的感觉太爽了(✪ω✪))
def L_layer_model(X, Y, layers_dims, learning_rate = 0.0075, num_iterations = 3000, print_cost=False):
"""
Implements a L-layer neural network: [LINEAR->RELU]*(L-1)->LINEAR->SIGMOID.
Arguments:
X -- data, numpy array of shape (num_px * num_px * 3, number of examples)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples)
layers_dims -- list containing the input size and each layer size, of length (number of layers + 1).
learning_rate -- learning rate of the gradient descent update rule
num_iterations -- number of iterations of the optimization loop
print_cost -- if True, it prints the cost every 100 steps
Returns:
parameters -- parameters learnt by the model. They can then be used to predict.
"""
np.random.seed(1)
costs = [] # keep track of cost
# Parameters initialization.
#(≈ 1 line of code)
# parameters = ...
# YOUR CODE STARTS HERE
parameters = initialize_parameters_deep(layers_dims)
# YOUR CODE ENDS HERE
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: [LINEAR -> RELU]*(L-1) -> LINEAR -> SIGMOID.
#(≈ 1 line of code)
# AL, caches = ...
# YOUR CODE STARTS HERE
AL, caches = L_model_forward(X, parameters)
# YOUR CODE ENDS HERE
# Compute cost.
#(≈ 1 line of code)
# cost = ...
# YOUR CODE STARTS HERE
cost = compute_cost(AL, Y)
# YOUR CODE ENDS HERE
# Backward propagation.
#(≈ 1 line of code)
# grads = ...
# YOUR CODE STARTS HERE
grads = L_model_backward(AL, Y, caches)
# YOUR CODE ENDS HERE
# Update parameters.
#(≈ 1 line of code)
# parameters = ...
# YOUR CODE STARTS HERE
parameters = update_parameters(parameters, grads, learning_rate)
# YOUR CODE ENDS HERE
# Print the cost every 100 iterations
if print_cost and i % 100 == 0 or i == num_iterations - 1:
print("Cost after iteration {}: {}".format(i, np.squeeze(cost)))
if i % 100 == 0 or i == num_iterations:
costs.append(cost)
return parameters, costs
11、Summary
在浅层神经网络的基础上稍有拓展,重点掌握反向传播的计算公式即可。