写在前面
很多数据库设计者,都是按照自己的性子和习惯来设计数据库数据表,其实不然。
其实,数据库的设计也有要遵循的原则。
范式,就是规范,就是指设计数据库需要(应该)遵循的原则。
每个范式,都是用来规定某种结构或数据要求——后一范式都是在前一范式已经满足的情况用来“加强要求”(这句话很重要)。
这也是面试中经常会问到的“数据库三范式指的是什么?”,很多小伙伴只知道原子性、唯一性、独立性,但是知其然而不知其所以然。
在这里,让你彻底弄明白,什么叫数据库的三范式!
第一范式(1NF):原子性(存储的数据应该具有“不可再分性”)
不良做法如下,“学生”一列有多项信息都合在一起了,不再具有原子性,所以应该分开:
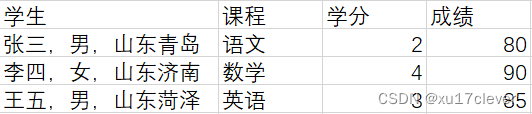
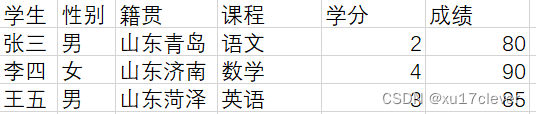
实际中,原子性还是比较容易理解的。
修改后:
第二范式(2NF):唯一性 (消除非主键部分依赖联合主键中的部分字段)(一定要在第一范式已经满足的情况下)
需要实现每一行数据具有唯一可区分的特性,并不能有部分依赖关系。
通常,给一个表加主键(也是推荐做法),就可以做到“唯一可区分”。
但主键有这样情况:
设定一个字段为主键:此时,表示该一个字段的值就可以明确确定一行数据。
设定多个字段为主键:表示只有这多个字段的值都确定后才能确定一行数据。此时也称为“联合主键”。
什么叫依赖:
如果确定一个表中的某个数据(A),则就可以确定该表中的其他另一个数据(B),则我们说:B依赖于A。
实际上,一个表只要有主键,则其他非主键一定是依赖于主键的。
什么叫“部分依赖”:
如果确定一个表中的某个数据组合(A,B),则就可以确定该表中的其他另一个数据(C),则我们说:C依赖于(A,B)(此时A,B通常就是做出主键)。
但:如果某个数据D,它只依赖于数据A,或者说,A一确定,则D也可以确定,此时我们就称为“数据D部分依赖于数据A——可见部分依赖是指某个非主键字段,依赖于联合主键字段的其中部分字段。
好了,说了这么多,估计大家也都糊涂了,接下来上例子吧!
不良做法:
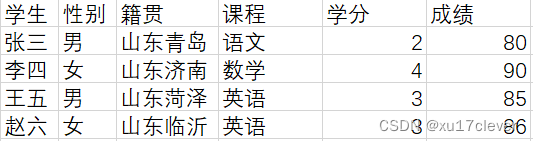
这个表虽然满足了第一范式,但是也很明显的感受到它的冗余性,其中学生信息和课程信息是冗余的。
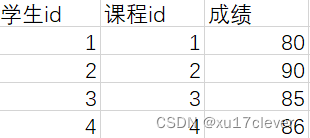
以上表如果是需要确定主键,就得是学生+课程作为联合主键。
第二范式要求非主键字段的值必须完全依赖主键(不能部分依赖),所以以上表中,学分是依赖课程的,成绩是依赖学生的。
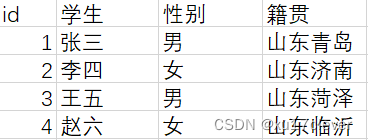
修改后,分为学生信息表、课程信息表、学生学分表:
学生信息表:只代表学生的个人信息,主键使用id以防止重名。
课程信息表:这里的主键可以不用id,使用课程名称也可以,不会有重名。
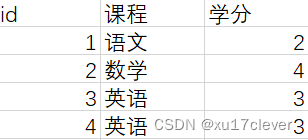
学生学分表:学生和课程,确定一个学分,这里学生id和课程id作为联合主键来对应一条成绩。
第三范式(3NF):独立性,消除传递依赖(非主键值不依赖于另一个非主键值)
在一个具有主键的表中,假设主键为A,其必然其他非主键都依赖于该主键,比如:B依赖于A,C依赖于A,D依赖于A。。。。。。
但同时:如果该表中的某个字段B的值一确定,就能够确定另一个字段的值C,则我们称为C依赖于B。
那么,就出现了:
C依赖B,B依赖A——这就是传递依赖。
则消除该传递依赖的的通常做法,就是将C依赖于B的数据,分离到另一个表中。
好了,还是蒙蒙的吧,上例子:
不良例子:
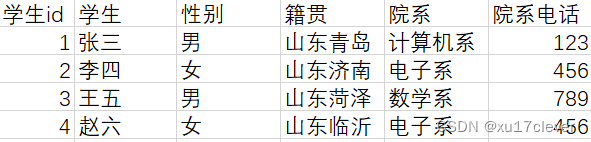
以上表既满足第一范式也满足第二范式,非主键字段也完全依赖于主键字段。
但是,院系电话字段,其实是依赖院系字段的。也就是说,院系电话字段是非主键值,而依赖了另一个非主键值-院系。所以就不符合第三范式。
改良:
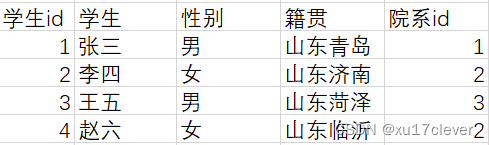
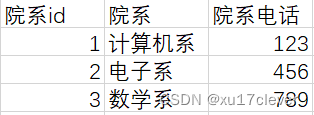
一个学生表,一个院系表,一目了然。
如果修改了院系信息,对应着也不需要修改学生信息表。但是如果还是使用以上不良例子的话,修改其中一个院系信息,得对应修改所有所属该院系的学生,
总结
通常,在实践中,满足3范式只要做到“一个表只存一种数据”基本就可以实现。
另外,范式不是绝对要求,有时候我们为了数据的使用方便,还会(需要)故意违反范式。
具体设计需求,还需要在工作中多多练习,寻找到最适合,最方便的数据库设计方案出来