目录
题目一-移除链表元素(来源)
题目描述
思路+实现
思路一 (双指针)
思路二(虚拟头节点-哨兵位)
题目二-反转链表(来源)
题目描述
思路+实现
思路一(双指针)
思路二(递归法)
题目三-链表的中间结点(来源)
题目描述
思路+实现
思路一
思路二(快慢指针)
题目四-返回倒数第K个节点(来源)
题目描述
思路+实现
思路一(直接遍历)
思路二(快慢指针)
题目五-合并两个有序链表(来源)
题目描述
思路+实现
题目六-链表分割(来源)
题目描述
思路+实现
题目七-链表的回文结构
题目描述(来源)
思路+实现
题目八-相交链表(来源)
题目描述
思路+实现
题目九-随机链表的复制(来源)
题目描述
思路+实现
题目一-移除链表元素(来源)
题目描述
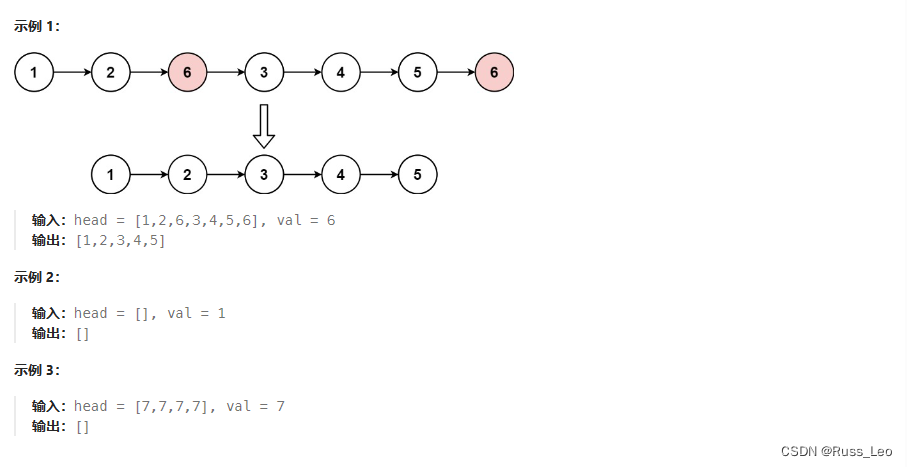
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
如下为图解
思路+实现
思路一 (双指针)
将链表遍历一遍,移除链表中值为val的结点。
设置两个均指向头节点的指针,prev(记录待删除节点的前一节点)和 cur (记录当前节点);
遍历整个链表,查找节点值为 val 的节点,找到即删除该节点,否则继续查找。
1、找到,将当前节点的前一节点(之前最近一个值不等于 val 的节点(prev))连接到当前节点(cur)的下一个节点(即将 prev 的下一节点指向 cur 的下一节点:prev->next = cur->next)。
2、没找到,更新最近一个值不等于 val 的节点(即 prev = cur),并继续遍历(cur = cur->next)。
struct ListNode* removeElements(struct ListNode* head, int val)
{
//循环处理,直至头结点为空或头结点的值不等于 val,此时将头结点指向第一个不为 val 的结点
while (NULL != head && head->val == val)
{
head = head->next;
}
//初始化两个指针,cur 用于遍历链表,prev 用于记录 cur 的前一个结点
struct ListNode* cur = head;
struct ListNode* prev = head;
//遍历链表,直到 cur 为空(即到达链表末尾)
while (cur != NULL)
{
//判断当前结点 cur 的值是否等于 val
if (cur->val == val)
{
//如果等于 val,则将 prev 结点的 next 指针指向 cur 的下一个结点,从而跳过并删除 cur 结点
prev->next = cur->next;
}
else
{
//如果不等于 val,则 prev 向后移动,与 cur 对齐
prev = cur;
}
//cur 指针向后移动,遍历下一个结点
cur = cur->next;
}
//返回处理后的链表头结点
return head;
}思路二(虚拟头节点-哨兵位)
通过在头节点前增加虚拟头节点,这样头节点就成了普通节点,不需要单独拎出来考虑,但是在返回的时候,返回的是虚拟头节点的下一节点而不是虚拟头节点。
struct ListNode* removeElements(struct ListNode* head, int val)
{
//分配内存创建一个虚拟头结点dummyHead,用于简化删除操作
struct ListNode* dummyHead = malloc(sizeof(struct ListNode));
//检查内存分配是否成功,如果失败则返回NULL
if (NULL == dummyHead)
{
return NULL;
}
//将虚拟头结点的next指针指向原始链表的头结点
dummyHead->next = head;
//初始化一个游标cur,让它指向虚拟头结点
struct ListNode* cur = dummyHead;
//遍历整个链表,直到到达链表尾部(cur->next不再指向任何结点)
while (cur->next != NULL)
{
//判断当前结点的下一个结点值是否等于要移除的值val
if (cur->next->val == val)
{
//若相等,则将当前结点的next指针直接指向待删除结点的下一个结点,从而跳过并删除该结点
cur->next = cur->next->next;
}
else
{
//若不相等,则正常移动游标到下一个结点
cur = cur->next;
}
}
//新链表的实际头结点是虚拟头结点的下一个结点
struct ListNode* retNode = dummyHead->next;
//释放虚拟头结点占用的内存
free(dummyHead);
//返回新链表的实际头结点
return retNode;
}题目二-反转链表(来源)
题目描述
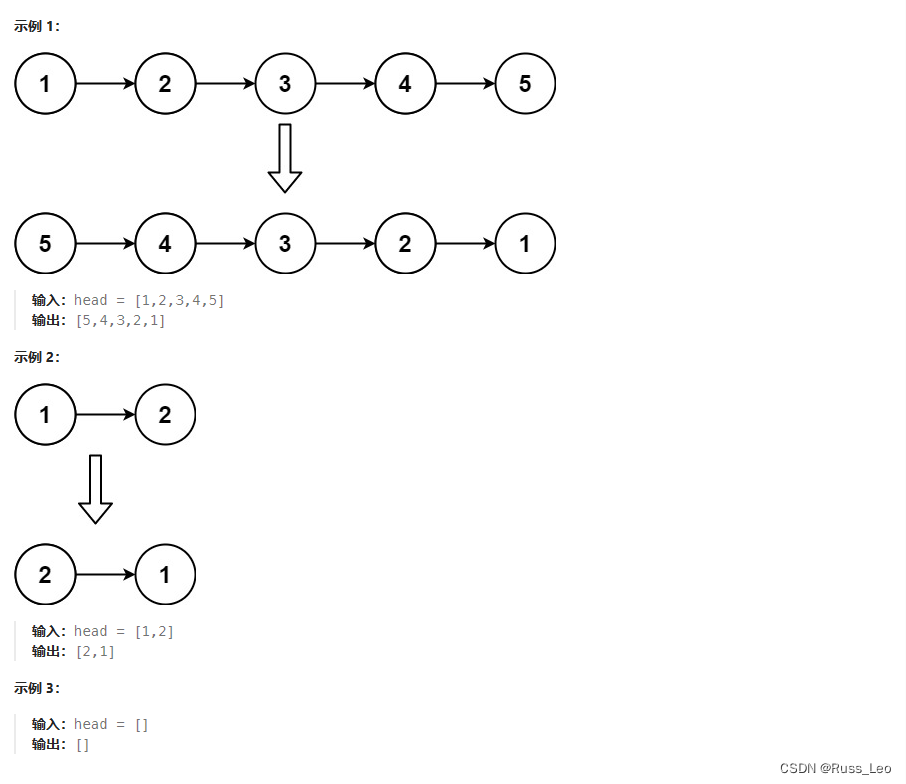
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
如下为图解
思路+实现
思路一(双指针)
从前向后遍历链表,然后把每个结点的 next 指向前一个结点就好。
具体实现中,首先需要两个指针,一个 cur 指针在遍历到每个结点进行操作,一个 prev 指针指向 cur 的前一个结点。其次,由于 cur->next 指向 prev,导致原来的 cur 的下一个结点失去引用,所以还需要一个指针 temp 用来保存后一个结点。
struct ListNode* reverseList(struct ListNode* head)
{
// 初始化两个指针,cur 用于遍历链表,初始时指向头节点
struct ListNode* cur = head;
// 初始化一个指针 prev 用于暂存每个节点的前一个节点,初始时 prev 为 NULL
struct ListNode* prev = NULL;
// 当 cur 不为空时,执行循环
while (cur)
{
// 临时存储 cur 节点的下一个节点(即将被 cur 节点覆盖的下一个节点的地址)
struct ListNode* temp = cur->next;
// 修改 cur 节点的 next 指针,使其指向 prev 节点,即完成了一次节点间的翻转连接
cur->next = prev;
// prev 和 cur 同时向前移动一步,prev 移动到 cur 的位置,cur 移动到下一个节点的位置
prev = cur;
cur = temp;
}
// 当循环结束时,prev 指针指向了原链表的新头部,因此返回 prev 作为翻转后链表的新头节点
return prev;
}思路二(递归法)
递归法和双指针法是一样的逻辑,同样是当 curr 为空的时候循环结束,不断将 curr 指向 pre 的过程。
struct ListNode* reverseList(struct ListNode* head)
{
// 基线条件:如果头结点为空或者只有一个结点,无需反转,直接返回头结点
if (head == NULL || head->next == NULL)
{
return head;
}
// 递归调用,将后续部分链表反转,并获取反转后的尾结点
struct ListNode* newTail = reverseList(head->next);
// 将尾结点的next指针指向当前头结点,完成局部反转
head->next->next = head;
// 更新当前头结点的next指针,使其指向NULL,成为新的尾结点
head->next = NULL;
// 返回新的头结点,即原链表的尾结点
return newTail;
}题目三-链表的中间结点(来源)
题目描述
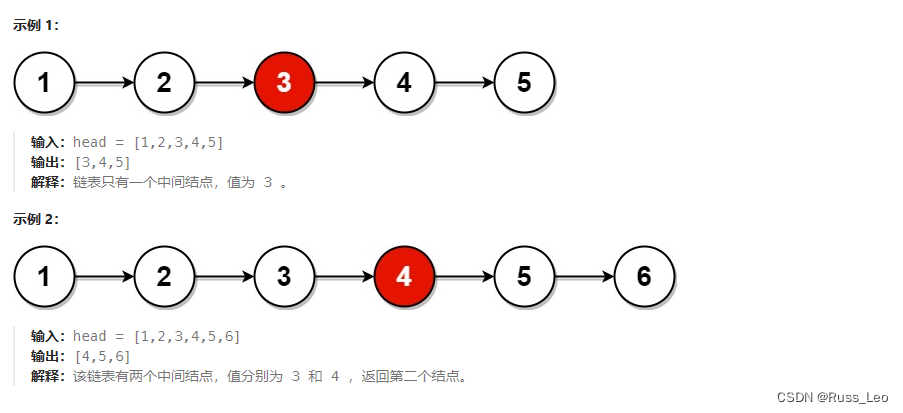
给你单链表的头结点 head ,请你找出并返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
思路+实现
思路一
通过遍历计算链表的长度,再找到中间位置即可
// 定义链表节点结构体
struct ListNode {
int val; // 节点值
struct ListNode* next; // 指向下一个节点的指针
};
// 函数声明:找到并返回给定单链表的中间节点
struct ListNode* middleNode(struct ListNode* head)
{
// 初始化一个临时指针p,并将其指向链表头节点
struct ListNode* p = head;
// 初始化计数变量len,用于计算链表的长度
int len = 0;
// 遍历链表,统计链表总长度
while(p != NULL)
{
// 将p移动到下一个节点
p = p -> next;
// 长度加一
len++;
}
// 重新将p指针初始化为头节点,开始第二次遍历以定位中间节点
p = head;
// 初始化计数变量k,用于跟踪当前遍历到的位置
int k = 0;
// 遍历链表,直到找到中间位置
while(k < len / 2)
{
// k自增,表示当前位置前进了1
k++;
// p指针移动到下一个节点
p = p -> next;
}
// 当退出循环时,p指向的就是链表的中间节点(对于长度为奇数的链表)或第一个中间节点(对于长度为偶数的链表)
// 注意:若需返回第二个中间节点(仅针对长度为偶数的链表),还需在此基础上再移动一次p指针
// 返回中间节点
return p;
}思路二(快慢指针)
使用两个指针变量,刚开始都位于链表的第 1 个结点,一个永远一次只走 1 步,一个永远一次只走 2 步,一个在前,一个在后,同时走。这样当快指针走完的时候,慢指针就来到了链表的中间位置。
// 定义链表节点结构体
struct ListNode
{
int val; // 节点值
struct ListNode* next; // 指向下一个节点的指针
};
// 函数声明:找到并返回给定单链表的中间节点
struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode *slow = head; // 慢指针初始化为头节点
struct ListNode *fast = head; // 快指针初始化也为头节点
// 当快指针未达到链表尾部时,持续移动
while (fast != NULL && fast->next != NULL)
{
slow = slow->next; // 慢指针向前移动一个节点
fast = fast->next->next; // 快指针向前移动两个节点
}
// 慢指针所指向的就是链表的中间节点
return slow;
}题目四-返回倒数第K个节点(来源)
题目描述
实现一种算法,找出单向链表中倒数第 k 个节点。返回该节点的值。

思路+实现
思路一(直接遍历)
最直接的解法是「统计链表长度」,分为两步:
遍历并统计链表长度,记链表长度为 N ;
设置一个节点指针向前走 N−k步,便可找到链表倒数第 k 个节点。
struct ListNode
{
int val;
struct ListNode *next;
};
int kthToLast(struct ListNode* head, int k)
{
// 判断链表是否为空
if (head == NULL )
{
return NULL;
}
// 第一次遍历获取链表长度
int length = 0;
struct ListNode* temp = head;
while (temp != NULL)
{
length++;
temp = temp->next;
}
// 第二次遍历,让指针先走k步
temp = head;
for (int i = 0; i < length - k; ++i)
{
temp = temp->next;
}
// 返回倒数第k个节点
return temp->val;
}思路二(快慢指针)
借助双指针,可省去统计链表长度操作,算法流程为:
初始化双指针 low , fast 都指向头节点 head ;
先令 fast 走 k 步,此时 low , fast 的距离为 k ;
令 low , fast 一起走,直到 fast 走过尾节点时跳出,此时 low 指向「倒数第 k 个节点」,返回之即可。
struct ListNode
{
int val;
struct ListNode *next;
}
int kthToLast(struct ListNode* head, int k)
{
// 判断链表是否为空
if (head == NULL )
{
return NULL;
}
struct ListNode* fast = head; // 初始化fast指针指向头节点
struct ListNode* low = head; // 初始化low指针也指向头节点
// 先让fast指针先走k步
for (int i = 0; i < k - 1 && fast != NULL; i++)
{
fast = fast->next;
}
// 如果k大于链表长度,则返回-1或其他无效值
if (fast == NULL)
{
return -1;
}
// 之后,low和fast指针同步移动,直到fast到达链表尾部
while (fast->next != NULL)
{
low = low->next;
fast = fast->next;
}
// 此时low指向的就是倒数第k个节点,返回其值
return low->val;
}题目五-合并两个有序链表(来源)
题目描述
将两个升序链表为一个新的升序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。

思路+实现
需创建一个头结点,然后从两个链表的表头开始依次比较传入的两个链表的结点的大小,并将两个链表中较小的结点尾插到新链表的后面即可。
struct ListNode
{
int val;
struct ListNode *next;
};
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
// 申请一个新的临时头节点,作为合并后链表的起始点,不存储有效数据
struct ListNode* guard = (struct ListNode*)malloc(sizeof(struct ListNode));
// 初始化尾指针,指向临时头节点,用于构建新的有序链表
struct ListNode* cur = guard;
// 初始化两个指针分别指向待合并链表l1和l2的当前节点
struct ListNode* cur1 = list1;
struct ListNode* cur2 = list2;
// 当两个链表均未遍历完时执行循环
while (cur1 && cur2)
{
// 比较当前节点的值,将较小节点链接到新链表的尾部
if (cur1->val < cur2->val)
{
cur->next = cur1;
// 移动l1的当前节点指针到下一个节点
cur1 = cur1->next;
}
else
{
cur->next = cur2;
// 移动l2的当前节点指针到下一个节点
cur2 = cur2->next;
}
// 更新尾指针,使其始终指向新链表的最后一个节点
cur = cur->next;
}
// 将未遍历完的链表剩余部分链接到新链表的尾部
if (cur1) cur->next = cur1;
else cur->next = cur2;
// 新链表的头指针指向临时头节点的下一个节点,即最小值节点
struct ListNode* head = guard->next;
// 释放临时头节点,无需在最终链表中保留
free(guard);
// 返回合并后的新链表头指针
return head;
}题目六-链表分割(来源)
题目描述
现有一链表的头指针 ListNode* pHead,给一定值x,编写一段代码将所有小于x的结点排在其余结点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针。
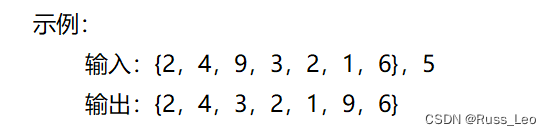
思路+实现
创建两个链表,遍历一遍传入的链表,将值大于x的结点和值小于x的结点依次尾插到两个链表中,最后再将这两个链表链接起来,并返回第一个结点的位置即可。
1.把小于x的结点尾插到less链表,把大于x的结点尾插到greater链表。
2.将less链表与greater链表链接起来。
typedef struct ListNode
{
int val;
struct ListNode *next;
}ListNode;
ListNode* partition(ListNode* pHead, int x)
{
// 创建两个空链表的头节点以及它们对应的尾节点指针
ListNode* greaterHead, *greaterTail, *lessHead, *lessTail;
// 分别为大于等于x的链表和小于x的链表分配内存空间,并初始化为空链表(头节点的next设为NULL)
greaterHead = greaterTail = (ListNode*)malloc(sizeof(struct ListNode));
lessHead = lessTail = (ListNode*)malloc(sizeof(struct ListNode));
greaterTail->next = lessTail->next = NULL;
// 创建一个指针cur遍历原始链表
ListNode* cur = pHead;
// 遍历整个原始链表
while(cur)
{
// 如果当前节点的值小于x,则将其添加到小于x的链表尾部
if(cur->val < x)
{
lessTail->next = cur;
// 更新小于x链表的尾节点指针
lessTail = lessTail->next;
}
// 否则,将其添加到大于等于x的链表尾部
else
{
greaterTail->next = cur;
// 更新大于等于x链表的尾节点指针
greaterTail = greaterTail->next;
}
// 移动原始链表的指针到下一个节点
cur = cur->next;
}
// 将小于x的链表与大于等于x的链表连接起来,使得小于x的部分在前
lessTail->next = greaterHead->next;
// 确保大于等于x的链表末尾不指向任何节点
greaterTail->next = NULL;
// 获取新链表的头节点,即小于x的链表的实际头节点
ListNode* head = lessHead->next;
// 释放两个空链表头节点的内存,因为它们已经完成了辅助构建新链表的任务
free(greaterHead);
free(lessHead);
// 返回新链表的头节点
return head;
}题目七-链表的回文结构
题目描述(来源)
对于一个链表,请设计一个时间复杂度为O(n),额外空间复杂度为O(1)的算法,判断其是否为回文结构。
给定一个链表的头指针A,请返回一个bool值,代表其是否为回文结构。保证链表长度小于等于900。

思路+实现
找到传入链表的中间结点,并将中间结点及其后面结点进行反转,然后再将原链表的前半部分与反转后的后半部分进行比较,若相同,则该链表是回文结构,否则,不是回文结构。
1.找到链表的中间结点。

2.反转中间结点及其后面的结点。

3.比较链表的前半部分与后半部分的结点值,若相同则是回文结构,否则,不是回文结构。

将A指针指向的结点与RHead指针指向的结点进行比较,若相同,则两个指针后移,继续比较后面的结点,直到RHead指针指向NULL时,比较结束。
// 该函数的作用是找到链表的中间节点并返回
struct ListNode* middleNode(struct ListNode* head)
{
// 初始化两个指针,slow和fast,都指向链表头节点
struct ListNode* fast = head;
struct ListNode* slow = head;
// 当fast指针及其下一个节点都不为空时,持续执行循环
while (fast && fast->next)
{
// slow指针每次向前移动一个节点
slow = slow->next;
// fast指针每次向前移动两个节点
fast = fast->next->next;
}
// 循环结束后,slow指针指向了链表的中间节点
return slow;
}
// 该函数的作用是反转链表,并返回反转后的新链表头节点
struct ListNode* reverseList(struct ListNode* head)
{
// 初始化一个指针cur指向原链表头节点
struct ListNode* cur = head;
// 初始化一个新链表头节点newhead为NULL
struct ListNode* newhead = NULL;
// 当cur指向的节点不为空时,持续执行循环
while (cur)
{
// 保存cur节点的下一个节点
struct ListNode* next = cur->next;
// 反转cur节点的指向,使其指向新的链表头
cur->next = newhead;
// 更新新链表头节点为当前cur节点
newhead = cur;
// 移动cur指针到下一个节点
cur = next;
}
// 循环结束后,newhead指向反转后的新链表头节点
return newhead;
}
// 该函数的作用是检查链表是否为回文链表,并返回布尔值
bool chkPalindrome(ListNode* Head)
{
// 首先找到链表的中间节点
ListNode* mid = middleNode(Head);
// 将中间节点之后的部分反转,得到RHead
ListNode* RHead = reverseList(mid);
// 用两个指针分别从头节点和反转后的链表头节点开始遍历
while (RHead)
{
// 如果对应位置的节点值不相等,则链表不是回文链表,返回false
if (Head->val != RHead->val)
return false;
// 两个指针分别向后移动一位
Head = Head->next;
RHead = RHead->next;
}
// 若循环结束仍未发现不相等的节点值,则链表是回文链表,返回true
return true;
}题目八-相交链表(来源)
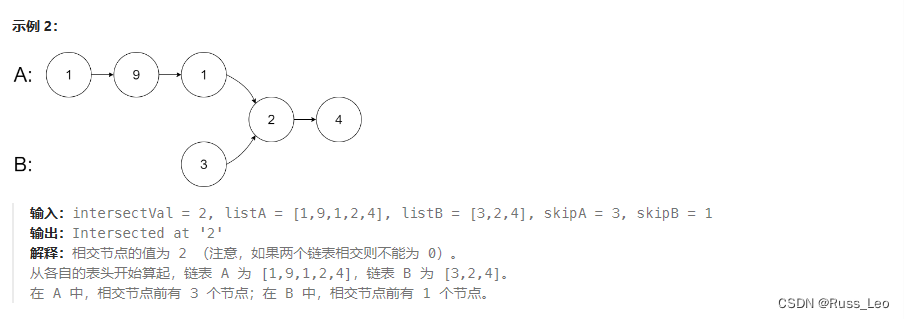
题目描述
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 nul1 。
图示两个链表在节点 c1 开始相交:

题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0
listA - 第一个链表
listB - 第二个链表
skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数
skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。


思路+实现
1.判断这两个链表是否相交。
要寻找两个链表的起始结点,首先我们需要判断这两个链表是否相交。那么如何判断两个单向链表是否相交呢?如果两个单向链表是相交的那么这两个链表的最后一个结点必定是同一个。
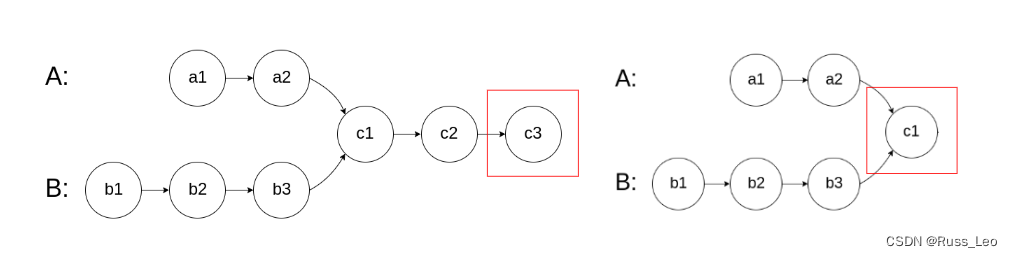
2.寻找这两个链表的起始相交结点。
我们假设这两个链表的结点个数之差为count,我们可以让指向较长链表的指针先向后移动count步,然后指向长链表的指针和指向短链表的指针再同时向后移动,这样这两个指针最后会同时走到各自的链表结尾(NULL)。

在两个指针同时向后移动的过程中,第一次指向的同一个结点便是这两个相交链表的起始结点。这时返回该结点地址即可。

注:在寻找链表的最后一个结点的同时,我们便可以计算两个链表的长度,只不过这时我们只遍历到了最后一个结点,并没有遍历到NULL,所以统计的两个链表的结点个数都比链表实际长度少一,但这两个值相减后依然是这两个链表的结点个数差。
// 定义链表节点结构体
struct ListNode
{
int val; // 节点的值
struct ListNode *next; // 指向下一个节点的指针
};
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB)
{
// 初始化两个指针分别指向两个链表的头节点
struct ListNode* curA = headA;
struct ListNode* curB = headB;
// 计算链表A和链表B的长度
int lenA = 0, lenB = 0;
while (curA->next)
{
lenA++;
curA = curA->next;
}
while (curB->next)
{
lenB++;
curB = curB->next;
}
// 如果两个链表都没有交点,那么它们各自的尾节点不会相同,这时直接返回NULL
if (curA != curB) return NULL;
// 初始化长链表和短链表的指针
struct ListNode* longlist = headA;
struct ListNode* shortlist = headB;
// 根据长度判断哪个链表是长链表,哪个是短链表
if (lenA < lenB)
{
longlist = headB;
shortlist = headA;
}
// 让长链表指针先向前移动|lenA - lenB|个节点,使长链表和短链表的尾节点对齐
int count = abs(lenA - lenB);
while (count--)
{
longlist = longlist->next;
}
// 两个指针同时向前移动,直到找到交点
while (longlist != shortlist)
{
longlist = longlist->next;
shortlist = shortlist->next;
}
// 返回交点节点
return longlist;
}题目九-随机链表的复制(来源)
题目描述
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码只接受原链表的头节点 head 作为传入参数。
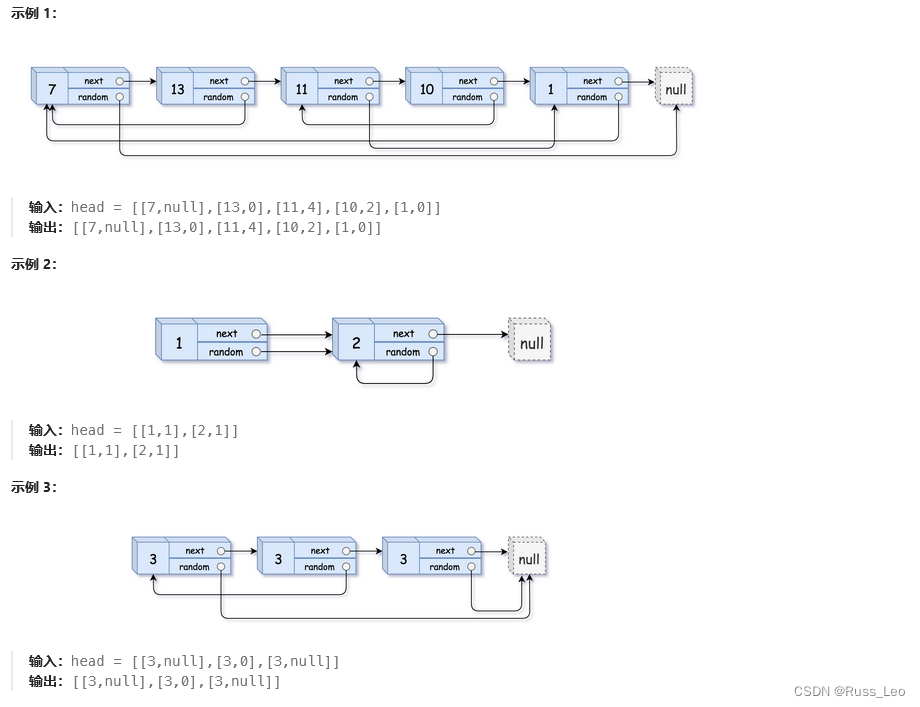
思路+实现
此题可以分三步进行:
1.拷贝链表的每一个节点,拷贝的节点先链接到被拷贝节点的后面
2.复制随机指针的链接:拷贝节点的随机指针指向被拷贝节点随机指针的下一个位置
3.拆解链表,把拷贝的链表从原链表中拆解出来
struct Node* copyRandomList(struct Node* head)
{
// 如果原始链表为空,则直接返回NULL
if (head == NULL) return NULL;
// 遍历原始链表,为每个节点创建副本并插入到原始链表中
struct Node* cur = head;
while(cur)
{
// 创建新节点并分配内存
struct Node* copy = (struct Node*)malloc(sizeof(struct Node));
// 将当前节点的值复制给新节点
copy->val = cur->val;
// 新节点的下一个节点指向当前节点的下一个节点
copy->next = cur->next;
copy->random = NULL; // 初始化新节点的随机指针为NULL
// 将新节点插入到原始链表中,作为当前节点的下一个节点
cur->next = copy;
// 移动到原始链表的下一个节点
cur = copy->next;
}
// 遍历原始链表,更新新节点的随机指针,使其指向复制链表中的对应节点
cur = head;
while(cur)
{
// 若当前节点的随机指针非空,则其副本节点的随机指针指向原始链表中对应节点的副本
if (cur->random != NULL)
cur->next->random = cur->random->next;
// 跳过已处理过的副本节点,移动到原始链表的下一个节点
cur = cur->next->next;
}
// 分离原始链表与复制链表
cur = head;
struct Node* copyhead = NULL, *copytail = NULL;
while(cur)
{
// 获取当前节点的副本
struct Node* copy = cur->next;
// 断开原始链表与副本节点的连接
cur->next = copy->next;
// 更新复制链表的链接关系
if (copyhead == NULL)
// 如果复制链表尚未开始,则设置头结点和尾结点均为该副本节点
copyhead = copytail = copy;
else
{
// 否则将当前尾结点的next指向副本节点,更新尾结点
copytail->next = copy;
copytail = copy;
}
// 移动到原始链表的下一个节点
cur = cur->next;
}
// 返回复制链表的头结点
return copyhead;
}





![【YOLOv8改进[Backbone]】使用MobileNetV3助力YOLOv8网络结构轻量化并助力涨点](https://img-blog.csdnimg.cn/direct/f4e46c4ccc8d4252ba4ba71cb80d1551.png)