目录
- 数值字段
- round
- Box/Bins
- 类别字段
- onehot
- LabelEncoder
- Ordinal Encoding
- BinaryEncoder
- Frequency/Count Encoding
- Mean/Target Encoding
- 日期字段
- 特征筛选
- feature_importances_
- 利用方差
- 利用相关性
- 利用线性模型
- 迭代消除
- 排列重要性(Permutation Importance)
特征工程决定了模型精度的上限。
特征工程是数据挖掘的主要工作内容:数据清洗、数据预处理、数据转换。
特征工程大概占据了60%-70%的时间。
数值字段

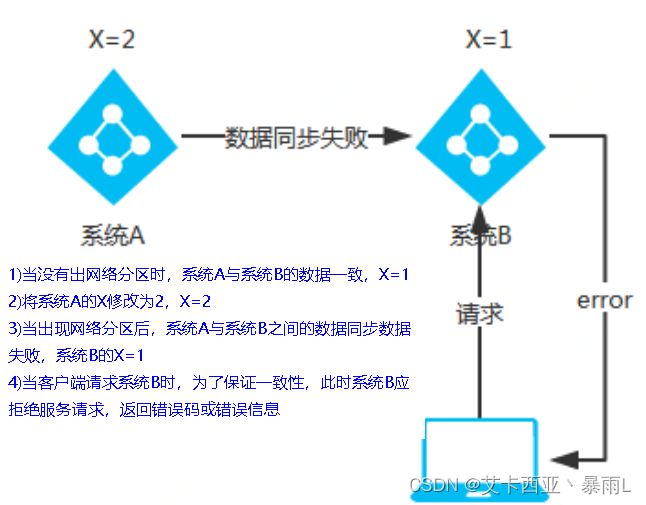
例子:
df = pd.DataFrame({
'student_id': [1,2,3,4,5,6,7],
'country': ['China', 'USA', 'UK', 'Japan', 'Korea', 'China', 'USA'],
'education': ['Master', 'Bachelor', 'Bachelor', 'Master', 'PHD', 'PHD', 'Bachelor'],
'age': [34.5, 28.9, 19.5, 23.6, 19.8, 29.8, 31.7],
'target': [1, 0, 1, 0, 1, 0, 1]
})
df.head(10)
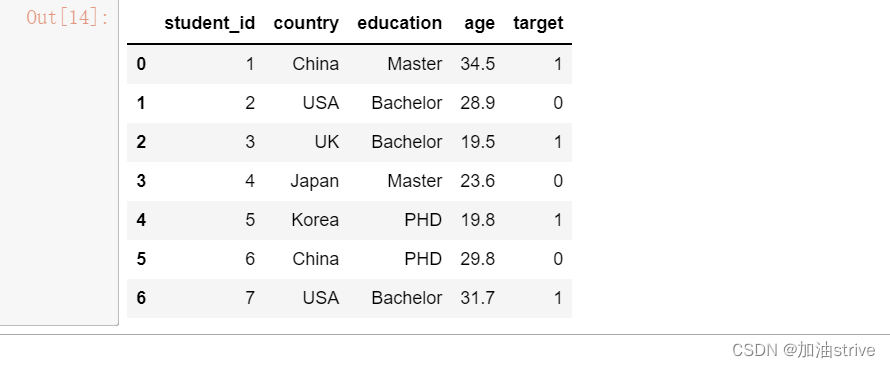
round
# 省略小数点
df['age_round1'] = df['age'].round()
# 按照区间进行分段 (实质是缩放)
df['age_round2'] = (df['age'] / 10).astype(int)
df.head(10)
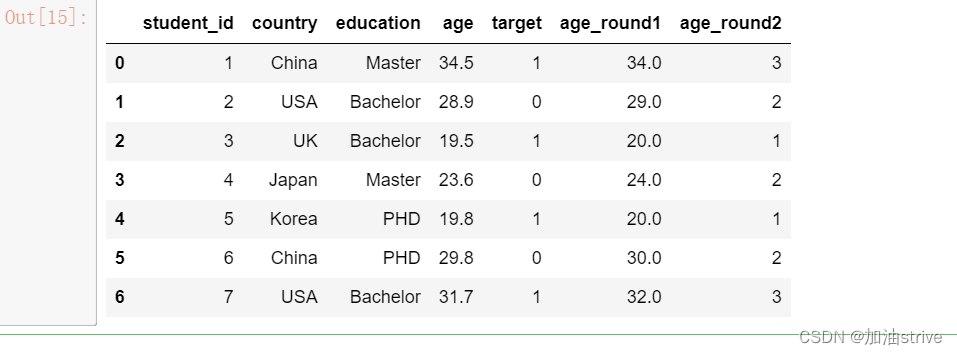
可以一定程度上忽略特殊值对模型的影响
Box/Bins
df['age_<20'] = (df['age'] <= 20).astype(int)
df['age_20-25'] = ((df['age'] > 20) & (df['age'] <=25)).astype(int)
df['age_20-25'] = ((df['age'] > 25) & (df['age'] <= 30)).astype(int)
df['age_>30'] = (df['age'] > 30).astype(int)
df.head(10)
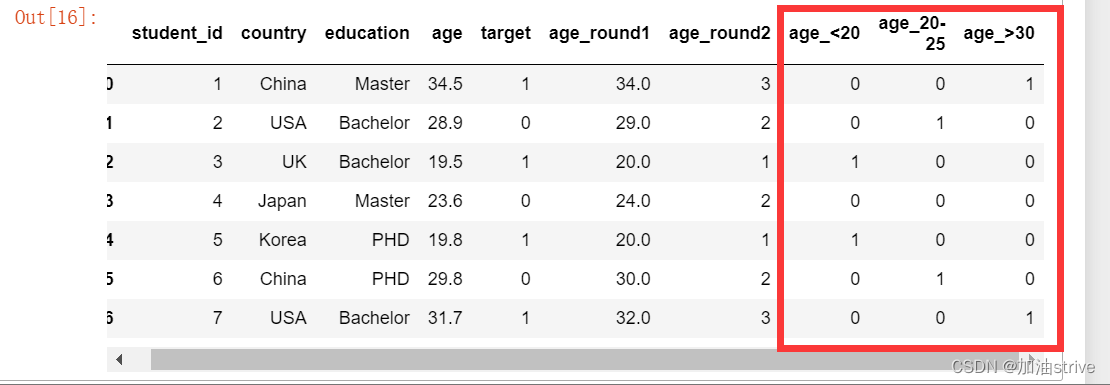
分箱,类似于one hot 编码
类别字段
类别字段是最常见的字段
主要分为两种:
- 一种是常规的类别字段
比如:①猫、狗、牛
②铅笔、钢笔、油笔 - 有次序性的类别字段
比如: ①专科、本科、博士
②(情感分析中)不好、一般、好

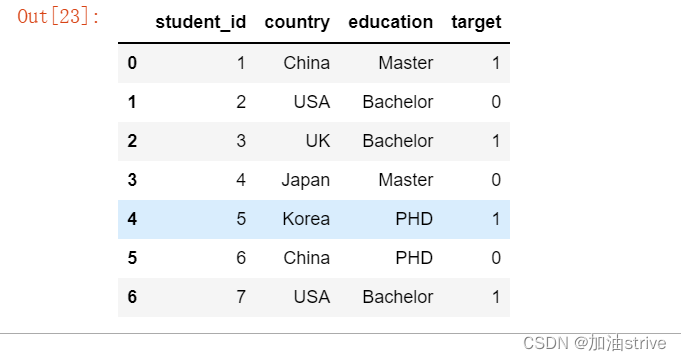
例子
假设数据如下:
df = pd.DataFrame({
'student_id': [1,2,3,4,5,6,7],
'country': ['China', 'USA', 'UK', 'Japan', 'Korea', 'China', 'USA'],
'education': ['Master', 'Bachelor', 'Bachelor', 'Master', 'PHD', 'PHD', 'Bachelor'],
'target': [1, 0, 1, 0, 1, 0, 1]
})
df.head(10)
onehot
pandas中get_dummies()函数是onehot编码
pd.get_dummies(df, columns=['education'])
# one-of-k
# 1 0 0
# 0 1 0
# 0 0 1
sklearn中封装的onehot编码
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder()
ohe.fit_transform(df[['education']]).toarray()

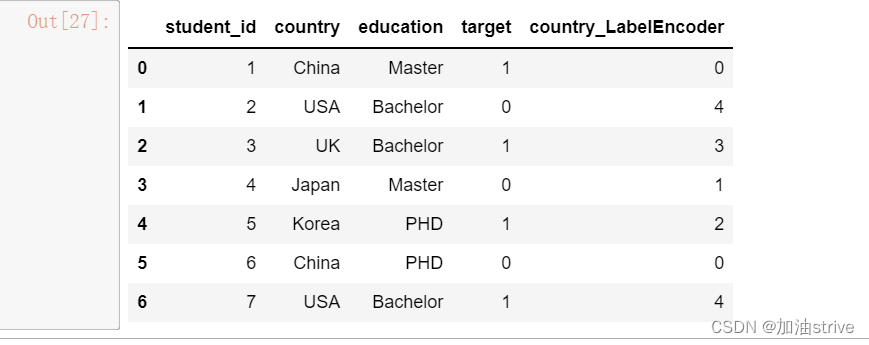
LabelEncoder
标签编码
优点:相比于onehot,没有增加太多的数据维度
缺点:编码后形成了大小关系
sklearn中的LabelEncoder
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['country_LabelEncoder'] = le.fit_transform(df['country'])
df.head(10)
pandas中的factorize()方法
df['country_LabelEncoder'] = pd.factorize(df['country'])[0]
df.head(10)

一个比较通用的方法:
遇到一个类别字段,如果它的取值空间个数<10,就用onehot;否则,就用LabelEncoder
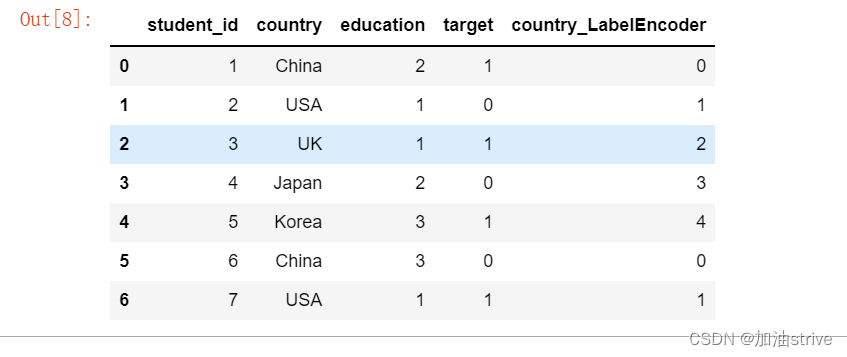
Ordinal Encoding
指定它的编码等级
df['education'] = df['education'].map(
{'Bachelor': 1,
'Master': 2,
'PHD': 3})
df.head(10)
BinaryEncoder
二进制编码,机组中的二进制编码
import category_encoders as ce
encoder = ce.BinaryEncoder(cols= ['country'])
pd.concat([df, encoder.fit_transform(df['country']).iloc[:, 1:]], axis=1)

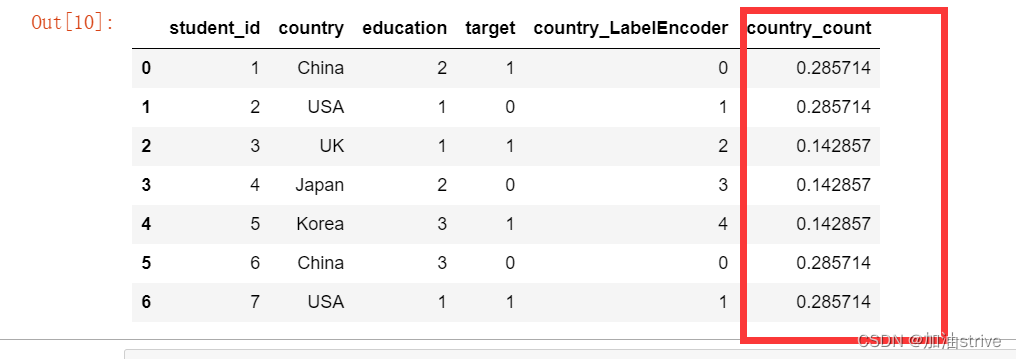
Frequency/Count Encoding
出现频率
df['country_count'] = df['country'].map(df['country'].value_counts()) / len(df)
df.head(10)
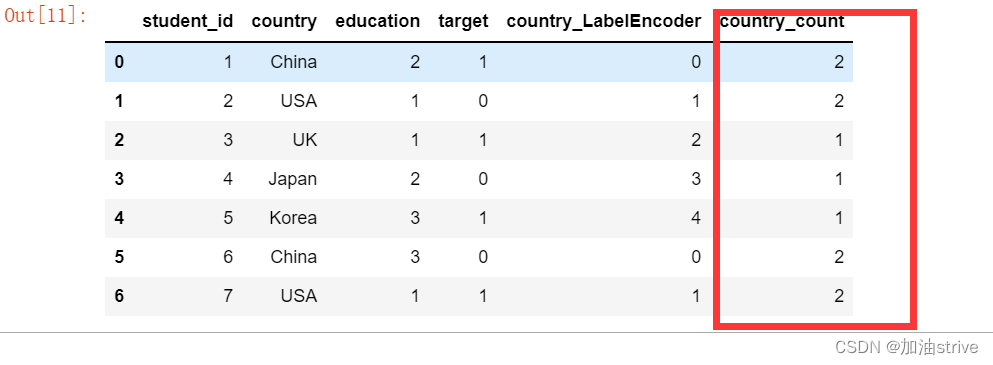
出现次数
df['country_count'] = df['country'].map(df['country'].value_counts())
df.head(10)
Mean/Target Encoding
目标编码
以目标值作为参照进行编码
df.groupby(['country'])['target'].mean()

解释: china 出现了两次,分别是0和1 ,均值就是0.5
df['country_target'] = df['country'].map(df.groupby(['country'])['target'].mean())
df.head(10)

优点:能够帮助模型更好的拟合
缺点:容易过拟合
使用训练集的target encoding对全部数据集进行编码,不能直接对验证集进行target encoding
日期字段

特征筛选
特征筛选方法,在比赛中,最实用的方法是:删除/添加一个字段,看看对模型精度是否产生影响,如果增加精度,就保留这个字段,如果精度减少,就删除这个字段。
基于统计值的特征筛选
- 字段方差:表示字段的波动范围,如果字段波动范围小,表示这个字段包含的信息量较少
- 字段缺失比例:缺失比例较多,60%以上,基本可以删除该特征
- 分布一致性:训练集和特征集的特征分布是否均衡,若不均衡,可以考虑删除该特征
- 离群点以及标签的相关性:比如用皮尔逊相关系数,以及杰卡德相关系数,来判断特征与标签的相关性。
基于模型的特征筛选
- 线性模型

- 树模型

- 某特征随机打散后,模型精度前后对比


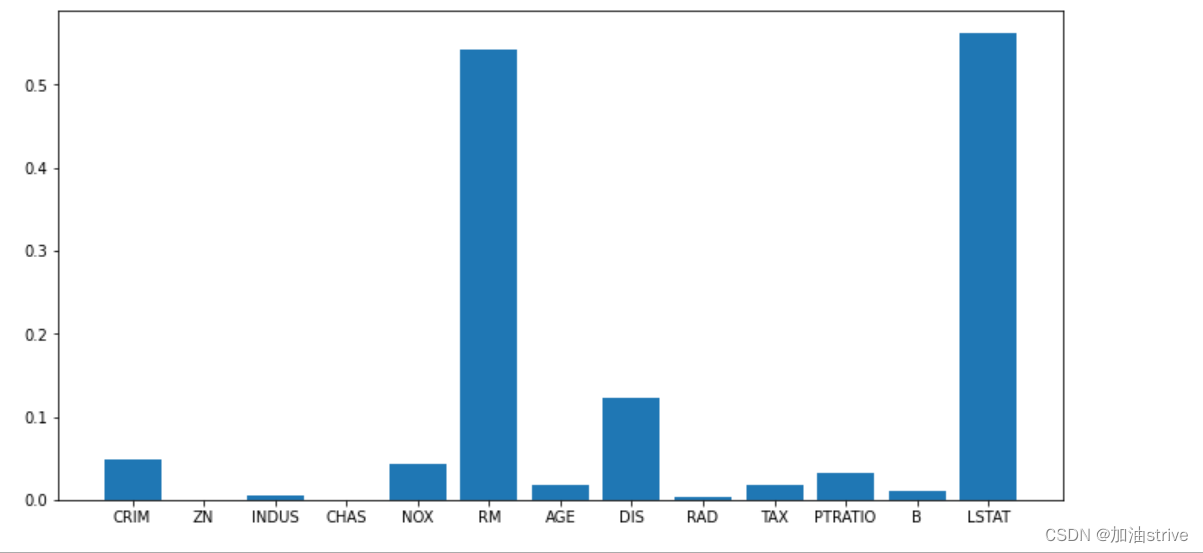
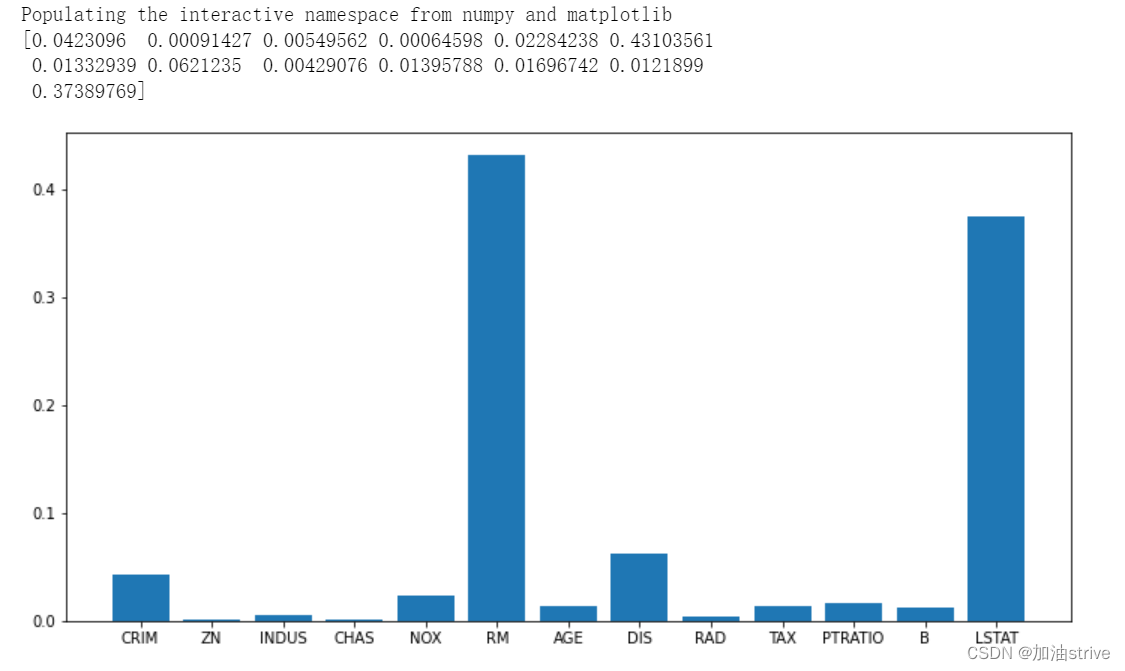
feature_importances_
随机森林回归器 feature_importances_
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import load_boston
data = load_boston()
rf = RandomForestRegressor()
rf.fit(data.data, data.target);
print(rf.feature_importances_)
plt.figure(figsize=(12, 6))
plt.bar(range(1, 14), rf.feature_importances_)
_ = plt.xticks(range(1, 14), data.feature_names)
lightgbm回归器 feature_importances_
import numpy as np
from lightgbm import LGBMRegressor
data = load_boston()
clf = LGBMRegressor()
clf.fit(data.data, data.target)
plt.figure(figsize=(12, 6))
plt.bar(range(1, 14), clf.feature_importances_)
_ = plt.xticks(range(1, 14), data.feature_names)

利用方差
from sklearn.feature_selection import VarianceThreshold
X = [[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]]
sel = VarianceThreshold(threshold=(.8 * (1 - .8)))
sel.fit_transform(X)
sel.fit_transform(data.data)
print(data.feature_names[~sel.get_support()])
print(data.feature_names)
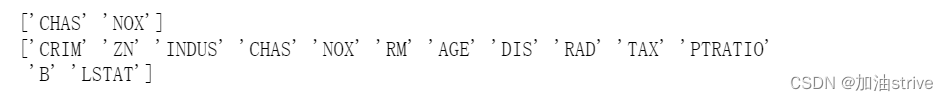
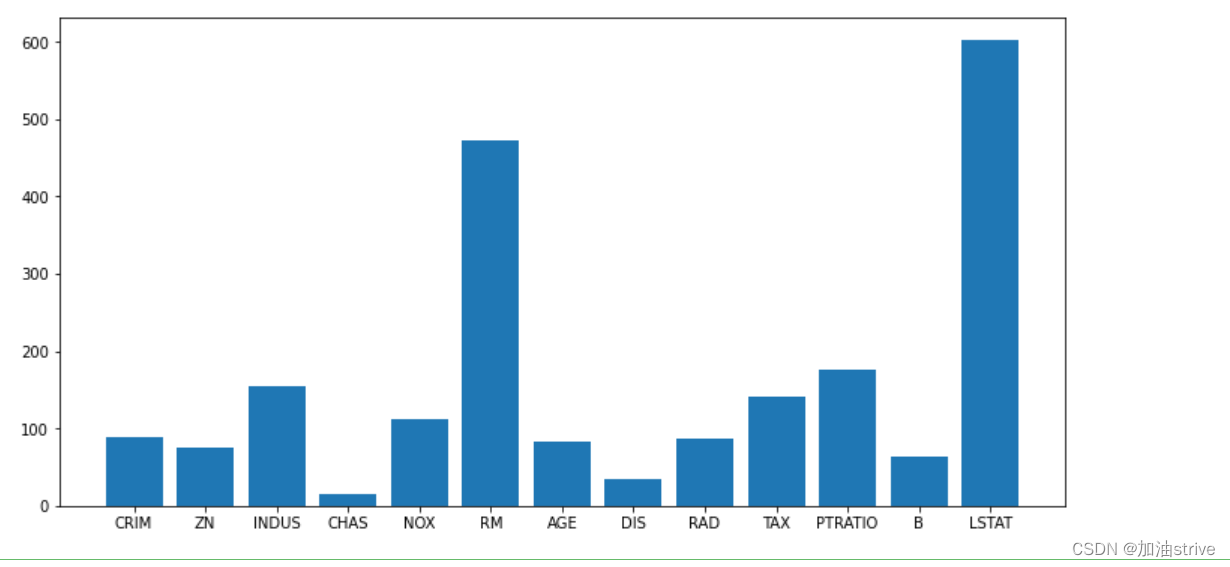
利用相关性
SelectKBest 、 f_regression
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
sel = SelectKBest(f_regression, k='all').fit(data.data, data.target)
sel.fit_transform(data.data, data.target)
print(data.feature_names)
print(sel.scores_)
plt.figure(figsize=(12, 6))
plt.bar(range(data.data.shape[1]), sel.scores_)
_ = plt.xticks(range(data.data.shape[1]), data.feature_names)
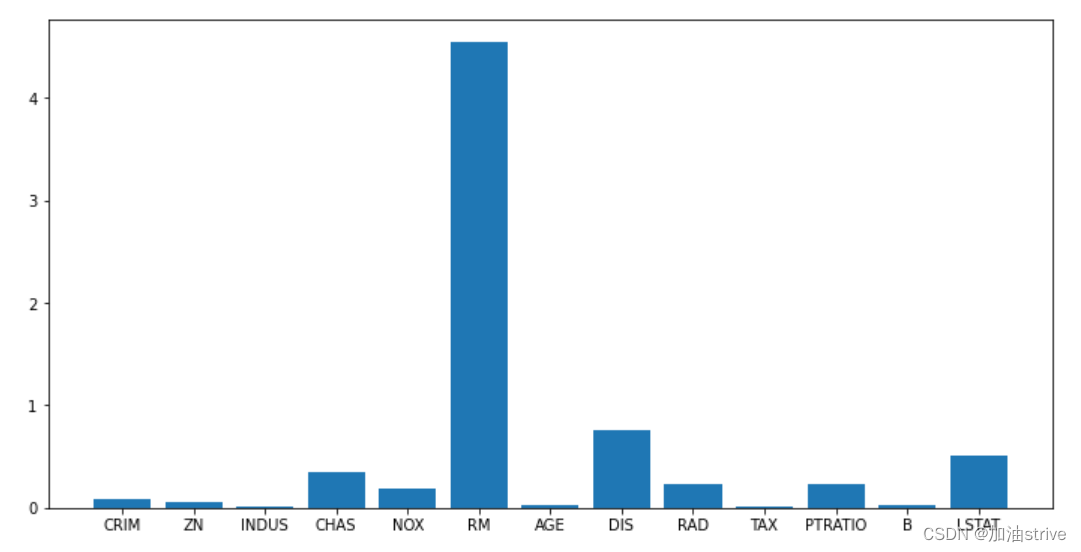
利用线性模型
线性模型的coef_
from sklearn.svm import LinearSVR
from sklearn.feature_selection import SelectFromModel
lsvc = LinearSVR().fit(data.data, data.target)
print(data.feature_names)
print(lsvc.coef_)
plt.figure(figsize=(12, 6))
plt.bar(range(data.data.shape[1]), np.abs(lsvc.coef_))
_ = plt.xticks(range(data.data.shape[1]), data.feature_names)
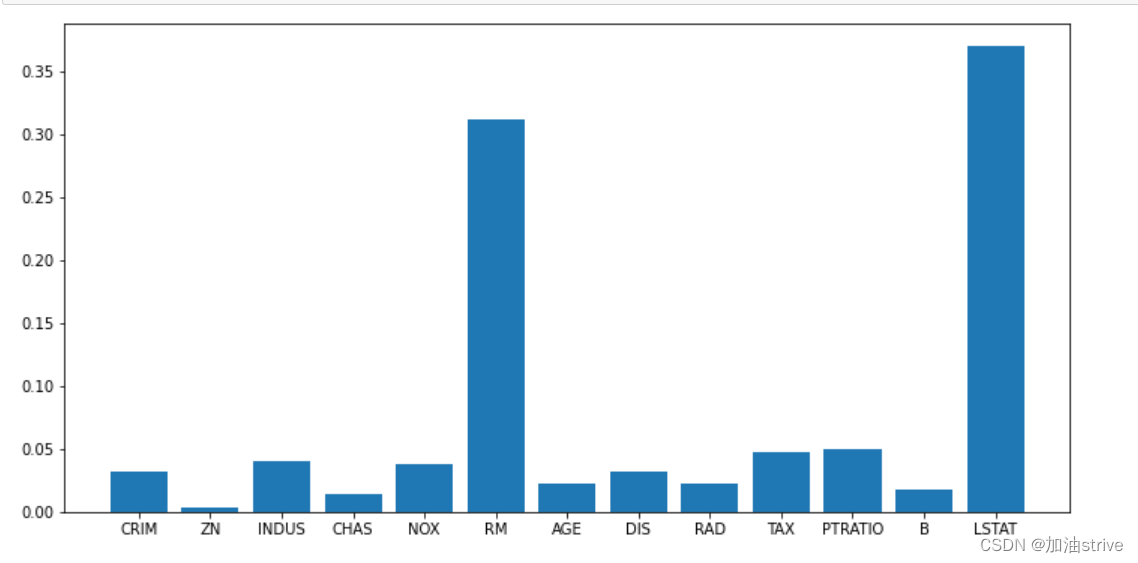
迭代消除
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.feature_selection import SelectFromModel
clf = ExtraTreesRegressor(n_estimators=50)
clf = clf.fit(data.data, data.target)
plt.figure(figsize=(12, 6))
plt.bar(range(data.data.shape[1]), clf.feature_importances_)
_ = plt.xticks(range(data.data.shape[1]), data.feature_names)
排列重要性(Permutation Importance)
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.inspection import permutation_importance
clf = RandomForestRegressor().fit(data.data, data.target)
result = permutation_importance(clf, data.data, data.target, n_repeats=10,
random_state=0)
result.importances_mean
plt.figure(figsize=(12, 6))
plt.bar(range(data.data.shape[1]), result.importances_mean)
_ = plt.xticks(range(data.data.shape[1]), data.feature_names)