文章目录
- 1、获取执行计划常用方法
- 1.1、使用AUTOTRACE查看执行计划
- 1.2、使用EXPLAIN PLAN FOR查看执行计划
- 1.3、查看带有A-TIME的执行计划
- 1.4、查看正在执行的SQL的执行计划
- 2、定制执行计划
- 3、怎么通过查看执行计划建立索引
- 4、运用光标移动大法阅读执行计划
SQL执行缓慢有很多原因,有时候是数据库本身原因,比如LATCH争用,或者某些参数设置不合理。有时候是SQL写法有问题,有时候是缺乏索引,可能是因为统计信息过期或者没收集直方图,也可能是优化器本身并不完善或者优化器自身BUG而导致的性能问题,还有可能是业务原因,比如要访问一年的数据,然而一年累计有数亿条数据,数据量太大导致SQL性能缓慢。
如果是数据库自身原因导致SQL缓慢,我们需要通过分析等待事件,做出相应处理。本贴侧重讨论单纯的SQL优化,因此更侧重于分析SQL写法,分析SQL的执行计划。
SQL调优就是通过各种手段和方法使优化器选择最佳执行计划,以最小的资源消耗获取到想要的数据。
1、获取执行计划常用方法
1.1、使用AUTOTRACE查看执行计划
我们利用SQLPLUS中自带的AUTOTRACE工具查看执行计划。AUTOTRACE用法如下:
SQL> set autot
Usage: SET AUTOT[RACE] {OFF | ON | TRACE[ONLY]} [EXP[LAIN]] [STAT[ISTICS]]
方括号内的字符可以省略。
- set autot on:该命令会运行SQL并且显示运行结果,执行计划和统计信息。
- set autot trace:该命令会运行SQL,但不显示运行结果,会显示执行计划和统计信息。
- set autot trace exp:运行该命令查询语句不执行,DML语句会执行,只显示执行计划。
- set autot trace stat:该命令会运行SQL,只显示统计信息。
- set autot off:关闭AUTOTRACE。
我们使用set autot on查看执行计划(基于Oracle11gR2,Scott账户)。
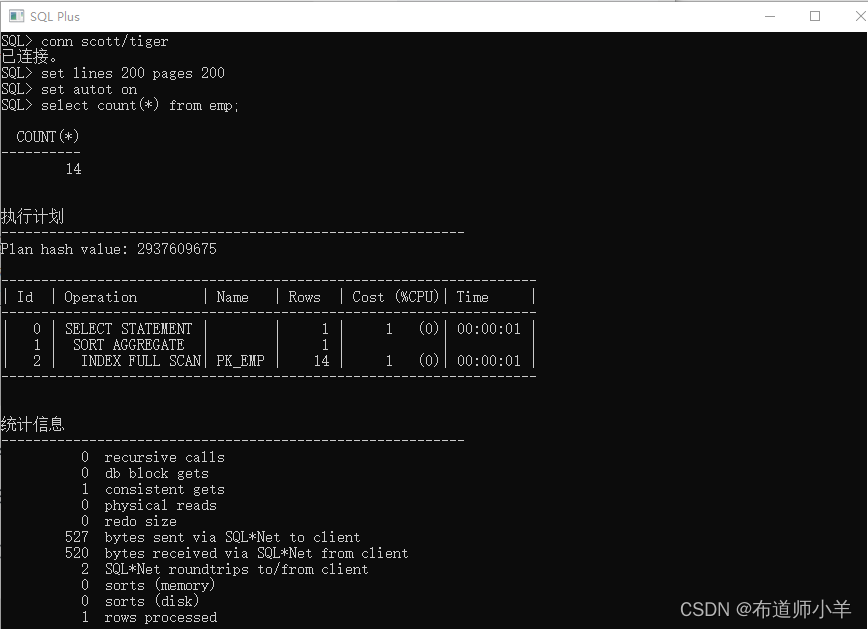
使用set autot on查看执行计划会输出SQL运行结果,如果SQL要返回大量结果,我们可以使用set autot trace查看执行计划,set autot trace不会输出SQL运行结果。

利用AUTOTRACE查看执行计划会带来一个额外的好处,当SQL执行完毕之后,会在执行计划的末尾显示SQL在运行过程中耗费的一些统计信息。
- ecursive calls表示递归调用的次数。一个SQL第一次执行就会发生硬解析,在硬解析的时候,优化器会隐含地调用一些内部SQL,因此当一个SQL第一次执行,recursive calls会大于0;第二次执行的时候不需要递归调用,recursive calls会等于0。
如果SQL语句中有自定义函数,recursive calls永远不会等于0,自定义函数被调用了多少次,recursive calls就会显示为多少次。
- db block gets表示有多少个块发生变化,一般情况下,只有DML语句才会导致块发生变化,所以查询语句中db block gets一般为0。如果有延迟块清除,或者SQL语句中调用了返回CLOB的函数,db block gets也有可能会大于0,不要觉得奇怪。
- consistent gets表示逻辑读,单位是块。在进行SQL优化的时候,我们应该想方设法减少逻辑读个数。通常情况下逻辑读越小,性能也就越好。需要注意的是,逻辑读并不是衡量SQL执行快慢的唯一标准,需要结合I/O等其他综合因素共同判断。
怎么通过逻辑读判断一个SQL还存在较大优化空间呢?如果SQL的逻辑读远远大于SQL语句中所有表的段大小之和(假设所有表都走全表扫描,表关联方式为HASH JOIN),那么该SQL就存在较大优化空间。
- physical reads表示从磁盘读取了多少个数据块,如果表已经被缓存在buffer cache中,没有物理读,physical reads等于0。
- redo size表示产生了多少字节的重做日志,一般情况下只有DML语句才会产生redo,查询语句一般情况下不会产生redo,所以这里redo size为0。如果有延迟块清除,查询语句也会产生redo。
- bytes sent via SQL*Net to client表示从数据库服务器发送了多少字节到客户端。
- bytes received via SQL*Net from client表示从客户端发送了多少字节到服务端。
- SQL*Net roundtrips to/from client表示客户端与数据库服务端交互次数,我们可以通过设置arraysize减少交互次数。
- sorts (memory)和sorts (disk)分别表示内存排序和磁盘排序的次数。
- rows processed表示SQL一共返回多少行数据。我们在做SQL优化的时候最关心这部分数据,因为可以根据SQL返回的行数判断整个SQL应该是走HASH连接还是走嵌套循环。如果rows processed很大,一般走HASH连接;如果rows processed很小,一般走嵌套循环。
1.2、使用EXPLAIN PLAN FOR查看执行计划
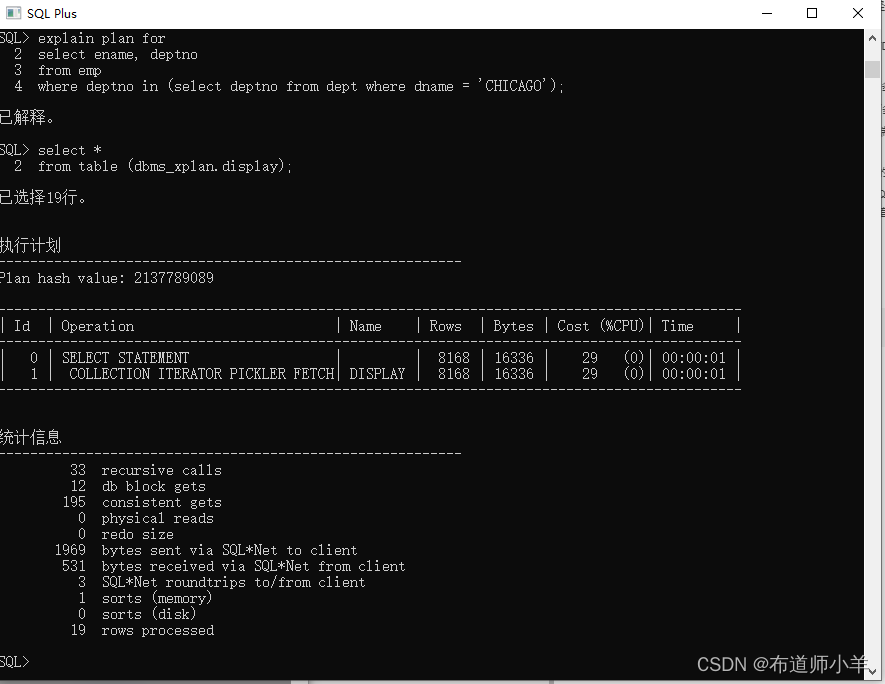
使用explain plan for查看执行计划,用法如下:
explain plan for SQL语句;
select * from table(dbms_xplan.display);
示例(Oracle11gR2,Scott账户)如下:
查看高级(ADVANCED)执行计划,用法如下:
explain plan for SQL语句;
select * from table(dbms_xplan.display(NULL, NULL, 'advanced -projection'));
示例(Oracle11gR2,Scott账户)如下:
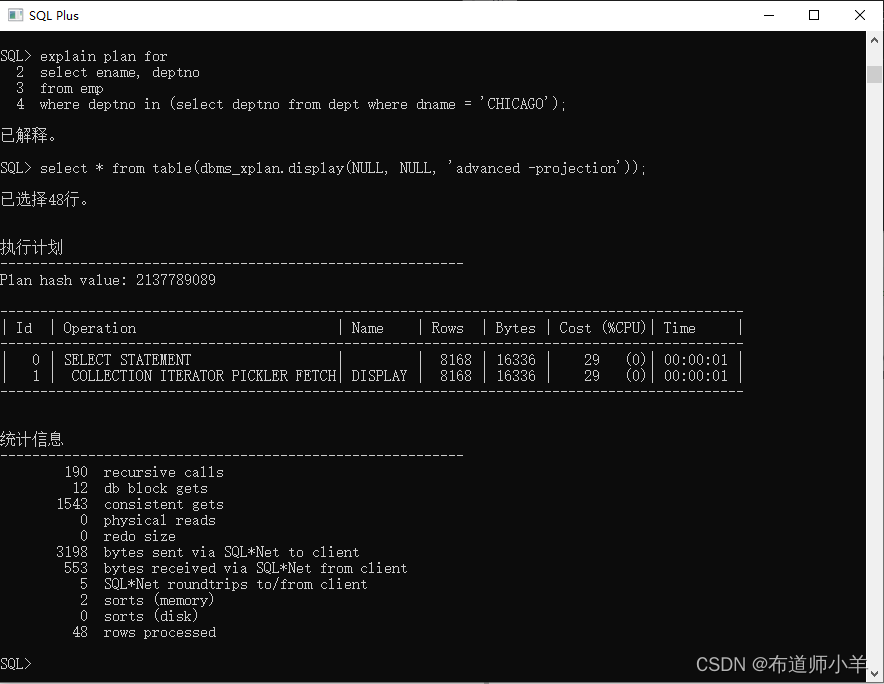
高级执行计划比普通执行计划多了Query Block Name /Object Alias和Outline Data。当需要控制半连接/反连接执行计划的时候,我们就可能需要查看高级执行计划。有时候我们需要使用SQL PROFILE固定执行计划,也可能需要查看高级执行计划。
Query Block Name表示查询块名称,Object Alias表示对象别名。Outline Data表示SQL内部的HINT。一条SQL语句可能会包含多个子查询,每个子查询在执行计划内部就是一个Query Block。为什么会有Query Block呢?比如一个SQL语句包含有多个子查询,假如每个子查询都要访问同一个表,不给表取别名,这个时候我们怎么区分表属于哪个子查询呢?所以Oracle会给同一个SQL语句中的子查询取别名,这个名字就是Query Block Name,以此来区分子查询中的表。Query Block Name默认会命名为SEL$1,SEL$2,SEL$3等,我们可以使用HINT:qb_name(别名)给子查询取别名。
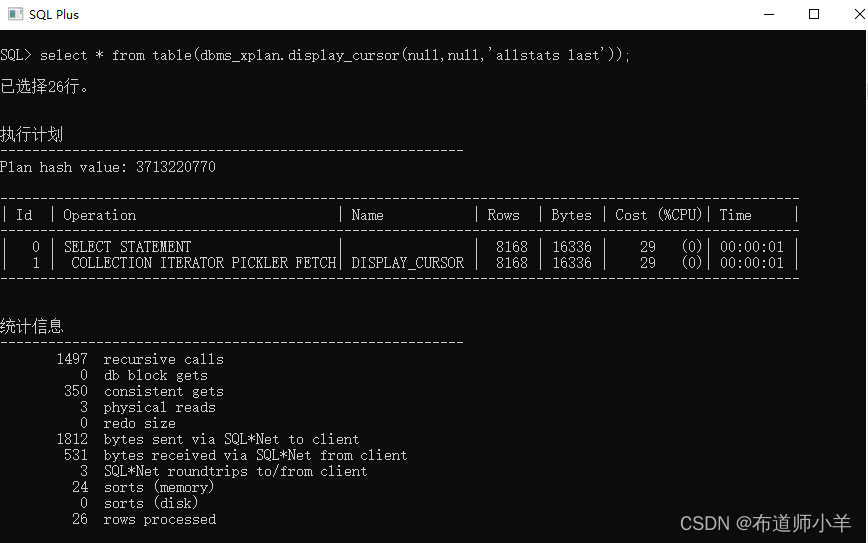
1.3、查看带有A-TIME的执行计划
查看带有A-TIME的执行计划的用法如下:
alter session set statistics_level=all;
或者在SQL语句中添加hint:/ *+ gather_plan_statistics */
运行完SQL语句,然后执行下面的查询语句就可以获取带有A-TIME的执行计划:
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
1.4、查看正在执行的SQL的执行计划
有时需要抓取正在运行的SQL的执行计划,这时我们需要获取SQL的SQL_ID以及SQL的CHILD_NUMEBR,然后将其代入下面SQL,就能获取正在运行的SQL的执行计划。
select * from table(dbms_xplan.display_cursor('sql_id',child_number));
示例(Oracle11gR2,Scott账户)如下,先创建两个测试表a,b:
create table a as select * from dba_objects;
create table b as select * from dba_objects;
然后在一个会话中执行如下SQL:
select count(*) from a,b where a.owner=b.owner;
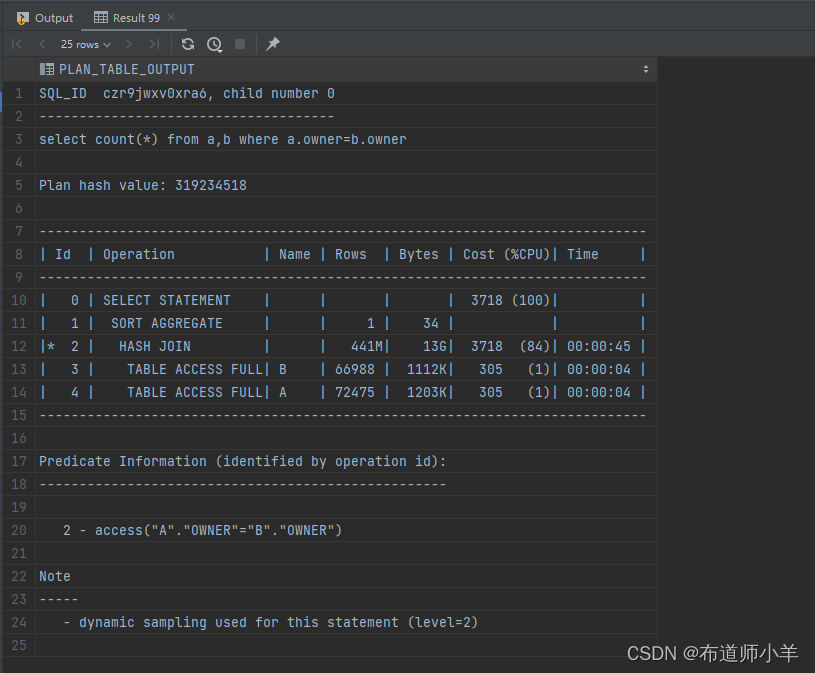
在另外一个会话中执行如下SQL,结果如下图所示:
select a.sid, a.event, a.sql_id, a.sql_child_number, b.sql_text
from v$session a, v$sql b
where a.sql_address = b.address
and a.sql_hash_value = b.hash_value
and a.sql_child_number = b.child_number
order by 1 desc;
接下来我们将SQL_ID和CHILD_NUMBER代入以下SQL:
select * from table(dbms_xplan.display_cursor('czr9jwxv0xra6',0));
2、定制执行计划
在Oracle数据库中,执行计划是树形结构,因此我们可以利用树形查询来定制执行计划。
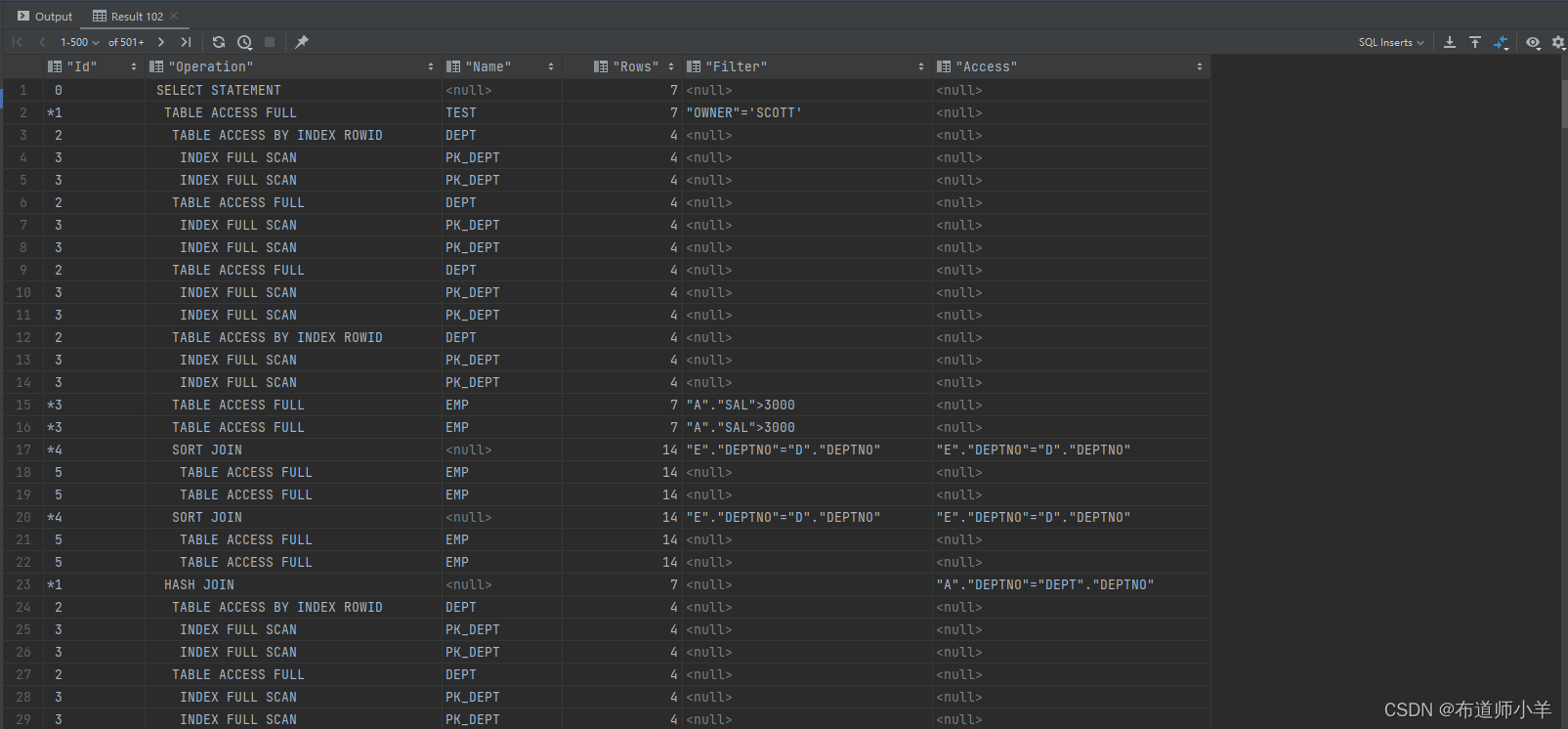
我们打开PLSQL dev SQL窗口,登录示例账户Scott并且运行如下SQL:
explain plan for
select /*+ use_hash(a,dept) */ *
from emp a,
dept
where a.deptno = dept.deptno
and a.sal > 3000;
然后执行下面的脚本,结果如下图所示:
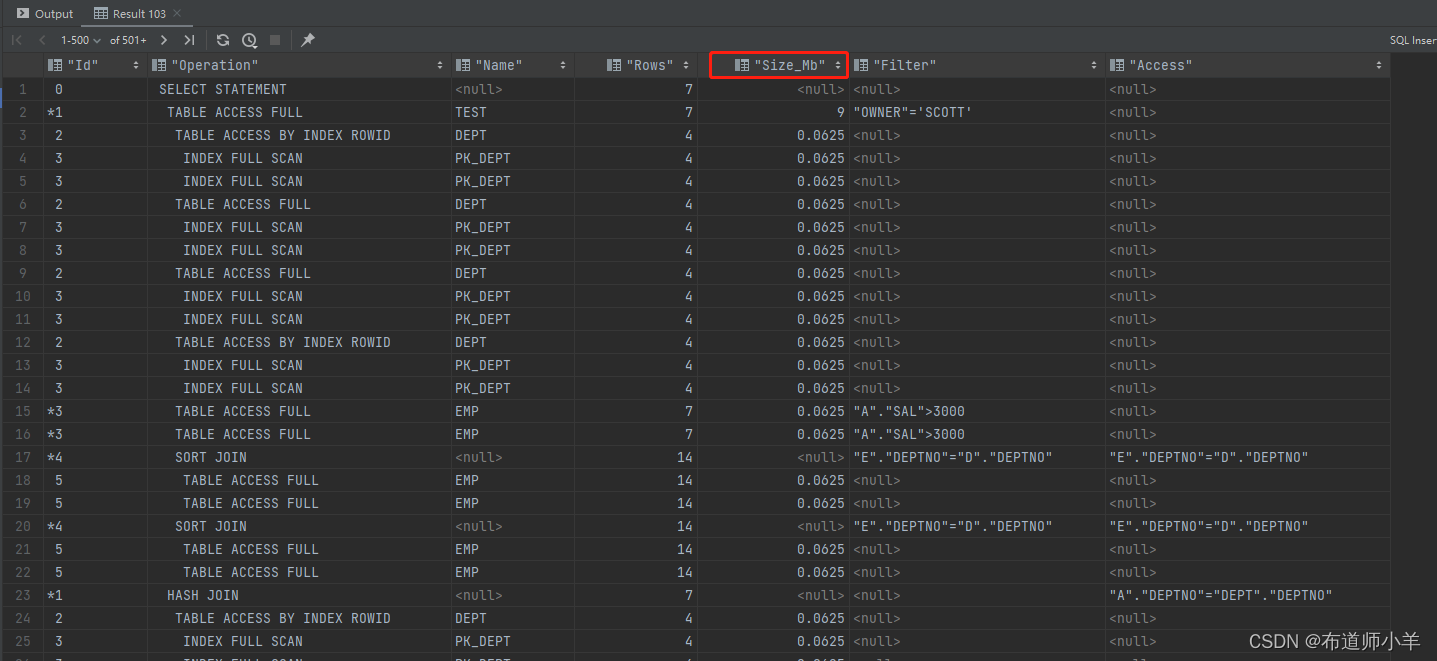
只有大表才会产生性能问题,因此可以将表的段大小添加到定制执行计划中,这样我们在用定制执行计划优化SQL的时候,可以很方便地知道表大小,从而更快地判断该步骤是否可能是性能瓶颈。下面脚本添加表的段大小以及索引段大小到定制执行计划中,结果如下图所示:
select case
when (filter_predicates is not null or
access_predicates is not null) then
'*'
else
' '
end || id as "Id",
lpad(' ', level) || operation || ' ' || options "Operation",
object_name "Name",
cardinality as "Rows",
b.size_mb "Size_Mb",
filter_predicates "Filter",
access_predicates "Access"
from plan_table a,
(select owner, segment_name, sum(bytes / 1024 / 1024) size_mb
from dba_segments
group by owner, segment_name) b
where a.object_owner = b.owner(+)
and a.object_name = b.segment_name(+)
start with id = 0
connect by prior id = parent_id;
建立组合索引避免回表或者建立合适的组合索引减少回表次数。如果一个SQL只访问了某个表的极少部分列,那么我们可以将这些被访问的列联合在一起,从而建立组合索引。
下面脚本将添加表的总字段数以及被访问字段数量到定制执行计划中,结果如下图所示:
select case
when access_predicates is not null or filter_predicates is not null then
'*' || id
else
' ' || id
end as "Id",
lpad(' ', level) || operation || ' ' || options "Operation",
object_name "Name",
cardinality "Rows",
b.size_mb "Mb",
case
when object_type like '%TABLE%' then
REGEXP_COUNT(a.projection, ']') || '/' || c.column_cnt
end as "Column",
access_predicates "Access",
filter_predicates "Filter",
case
when object_type like '%TABLE%' then
projection
end as "Projection"
from plan_table a,
(select owner, segment_name, sum(bytes / 1024 / 1024) size_mb
from dba_segments
group by owner, segment_name) b,
(select owner, table_name, count(*) column_cnt
from dba_tab_cols
group by owner, table_name) c
where a.object_owner = b.owner(+)
and a.object_name = b.segment_name(+)
and a.object_owner = c.owner(+)
and a.object_name = c.table_name(+)
start with id = 0
connect by prior id = parent_id;
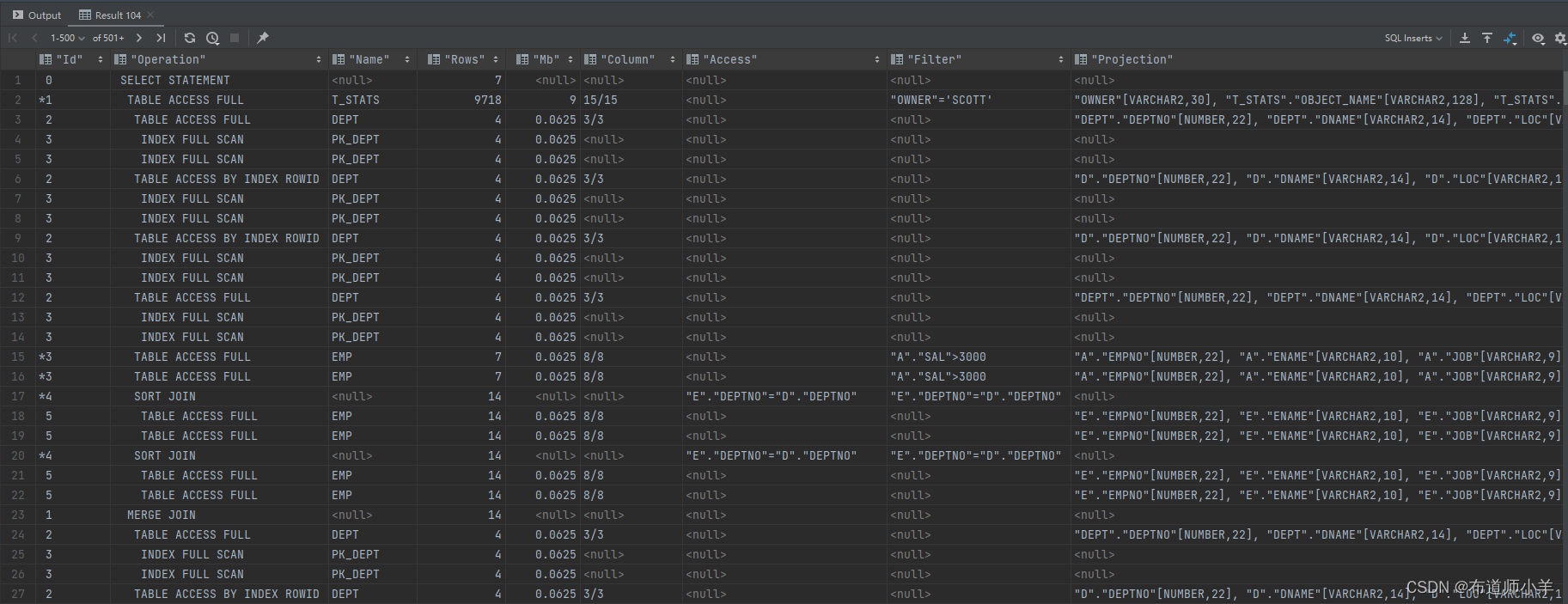
Column表示访问了表多少列/表一共有多少列。Projection显示了具体的访问列信息。
3、怎么通过查看执行计划建立索引
利用如下SQL讲解(基于Oracle11gR2 scott)。
explain plan for select e.ename,e.job,d.dname from emp e,dept d where e.deptno=d.deptno and e.sal<2000;
select * from table(dbms_xplan.display);
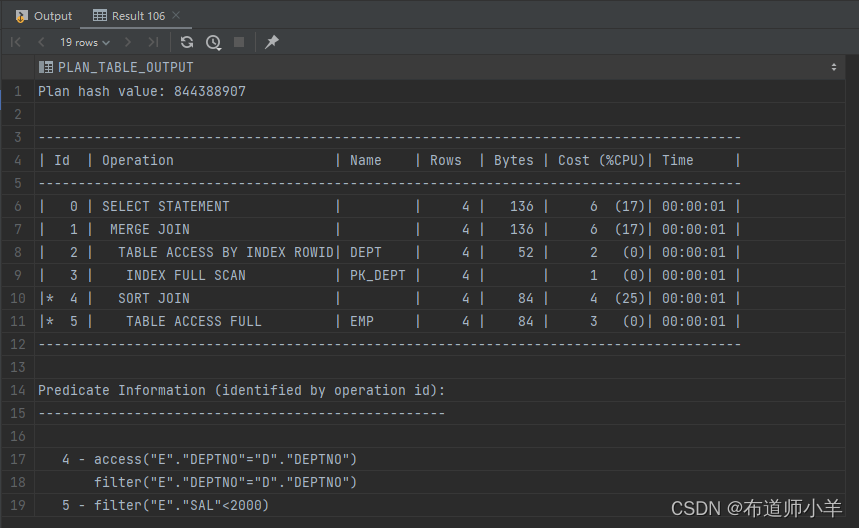
执行计划分为两部分,Plan hash value和Predicate Information之间这部分主要是表的访问路径以及表的连接方式。另外一部分是谓词过滤信息,这部分信息位于Predicate Information下面,谓词过滤信息非常重要。一些老DBA因为之前接触的是Oracle8i或者Oracle9i,那个时候执行计划还没有谓词信息,所以就遗留了一个传统,看执行计划只看访问路径和表连接方式了,而不关心谓词过滤信息。还有些人做SQL优化喜欢用10 046 trace 或者10 053 trace,如果仅仅是优化一个SQL,根本就不需要使用上面两个工具,直接分析SQL语句以及执行计划即可。当然,如果是为了深入研究为什么不走索引,为什么走了嵌套循环而没走HASH连接等,这个时候我们可以用10 053 trace;如果想研究访问路径是单块读或者是多块读,可以使用10 046 trace。
注意观察Id这列,有些Id前面有“*”号,这表示发生了谓词过滤,或者发生了HASH连接,或者是走了索引。
提问:TABLE ACCESS FULL前面没有“*”号怎么办?
回答:如果表很小,那么不需理会,小表不会产生性能问题。如果表很大,那么我们要询问开发人员是不是忘了写过滤条件,当然了一般也不会遇到这种情况。如果真的是没过滤条件呢?比如一个表有10GB,但是没有过滤条件,那么它就会成为整个SQL的性能瓶颈。这个时候我们需要查看SQL语句中该表访问了多少列,如果访问的列不多,就可以把这些列组合起来,建立一个组合索引,索引的大小可能就只有1GB左右。我们利用INDEX FAST FULL SCAN代替TABLE ACCESS FULL。在访问列不多的情况,索引的大小(Segment Size)肯定比表的大小(Segment Size)小,那么就不需要扫描10GB了,只需要扫描1GB,从而达到优化目的。如果SQL语句里面要访问表中大部分列,这时就不应该建立组合索引了,因为此时索引大小比表更大,可以通过其他方法优化,比如开启并行查询,或者更改表连接方式,让大表作为嵌套循环的被驱动表,同时在大表的连接列上建立索引。
提问:TABLE ACCESS FULL前面有“*”号怎么办?
回答:如果表很小,那么我们不需理会;如果表很大,可以使用“select count() from表”,查看有多少行数据,然后通过“select count() from表where *”对应的谓词过滤条件,查看返回多少行数据。如果返回的行数在表总行数的5%以内,我们可以在过滤列上建立索引。如果已经存在索引,但是没走索引,这时我们要检查统计信息,特别是直方图信息。如果统计信息已经收集过了,我们可以用HINT强制走索引。如果有多个谓词过滤条件,我们需要建立组合索引并且要将选择性高的列放在前面,选择性低的列在后面。如果返回的行数超过表总行数的5%,这个时候我们要查看SQL语句中该表访问了多少列,如果访问的列少,同样可以把这些列组合起来,建立组合索引,建立组合索引的时候,谓词过滤列在前面,连接列在中间,select部分的列在最后。如果访问的列多,这个时候就只能走全表扫描了。
提问:TABLE ACCESS BY INDEX ROWID前面有“*”号怎么办?
回答:TABLE ACCESS BY INDEX ROWID前面有“”号,表示回表再过滤。回表再过滤说明数据没有在索引中过滤干净。当TABLE ACCESS BY INDEX ROWID前面有“”号时,可以将“*”号下面的过滤条件包含在索引中,这样可以减少回表次数,提升查询性能。
4、运用光标移动大法阅读执行计划
执行计划中,最需要关心的有Id,Operation,Name,Rows:
- 看Id是为了观察Id前面是否有“*”号。
- Operation表示表的访问路径或者连接方式。
- Name是SQL语句中对象的名字,可以是表名、索引名、视图名、物化视图名或者CBO自动生成的名字。
- Rows是CBO根据统计信息以及数学公式计算出来的,也就是说Rows是假的,不是真实的。这里的Rows也被称作执行计划中返回的基数。再一次强调,Rows是假的,别被它骗了。前面介绍过带有A-Time的执行计划,带有A-Time的执行计划中E-Rows就是普通执行计划中的Rows,A-Rows才是真实的。在进行SQL优化的时候,我们经常需要手工计算某个访问路径的真实Rows,然后对比执行计划中的Rows。如果手工计算的Rows与执行计划中的Rows相差很大,执行计划往往就出错了。
有些人可能还会特意查看执行计划中的Cost,在进行SQL优化的时候,千万别看Cost!如果一个SQL语句都需要优化了,那么它的Cost还是准确的吗?有很大概率算错了!既然算错了,你还去看错误的Cost干什么呢?
下面我们将为大家介绍如何利用光标移动大法阅读执行计划。现有如下执行计划:
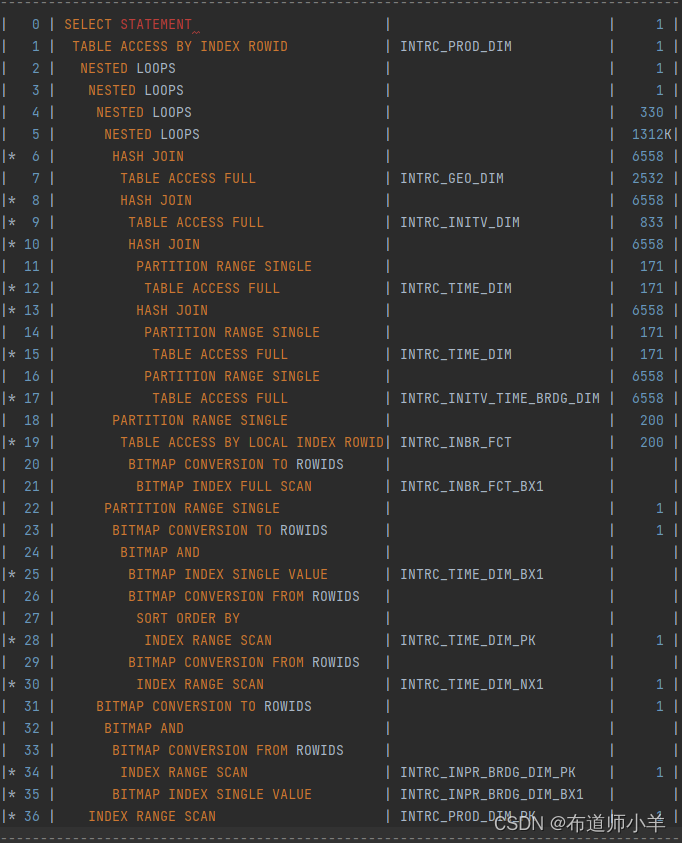
有些人可能会认为Id=15最先执行,因为Id=15的缩进最大,其实这是错误的。
现在给大家介绍一种方法:光标移动大法。光标就是我们打字的时候,鼠标点到某个地方,闪烁的光标。阅读执行计划的时候,一般从上往下看,找到执行计划的入口之后,再往上看。
阅读执行计划的时候,我们将光标移动到Id=0 SELECT的S前面,然后按住键盘的向下移动的箭头,向下移动,然后向右移动,然后再向下,再向右……Id=0和Id=1相差一个空格(缩进),上下相差一个空格(缩进)就是父子关系,上面的是父亲,下面的是儿子,儿子比父亲先执行。那么这里Id=1是Id=0的儿子,Id=1先执行。Id=2是Id=1的儿子,Id=2先执行。Id=3是Id=2的儿子,Id=3先执行。这样我们一直将光标移动到Id=7(向下,向右移动),Id=7与Id=8对齐,表示Id=7与Id=8是兄弟关系,上面的是兄,下面的是弟,兄优先于弟先执行,也就是说Id=7先于Id=8执行。Id=7也跟Id=19、Id=24、Id=34对齐,将光标移动到Id=7前面,向下移动光标,Id=19在Id=18的下面,光标移动大法是不能“穿墙”的,从Id=7移动到Id=19会穿过Id=18,同理Id=24、Id=34也“穿墙”了,因此Id=7只是和Id=8对齐。因为Id=7下面没有儿子,所以执行计划的入口是Id=7,整个执行计划中Id=7最先执行。
提问:怎么快速找到执行计划的入口?
回答:我们可以利用光标移动大法,先将光标放在Id=0这一步,然后一直向下向右移动光标,直到找到没有儿子的Id,这个Id就是执行计划的入口。
提问:怎么判断是哪个表与哪个表进行关联的?
回答:我们先找到表在执行计划中的Id,然后看这个Id(或者是这个Id的父亲)与谁对齐(利用光标上下移动),它与谁对齐,就与谁进行关联。比如Id=17这个表,它本身没有和任何Id对齐,但是Id=17的父亲是Id=16,与Id=14对齐,Id=14的儿子是Id=15,所以Id=17这个表是与Id=15这个表进行关联的,并且两个表是进行HASH连接的。
提问:在SQL优化实战中,怎么应用光标移动大法优化SQL?
回答:例如,有如下执行计划:
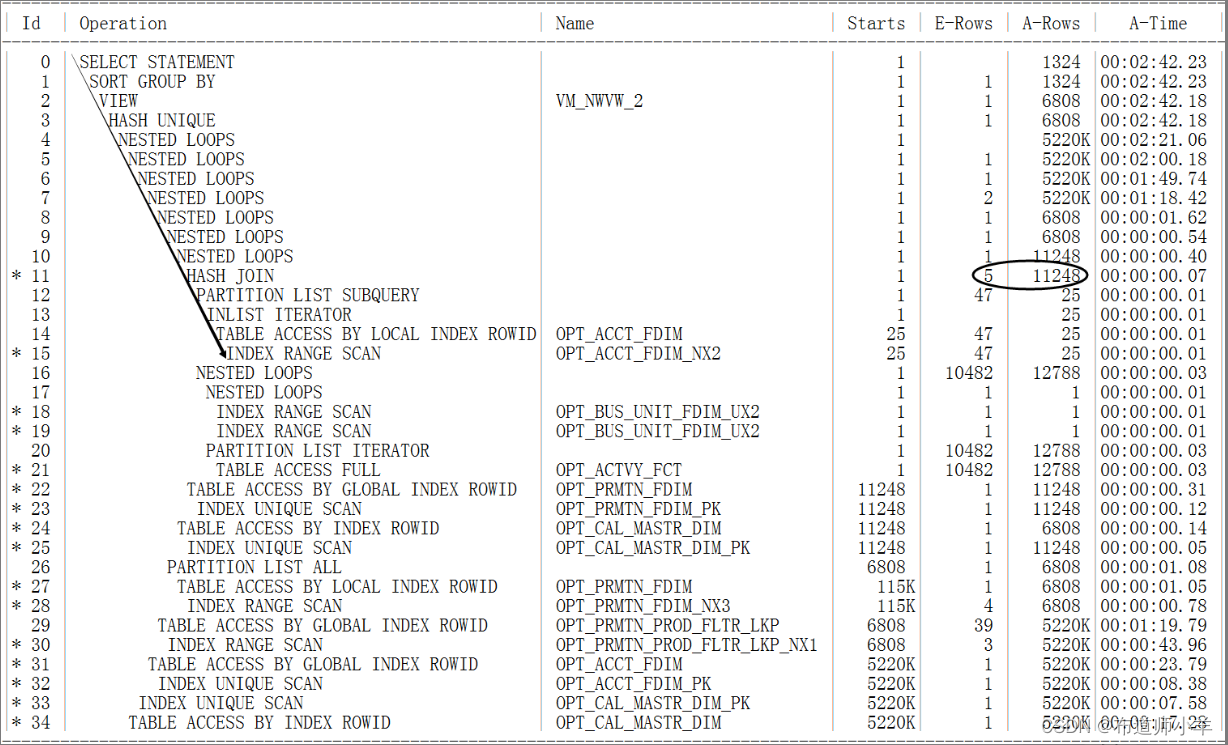
如果是SQL优化初学者(高手可以一眼看出执行计划哪里有性能问题),可以先利用光标移动大法找到执行计划入口,检查入口Rows返回的真实行数与CBO估算的行数是否存在较大差异。比如,这里执行计划入口为Id=15,优化器估算返回47行(E-Rows=47),实际上返回了25行(A-Rows=25),E-Rows与A-Rows差别不大。找到执行计划入口之后,我们应该从执行计划入口往上检查,Id=15上面的是Id=14,Id=14上面的是Id=13,这样一直检查到Id=11。Id=11估算返回5行(E-Rows=5),但是实际上返回了11 248行(A-Rows=11248),所以执行计划Id=11这步有问题,由于Id=11 Rows估算错误,它会导致后面整个执行计划出错,应该想办法让CBO估算出较为准确的Rows。
我们还可以利用光标移动大法找出哪个表与哪个表进行关联的,例如下面执行计划:
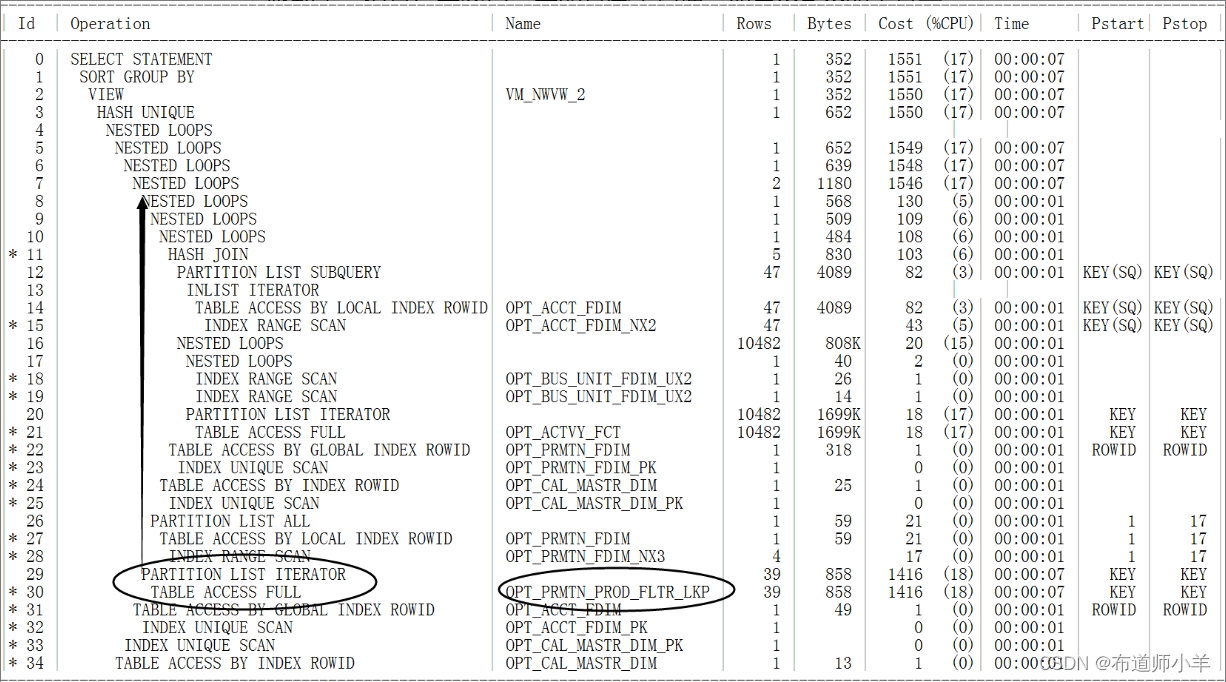
Id=29的表它与Id=8对齐,这表示Id=29的表是与一个结果集进行关联的,关联方式为嵌套循环(Id=7,NESTED LOOPS)。从执行计划中我们可以看到Id=29是嵌套循环的被驱动表,但是没走索引,走的是全表扫描。如果Id=29的表是一个大表,会出现严重的性能问题,因为它会被扫描多次,而且每次扫描的时候都是全表扫描,所以,我们需要在Id=29的表中创建一个索引(连接列上创建索引)。