文章目录
- 一、deepspeed是什么?
- 二、能训多大的模型,耗时如何?
- 三、RLHF训练流程
- 四、通信策略
一、deepspeed是什么?
传统的深度学习,模型训练并行,是将模型参数复制多份到多张GPU上,只将数据拆分(如,torch的Dataparallel),这样就会有大量的显存冗余浪费。而ZeRO就是为了消除这种冗余,提高对memory的利用率。注意,这里的“memory”不仅指多张GPU memory,还包括CPU。
而ZeRO的实现方法,就是把参数占用,逻辑上分成三种类型。将这些类型的参数划分:
optimizer states:即优化器的参数状态。例如,Adam的动量参数。
gradients:梯度缓存,对应于optimizer。
parameters:模型参数。
对应的,DeepSpeed的ZeRO config文件就可以分为如下几类:
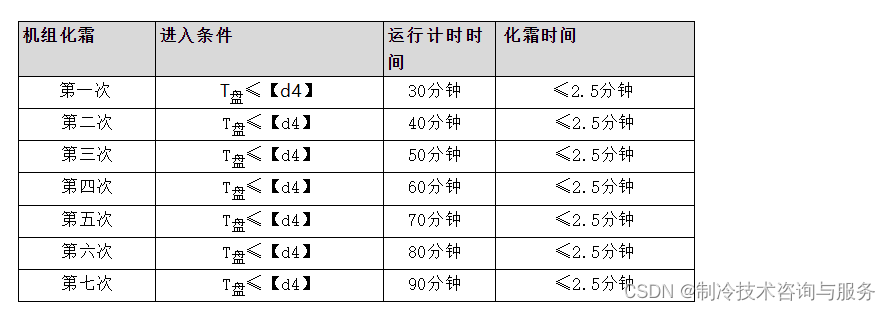
ZeRO Stage 1: 划分optimizer states。优化器参数被划分到多个memory上,每个memory上的进程只负责更新它自己那部分参数。
ZeRO Stage 2: 划分gradient。每个memory,只保留它分配到的optimizer state所对应的梯度。这很合理,因为梯度和optimizer是紧密联系在一起的。只知道梯度,不知道optimizer state,是没有办法优化模型参数的。
ZeRO Stage 3: 划分模型参数,或者说,不同的layer. ZeRO-3会在forward和backward的时候,自动将模型参数分配到多个memory。
由于ZeRO-1只分配optimizer states(参数量很小),实际使用的时候,我们一般只会考虑ZeRO-2和ZeRO-3。
二、能训多大的模型,耗时如何?
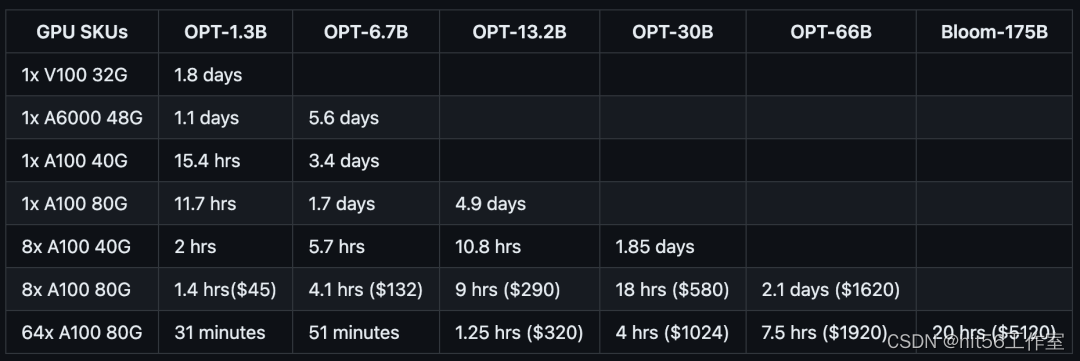
针对不同规模的模型和硬件配置,DeepSpeed-RLHF系统所需的时间和成本如下:
三、RLHF训练流程
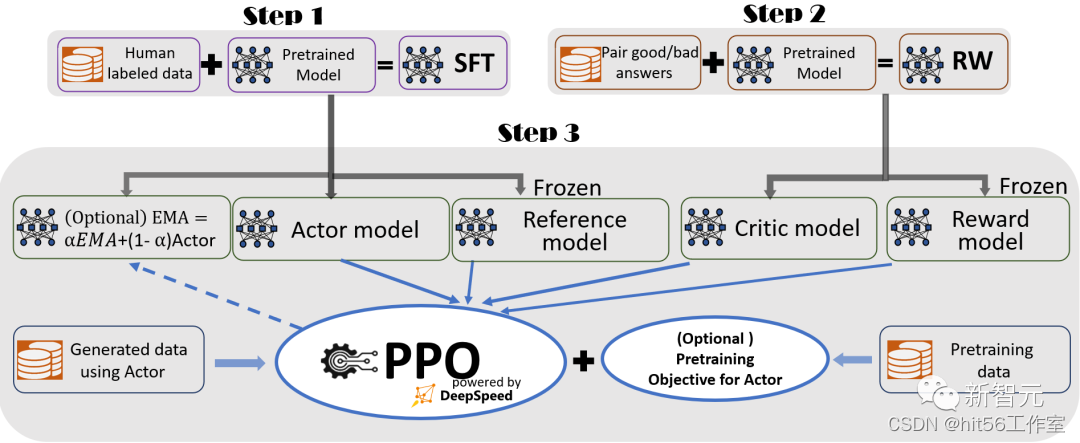
流程包括三个主要步骤:
第 1 步:监督微调 (SFT),使用精选的人类回答来微调预训练的语言模型,以应对各种查询。
第 2 步:奖励模型微调,用一个包含人类对同一查询的多个答案打分的数据集,来训练一个独立的(通常比SFT小)奖励模型(RW)。
第 3 步:RLHF训练,在这一步,SFT模型通过使用近似策略优化(PPO)算法,从RW模型的奖励反馈进一步微调。
在步骤3中,研究者还提供了两个附加功能,来帮助提高模型质量:
- 指数移动平均线(EMA)的收集,可以选择一个基于EMA的检查点,进行最终评估。
- 混合训练,将预训练目标(即下一个词预测)与 PPO 目标混合,以防止在公共基准(如SQuAD2.0)上的性能回归。
四、通信策略
DeepSpeed提供了mpi、gioo、nccl等通信策略
| 通信策略 | 通信作用 |
|---|---|
| mpi | 它是一种跨界点的通信库,经常用于CPU集群的分布式训练 |
| gloo | 它是一种高性能的分布式训练框架,可以支持CPU或者GPU的分布式训练 |
| nccl | 它是nvidia提供的GPU专用通信库,广泛用于GPU上的分布式训练 |
我们在使用DeepSpeed进行分布式训练的时候,可以根据自身的情况选择合适的通信库,通常情况下,如果是GPU进行分布式训练,可以选择nccl。