论文标题:SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments
论文地址:https://arxiv.org/pdf/2309.04077.pdf
项目地址:https://www.sri.com/ics/computer-vision/saynavSayNav介绍
SayNav 是一种新颖的规划框架,它利用来自大型语言模型 (LLM) 的人类知识,为自主agent动态生成分步指令,以在未知的大规模环境中执行复杂的导航任务。它还能够有效地泛化学习,以从模拟导航到真实的新环境。
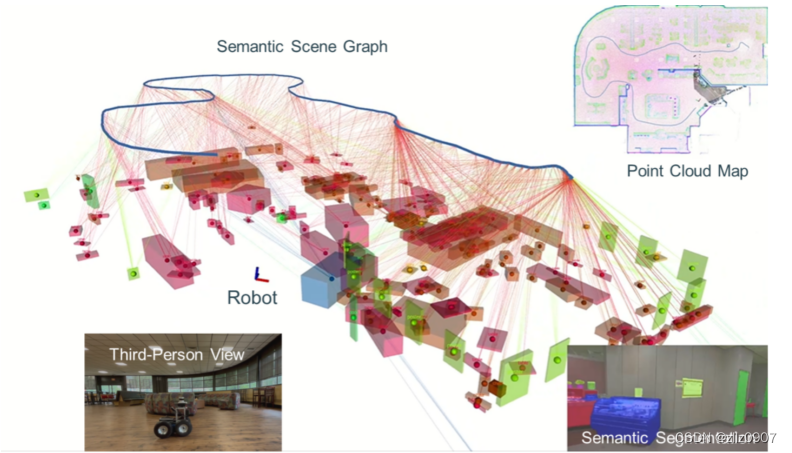
图0 在探索新环境的过程中,机器人不断构建点云图,并从图像中分割对象(语义分割),以增量生成语义场景图。SayNav 使用这个语义场景图来表示对象及其几何关系,以 LLM 进行导航。
感知、语义推理和动态规划功能对于自主agent在未知环境中执行复杂的导航任务至关重要,例如在新房屋中搜索和定位多个特定对象。它需要人类拥有的大量常识性知识才能成功完成这些任务。当前基于学习的方法,其中最流行的是深度强化学习 (DRL),需要对智能体进行大量训练才能获得合理的性能,即使是简单的导航任务,例如查找单个对象或到达单个目标点。
在本文中,我们介绍了 SayNav,这是一种利用大型语言模型 (LLM) 常识性知识的新方法,可以有效地泛化到未知大规模环境中的复杂导航任务。具体来说,SayNav 利用 LLM 作为高级规划器来动态生成分步指令,以便在导航过程中在新环境中定位目标对象。然后,LLM 生成的指令由预先训练的低级规划器执行,该规划器将每个指令步骤视为短距离点目标导航子任务。这种分解降低了导航任务的规划复杂性 - LLM 规划的子任务足够简单,低级规划器可以成功执行。
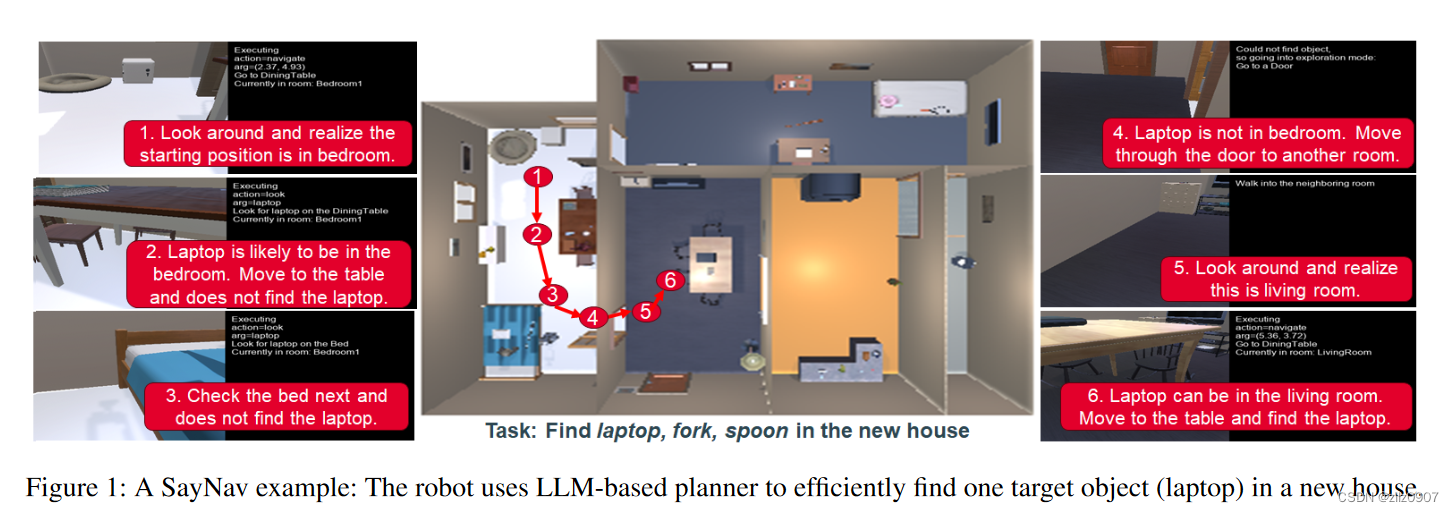
图1 SayNav 示例:机器人使用基于 LLM 的规划器在新房子里有效地找到一个目标对象(笔记本电脑)。
为了确保动态规划的可行性和有效性,SayNav 在探索过程中通过增量感知、构建和扩展 3D 场景图,对 LLM 使用了一种新颖的grounding机制。SayNav 使用摄像头持续感知世界,并提取包含相关信息的场景图,例如物体的 3D 位置及其在以智能体当前位置为中心的局部区域的空间关系。3D 场景图被转换为文本提示,以提供给 LLM。然后,LLM 会根据这些信息计划后续步骤,例如推断目标对象的可能位置并确定它们的优先级。此计划还包括条件语句和任何步骤无法实现目标时的回退选项。
我们使用逼真的基准数据集测试了 SayNav,其中包含 132 个独特的 ProcTHOR 房屋环境,具有不同的大小(从 3 到 10 个房间)、布局和家具/物体布置。评估指标是在每所房子里搜索和定位三个不同目标对象所花费的时间和成功率。我们的结果表明,SayNav能够grounding LLMs,以动态的方式为这个复杂的多目标导航任务生成成功的计划。
SayNav任务描述
我们选择多对象导航任务(Multi ON task)来验证 SayNav。这项任务的目标是让agent在大规模未知环境中导航,以便为三个预定义对象类别(如 "笔记本电脑"、"西红柿 "和 "面包")中的每个类别找到一个实例。agent在环境中的一个随机位置初始化,并接收目标对象类别(oi、oj、ok)作为输入。在导航过程中的每个时间步长 t,agent接收环境观测数据 et 并采取控制行动 at。观测数据包括 RGBD 图像、语义分割图和agent的姿势(位置和方向)。行动空间包括五个控制指令:左转、右转、向前移动、停止和环顾四周。向左转和向右转这两个动作都能使机器人旋转 90 度。向前移动动作则会将agent移动 25 厘米。如果agent在规定时间内找到(通过检测)所有三个物体,则任务执行成功。
需要注意的是,与以往的导航任务相比,MultiON 任务带来了更大的规划挑战和任务复杂性,以往的导航任务要么是寻找单一物体(Chaplot 等人,2020 年),要么是到达单一目标点(Wijmans 等人,2019 年)。例如,agent需要根据三个不同物体之间的优先顺序动态设定搜索计划。在探索布局未知的新房子时,该计划也可以改变。如图 1 所示,agent首先意识到自己在卧室里,然后决定优先从桌子等地方查找房间内的笔记本电脑。另一方面,如果该agent从厨房开始,那么先寻找叉子和勺子会更有效率。因此,这项新任务需要大量的语义推理和动态规划能力,就像人类所拥有的那样,自主agent才能在大规模的未知环境中进行探索。
SayNav 框架
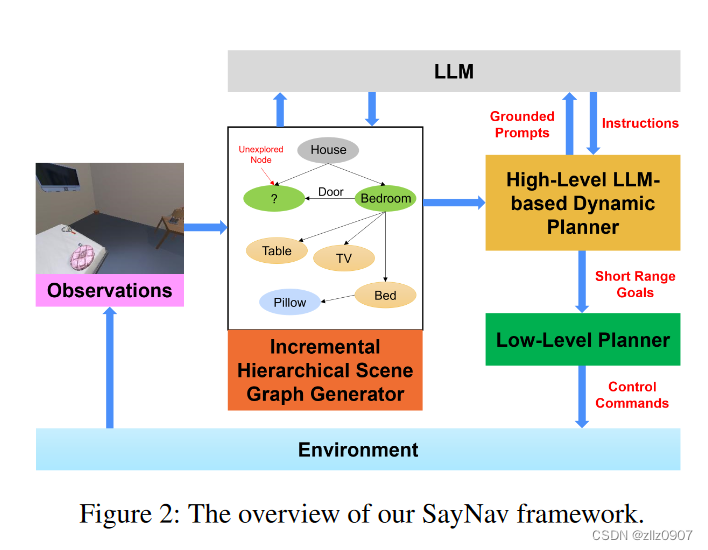
SayNav 包括三个模块:(1)增量场景图生成,(2)基于 LLM 的高级动态规划器,以及 (3) 低级规划器。
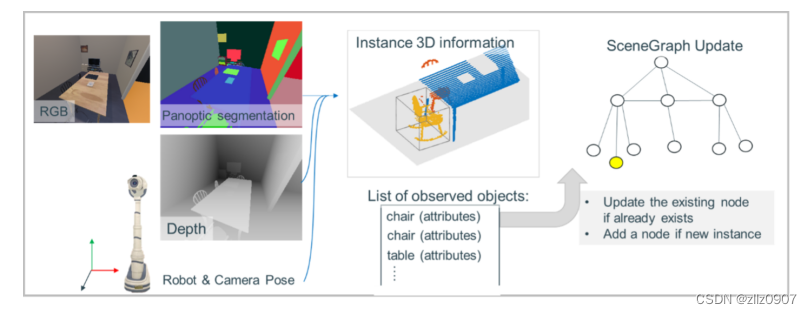
图3 增量场景图生成概念图
增量场景图生成模块会累积agent接收到的观测值,以构建和扩展 3D 场景图,该图对来自agent已探索区域的语义实体(如对象和家具)进行编码。三维场景图是一种分层图(layered graph),它表示节点及其关系(边)。这种表示最近已成为机器人技术中 3D 大规模环境的强大高级抽象。在这里,我们在 3D 场景图中定义了四个级别:小对象、大对象、房间和房屋。每个空间概念(节点)都与其 3D 坐标相关联。边揭示了不同层次的语义概念之间的拓扑关系。
基于高级 LLM 的动态规划器将场景图中的相关信息持续转换为文本提示,发送给预训练的 LLM,用于动态生成短期高级计划。当前一个计划失败或任务目标(查找三个对象)未实现时,基于 LLM 的规划器会扩展和更新计划。注意:SayNav 只需要通过上下文学习的几个示例来配置 LLM,以便在新环境中对复杂的多对象导航任务进行高级动态规划。如图4所示。

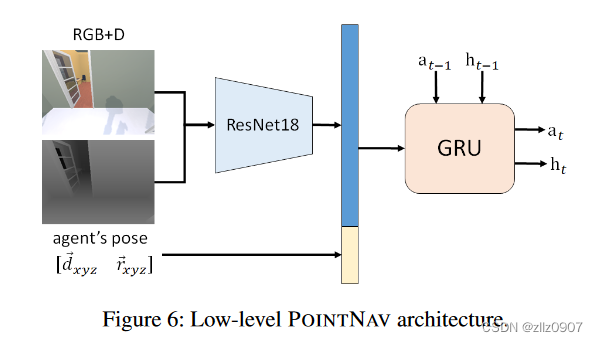
低级规划器将每个 LLM 计划的步骤转换为一系列控制命令以供执行。SayNav 将每个 LLM 规划步骤表述为低级规划器的短距离点目标导航 (POINTNAV) 子任务。每个子任务的目标点(例如从当前位置移动到当前房间中的桌子)由每个计划步骤中描述的对象的 3D 坐标分配。低级规划器使用 DAGGER 算法从头开始训练(无需预训练),仅使用 7 × 105 个模拟步骤。使用A* oracle作为专家来进行模仿学习的训练,对于行为克隆(behavior cloning),目标函数是最大限度地减少每一步预测行动与专家行动的交叉熵损失。在agent架构方面,根据(Wijmans 等人,2019 年),使用了图 6 所示的标准架构。接收 RGBD 图像和agent相对于目标位置的姿势作为输入。一个 GroupNorm(Wu 等人,2018 年)ResNet18(He 等人,2016 年)对输入的 RGBD 图像进行编码,一个 2 层 512 隐藏大小的门控递归单元(GRU)(Cho 等人,2014 年)结合历史和传感器输入来预测下一步行动。我们使用了 lr 10-4 和权重衰减 10-4 的 Adamax 优化器。batch size 16, 50 epochs。
SayNav 到多对象导航
我们使用最近推出的 ProcTHOR 框架进行实验,该框架建立在 AI2-THOR 模拟器之上。我们构建了一个包含 132 栋房屋的数据集,并为每个房屋进行新的多对象导航任务。我们提出了两个用于评估导航任务的标准指标:成功率 (SR) 和按路径长度加权的成功率(SPL)。SR 测量agent能够成功找到所有三个对象的情况百分比,而 SPL 则通过最短路径与实际路径的比率对成功进行归一化。除了这两个指标之外,我们还使用 Kendall 距离指标来衡量智能体获得的对象排序与真实值获得的对象排序之间的相似性。我们使用 Kendall Tau 将这个距离转换为相关系数,并在成功的事件中报告它(所有三个目标找到)。
为了充分验证多目标导航时SayNav中基于 LLM 的规划能力,我们分别实现了场景图生成模块和低级规划模块两个选项进行评估。可以使用视觉观察 (VO) 或真值(GT) 生成场景图。
我们使用经过高效训练的agent (PNav) 或oracle planner(OrNav) 作为低级规划器。对于 OrNav,使用 A* 算法,它可以访问环境中可到达的位置。给定目标位置,它可以规划从代理当前位置到目标的最短路径。
我们还实现了一种强大的基线方法,该方法使用 PNav 沿着最短路线导航,以通过三个对象的真值点。此基线用于显示从基于学习的智能体到多对象导航的性能上限,因为对象以最佳顺序提供给智能体。
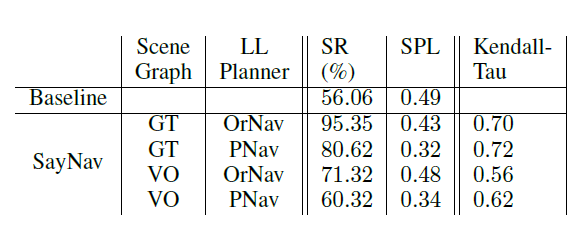
SayNav在多目标导航任务上的结果
根据实验结果,即使以最优顺序使用真值目标位置,基线方法的SR也仅为56.06%,这表明成功执行多个(顺序)点目标导航子任务(包括跨房间移动)的难度。相比之下,SayNav 在使用 PNav 或 OrNav 作为低级规划器使用视觉观察 (VO) 构建场景图时,实现了更高的 SR(分别为 60.32% 和 71.32%)。这一改进凸显了 SayNav 在大规模未知环境中导航的优势。
SayNav泛化到真实环境
SayNav 还支持从仿真到真实环境的高效泛化。基于LLM的高级规划策略可以通过模拟来学习,而适应是通过低级规划和控制来适应真实环境和模拟环境之间的差异。演示demo见https://youtu.be/_8ZnfniHGxk
SayNav局限性与未来方向
场景图生成面临着任何基于感知的算法都会遇到的各种挑战。除了常见的玻璃门问题,图 10 还显示了另一个由于视觉观察而导致的失败案例。请注意,在我们的实验中,agent并没有配备开关门的手臂。因此,它只能穿过打开的门移动到其他房间。在这个小插曲中,机器人在房间的大部分位置都无法观察到门(连接到有目标物体的另一个房间)是开着的。机器人反复尝试向当前房间的中心移动,并完善场景图。然而,它仍然无法识别门的 "打开 "状态,因此未能实现目标。如果有更好的机制来验证场景图中与对象节点(门)相关的属性(打开/关闭),就能帮助缓解这种情况。例如,agent可以靠近门,从所有可能的角度验证视觉观察结果,并将门的深度信息与墙的深度信息进行比较(关闭的门应与相连的墙具有几乎相同的深度)。未来,我们希望开发验证和反馈机制,以验证 LLM 生成的计划,从而提高 SayNav 的性能。我们还计划探索更小的 LLM(而不是 GPT-3.5 和 GPT-4),它们可以在真实机器人上本地运行。