- Scrapy框架基础
- Scrapy框架进阶
Scrapy 框架基础
【一】框架介绍
【1】简介
- Scrapy是一个用于网络爬取的快速高级框架,使用Python编写
- 他不仅可以用于数据挖掘,还可以用于检测和自动化测试等任务
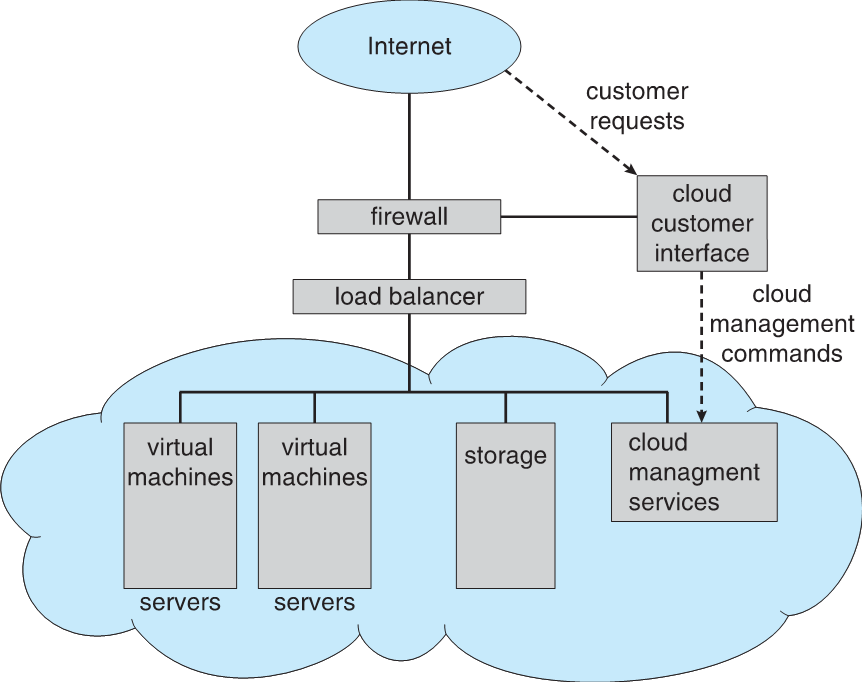
【2】框架
- 官网链接https://docs.scrapy.org/en/latest/topics/architecture.htm
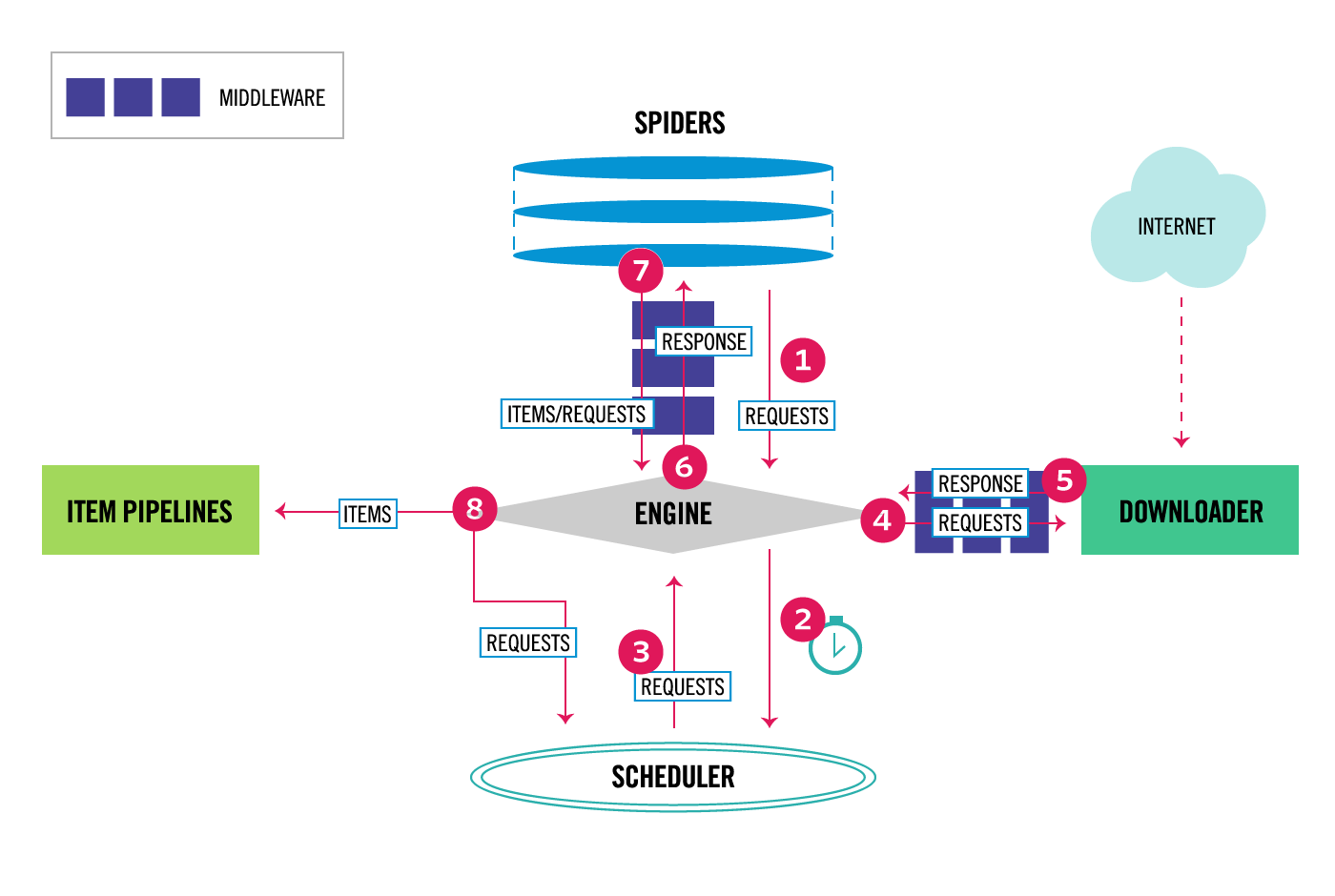
- 引擎(ENGINE)
- 核心组件
- 负责调度和监控Scrapy的所有组件
- 调度器(SCHEDULER)
- 负责接收所有待爬取的请求,并决定这些请求的调度顺序和时间
- 调度器会维持一个去重集合,避免对同一网页进行重复的爬取
- 下载器(DOWNLOADER)
- 下载器负责下载网络上的HTML页面,并将其转换为Scrapy可以处理的响应对象。
- Scrapy的下载器建立在Twisted这个高效的异步模型上,因此可以高效的处理大量并发请求
- 爬虫(SPIDERS)
- 负责处理下载响应后的数据。
- 通过定义一系列的解析规则,从响应中提取出所需要的数据。
- 同时,爬虫也会生成新的请求,并将其发送给调度器,以便进一步爬取相关联的页面
- 项目管道(ITEM PIPELINES)
- 负责处理爬虫提取出的数据
- 对数据进行清洗、验证、去重等操作,并将数据存储到数据库或文件中
- 爬虫中间件(MIDDLEWARE)
- 允许开发者在爬虫的请求发起之前或响应返回之后对数据进行定制化修改
- 如:添加请求头、设置代理、处理cookie等
- Scrapy提供了两种中间件:下载器中间件和爬虫中间件
【3】安装
- Linux平台直接安装即可
pip install scrapy
-
windows安装
- 直接安装,如果失败
- 这是因为一些其他模块没有提前安装
- 所以这里进行分步安装
-
windows安装步骤:
-
安装依赖项:Archived: Python Extension Packages for Windows - Christoph Gohlke (uci.edu)
-
安装wheel:Python分布工具,可以构建和安装wheel文件
-
pip install wheel
-
-
安装lxml:解析XML和HTML的Python库
-
pip install lxml
-
-
安装twisted:用于网络编程的的事件驱动框架
-
# 先直接安装试试,不行再指定版本 pip install Twisted -
pip install Twisted-版本号-python版本-python版本-系统.whl
-
-
-
安装scrapy
-
pip install scrapy
-
-
验证安装
-
scrapy version
-
-
【二】基本使用
【1】命令介绍
-
官网:https://docs.scrapy.org/en/latest/topics/commands.html
-
查看全部可用命令的帮助信息,或指定命令的详细信息
# 全部命令
scrapy -h
# 指定命令详细信息
scrapy 命令 -h
- 全局命令不需要切换至项目文件夹
- 项目命令需要切换至项目文件夹
(1)全局命令
-
startproject:创建一个新的Scrapy项目
-
genspider:创建一个新的爬虫程序
-
settings:显示一个Scrapy项目的配置信息
-
runspider:运行一个独立的Python文件作为爬虫,不需要创建项目
-
shell:进入Scrapy的交互式调试环境,可以检查选择器规则是否正确
-
fetch:单独请求一个界面,并获取响应结果
-
view:下载指定页面并在浏览器中打开,用于检查通过哪些请求获取数据
-
version:查看当前安装的Scrapy版本号
(2)项目命令
- crawl:运行一个Scrapy 爬虫,必须在项目目录下并确保配置文件中的爬虫协议(ROBOTSTXT_OBEY)设置为False
- check:检查项目中是否存在语法错误
- list:列出项目中包含的所有爬虫名称
- parse:使用回调函数解析给定的URL,用于验证回调函数是否正确
- bench:用于对Scrapy进行压力测试
【2】创建并启动项目
(1)创建项目
- 到指定文件下(即项目创建的位置)
cd 创建的位置
- 创建项目
scrapy startproject 项目名
- 进入创建的新项目
cd 项目名
- 创建spider项目
scrapy genspider 自定义爬虫程序文件名 目标网址
- 执行以上命令将得到如下目录文件

(2)启动项目
- 首先将爬虫协议(ROBOTSTXT_OBEY)改为False
- 一般在URL后面添加
/robots.txt就可以查看当前网址的爬虫协议
- 一般在URL后面添加
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
- 定义日志等级
- 低到高:
DEBUG、INFO、WARNING、ERROR、CRITICAL - 默认是
INFO,可以提高到ERROR,便于观察
- 低到高:
# 日志等级
LOG_LEVEL = "ERROR"
- 启动方式一:通过命令启动
- 先在进入项目目录
- 然后再启动
# 按照配置文件输出日志
scray crawl 自定义爬虫程序文件名
# 不输出日志文件
scray crawl 自定义爬虫程序文件名 --nolog
- 启动方式二:通过PY文件启动
- 在项目根目录下创建任意名称的py文件
- 填写以下内容运行即可
from scrapy.cmdline import execute
# 按照配置文件输出日志
execute(['scrapy', 'crawl', '自定义爬虫文件名'])
# 不输入日志
execute(['scrapy', 'crawl', '自定义爬虫程序文件名', "--nolog"])
【三】获取数据
【1】CSS解析器
-
官网:CSS 选择器参考手册 (w3school.com.cn)
-
CSS 选择器
| 选择器 | 例子 | 例子描述 |
|---|---|---|
| .class | .intro | 选择 class=“intro” 的所有元素。 |
| .class1.class2 | .name1.name2 | 选择 class 属性中同时有 name1 和 name2 的所有元素。 |
| .class1 .class2 | .name1 .name2 | 选择作为类名 name1 元素后代的所有类名 name2 元素。 |
| #id | #firstname | 选择 id=“firstname” 的元素。 |
| * | * | 选择所有元素。 |
| element | p | 选择所有 元素。 |
| element.class | p.intro | 选择 class=“intro” 的所有 元素。 |
| element,element | div, p | 选择所有
元素和所有
元素。 |
| element element | div p | 选择
元素内的所有
元素。 |
| element>element | div > p | 选择父元素是
的所有
元素。 |
| element+element | div + p | 选择紧跟
元素的首个
元素。 |
| element1~element2 | p ~ ul | 选择前面有 元素的每个
|
| [attribute] | [target] | 选择带有 target 属性的所有元素。 |
| [attribute=value] | [target=_blank] | 选择带有 target=“_blank” 属性的所有元素。 |
| [attribute~=value] | [title~=flower] | 选择 title 属性包含单词 “flower” 的所有元素。 |
| [attribute|=value] | [lang|=en] | 选择 lang 属性值以 “en” 开头的所有元素。 |
| [attribute^=value] | a[href^=“https”] | 选择其 src 属性值以 “https” 开头的每个 元素。 |
| [attribute$=value] | a[href$=“.pdf”] | 选择其 src 属性以 “.pdf” 结尾的所有 元素。 |
| [attribute*=value] | a[href*=“w3school”] | 选择其 href 属性值中包含 “abc” 子串的每个 元素。 |
| :active | a:active | 选择活动链接。 |
| ::after | p::after | 在每个 的内容之后插入内容。 |
| ::before | p::before | 在每个 的内容之前插入内容。 |
| :checked | input:checked | 选择每个被选中的 元素。 |
| :default | input:default | 选择默认的 元素。 |
| :disabled | input:disabled | 选择每个被禁用的 元素。 |
| :empty | p:empty | 选择没有子元素的每个 元素(包括文本节点)。 |
| :enabled | input:enabled | 选择每个启用的 元素。 |
| :first-child | p:first-child | 选择属于父元素的第一个子元素的每个 元素。 |
| ::first-letter | p::first-letter | 选择每个 元素的首字母。 |
| ::first-line | p::first-line | 选择每个 元素的首行。 |
| :first-of-type | p:first-of-type | 选择属于其父元素的首个 元素的每个 元素。 |
| :focus | input:focus | 选择获得焦点的 input 元素。 |
| :fullscreen | :fullscreen | 选择处于全屏模式的元素。 |
| :hover | a:hover | 选择鼠标指针位于其上的链接。 |
| :in-range | input:in-range | 选择其值在指定范围内的 input 元素。 |
| :indeterminate | input:indeterminate | 选择处于不确定状态的 input 元素。 |
| :invalid | input:invalid | 选择具有无效值的所有 input 元素。 |
| :lang(language) | p:lang(it) | 选择 lang 属性等于 “it”(意大利)的每个 元素。 |
| :last-child | p:last-child | 选择属于其父元素最后一个子元素每个 元素。 |
| :last-of-type | p:last-of-type | 选择属于其父元素的最后 元素的每个 元素。 |
| :link | a:link | 选择所有未访问过的链接。 |
| :not(selector) | :not§ | 选择非 元素的每个元素。 |
| :nth-child(n) | p:nth-child(2) | 选择属于其父元素的第二个子元素的每个 元素。 |
| :nth-last-child(n) | p:nth-last-child(2) | 同上,从最后一个子元素开始计数。 |
| :nth-of-type(n) | p:nth-of-type(2) | 选择属于其父元素第二个 元素的每个 元素。 |
| :nth-last-of-type(n) | p:nth-last-of-type(2) | 同上,但是从最后一个子元素开始计数。 |
| :only-of-type | p:only-of-type | 选择属于其父元素唯一的 元素的每个 元素。 |
| :only-child | p:only-child | 选择属于其父元素的唯一子元素的每个 元素。 |
| :optional | input:optional | 选择不带 “required” 属性的 input 元素。 |
| :out-of-range | input:out-of-range | 选择值超出指定范围的 input 元素。 |
| ::placeholder | input::placeholder | 选择已规定 “placeholder” 属性的 input 元素。 |
| :read-only | input:read-only | 选择已规定 “readonly” 属性的 input 元素。 |
| :read-write | input:read-write | 选择未规定 “readonly” 属性的 input 元素。 |
| :required | input:required | 选择已规定 “required” 属性的 input 元素。 |
| :root | :root | 选择文档的根元素。 |
| ::selection | ::selection | 选择用户已选取的元素部分。 |
| :target | #news:target | 选择当前活动的 #news 元素。 |
| :valid | input:valid | 选择带有有效值的所有 input 元素。 |
| :visited | a:visited | 选择所有已访问的链接。 |
【2】Xpath解析器
- 见爬虫XPath文章
- 同理支持链式操作
【3】获取数据
- .extract()
- 从选择器中提取匹配的所有元素
- 无论是否有匹配到,返回的都是一个列表(空列表)
- 列表内的元素都是字符串类型,标签也是字符串了
- .extract_first()
- 和.extract()类似
- 等价于.extract()[0]
- 但是没有匹配到元素将是None
# 列表
print(type(response.xpath('//div').extract()))
# 字符串
print(type(response.xpath('//div').extract()[-1]))
【四】配置文件
# 整个项目的名称
BOT_NAME = "scrapy_test"
# 爬虫文件存放位置
SPIDER_MODULES = ["scrapy_test.spiders"]
NEWSPIDER_MODULE = "scrapy_test.spiders"
# 日志等级
LOG_LEVEL = "ERROR"
# User-Agent设置
from fake_useragent import UserAgent
USER_AGENT = UserAgent().random
# 爬虫协议
ROBOTSTXT_OBEY = False
# 同时发送的最大并发请求数量,过高可能对目标服务器带来过大压力
CONCURRENT_REQUESTS = 16
# 发送连续请求之间的延迟时间(单位秒),减少目标服务器负载
DOWNLOAD_DELAY = 3
# 针对域名,同时发送最大并发请求数
CONCURRENT_REQUESTS_PER_DOMAIN = 16
# 针对IP,同时发送最大并发请求数
CONCURRENT_REQUESTS_PER_IP = 16
# 是否使用cookie,关闭可以减少cpu使用率
COOKIES_ENABLED = False
# 是否对失败的请求进行重新尝试
RETRY_ENABLED = False
# 默认下载超时时间
DOWNLOAD_TIMEOUT = 180
# 默认请求头
DEFAULT_REQUEST_HEADERS = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en",
}
# 爬虫中间件配置
SPIDER_MIDDLEWARES = {
"scrapy_test.middlewares.ScrapyTestSpiderMiddleware": 543,
}
# 下载中间件配置
DOWNLOADER_MIDDLEWARES = {
"scrapy_test.middlewares.ScrapyTestDownloaderMiddleware": 543,
# }
# 启用或禁用Scrapy扩展
EXTENSIONS = {
"scrapy.extensions.telnet.TelnetConsole": None,
}
# 管道持久化配置
ITEM_PIPELINES = {
"scrapy_test.pipelines.ScrapyTestPipeline": 300,
}
# 启用或禁用自动节流功能
AUTOTHROTTLE_ENABLED = True
# 初始下载延迟,用于评估目标服务器的响应时间
AUTOTHROTTLE_START_DELAY = 5
# 最大下载延迟,单位秒
AUTOTHROTTLE_MAX_DELAY = 60
# 目标并发数,根据下载延迟进行调整,越接近1,会越严格遵守这个并发数
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# 是否启动节流功能日志
AUTOTHROTTLE_DEBUG = False
# 启用或禁用HTTP请求缓存功能
HTTPCACHE_ENABLED = True
# 缓存过期时间,0是永不过期
HTTPCACHE_EXPIRATION_SECS = 0
# 缓存数据存储的路径
HTTPCACHE_DIR = "httpcache"
# 一个不应被缓存的HTTp状态码列表
HTTPCACHE_IGNORE_HTTP_CODES = []
# 用于存储缓存的数据类
HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# 请求指纹算法的实现版本。这用于生成请求的唯一标识符,用于缓存和其他目的。
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
# 用于Scrapy的Twisted事件循环反应器的类。这可以影响Scrapy的异步性能和兼容性。
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
# 导出数据时使用的字符编码。这通常用于控制导出文件的编码格式。
FEED_EXPORT_ENCODING = "utf-8"
# 是否启用Telnet控制台。Telnet控制台允许你通过telnet协议与正在运行的Scrapy爬虫进行交互,比如查看状态、暂停/恢复爬虫等。
TELNETCONSOLE_ENABLED = False


![ERROR in [eslint] reorder to top import/first](https://img-blog.csdnimg.cn/direct/392bce29e00d41a4b7c2a43e823a3b9d.png#pic_center)