sync 包提供了一个强大且可复用的实例池,以减少 GC 压力。在使用该包之前,我们需要在使用池之前和之后对应用程序进行基准测试。这非常重要,因为如果不了解它内部的工作原理,可能会影响性能。
池的限制
我们来看一个例子以了解它如何在一个非常简单的上下文中分配 10k 次:
type Small struct {
a int
}
var pool = sync.Pool{
New: func() interface{} { return new(Small) },
}
//go:noinline
func inc(s *Small) { s.a++ }
func BenchmarkWithoutPool(b *testing.B) {
var s *Small
for i := 0; i < b.N; i++ {
for j := 0; j < 10000; j++ {
s = &Small{ a: 1, }
b.StopTimer(); inc(s); b.StartTimer()
}
}
}
func BenchmarkWithPool(b *testing.B) {
var s *Small
for i := 0; i < b.N; i++ {
for j := 0; j < 10000; j++ {
s = pool.Get().(*Small)
s.a = 1
b.StopTimer(); inc(s); b.StartTimer()
pool.Put(s)
}
}
}
上面有两个基准测试,一个没有使用 sync.Pool,另一个使用了:
name time/op alloc/op allocs/op
WithoutPool-8 3.02ms ± 1% 160kB ± 0% 1.05kB ± 1%
WithPool-8 1.36ms ± 6% 1.05kB ± 0% 3.00 ± 0%
由于循环有 10k 次迭代,因此不使用池的基准测试在堆上需要 10k 次内存分配,而使用了池的基准测试仅进行了 3 次分配。 这 3 次分配由池产生的,但却只分配了一个结构实例。目前看起来还不错;使用 sync.Pool 更快,消耗更少的内存。
但是,在一个真实的应用程序中,你的实例可能会被用于处理繁重的任务,并会做很多头部内存分配。在这种情况下,当内存增加时,将会触发 GC。我们还可以使用命令 runtime.GC() 来强制执行基准测试中的 GC 来模拟此行为:(译者注:在 Benchmark 的每次迭代中添加runtime.GC())
name time/op alloc/op allocs/op
WithoutPool-8 993ms ± 1% 249kB ± 2% 10.9k ± 0%
WithPool-8 1.03s ± 4% 10.6MB ± 0% 31.0k ± 0%
我们现在可以看到,在 GC 的情况下池的性能较低,分配数和内存使用也更高。我们继续更深入地了解原因。
池的内部工作流程
深入了解 sync/pool.go 包的初始化,可以帮助我们之前的问题的答案:
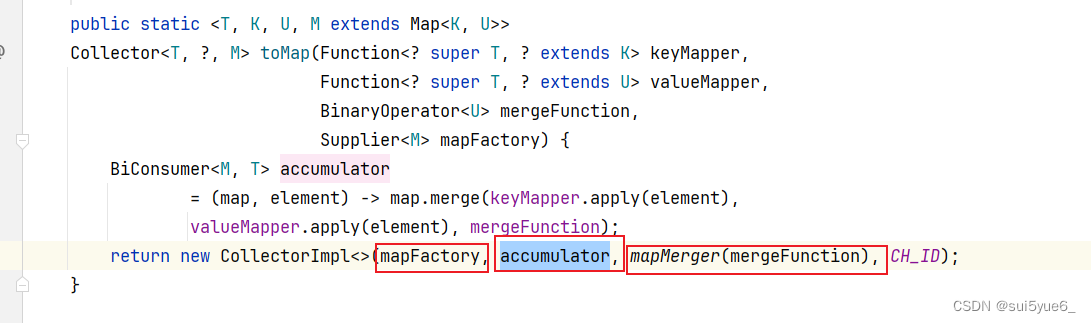
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
他将注册一个在运行时清理 pool 对象的方法。GC 在文件 runtime/mgc.go 中将触发这个方法:
func gcStart(trigger gcTrigger) {
[...]
// 在开始 GC 前调用 clearpools
clearpools()
这就解释了为什么在调用 GC 时性能较低。因为每次 GC 运行时都会清理 pool 对象(译者注:pool 对象的生存时间介于两次 GC 之间)。文档也告知我们:
存储在池中的任何内容都可以在不被通知的情况下随时自动删除
现在,让我们创建一个流程图以了解池的管理方式:
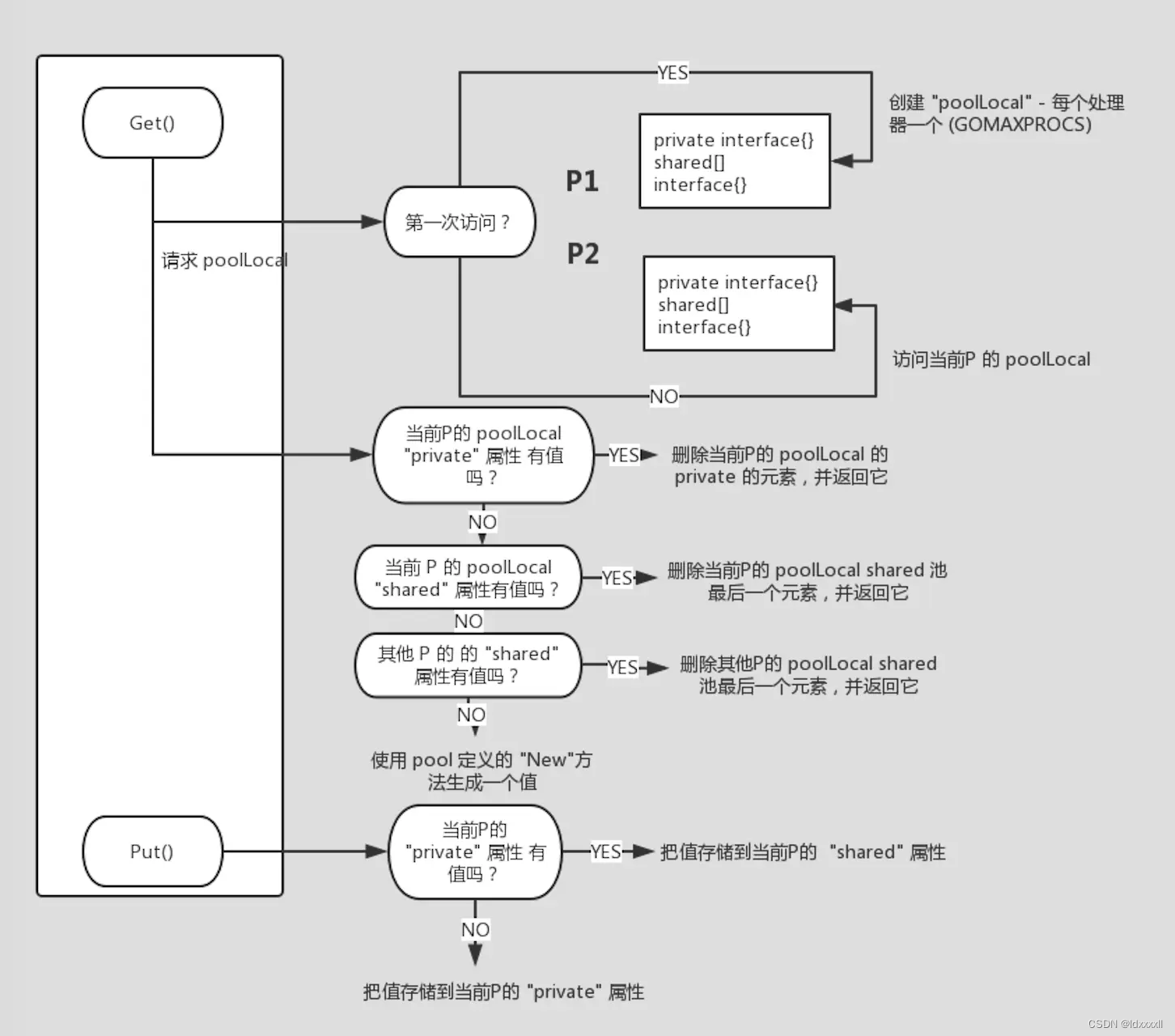
对于我们创建的每个 sync.Pool,go 生成一个连接到每个处理器(译者注:处理器即 Go 中调度模型 GMP 的 P,pool 里实际存储形式是 [P]poolLocal)的内部池 poolLocal。该结构由两个属性组成:private 和 shared。第一个只能由其所有者访问(push 和 pop 不需要任何锁),而 shared 属性可由任何其他处理器读取,并且需要并发安全。实际上,池不是简单的本地缓存,它可以被我们的应用程序中的任何 线程/goroutines 使用。
Go 的 1.13 版本将改进 shared 的访问,并且还将带来一个新的缓存,以解决 GC 和池清理相关的问题。
新的无锁池和 victim 缓存
Go 1.13 版将 shared 用一个双向链表poolChain作为储存结构,这次改动删除了锁并改善了 shared 的访问。以下是 shared 访问的新流程:

使用这个新的链式结构池,每个处理器可以在其 shared 队列的头部 push 和 pop,而其他处理器访问 shared 只能从尾部 pop。由于 next/prev 属性,shared 队列的头部可以通过分配一个两倍大的新结构来扩容,该结构将链接到前一个结构。初始结构的默认大小为 8。这意味着第二个结构将是 16,第三个结构 32,依此类推。
此外,现在 poolLocal 结构不需要锁了,代码可以依赖于原子操作。
关于新加的 victim 缓存(译者注:关于引入 victim 缓存的 commit,引入该缓存就是为了解决之前 Benchmark 那个问题),新策略非常简单。现在有两组池:活动池和存档池(译者注:allPools 和 oldPools)。当 GC 运行时,它会将每个池的引用保存到池中的新属性(victim),然后在清理当前池之前将该组池变成存档池:
// 从所有 pool 中删除 victim 缓存
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// 把主缓存移到 victim 缓存
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// 非空主缓存的池现在具有非空的 victim 缓存,并且池的主缓存被清除
oldPools, allPools = allPools, nil
有了这个策略,应用程序现在将有一个循环的 GC 来 创建/收集 具有备份的新元素,这要归功于 victim 缓存。在之前的流程图中,将在请求"shared" pool 的流程之后请求 victim 缓存。