RAG 是什么
RAG 在 Langchain 上的定义是,作为大语言模型最常用的场景就是问答系统,可以针对特别来源数据做问题回答,就是私有数据,这就是 RAG,英文全称是Retrieval Augmented Generation。就是对现有模型数据的增广,大语言模型都是在公众数据上训练,而且只是拿到了某一个时间点之前的数据。我查了一下 GPT,他最新的数据是 2023年 12 月,数据还是很新的。但是对于一些私有数据,模型肯定是没有的,对数据的增广就很有必要。
RAG 架构
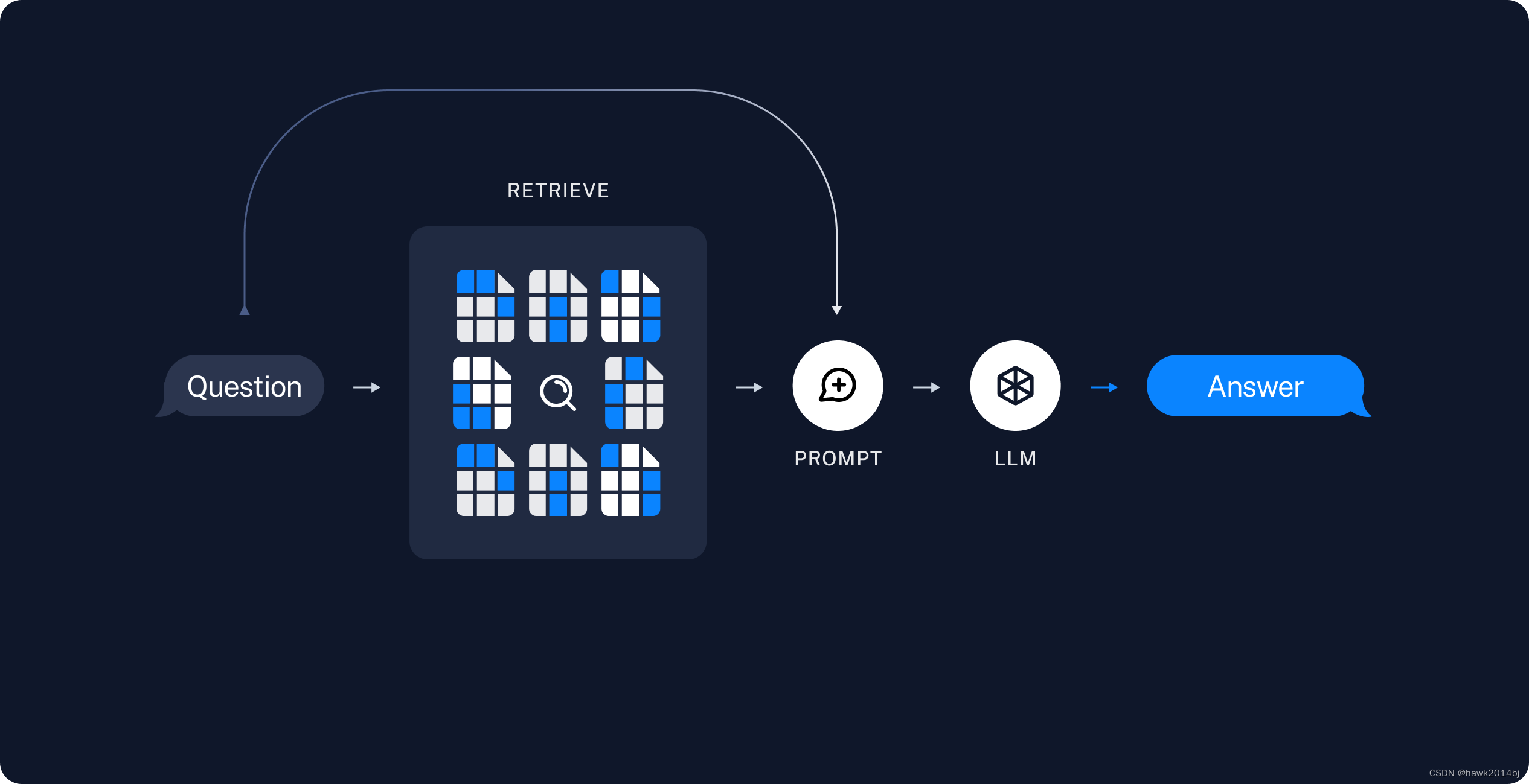
RAG主要包括两个主要部分,首先是索引,从源头获取数据并进行索引的流程,例如从 PDF 获取数据,这通常在离线进行。第二步是搜索和生成,在运行时接收用户查询语句,从索引中检索相关数据,然后传递给模型。其实这个很像 ES 的全文检索,只是 ES 没有那么高级,ES 用的是分词,通过匹配进行查找。而 RAG 这里的分词用的是向量数据库,查找方式是相似度。
索引
- 首先导入文件,通过文件 Loader 可以导入 PDF、Word 等。
- 切分,将大文档进行切分,切分文档对索引和模型都有好处,搜索大文档对性能是很大的挑战,对于模型而言,模型的上下文是有限的,短小的上下文肯定更好,虽然现在模型的上下文都已经很大了。
- Embedding, 将切分的文档进行 embedding,向量化。
- 存储,要将索引进行保存,以便后续进行搜索。

搜索并生成
最后,根据用户输入的查询语句向量化后,在向量数据库中进行查询匹配,并将数据库的返回的结果和用户的查询语句一起发送给模型。
下面我们通过一个例子实现 chatpdf,用 langchain 加 ollama 进行实现RAG,运行在 Mac 上,性能可以接受。
安转依赖
conda create --name rag python=3.10
conda activate rag
pip install langchain
pip install streamlit
pip install chromadb
pip install pypdf
运行 chatpdf
模型用的 qwen:7b,需要把 ollama 运行起来。
from langchain.chains import RetrievalQA
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.callbacks.manager import CallbackManager
from langchain_community.llms import Ollama
from langchain_community.embeddings.ollama import OllamaEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory
import streamlit as st
import os
import time
if not os.path.exists('files'):
os.mkdir('files')
if not os.path.exists('jj'):
os.mkdir('jj')
if 'template' not in st.session_state:
st.session_state.template = """You are a knowledgeable chatbot, here to help with questions of the user. Your tone should be professional and informative.
Context: {context}
History: {history}
User: {question}
Chatbot:"""
if 'prompt' not in st.session_state:
st.session_state.prompt = PromptTemplate(
input_variables=["history", "context", "question"],
template=st.session_state.template,
)
if 'memory' not in st.session_state:
st.session_state.memory = ConversationBufferMemory(
memory_key="history",
return_messages=True,
input_key="question")
if 'vectorstore' not in st.session_state:
st.session_state.vectorstore = Chroma(persist_directory='jj',
embedding_function=OllamaEmbeddings(base_url='http://localhost:11434',
model="qwen:7b")
)
if 'llm' not in st.session_state:
st.session_state.llm = Ollama(base_url="http://localhost:11434",
model="qwen:7b",
verbose=True,
callback_manager=CallbackManager(
[StreamingStdOutCallbackHandler()]),
)
# Initialize session state
if 'chat_history' not in st.session_state:
st.session_state.chat_history = []
st.title("PDF Chatbot")
# Upload a PDF file
uploaded_file = st.file_uploader("Upload your PDF", type='pdf')
for message in st.session_state.chat_history:
with st.chat_message(message["role"]):
st.markdown(message["message"])
if uploaded_file is not None:
if not os.path.isfile("files/"+uploaded_file.name+".pdf"):
with st.status("Analyzing your document..."):
bytes_data = uploaded_file.read()
f = open("files/"+uploaded_file.name+".pdf", "wb")
f.write(bytes_data)
f.close()
loader = PyPDFLoader("files/"+uploaded_file.name+".pdf")
data = loader.load()
# Initialize text splitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1500,
chunk_overlap=200,
length_function=len
)
all_splits = text_splitter.split_documents(data)
# Create and persist the vector store
st.session_state.vectorstore = Chroma.from_documents(
documents=all_splits,
embedding=OllamaEmbeddings(model="qwen:7b")
)
st.session_state.vectorstore.persist()
st.session_state.retriever = st.session_state.vectorstore.as_retriever()
# Initialize the QA chain
if 'qa_chain' not in st.session_state:
st.session_state.qa_chain = RetrievalQA.from_chain_type(
llm=st.session_state.llm,
chain_type='stuff',
retriever=st.session_state.retriever,
verbose=True,
chain_type_kwargs={
"verbose": True,
"prompt": st.session_state.prompt,
"memory": st.session_state.memory,
}
)
# Chat input
if user_input := st.chat_input("You:", key="user_input"):
user_message = {"role": "user", "message": user_input}
st.session_state.chat_history.append(user_message)
with st.chat_message("user"):
st.markdown(user_input)
with st.chat_message("assistant"):
with st.spinner("Assistant is typing..."):
response = st.session_state.qa_chain(user_input)
message_placeholder = st.empty()
full_response = ""
for chunk in response['result'].split():
full_response += chunk + " "
time.sleep(0.05)
# Add a blinking cursor to simulate typing
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
chatbot_message = {"role": "assistant", "message": response['result']}
st.session_state.chat_history.append(chatbot_message)
else:
st.write("Please upload a PDF file.")
启动chatpdf
streamlit run app.py
上传 PDF,输入问题,就可以和模型对话PDF 中的内容了。

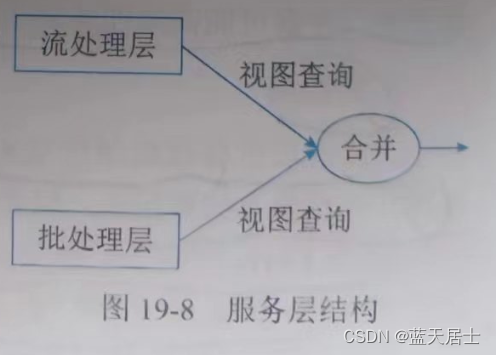
RAG 是数据增广,也可以说是数据过滤,按照今天大模型的发展,上下文的长度已经卷到200 万个汉字的无损上下文,那么 RAG 会不会以后就不需要了,每次对话都把文档带上,让我们拭目以待。






![[计算机效率] 网站推荐:格式转换类](https://img-blog.csdnimg.cn/direct/8f41e29b7afd414b876bde9b8c9f040e.png)