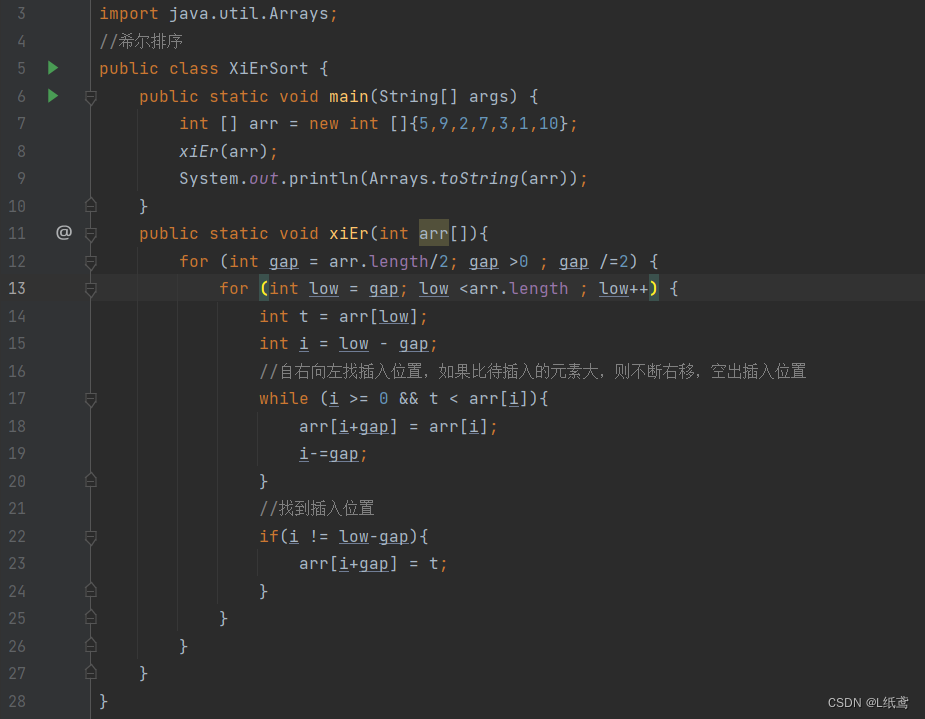
接前一篇文章:软考 系统架构设计师系列知识点之大数据设计理论与实践(7)
所属章节:
第19章. 大数据架构设计理论与实践
第3节 Lambda架构
19.3.3 Lambda架构介绍
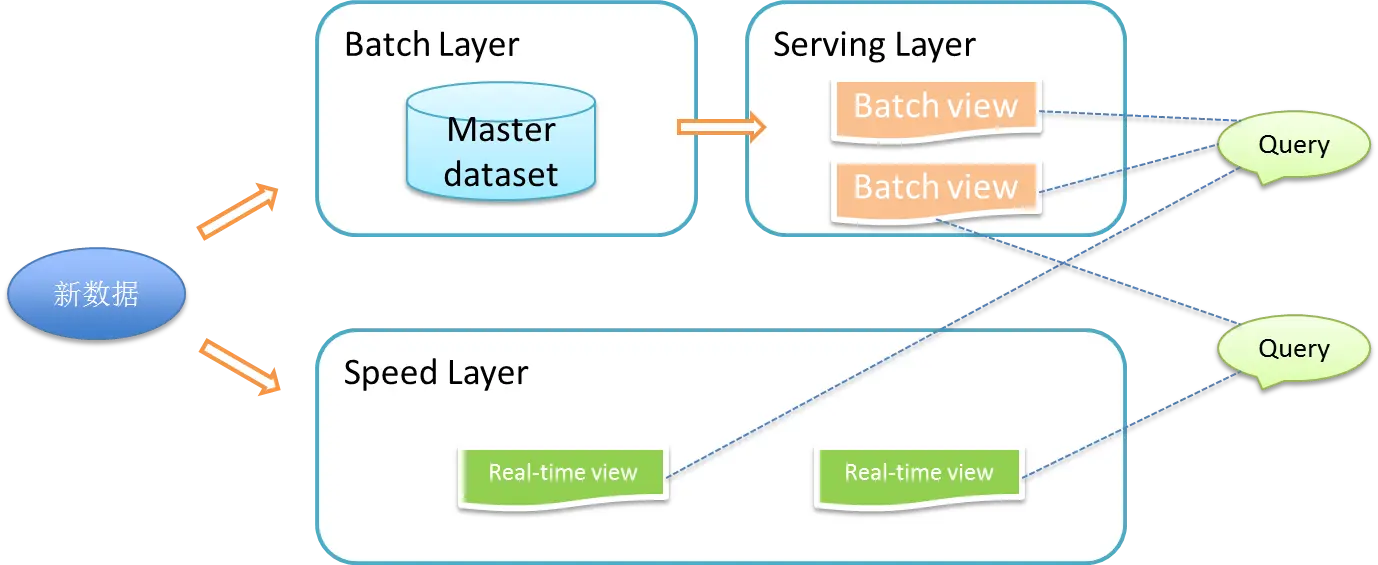
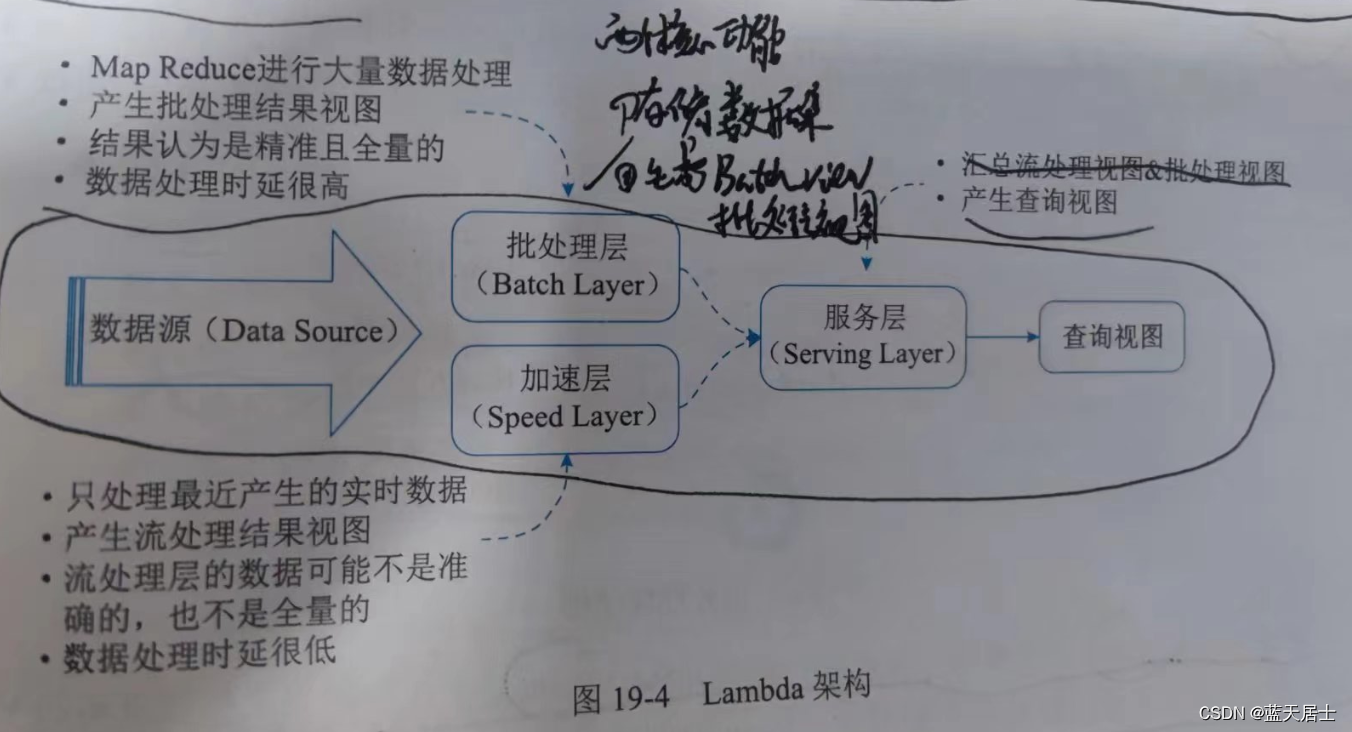
1. 批处理层
2. 加速层
对加速层批处理视图建立索引,便于能快速进行即席查询(Ad Hoc Queries)。它存储实时视图并处理传入的数据流,以便更新这些视图。
加速层(Batch Layer)可以很好地处理离线数据,但有很多场景数据不断实时生成,并且需要实时查询处理。Speed Layer正是用来处理增量的实时数据。
Speed Layer和Batch Layer比较类似。如图19-7所示:

加速层(Speed Layer)对数据进行计算并生成Realtime View,其主要区别在于:
(1)Speed Layer处理的数据是最近的增量数据流,Batch Layer处理的是全体数据集。
(2)Speed Layer为了效率,接收到新数据时不断更新Realtime View,而Batch Layer根据全体离线数据集直接得到Batch View。
Lambda架构将数据处理分解为Batch Layer和Speed Layer有如下优点:
- 容错性
Speed Layer中处理的数据也不断写入Batch Layer,当Batch Layer中重新计算的数据集包含Speed Layer处理的数据集后,当前的Real-time View就可以丢弃,这也就意味着Speed Layer处理中引入的错误,在Batch Layer重新计算时都可以得到修正。这一点也可以看成是CAP理论中的最终一致性(Eventual Consistency)的体现。
- 复杂性隔离
Batch Layer处理的是离线数据,可以很好地掌控。Speed Layer采用增量算法处理实时数据,复杂性比Batch Layer要高很多。通过分开Batch Layer和Speed Layer,把复杂性隔离到Speed Layer,可以很好地提高整个系统的鲁棒性和可靠性。
- 横向扩容(Scalable)
当数据量/负载增大时,可扩展的系统通过增加更多的机器资源来维持性能。也就是常说的系统需要线性可扩展,通常采用scale out(通过增加机器的个数)而不是scale up(增加机器的性能)。
3. 服务层
Lambda架构的Serving Layer用于响应用户的查询请求,合并Batch View和Real-time View中的结果数据集到最终的数据集。该层提供了主数据集上执行的计算结果的低延迟访问。读取速度可以通过数据附加的索引来加速。与加速层类似,该层也必须满足以下要求,例如随机读取、批量写入、可伸缩性和容错能力。
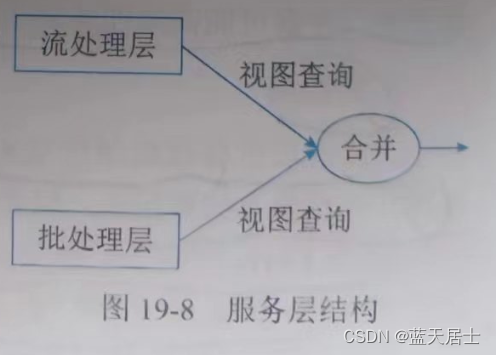
这涉及数据如何合并的问题。前面讨论了查询函数的Monoid性质,如果查询函数满足Monoid性质,即满足结合律,只需要简单地合并Batch View和Real-time View中的结果数据集即可;否则,可以把查询函数转换成多个满足Monoid性质的查询函数的运算,单独对每个满足Monoid性质的查询函数进行Batch View和Real-time View中的结果数据集合并,然后再计算得到最终的结果数据集。另外,也可以根据业务自身的特性,运用业务自身的规则来对Batch View和Real-time View中的结果数据集合并。如图19-8所示:
至此,“19.3.3 Lambda架构介绍”的全部内容就讲解完了。更多内容请看下回。



![[计算机效率] 网站推荐:格式转换类](https://img-blog.csdnimg.cn/direct/8f41e29b7afd414b876bde9b8c9f040e.png)