setting.py实验目的及要求:
【实验目的】
通过本实验了解Scrapy爬虫框架;熟练掌握Scrapy的基本使用方法和常用技巧。
【实验要求】
使用Scrapy框架,抓取网站商品信息(京东、淘宝、当当等任选一个),并将结果保存成多种形式。(本文选择当当)
实验原理及内容:
【实验原理】(列出相关知识点)
- Scrapy框架:
- 理解Scrapy框架的基本原理和架构。
- HTTP请求和响应:
- 理解HTTP请求和响应的基本概念。
- 如何通过Scrapy发送HTTP请求和处理响应。
- Web页面结构:
- 了解HTML和CSS的基础知识,理解Web页面的结构。
- CSS选择器和XPath:
- 使用CSS选择器或XPath在网页中定位和提取信息。
- Scrapy Spider:
- 创建Scrapy Spider,定义如何抓取和解析页面。
- 如何通过Spider跟踪链接和处理分页。
- Scrapy Items:
- 定义Scrapy Items,用于存储抓取的数据。
- Scrapy Pipelines:
- 编写Scrapy Pipelines处理抓取到的Item。
- 配置Pipeline在settings.py中。
- 异常处理:
- 处理可能出现的异常,例如超时、连接错误等。
- 数据存储:
- 将抓取到的数据保存到不同的存储介质,如文件、数据库等。
- 用户代理和IP代理:
- 设置和使用用户代理和IP代理,以避免被封禁。
- 异步和并发:
- 配置异步和并发请求以提高爬取效率。
- Scrapy Settings:
- 配置Scrapy的Settings,包括用户代理、下载延迟等。
- Web爬取伦理:
- 了解爬虫的伦理和法律问题,避免对网站造成不必要的压力。
- 日志和调试:
- 使用Scrapy的日志系统进行调试。
- 扩展和定制:
- 定制和扩展Scrapy,满足特定需求。
【程序思路】
- 首先,因为我们要抓取网页中的标题、链接和评论数,所以我们首先得写items.py
- 在这里添加完我们需要爬取的哪些数据后,我们在转向我们的爬虫文件,我们通过 scrapy genspider dd dangdang.com 创建了一个爬虫文件dd.py
- 然后开始撰写settings.py
- 最后编写pipelines.py文件了(也就是可以正式操作数据了)。
实验数据与结果分析:(含运行结果截屏)
【实验结果】
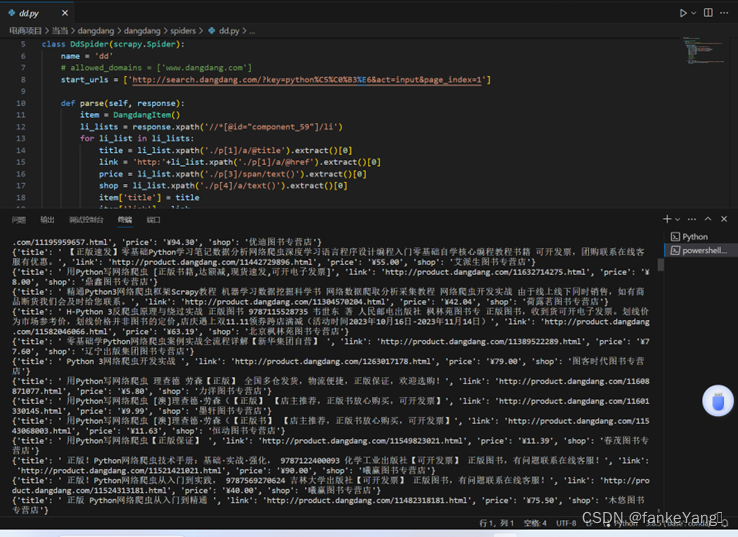


【结果分析】
利用Scrapy框架抓取了当当网站商品信息,并通过ppline.py将数据存储到了mysql数据库中,可以以不同数据存储方式存储。
实验小结:(包括问题和解决方法、心得体会、意见与建议等)
在进行这个实验的过程中,我首先面临的挑战是网站结构的变化。由于当当网站可能会定期更新,导致之前编写的爬虫代码无法正确提取信息。为了解决这个问题,我学习了如何动态调整选择器以适应变化的网页结构,并通过查看网页源代码来快速调整选择器,确保爬虫的准确性。
在实验中,我深刻体会到Scrapy框架的强大之处。通过定义Item、编写Spider、配置Pipeline等步骤,我成功地构建了一个功能强大的爬虫,能够高效地抓取和处理目标网站的信息。学会使用Scrapy的中间件和设置,我更好地掌握了爬虫的并发和异步请求的处理方式,提高了爬取效率。
通过实验,我还发现了对数据进行实时分析和监控的重要性。及时发现并解决异常情况,如数据缺失、异常格式等,有助于提高爬虫的稳定性。此外,通过对数据进行统计和可视化分析,我更全面地了解了抓取到的信息,发现了一些潜在的趋势和规律。通过这个实验,我不仅掌握了Scrapy框架的使用,还培养了解决实际问题的能力,让我受益匪浅。
实验源代码清单:(带注释)
item.py:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
price = scrapy.Field()
shop = scrapy.Field()
# Scrapy settings for dangdang project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'dangdang'
SPIDER_MODULES = ['dangdang.spiders']
NEWSPIDER_MODULE = 'dangdang.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
}
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'dangdang.middlewares.DangdangSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'dangdang.middlewares.DangdangDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'dangdang.pipelines.DangdangPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
Pipline.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
#from itemadapter import ItemAdapter
#from pymongo import MongoClient
class DangdangPipeline:
def __init__(self):
self.client = MongoClient(host='localhost',port=27017)
self.db = self.client['当当']
self.collections = self.db['python爬虫']
def process_item(self, item, spider):
data = {
'title': item['title'],
'link': item['link'],
'price': item['price'],
'shop': item['shop'],
}
print(data)
self.collections.insert(data)
return item
dd.py
import scrapy
from dangdang.items import DangdangItem
class DdSpider(scrapy.Spider):
name = 'dd'
# allowed_domains = ['www.dangdang.com']
start_urls = ['http://search.dangdang.com/?key=python%C5%C0%B3%E6&act=input&page_index=1']
def parse(self, response):
item = DangdangItem()
li_lists = response.xpath('//*[@id="component_59"]/li')
for li_list in li_lists:
title = li_list.xpath('./p[1]/a/@title').extract()[0]
link = 'http:'+li_list.xpath('./p[1]/a/@href').extract()[0]
price = li_list.xpath('./p[3]/span/text()').extract()[0]
shop = li_list.xpath('./p[4]/a/text()').extract()[0]
item['title'] = title
item['link'] = link
item['price'] = price
item['shop'] = shop
# print(title)
# print(link)
# print(price)
# print(shop)
# print('*'*100)
yield item
for page in range(2,101):
url = f'http://search.dangdang.com/?key=python%C5%C0%B3%E6&act=input&page_index={page}'
result = scrapy.Request(url,callback=self.parse)
yield result
项目总结构为:





![[计算机效率] 网站推荐:格式转换类](https://img-blog.csdnimg.cn/direct/8f41e29b7afd414b876bde9b8c9f040e.png)