简介
典型的压缩管道由四个组件组成:
编码:输入图像
x
x
x通过编码器函数
ε
\varepsilon
ε,将其转换为潜在表示
z
z
z。
量化:截断
z
z
z以丢弃一些不重要的信息
熵编码:使用某种形式的熵编码(例如:算术编码)来无损地存储截断的潜在
z
^
\hat z
z^
解码:原始
x
x
x被重构为通过使用
z
^
\hat z
z^通过解码器函数
D
D
D获得
x
^
\hat x
x^

需要注意的是,压缩失真主要是由量化步骤造成的——编码器可以是一个双射函数。我们根据某种失真度量来衡量原始图像与重构图像之间的接近程度,其中常见的选择是平方误差
d
d
d
d
(
x
,
x
^
)
=
∣
∣
x
−
x
^
∣
∣
2
2
d(x,\hat x)=||x-\hat x||^2_2
d(x,x^)=∣∣x−x^∣∣22
它使得图像数据在压缩和解压缩过程中丢失了一些信息,因此导致了压缩的失真。失真度量是用来衡量原始图像和压缩后的重建图像之间的差异程度的指标,通常使用的是平方误差,即重建像素值与原始像素值之间的差的平方。
虽然传统的压缩方法(例如JPEG)独立地优化了这些组件中的每一个,但基于神经的学习方法可以联合优化它们,这可能是非常有益的。自然地,这种神经方法建立在自动编码器架构上,由三个可学习的组件组成:编码器 ε θ \varepsilon_\theta εθ,解码器 D ψ D_\psi Dψ和熵模型 p ζ p_\zeta pζ,其中 θ \theta θ, ψ \psi ψ和 ζ \zeta ζ是可训练的参数。
上文的速率失真理论在图像压缩中是一种重要的概念
用于平衡压缩比特率(速率)和压缩图像质量之间的关系。以下是速率失真理论在图像压缩中的详细解释:
- 速率(Rate):速率指的是用于表示和传输图像信息所需的比特数。在图像压缩中,我们希望以最小的比特数来表示图像,以减少存储和传输成本。通常情况下,速率与压缩比特率直接相关,即速率越低,表示压缩得越好。
- 失真(Distortion):失真是指压缩后的图像与原始图像之间的差异程度。在图像压缩中,失真通常以图像的均方误差(MSE)来衡量,即压缩后图像像素与原始图像像素之间的平均差的平方。压缩时,我们希望尽量减小失真,使压缩后图像尽可能接近原始图像。
- 速率失真函数(Rate-Distortion Function):速率失真函数描述了在给定失真水平下,所需的最小比特率。在图像压缩中,速率失真函数用于评估不同压缩算法或参数设置下的压缩性能。通常情况下,我们希望在给定的失真水平下,找到最小的速率失真函数值,以实现高效的图像压缩。
- 速率失真优化(Rate-Distortion Optimization):速率失真优化是指在给定失真水平的约束下,通过调整压缩算法或参数来最小化所需的比特率。在图像压缩中,速率失真优化的目标是找到最佳的压缩方案,以在给定失真水平下实现最小的比特率,或在给定比特率下实现最小的失真。
当我们进行图像压缩时,我们通常希望在减少文件大小(即减少比特率或速率)的同时尽可能地保持图像的质量。速率失真理论就是帮助我们找到这种平衡的一种方法。
首先,我们要明白,压缩图像就是要以尽量少的比特(或者说数字信息)来表示图像,这样就可以节省存储空间或者传输带宽。但是,当我们减少了比特率时,压缩后的图像质量往往会下降,因为我们丢失了一些原始图像中的细节和信息。
速率失真理论告诉我们,存在一种平衡点,在这个点上,我们以最小的比特率来压缩图像,同时仍然保持了所需的图像质量。这个平衡点取决于所使用的压缩算法和质量度量标准。
换句话说,速率失真理论帮助我们找到了一个最优的压缩方案,即在压缩图像时,我们尽可能地减少比特率,但是又不至于使图像质量变得太差。这样,我们就可以在存储或传输图像时达到更高的效率,同时又不牺牲图像的观感质量。
那么如何将这个概念加入到神经网络编码中呢
在这篇论文中《Improving Statistical Fidelity for Neural Image Compression with Implicit Local Likelihood Models》介绍了一种方法,下文将以这篇论文为基础展开理论介绍
论文地址:https://proceedings.mlr.press/v202/muckley23a/muckley23a.pdf
代码地址:https://github.com/facebookresearch/NeuralCompression/tree/main/projects/illm
在神经网络编码中引入速率失真理论的关键在于将其约束条件融入训练过程中,以平衡压缩率、失真度量和统计保真度。这需要设计合适的损失函数和训练目标,以确保编码器和解码器的性能在压缩数据时能够尽可能地接近最优的速率失真性能。接下来,我们将探讨如何将速率失真理论融入到神经网络编码中,并详细介绍其中涉及的方法和公式。
符号表示
我们使用了一些数学符号和概念来描述神经网络编码器的设计。
首先引入了使用概率空间 ( Ω , F , P ) (Ω,F,P) (Ω,F,P)来描述随机变量的行为。在这里, Ω Ω Ω代表样本空间, F F F代表事件空间, P P P则是概率函数,用于描述事件发生的可能性。
然后引入了两个随机变量, X : Ω → X X:Ω→X X:Ω→X 和 Y : Ω → Y Y:Ω→Y Y:Ω→Y,它们分别将样本空间映射到 X X X和 Y Y Y的值域 ,它们分别表示原始信号和编码后的信号,这两个随机变量都是函数,将样本空间映射到它们的取值范围上。我们用大写字母表示随机变量,例如 X X X, Y Y Y,
用小写字母表示它们的具体取值,如 x ∈ X x ∈ X x∈X。分布函数 P X P_X PX表示 X X X的概率分布,而 p x px px表示 P X P_X PX的概率质量函数。还引入了条件分布表示 P X ∣ Y P_{X|Y} PX∣Y,它描述了在给定 Y Y Y的情况下 X X X的分布情况。
这实际上是一系列概率测度,对于每个y的取值,都存在相应的条件分布 P X ∣ Y = y P_{X|Y=y} PX∣Y=y。期望值用 E x ∼ P X [ q ( x ) ] E_{x∼PX}[q(x)] Ex∼PX[q(x)]表示,也可以简写为 E [ q ( x ) ] E[q(x)] E[q(x)]。
速率失真感知理论
在有损压缩中,目标是尽可能用尽量少的比特(比特率)存储离散随机变量 X X X的结果 x ∼ P X x∼P_X x∼PX,例如自然图像,同时确保重构 x ^ ∼ P X ^ ∣ x \hat x∼P_{\hat X|x} x^∼PX^∣x的质量水平不低于 τ τ τ。这个方法表述为速率失真理论(Shannon,1948)。Shannon得出的最佳比特率R由速率失真函数表征:

其中 I ( ⋅ ; ⋅ ) I(·;·) I(⋅;⋅)表示互信息, ρ ( ⋅ , ⋅ ) ρ(·,·) ρ(⋅,⋅)是一个失真度量。Blau & Michaeli(2019)将上述速率失真函数扩展为另一个约束方法,该约束方法表征了重构的统计数据与真实数据分布的统计数据之间的相似程度:
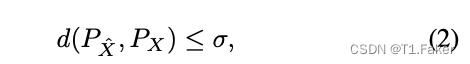
这里 d ( ⋅ , ⋅ ) d(·,·) d(⋅,⋅) 是分布之间的某种差异度量,如Kullback-Leibler散度(KLD)。
接下来,将展示如何通过逼近和放宽受限速率失真感知函数 R ( τ , σ ) R(τ,σ) R(τ,σ) 来构建可微分的训练目标。也就是损失函数。
有损压缩编解码器损失优化
在有损压缩算法中,我们的目标是设计一个编码器和解码器,能够将原始数据 x x x压缩成潜在表示 y y y,并能够从该潜在表示重构出近似原始数据 x ^ \hat{x} x^。为了在训练过程中平衡压缩率、失真度量和统计保真度,我们需要引入概率空间和相关的概率分布。
我们假设源符号 x x x将被编码成一个(量化的)潜在表示 y = f ( x ) y = f(x) y=f(x),其中 f : X → Y f:X→Y f:X→Y。随后,我们使用一个熵编码器 g ω ( y ) g_ω(y) gω(y)来将 y y y无损地压缩成其可能的最短比特串。
将 r ( x ) : = ∣ g ω ( y ) ∣ r(x) := |g_ω(y)| r(x):=∣gω(y)∣表示由 g ω g_ω gω生成的二进制串的比特率或长度。由于发送方和接收方都具有熵编码器的共同知识,接收方可以应用解码器 h : Y → X h:Y→X h:Y→X来恢复源信号 x ^ = h ( y ) = f ◦ h ( x ) \hat x = h(y) = f ◦ h(x) x^=h(y)=f◦h(x)。
我们将编码器、解码器和熵编码器的元组称为有损编解码器 ( f , g ω , h ) (f, g_ω, h) (f,gω,h)。在这个设计中,我们的目标是通过学习参数化的有损编解码器 ( f φ , g ω , h υ ) (f_φ, g_ω, hυ) (fφ,gω,hυ)来优化。在这种情况下,编码器 f φ f_φ fφ和解码器 h υ h_υ hυ是神经网络,熵编码器 g ω g_ω gω将由对表示的边缘参数化近似定义,换句话说,我们需要学习 P Y ∣ ω P_{Y|ω} PY∣ω。为了实现这一目标,我们需要将速率失真理论的约束应用于训练目标中,以便在优化过程中平衡比特率、失真度量和统计保真度。
使用拉格朗日乘数放松(1)速率和(2)失真感知函数的约束,并考虑到统计保真度约束,我们的训练目标如下:
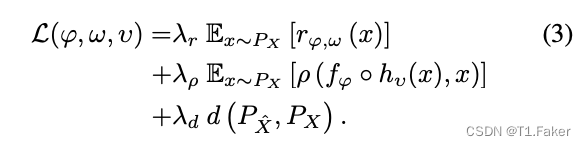
在这里详细描述我们损失编解码器的功能形式之前,需要说明如何在实践中近似计算分布的差异。
机械地说,通常很容易为 ρ ( f φ ◦ h υ ( x ) , x ) ρ(f_φ ◦ h_υ(x), x) ρ(fφ◦hυ(x),x)指定失真函数,但最小化 P X ^ P_{\hat X} PX^ 和 P X P_X PX 之间的差异项 d ( P X ^ , P X ) d(P_{\hat X} , P_X) d(PX^,PX) 可能会更加复杂。一种常用的技术是使用生成对抗网络(GANs)来优化对称的Jensen-Shannon散度(JSD)(Goodfellow等,2014;Nowozin等,2016)。JSD是分布之间的一种合适的散度度量,这意味着如果有足够的训练样本并且模型类 P X ^ P_{\hat X} PX^ 足够丰富,就可以准确地近似 P X P_X PX。Goodfellow等(2014)展示了JSD通过众所周知的GAN最小最大优化问题得到最小化:
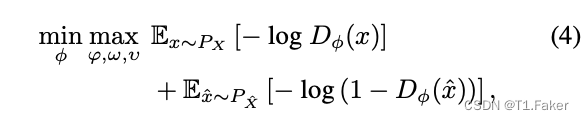
其中 D ϕ D_ϕ Dϕ是一个参数化的鉴别器函数(具有参数 ϕ ϕ ϕ),用于估计一个样本是否来自真实数据分布,我们使用了简写 x ^ = f φ ◦ h υ ( x ) \hat x = f_φ ◦ h_υ(x) x^=fφ◦hυ(x)。在神经压缩中,假设 P X ^ P_{\hat X} PX^ 是联合分布 P X P X ^ ∣ x P_XP_{\hat X|x} PXPX^∣x 的边际分布。为了计算(4)中的经验风险,我们为 x x x 和 x ^ \hat x x^ 绘制不同的样本。从(4)中反转符号的生成器损失函数是:
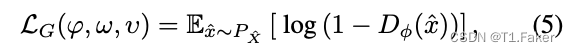
可以将其用作(3)中 d ( P X ^ , P X ) d(P_{\hat X} , P_X) d(PX^,PX) 的替代项(用于鉴别器的交替最小化)。这种方法已经应用于几种神经压缩系统中(Agustsson等,2019;Mentzer等,2020)。与用于图像生成的GAN相比, P X ^ P_{\hat X} PX^ 的任务由于神经压缩任务的属性而大大简化。因此,重新设计了鉴别器,以反映压缩所需的投影的局部性。
论文结构和方法
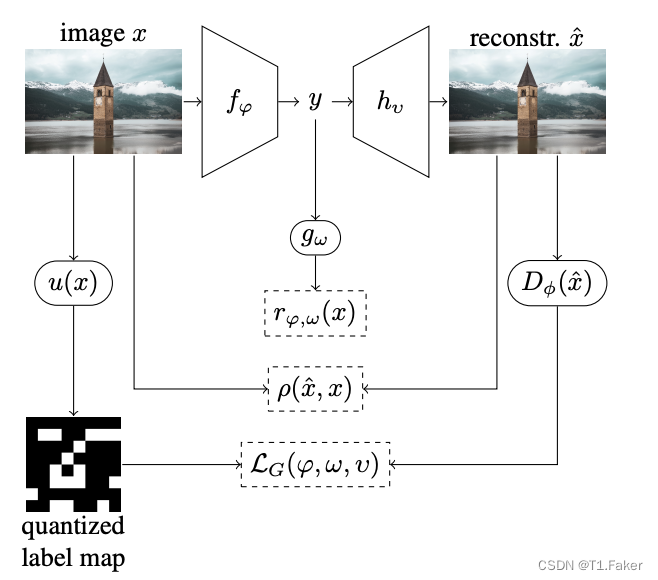
图 2. 使用基于鉴别器的差异最小化的学习有损压缩系统概述。图像
x
x
x 被编码并量化为潜变量
y
y
y。概率模型
g
ω
g_ω
gω 可以对
y
y
y 进行熵编码,并估计速率
r
φ
,
ω
r_{φ,ω}
rφ,ω。解码器
h
υ
h_υ
hυ 将量化的
y
y
y 转换回压缩图像
x
^
\hat x
x^。为了提高统计保真度,还通过一个鉴别器
D
ϕ
D_ϕ
Dϕ 进行训练,该鉴别器试图匹配预训练标签器
u
u
u 的标签。
自动编码器架构
在这里,描述了编码器 f φ f_φ fφ,解码器 h υ h_υ hυ 以及由熵编码器 g ω g_ω gω 使用的潜在边缘 P Y ∣ ω P_{Y|ω} PY∣ω。由于速率失真函数与变分推断之间的关系,神经编解码器可以被视为一种变分自动编码器的类型(Balle等人,2017)。与神经压缩领域的先前工作一致,使用了两级分层自动编码器来建模数据分布,也称为超先验模型(Balle等人,2018)。这个模型类别以自身为模型的主导先验 P Y ∣ ω P_{Y|ω} PY∣ω 命名,本身被建模为一个潜变量模型:
P Y ∣ ω = ∑ P Y ∣ z ; ω P z P_{Y∣ω}=\sum P_{Y∣z;ω}P_z PY∣ω=∑PY∣z;ωPz
先前的工作对先验分布进行了不同的选择,例如条件高斯(Balle等人,2018;Minnen等人,2018;Mentzer等人,2020)。采用了Minnen等人(2018)的方法,对高斯的均值和尺度进行条件设定,并将其称为均值-尺度超先验模型。对于编码器和解码器的架构,遵循了Mentzer等人(2020)的方法,其使用的模型比Minnen等人(2018)使用的模型更大更深。
隐式局部似然模型
为了开发的似然模型,假设可以访问一个标签向量函数 u : X → 0 , 1 ( C + 1 ) × W × H u:X→{0,1}^{(C+1)×W×H} u:X→0,1(C+1)×W×H。对于数据集中的任何 x x x, u u u 输出一个三维空间分布的独热目标向量图,其中 C C C 是标签数量, W W W 是潜空间宽度, H H H 是潜空间高度。将零标签保留为“假”类,用于指示重构图像,并使用其余的 C C C 类来标记原始图像。定义 b 0 b0 b0 作为一个独热目标 ( C + 1 ) × W × H (C+1)×W×H (C+1)×W×H 张量,其中 C C C 维度中的零元素的值为 1,实际上是标准 GAN 术语中的“假”类。
遵循Sushko等人(2022),现在可以定义两个 c-GAN 风格的对抗损失函数:
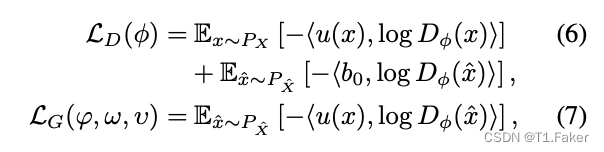
其中 D ϕ ( x ) D_ϕ(x) Dϕ(x) 现在是一个矢量值函数, ⟨ ⋅ , ⋅ ⟩ ⟨·,·⟩ ⟨⋅,⋅⟩ 表示内积。请注意,与其仅区分原始和重构图像不同,这里鉴别器的目标是区分原始图像的 C C C 个图像标签,以及检测重构图像。生成器损失对应于Goodfellow等人(2014)提出的非饱和 GAN 损失,扩展到多标签情况。它的目标是为重构图像最大化相应实际图像标签的鉴别器概率。这实际上允许鉴别器在标签中使用更多的局部信息。
标签函数的选择
标签函数的选择影响方法的成功。方程(6)和(7)允许广泛类别的标签,包括当设置 W = H = 1 W = H = 1 W=H=1 时的全局图像标签,以及 H , W > 1 H,W > 1 H,W>1 时的空间分布标签。由于目标是在隐式似然模型中强制执行局部性,论文选择应用 VQ-VAEs(van den Oord等人,2017;Razavi等人,2019)。通过向量量化,将 VQ-VAE 自动编码器的潜空间划分为具有集群均值 m c c = 1 C {mc}_{c=1}^{C} mcc=1C 的 C C C 个簇。对于原始图像,设置为如下
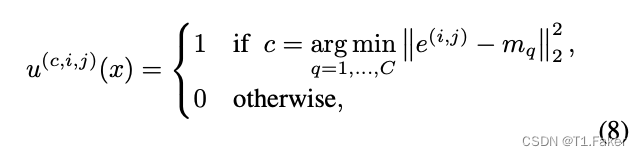
这里 e ( i , j ) e^{(i,j)} e(i,j) 是来自 VQ 编码器位置 ( i , j ) (i, j) (i,j) 处的通道向量。VQ-VAE 编码器将潜向量空间划分为 C C C 个Voronoi单元格。由于Voronoi单元格是凸的,任何两点都是路径连通的。此外,由于解码器架构是连续映射,因此即使在重构空间 X X X 中,路径连通性仍然保持不变。换句话说,使用 VQ-VAE 方法,标签空间的局部性意味着图像空间的局部性。这与其他标签方法形成对比,例如 ImageNet 类。没有用于生成潜在代码的模型,论文的方法不考虑无条件生成,尽管可以使用自回归技术实现这一点。我们的 VQ-VAE 架构基于带有一些修改的 VQ-GAN 变体(Esser等人,2021):
论文使用 ChannelNorm(Mentzer等人,2020)代替 GroupNorm,以改善不同图像区域的归一化统计稳定性。
我们使用 XCiT(El-Nouby等人,2021)用于注意力层,以提高计算效率。
鉴于此架构,似然函数的数量由潜空间的空间大小( W × H W×H W×H)和 VQ-VAE 的代码本大小 C C C 控制。更大的潜空间和代码本将导致更小的似然邻域。除非另有说明,使用 256 × 256 256×256 256×256 图像的 32 × 32 32×32 32×32 潜空间和代码本大小为 1024 1024 1024。
鉴别器架构
对于鉴别器,论文使用了 U-Net 架构(Ronneberger等人,2015),这是Sushko等人(2022)在语义图像合成背景下提出的。在他们的情况下,鉴别器的目标是使用语义分割图的条件标签为真实图像的像素打上相应的标签,同时将生成图像中的像素标记为“假”。在这个情况下,鉴别器不是预测手动注释的语义类别,而是预测标签函数 u u u 提供的标签中的类别。U-Net 变体使用了 LeakyReLU(Xu等人,2015)作为激活函数,并构建在残差块上,而不是原始 U-Net 的前馈块上(Ronneberger等人,2015)。由于潜在分辨率与图像分辨率不同,在 32 × 32 32×32 32×32 潜空间的输出路径处截断了 U-Net 的输出路径,该潜空间由 u ( x ) u(x) u(x) 提供。