说明:
- KVM版本:5.9.1
- QEMU版本:5.0.0
- 工具:Source Insight 3.5, Visio
概述
- 从本文开始将研究一下virtio;
- 本文会从一个网卡虚拟化的例子来引入virtio,并从大体架构上进行介绍,有个宏观的认识;
- 细节的阐述后续的文章再跟进;
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
1. 网卡
1.1 网卡工作原理
先来看一下网卡的架构图(以Intel的82540为例):

- OSI模型,将网络通信中的数据流划分为7层,最底下两层为物理层和数据链路层,对应到网卡上就是PHY和MAC控制器;
- PHY:对应物理层,负责通信设备与网络媒介(网线)之间的互通,它定义传输的光电信号、线路状态等;
- MAC控制器:对应数据链路层,负责网络寻址、错误侦测和改错等;
- PHY和MAC通过MII/GMII(Media Independent Interface)和MDIO(Management Data Input/output)相连;
- MII/GMII(Gigabit MII):由IEEE定义的以太网行业标准,与媒介无关,包含数据接口和管理接口,用于网络数据传输;
- MDIO接口,也是由IEEE定义,一种简单的串行接口,通常用于控制收发器,并收集状态信息等;
- 网卡通过PCI接口接入到PCI总线中,CPU可以通过访问BAR空间来获取数据包,也有网卡直接挂在内存总线上;
- 网卡还有一颗EEPROM芯片,用于记录厂商ID、网卡的MAC地址、配置信息等;
我们主要关心它的数据流,所以,看看它的工作原理吧:
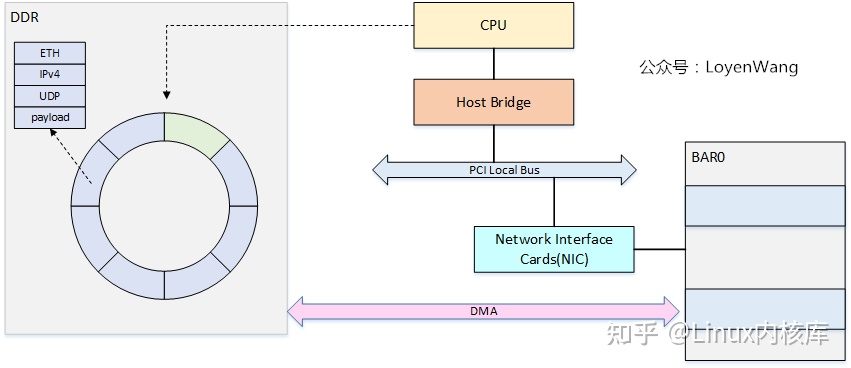
- 网络包的接收与发送,都是典型的生产者-消费者模型,简单来说,CPU会在内存中维护两个ring-buffer,分别代表RX和TX,ring-buffer中存放的是描述符,描述符里包含了一个网络包的信息,包括了网络包地址、长度、状态等信息;
- ring-buffer有头尾两个指针,发送端为:TDH(Transmit Descriptor Head)和TDT(Transmit Descriptor Tail),同理,接收端为:RDH(Receive Descriptor Head)和RDT(Receive Descriptor Tail),在数据传输时,由CPU和网卡来分开更新头尾指针的值,这也就是生产者更新尾指针,消费者更新头指针,永远都是消费者追着生产者跑,ring-buffer也就能转起来了;
- 数据的传输,使用DMA来进行搬运,CPU的拷贝显然是一种低效的选择。在之前PCI系列分析文章中分析过,PCI设备有自己的BAR空间,可以通过DMA在BAR空间和DDR空间内进行搬运;
1.2 Linux网卡驱动
在网卡数据流图中,我们也基本看到了网卡驱动的影子,驱动与网卡之间是异步通信:

- 驱动程序负责硬件的初始化,以及TX和RX的ring-buffer的创建及初始化;
- ndo_start_xmit负责将网络包通过驱动程序发送出去,netif_receive_skb负责通过驱动程序接收网络包数据;
- 数据通过struct sk_buff来存储;
- 发送数据时,CPU负责准备TX网络包数据以及描述符资源,更新TDT指针,并通知NIC可以进行数据发送了,当数据发送完毕后NIC通过中断信号通知CPU进行下一个包的处理;
- 接收数据时,CPU负责准备RX的描述符资源,接收数据后,NIC通过中断通知CPU,驱动程序通过调度内核线程来处理网络包数据,处理完成后进行下一包的接收;
2. 网卡全虚拟化
2.1 全虚拟化方案
全虚拟化方案,通过软件来模拟网卡,Qemu+KVM的方案如下图:
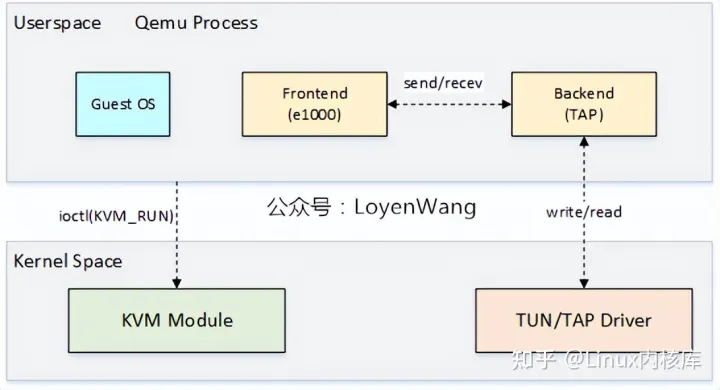
- Qemu中,设备的模拟称为前端,比如e1000,前端与后端通信,后端再与底层通信,我们来分别看看发送和接收处理的流程;
- 发送:
- Guest OS在准备好网络包数据以及描述符资源后,通过写TDT寄存器,触发VM的异常退出,由KVM模块接管;
- KVM模块返回到Qemu后,Qemu会检查VM退出的原因,比如检查到e1000寄存器访问出错,因而触发e1000前端工作;
- Qemu能访问Guest OS中的地址内容,因而e1000前端能获取到Guest OS内存中的网络包数据,发送给后端,后端再将网络包数据发送给TUN/TAP驱动,其中TUN/TAP为虚拟网络设备;
- 数据发送完成后,除了更新ring-buffer的指针及描述符状态信息外,KVM模块会模拟TX中断;
- 当再次进入VM时,Guest OS看到的是数据已经发送完毕,同时还需要进行中断处理;
- Guest OS跑在vCPU线程中,发送数据时相当于会打算它的执行,直到处理完后再恢复回来,也就是一个严格的同步处理过程;
- 接收:
- 当TUN/TAP有网络包数据时,可以通过读取TAP文件描述符来获取;
- Qemu中的I/O线程会被唤醒并触发后端处理,并将数据发送给e1000前端;
- e1000前端将数据拷贝到Guest OS的物理内存中,并模拟RX中断,触发VM的退出,并由KVM模块接管;
- KVM模块返回到Qemu中进行处理后,并最终重新进入Guest OS的执行中断处理;
- 由于有I/O线程来处理接收,能与vCPU线程做到并行处理,这一点与发送不太一样;
2.2 弊端
- Guest OS去操作寄存器的时候,会触发VM退出,涉及到KVM和Qemu的处理,并最终再次进入VM,overhead较大;
- 不管是在Host还是Guest中,中断处理的开销也很大,中断涉及的寄存器访问也较多;
- 软件模拟的方案,吞吐量性能也比较低,时延较大;
所以,让我们大声喊出本文的主角吧!
3. 网卡半虚拟化
在进入主题前,先思考几个问题:
- 全虚拟化下Guest可以重用驱动、网络协议栈等,但是在软件全模拟的情况下,我们是否真的需要去访问寄存器吗(比如中断处理),真的需要模拟网卡的自协商机制以及EEPROM等功能吗?
- 是否真的需要模拟大量的硬件控制寄存器,而这些寄存器在软件看来毫无意义?
- 是否真的需要生产者/消费者模型的通知机制(寄存器访问、中断)?
3.1 virtio
网卡的工作过程是一个生产者消费者模型,但是在前文中可以看出,在全虚拟化状态下存在一些弊端,一个更好的生产者消费者模型应该遵循以下原则:
- 寄存器只被生产者使用去通知消费者ring-buffer有数据(消费者可以继续消费),而不再被用作存储状态信息;
- 中断被消费者用来通知生产者ring-buffer是非满状态(生产者可以继续生产);
- 生产者和消费者的状态信息应该存储在内存中,这样读取状态信息时不需要VM退出,减少overhead;
- 生产者和消费者跑在不同的线程中,可以并行运行,并且尽可能多的处理任务;
- 非必要情况下,相互之间的通知应该避免使用;
- 忙等待(比如轮询)不是一个可以接受的通用解决方案;
基于上述原则,我们来看看从特殊到一般的过程:

- 第一行是针对网卡的实现,第二行更进一步的抽象,第三行是通用的解决方案了,对I/O操作的虚拟化通用支持;
所以,在virtio的方案下,网卡的虚拟化看上去就是下边这个样子了:

- Hypervisor和Guest都需要实现virtio,这也就意味着Guest的设备驱动知道自己本身运行在VM中;
- virtio的目标是高性能的设备虚拟化,已经形成了规范来定义标准的消息传递API,用于驱动和Hypervisor之间的传递,不同的驱动和前端可以使用相同的API;
- virtio驱动(比如图中的virtio-net driver)的工作是将OS-specific的消息转换成virtio格式的消息,而对端(virtio-net frontend)则是做相反的工作;
virtio的数据传递使用scatter-gather list(sg-list):
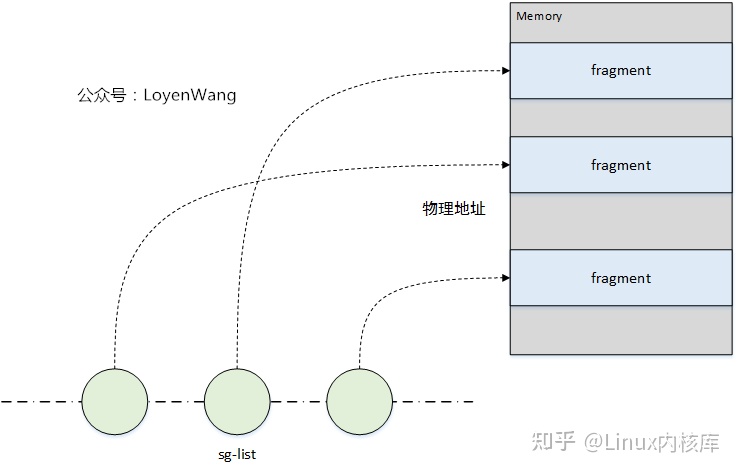
- sg-list是概念上的(物理)地址和长度对的链表,通常作为数组来实现;
- 每个sg-list描述一个多块的buffer,消费者用它来作为输入或输出操作;
virtio的核心是virtqueue(VQ)的抽象:
- VQ是队列,sg-list会被Guest的驱动放置到VQ中,以供Hypervisor来消费;
- 输出sg-list用于向Hypervisor来发送数据,而输入sg-list用于接收Hypervisor的数据;
- 驱动可以使用一个或多个virqueue;

- 当Guest的驱动产生一个sg-list时,调用add_buf(SG, Token)入列;
- Hypervisor进行出列操作,并消费sg-list,并将sg-list push回去;
- Guest通过get_buf()进行清理工作;
上图说的是数据流方向,那么事件的通知机制如下:

- 当Guest驱动想要Hypervisor消费sg-list时,通过VQ的kick来进行通知;
- 当Hypervisor通知Guest驱动已经消费完了,通过interupt来进行通知;
大体的数据流和控制流讲完了,细节实现后续再跟进了。
3.2 半虚拟化方案
那么,半虚拟化框架下的网卡虚拟化数据流是啥样的呢?
- 发送

- 接收

相信你应该对virtio有个大概的了解了,好了,收工。