论文地址:https://arxiv.org/pdf/2210.11610.pdf
相关博客
【自然语言处理】【chatGPT系列】大语言模型可以自我改进
【自然语言处理】【ChatGPT系列】WebGPT:基于人类反馈的浏览器辅助问答
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
【自然语言处理】【ChatGPT系列】Chain of Thought:从大模型中引导出推理能力
【自然语言处理】【ChatGPT系列】InstructGPT:遵循人类反馈指令来训练语言模型
【自然语言处理】【ChatGPT系列】大模型的涌现能力
一、简介
规模
(scaling)
\text{(scaling)}
(scaling)能够使大语言模型
(LLM)
\text{(LLM)}
(LLM)在各类自然语言处理任务
(NLP)
\text{(NLP)}
(NLP)上实现了state-of-the-art。更重要的是,当大语言模型达到数千亿参数量是涌现出了新的能力:
in-context few-shot learning
\text{in-context few-shot learning}
in-context few-shot learning使得大语言模型在未见过的任务上表现的很好;
Chain-of-Thought(CoT) prompting
\text{Chain-of-Thought(CoT) prompting}
Chain-of-Thought(CoT) prompting展示了大模型在各种任务上的推理能力;
self-consistency
\text{self-consistency}
self-consistency通过自评估多条推理路径进一步改善的效果。
尽管在大规模语料库上训练的模型具有令人难以置信的能力,根本性使模型超过 few-shot baselines \text{few-shot baselines} few-shot baselines仍然需要在大量的高质量监督数据集上进行微调。 FLAN \text{FLAN} FLAN和 T0 \text{T0} T0规划了数十个基准 NLP \text{NLP} NLP数据集来提高模型在未见过任务上的 zero-shot \text{zero-shot} zero-shot效果; InstructGPT \text{InstructGPT} InstructGPT通过众包的方式为各种文本指令提供人类的答案,从而使模型更好的对齐人类的指令。虽然在收集高质量监督数据上付出了巨大的努力,但是人脑刚好相反,其具有元认知过程的能力,其可以在没有外部输入的情况下提高自身的推理能力。
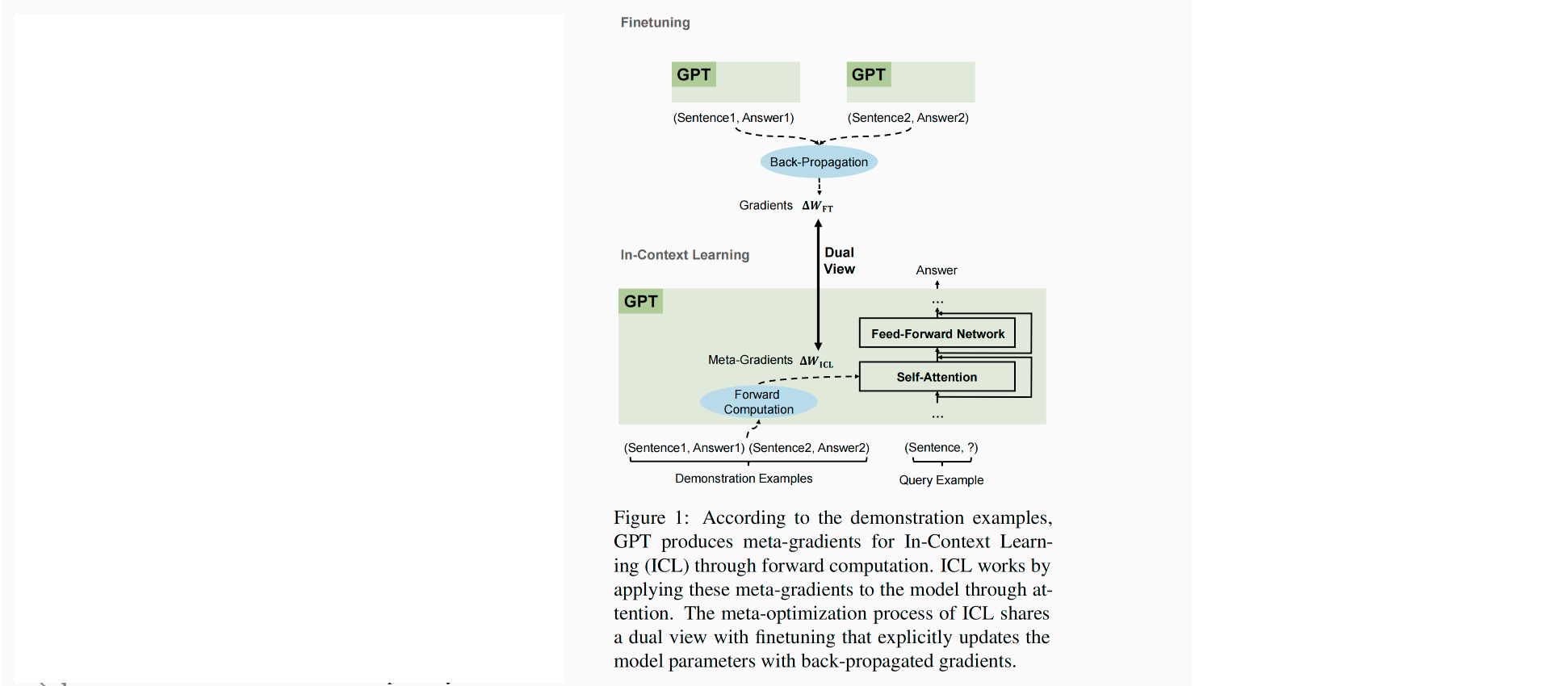
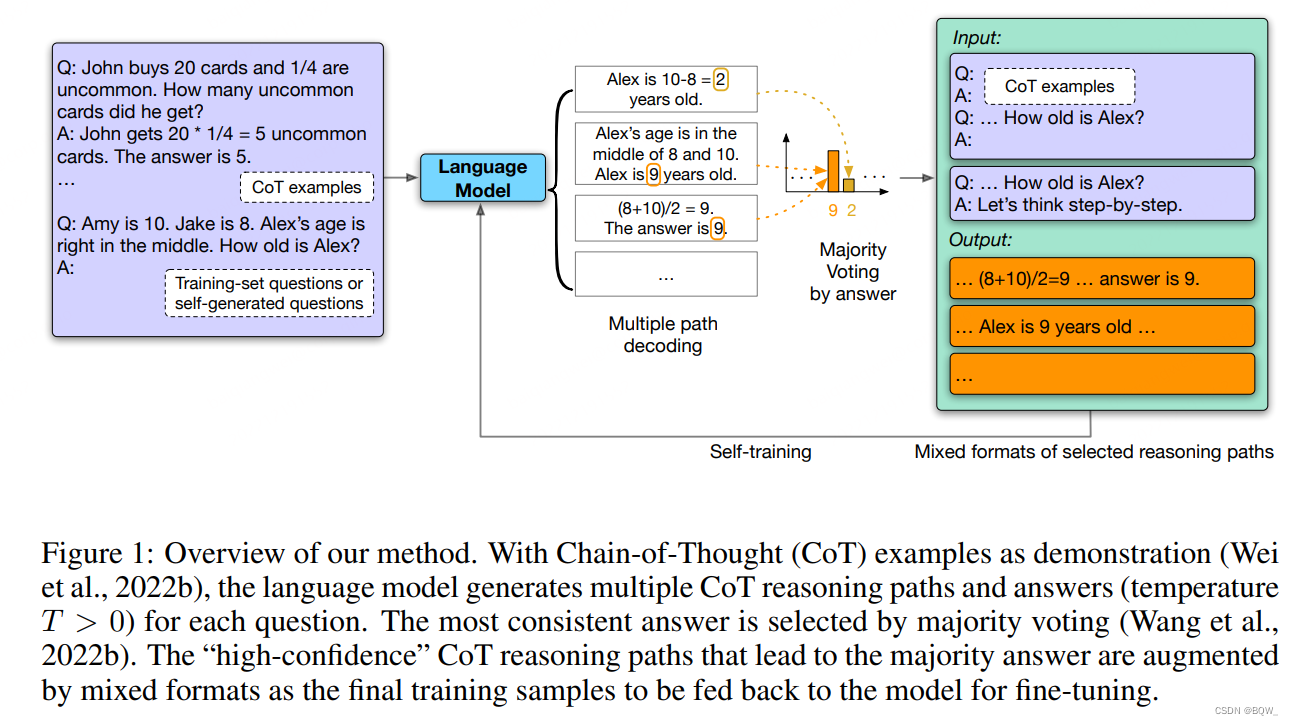
在本文中,研究在不使用监督数据的情况下 LLM \text{LLM} LLM自我改善推理能力。我们展示了仅使用多个 NLP \text{NLP} NLP任务数据集的输入序列(没有真实的输出序列),预训练的 LLM \text{LLM} LLM就能够改善领域内和领域外任务的效果。本文方法如上图所示:使用 Chain-of-Thought(CoT) \text{Chain-of-Thought(CoT)} Chain-of-Thought(CoT)作为 prompts \text{prompts} prompts来采样多个预测值,然后使用多数投票的方式过滤掉"高置信度"的预测,最后在这些高置信度预测上微调 LLM \text{LLM} LLM。得到的模型在贪心和多路径评估上都改善了推理能力。我们称以这种方式微调模型为语言模型的自我改善 (Language Model Self-Improved,LMSI) \text{(Language Model Self-Improved,LMSI)} (Language Model Self-Improved,LMSI)。这与人类大脑的学习方式类似:给定一个问题,通过多次思考得到不同的可能结果,总结出问题应该如何解决的结论,然后从自己的解决方案中学习或者记忆。我们使用预训练的 PaLM-540B LLM \text{PaLM-540B LLM} PaLM-540B LLM验证了本文的方法,本文的方法不仅改善了训练的任务 ( 在GSM8K上, 74.4 % → 82.1 % ; 在DROP上, 78.2 % → 83.0 % ; 等 ) (\text{在GSM8K上,}74.4\%\rightarrow 82.1\%;\text{在DROP上,}78.2\%\rightarrow83.0\%;\text{等}) (在GSM8K上,74.4%→82.1%;在DROP上,78.2%→83.0%;等),而且也增强了领域外的测试任务 (AQUA、StrategyQA,MNLI) \text{(AQUA、StrategyQA,MNLI)} (AQUA、StrategyQA,MNLI),在不依赖监督数据的情况下在许多任务上实现了 state-of-the-art \text{state-of-the-art} state-of-the-art表现。最后,我们在自生成的额外输入问题和 few-shot CoT prompts \text{few-shot CoT prompts} few-shot CoT prompts上进行了初步的研究,其能够进一步的减少模型自我改善所需要的人工。我们希望本文简单的方法和强有力的实验结果能够鼓励社区在未来的工作中研究不使用人类简单来达到 LLMs \text{LLMs} LLMs的最佳性能。
本文的贡献如下:
- 我们证明了,通过使用没有真实输出的数据集,并利用 CoT \text{CoT} CoT推理和 self-consistency \text{self-consistency} self-consistency,大语言模型可以实现自我改善,并在领域内多任务上实现有力的效果,以及领域外的泛化。我们在 ARC,OpenBookQA和ANLI \text{ARC,OpenBookQA和ANLI} ARC,OpenBookQA和ANLI数据集上实现了 state-of-the-art \text{state-of-the-art} state-of-the-art级别的结果。
- 我们对微调后的训练采样形式和采样温度进行了详细的消融研究,并为大多数成功自改善的 LLM \text{LLM} LLM确定了关键的设计选择。
- 我研究了其他两种自我改进的方法,其中模型从有效的输入问题中生成额外的问题,以及生成 few-shot CoT prompt \text{few-shot CoT prompt} few-shot CoT prompt模板。
二、方法
本文方法总体如图1所示:给定一个预训练的大语言模型 M M M和一个仅包含问答的训练数据集 D t r a i n = { x i } i = 1 D \mathcal{D}^{train}=\{x_i\}_{i=1}^D Dtrain={xi}i=1D。对于每个问题 x i ∈ D t r a i n x_i\in \mathcal{D}^{train} xi∈Dtrain,应用具有采样问答 T > 0 T>0 T>0的多路径解码来生成 m m m个推理路径和答案 { r i 1 , r i 2 , … , r i m } \{r_{i_1},r_{i_2},\dots,r_{i_m}\} {ri1,ri2,…,rim},并使用多少投票 (self-consistency) \text{(self-consistency)} (self-consistency)来选择最一致且最高置信度的答案。然后保留所有导致最一致答案的推理路径,应用混合形式的 prompts \text{prompts} prompts和答案来增强,并在这些自生成的推理答案数据上微调模型。
1. 生成和过滤多个推理路径
Self-consistency
\text{Self-consistency}
Self-consistency在推理任务上带来了巨大的改善(例如,在
GSM8K
\text{GSM8K}
GSM8K数据集上
56.5
%
→
74.4
%
56.5\%\rightarrow74.4\%
56.5%→74.4%),并且贪心解码和多元解码之间的差距表明,使用自选的高置信度推理路径作为训练数据,有潜力进一步改善
M
M
M的推理能力。

对于每个训练问题
x
i
x_i
xi,采样
m
m
m个
CoT
\text{CoT}
CoT推理路径,表示为
{
r
i
1
,
r
i
2
,
…
,
r
i
m
}
\{r_{i_1},r_{i_2},\dots,r_{i_m}\}
{ri1,ri2,…,rim}(如上表1所示)。因为模型
M
M
M是通过来自Wei et al工作中的
CoT
\text{CoT}
CoT例子提示的,我们也应用
"The answer is"
\text{"The answer is"}
"The answer is"相同的输出解析来生成预测答案
{
y
i
1
,
y
i
2
,
…
,
y
i
m
}
\{y_{i_1},y_{i_2},\dots,y_{i_m}\}
{yi1,yi2,…,yim}。最一致的答案通过多数投票的方式选出(不一定是正确答案),表示为
y
i
~
=
arg
max
y
i
j
∑
k
=
1
m
I
(
y
i
j
=
y
i
k
)
\tilde{y_i}=\arg\max_{y_{i_j}}\sum_{k=1}^m\mathbb{I}(y_{i_j}=y_{i_k})
yi~=argmaxyij∑k=1mI(yij=yik)。对于所有的训练问题,我们将过滤那些
y
~
\tilde{y}
y~为最终答案的
CoT
\text{CoT}
CoT推理路径,并将其放入到自训练数据集中,表示为
D
self-consistent
=
{
x
i
,
r
~
i
}
\mathcal{D}^{\text{self-consistent}}=\{x_i,\tilde{\textbf{r}}_i\}
Dself-consistent={xi,r~i},其中
r
~
i
=
{
r
i
j
∣
1
≤
j
≤
m
,
y
i
j
=
y
~
i
}
\tilde{\textbf{r}}_i=\{r_{i_j}|1\leq j \leq m,y_{i_j}=\tilde{y}_i\}
r~i={rij∣1≤j≤m,yij=y~i}。
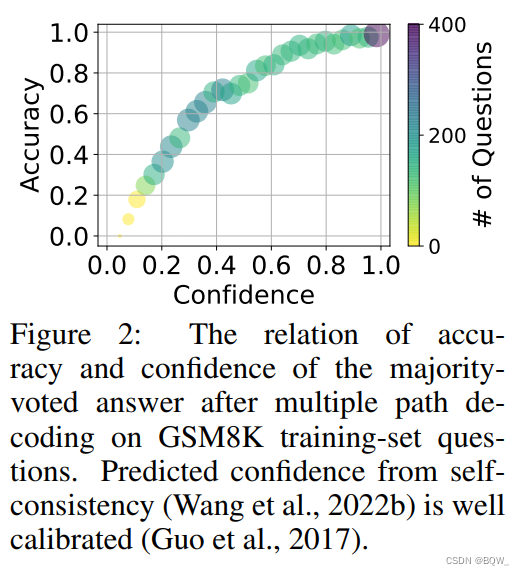
不使用任何真实的标签来过滤样本是很重要的,自我生成的 CoT \text{CoT} CoT推理路径大多数是可靠的,并且错误的答案也不会伤害模型的自我改善能力。上图绘制了 GSM8K \text{GSM8K} GSM8K训练集对于每个问题生成的 CoT \text{CoT} CoT路径置信度和准确率的关系。置信度是结果为 y ~ \tilde{y} y~的 CoT \text{CoT} CoT路径数量除以总路径数量 m m m。 y y y轴是在某个确定的置信度下的 y ~ \tilde{y} y~的准确率。圆形区域和颜色深浅表示该置信度下的问题数量。可以观察到越确信的答案越可能是正确的,意味着当一个问题有越多的一致 CoT \text{CoT} CoT路径,那么对应的 y ~ \tilde{y} y~越可能是正确的。另一方面,当 y ~ \tilde{y} y~是错误的,其可能没有多少 CoT \text{CoT} CoT路径支持,为训练样本带来有效的噪音。
2. 使用混合格式进行训练

为了避免语义模型过拟合至具体的 prompts \text{prompts} prompts或者答案风格,我们为每个推理路径创建了4中不同的格式,并且混合至自训练数据中(如上表2所示)。在第一种形式中,将小部分的 Chain-of-Thought examples \text{Chain-of-Thought examples} Chain-of-Thought examples作为新问题的前缀,而语言模型的输出被训练为过滤后的 CoT \text{CoT} CoT推理路径相同。在第二种格式中,我们使用问题和其直接答案作为标准的 prompting \text{prompting} prompting,并且语言模型的输出也仅包含直接的答案。第三和第四种形式也类似于第一和第二种,除了没有给问答对的样例,因此模型将要在 in-context zero-shot \text{in-context zero-shot} in-context zero-shot的情况下学习。在第三种形式中,我们希望模型在不拼接包含 CoT \text{CoT} CoT推理的样例情况下输出 CoT \text{CoT} CoT推理,我们将"Let’s think step by step."追加至输入序列末尾,来指导语言模型逐步的生成 CoT \text{CoT} CoT推理路径。混合格式的训练样本会用来微调预训练语言模型 M M M。
3. 生成问题和 prompts \text{prompts} prompts
给定一组训练问题以及少量的人工撰写的 Chain-of-Thought \text{Chain-of-Thought} Chain-of-Thought样例作为 prompts \text{prompts} prompts,我们提出的方法能够使模型自我改善。然而,若训练问题或者 CoT \text{CoT} CoT样本的数量有限时,我们的方法可能无法生成足够的样本用户模型自训练。需要人类工程师从网络上收集问题。为了进一步减少人工,我们研究了如何自生成更多的训练问题和 prompts \text{prompts} prompts。
3.1 问题生成
先前的一些工作讨论了使用 LLMs \text{LLMs} LLMs来生成多样训练样本进行 few-shot \text{few-shot} few-shot数据增强。然而,这些方法都是为分类任务设计的,并且需要为每个 few-shot \text{few-shot} few-shot样本提供真实标签。我们使用简单且有效的方法来为领域内生成多样的问题。具体来说,我们随机的选择几个现有的问题,将其按照随机的顺序拼接起来作为输入 prompt \text{prompt} prompt,并且让语言模型生成连续的序列作为新问题。我们重复这个过程来获得大量的新问题,并使用 self-consistency \text{self-consistency} self-consistency来保留高置信度的答案。这些问题会被用来作为自生成的训练问题。
3.2 Prompt \text{Prompt} Prompt生成
给定一个问题集合,人工撰写一些
CoT
\text{CoT}
CoT样例作为能够带来最终答案的推理路径。在不使用人工
prompts
\text{prompts}
prompts的
zero-shot
\text{zero-shot}
zero-shot设定中,我们能够使用模型本身来生成这些
CoT
\text{CoT}
CoT路径。遵循Kojima et al.,在答案开始处添加
A: Let’s think step by step.
\text{A: Let's think step by step.}
A: Let’s think step by step.,并且让语言模型来生成连续的推理路径。然后使用这些生成的推理路径作为
few-shot CoT prompting
\text{few-shot CoT prompting}
few-shot CoT prompting样本。
三、实验设置
1. 任务和数据集
-
算术推理
我们使用数学问题集 GSM8K \text{GSM8K} GSM8K,以及一个需要数字推理能力的阅读理解基准 DROP \text{DROP} DROP。遵循
Zhou et al.等人的工作将 DROP \text{DROP} DROP划分为足球相关和非足球相关的训练子集。 -
常识推理
我们使用 OpenBookQA \text{OpenBookQA} OpenBookQA数据集和 ARC \text{ARC} ARC数据集。对于 ARC \text{ARC} ARC,我们在实验中仅使用 ARC-c \text{ARC-c} ARC-c子集。两个数据集都包含多个选项的问题。
-
自然语言推断
我们使用 ANLI \text{ANLI} ANLI的子集 ANLI-A2 \text{ANLI-A2} ANLI-A2和 ANLI-A3 \text{ANLI-A3} ANLI-A3,其相比于子集 ANLI-A1 \text{ANLI-A1} ANLI-A1更具有挑战性。这些数据集包含了具有关系
entailment、neutral和contradiction的句子对。
2. 模型、训练设置和超参数
我们遵循先前的研究,并在具有 540B \text{540B} 540B参数的自回归 Transformer \text{Transformer} Transformer语言模型上进行实验。我们为训练集中的每个问题生成 m = 32 m=32 m=32个推理路径。每个推理路径被增强为4种形式,最终的训练样本尺寸为 128 × ∣ D t r a i n ∣ 128\times |\mathcal{D}^{train}| 128×∣Dtrain∣,其中 ∣ D t r a i n ∣ |\mathcal{D}^{train}| ∣Dtrain∣是对应训练集的尺寸。除了 DROP \text{DROP} DROP以外的所有数据集,我们都使用完整的训练集。为了降低训练的代价,我们从 DROP \text{DROP} DROP数据集中足球和非足球划分中采样 5 k 5k 5k的样本,并从 ANLI-A2 \text{ANLI-A2} ANLI-A2和 ANLI-A3 \text{ANLI-A3} ANLI-A3中采样 5 k 5k 5k的样本。对于每个数据集,我们以学习率 5 e − 5 5e-5 5e−5和 batch size \text{batch size} batch size为32来微调模型 10k \text{10k} 10k步。对于多路径解码,我们使用的采样温度为 T = 0.7 T=0.7 T=0.7。在随后的自我改善中使用的温度为 T = 1.2 T=1.2 T=1.2。在所有的实验中,我们设置最大的解码步骤为 256 \text{256} 256。
四、结果
1. 主要结果
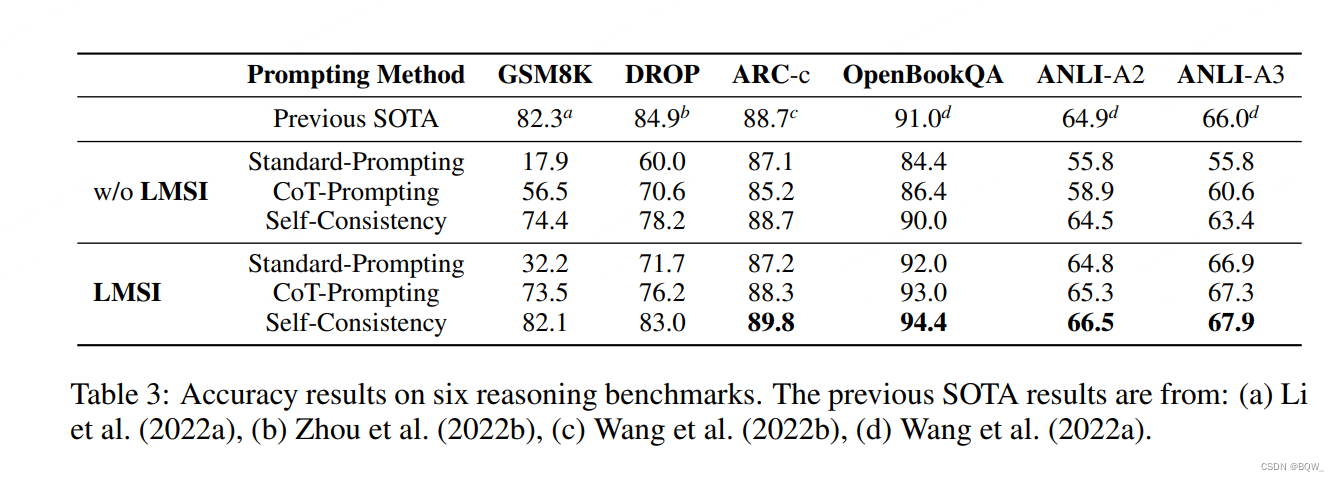
上表3展示了使用 LMSI \textbf{LMSI} LMSI前后模型 PaLM-540B \text{PaLM-540B} PaLM-540B的结果。在所有的6个数据集上,对于每个模型测试时,应用三种不同的 prompting \text{prompting} prompting:标准 prompting \text{prompting} prompting、 CoT-Prompting \text{CoT-Prompting} CoT-Prompting和 Self-Consistency \text{Self-Consistency} Self-Consistency。我们观察到,在使用 LMSI \textbf{LMSI} LMSI后,三种 prompting \text{prompting} prompting方法都有大幅度的提高。相比于 self-consistency \text{self-consistency} self-consistency,使用 LMSI \textbf{LMSI} LMSI后的 self-consistency \text{self-consistency} self-consistency可以有显著的改善:在 GSM8K \text{GSM8K} GSM8K上有 + 7.7 % +7.7\% +7.7%,在 DROP \text{DROP} DROP上有 + 4.8 % +4.8\% +4.8%,在 OpenBookQA \text{OpenBookQA} OpenBookQA上有 + 4.4 % +4.4\% +4.4%,在 ANLI-A3 \text{ANLI-A3} ANLI-A3上有 + 4.5 % +4.5\% +4.5%。这表明我们提出的方法非常的有效。此外,使用了 LMSI \textbf{LMSI} LMSI的单路径 CoT-Prompting \text{CoT-Prompting} CoT-Prompting的效果接近甚至优于不使用 LMSI \text{LMSI} LMSI的多路径 Self-Consistency \text{Self-Consistency} Self-Consistency,这表明 LMSI \text{LMSI} LMSI确实有助于模型从多个一致的推理路径中学习。我们也比较了我们的结果与先前的 SOTA \text{SOTA} SOTA。在 ARC-c \text{ARC-c} ARC-c、 OpenBookQA \text{OpenBookQA} OpenBookQA、 ANLI-A2 \text{ANLI-A2} ANLI-A2和 ANLI-A3 \text{ANLI-A3} ANLI-A3上, LMSI \text{LMSI} LMSI都超越了先前的 SOTA \text{SOTA} SOTA。在 GSM8K \text{GSM8K} GSM8K上, LMSI \text{LMSI} LMSI的效果接近于 DiVeRSe \text{DiVeRSe} DiVeRSe方法(该方法使用了多种 prompts \text{prompts} prompts并整合了一个集成100个输出路径的投票验证器)。相反,我们仅使用了32自生成的路径并使用了带有 LMSI \textbf{LMSI} LMSI的 self-consistency \text{self-consistency} self-consistency。在 DROP \text{DROP} DROP数据集上, LMSI \textbf{LMSI} LMSI的效果接近 OPERA \text{OPERA} OPERA方法(其使用了真实标签进行训练)。另一方面,我们的方法仅利用了训练集中的问题,没有使用任何的真实标签。
-
针对未见过任务的多任务自训练
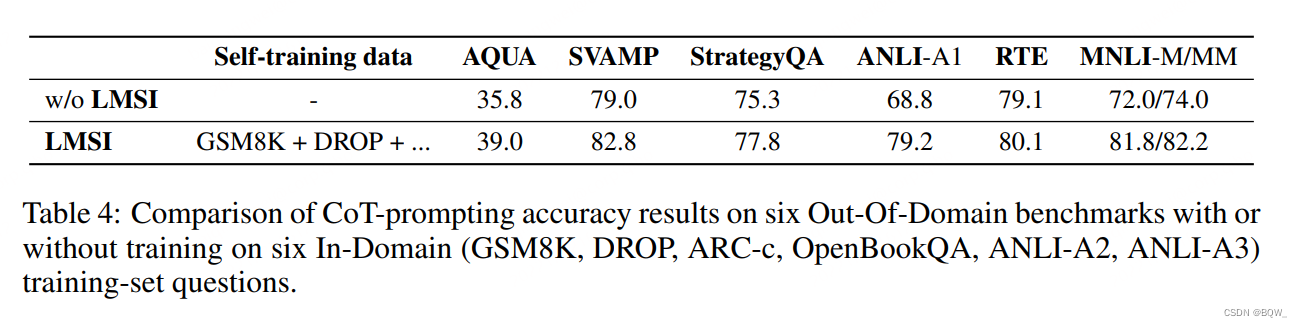
为了证明 LMSI \textbf{LMSI} LMSI的泛化能力,我们在上面6个数据集的混合训练集问题上进行自训练实验,然后在6个领域外任务上使用相同的模型进行评估。领域外任务包括:(1) AQUA \textbf{AQUA} AQUA和 SVAMP \textbf{SVAMP} SVAMP是算术推理任务;(2) StrategyQA \textbf{StrategyQA} StrategyQA是常识推理任务;(3) ANLI-A1,RTE,MNLI-M/MM \textbf{ANLI-A1,RTE,MNLI-M/MM} ANLI-A1,RTE,MNLI-M/MM是自然语言推理任务。在这些任务中, AQUA,StrategyQA,RTE \textbf{AQUA,StrategyQA,RTE} AQUA,StrategyQA,RTE与领域内任务显著不同。这三个任务有其自己的 few-shot prompts \text{few-shot prompts} few-shot prompts。上表4中,可以观察到 LMSI \textbf{LMSI} LMSI在所有的领域外任务上都有较高的准确率,说明语言模型的整体推理能够被增强。
-
使用 Chain-of-Thought \text{Chain-of-Thought} Chain-of-Thought训练的重要性
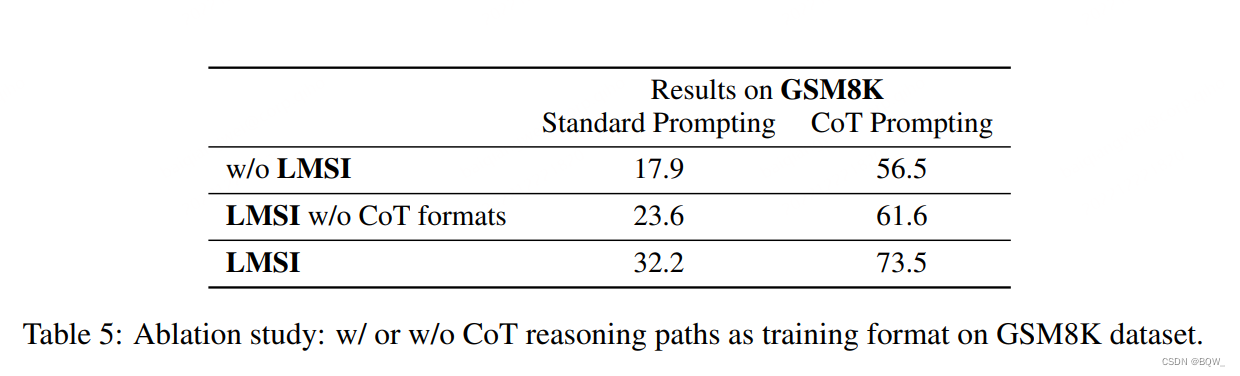
我们证明了使用 Chain-of-Thoughts \text{Chain-of-Thoughts} Chain-of-Thoughts训练语言模型的重要性。上表5所示,列出了所有四种形式的 LMSI \textbf{LMSI} LMSI结果。结果显示,不使用 CoT \text{CoT} CoT形式,语言模型仍然可以自我改善,但是效果的收益会大幅度的下降。
2. 推进自我改善的极限
- 自生成问题
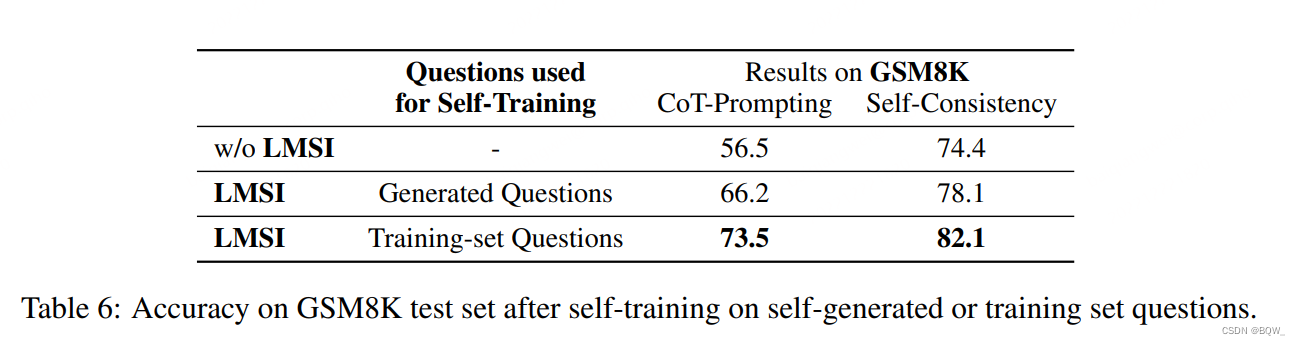
我们进一步探索了 few-shot \text{few-shot} few-shot的设置,仅有少量目标域上的训练问题。在 GSM8K \text{GSM8K} GSM8K上,仅采用10个真实问题作为 few-shot \text{few-shot} few-shot样本,然后使用语言模型来生成更多的训练问题。然后使用这些生成的问题来自训练语言模型,结果如上表6所示。结果显示使用自生成的问题仍然可以改善语言模型的能力,但是使用真实世界的问题能够带来更好的结果。
-
自生成 few-shot CoT Prompts \text{few-shot CoT Prompts} few-shot CoT Prompts

我们也探索了没有领域内 CoT \text{CoT} CoT样本的情况。我们应用 Step-by-Step \text{Step-by-Step} Step-by-Step方法来生成 CoT \text{CoT} CoT样本,结果如上图3显示。我们可以观察到使用自生成的 Step-by-Step CoT \text{Step-by-Step CoT} Step-by-Step CoT样本作为 few-shot prompting \text{few-shot prompting} few-shot prompting校友显著优于 Step-by-Step \text{Step-by-Step} Step-by-Step,并且接近人类撰写的 few-shot CoT \text{few-shot CoT} few-shot CoT。尽管 prompt \text{prompt} prompt的准确率有限(贪心 Step-by-Step \text{Step-by-Step} Step-by-Step的准确率为43%),但是
Few-Shot w/ Step-by-Step强劲的表现可能是利用了来自多路径解码的更多样 CoT prompts \text{CoT prompts} CoT prompts。因为我们不使用训练问题或者 few-shot CoT \text{few-shot CoT} few-shot CoT样本,74.2%也是 GSM8K \text{GSM8K} GSM8K上 zero-shot \text{zero-shot} zero-shot的最好效果。
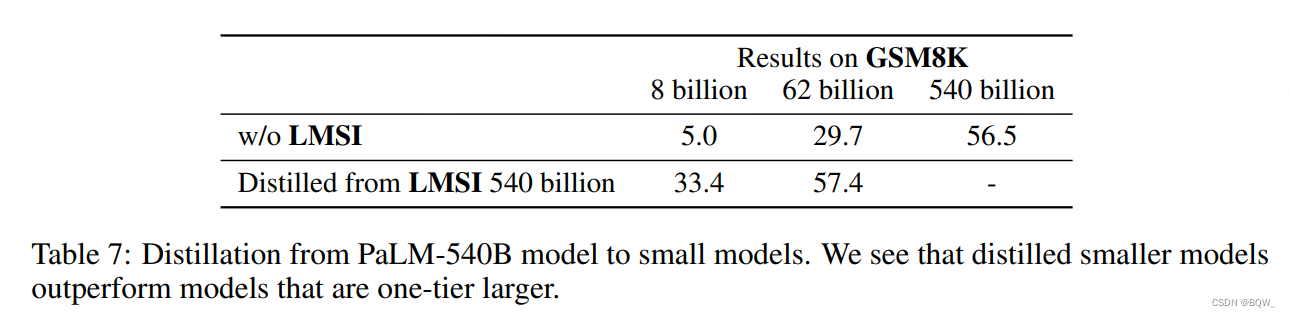
3. 蒸馏至较小模型
我们也探索了知识是否可以蒸馏至更小的模型。我们使用了由 PaLM-540B \text{PaLM-540B} PaLM-540B生成的相同训练集,但是在更小的尺寸上微调模型 ( PaLM-8B,PaLM-62B ) (\text{PaLM-8B,PaLM-62B}) (PaLM-8B,PaLM-62B),上表7展示了蒸馏的结果。有趣的是,通过 LMSI \textbf{LMSI} LMSI蒸馏后, 62B \text{62B} 62B的模型效果优于 540B \text{540B} 540B模型, 8B \text{8B} 8B的模型优于 62B \text{62B} 62B模型。这也意味着在有限计算资源的下游任务上,大模型的推理知识可以用于大幅度的增强小模型。