Why Can GPT Learn In-Context?
Language Models Secretly Perform Gradient Descent as Meta-Optimizers
为什么GPT能够在In-context的环境中进行学习呢?Language Models能够像Meta-Optimizer一样秘密地执行梯度下降。
这篇文章的作者来自清华、北大,代码发布在 https://github.com/microsoft/LMOps
Abstract
motivation:
Large pertrained Language models have shown surprising In-Context Learning ability.
To better understans how ICL works, this paper explains language models as meta-opetimizers and understands ICL as a kind of implicit finetuning.
这篇文章的发现:
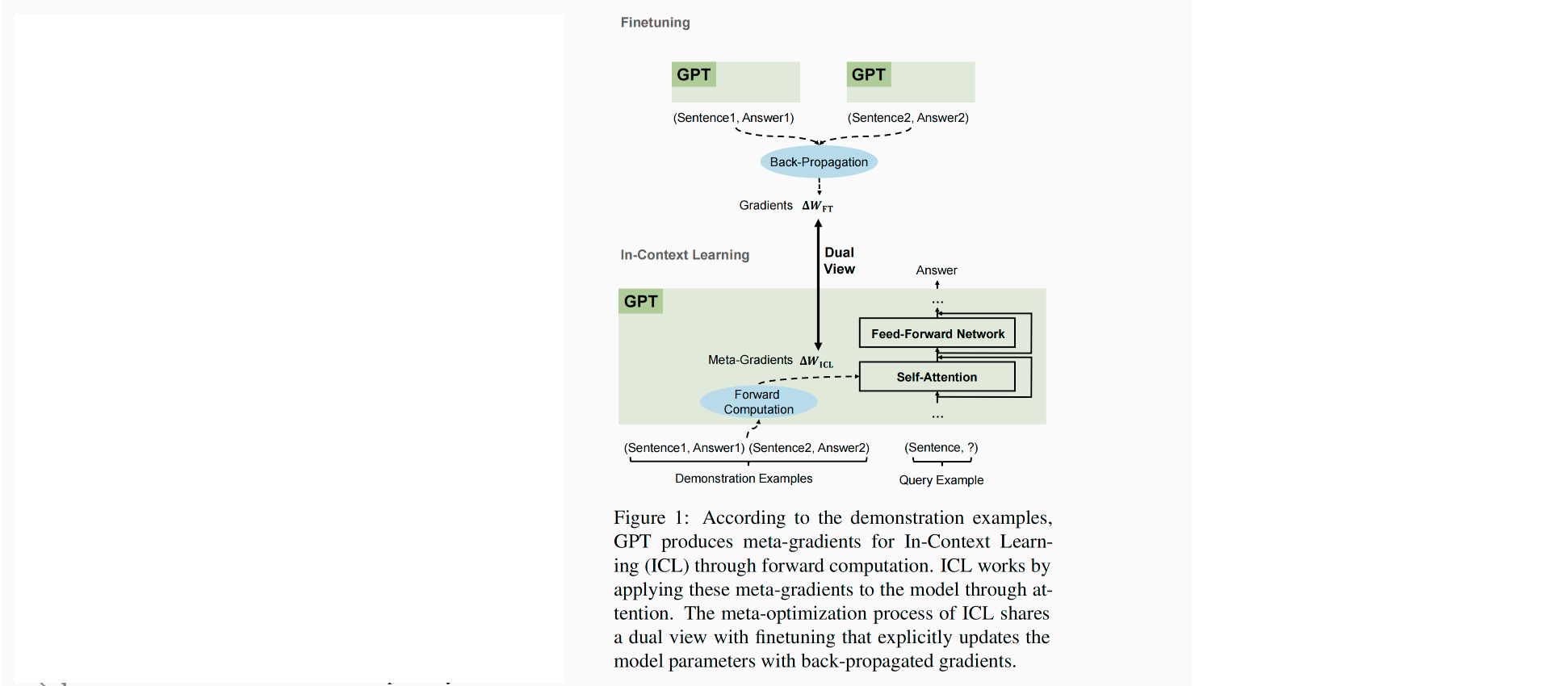
Theoretically, we figure out that the Transformer attention has a dual form of gradient descent based optimization. 从理论上,作者发现Transformer的注意力机制同时具有基于梯度下降优化的双重形式。
在这里理论的基础上,作者认为GPT ①首先通过一些示例样例来构造meta-gradients ② 然后将这个meta-gradients应用在原始的GPT上,构造一个ICL model。
- a pretrained GPT serves as a meta-optimizer;
- it produces meta-gradients according to the demon stration examples through forward computation;
- the meta-gradients are applied to the original language model through attention to build an ICL model.
在实验上:
作者比较了ICL和显式地fine-tuning。结果是它们的表现在 prediction level、representation level、attention behavior level上相似。
🤔 这里引出了一个思考的问题,既然两种方法的结果相似,为啥要用ICL呢?
当然是有必要的,这篇文章的主要目标是提出了一种理解GPT学习In-context的原因。基于这种深层次的理解,即,既然GPT本质上是构造了一个meta-gradient,那是不是可以使用momentum控制这个gradient,就好像基于动量的梯度下降算法一样,这个是本文的一个重要贡献:
Further, we attempt to take advantage of our understanding of meta-optimization for model designing. To be specifific, we design a momentum based attention, which regards the attention values as meta-gradients and applies the momentum mechanism to them. Experiments on both language modeling and in-context learning show that our momentum-based attention consistently outperforms vanilla attention, which supports our understanding of meta-optimization again from another aspect.
😀 这里有一个问题,我们可以去思考一下,GPT learn in-context时学习了meta-gradient,那这样的理解能不能引入模块化呢?
-
如果我们把GPT当做一个meta-optimizer,那其在一些logic reasoning数据的能力上必然不能达到一些模块化设计的结构上要好。所以我们可以尝试在一些具有更高logic reasoning能力的LLM来实现这一过程。
- 按照这个思路走,那motivation是什么?怎么编写这个
-
在这篇文章中,作者将Transformer应用在meta-learning中,或者是in-context learning中,作者将ICL理解为一种隐式的meta-train的过程。 在
General purpose in-context learning by meta-learning transformers这篇文章中,作者研究了在Transformer中进行in-context learning时,they show that the capabilities of meta-trained algorithms are bottlenecked by the accessible state size (memory) determining the next prediction, unlike standard models which are thought to be bottlenecked by parameter count.- 这么看来,
General purpose in-context learning by meta-learning transformers这篇文章与目前的这篇文章的理解实际上并不是冲突的,可以使用那篇文章提出的观点来优化这篇文章中所提到GPT learn in-context时的能力。通俗一点就是,gpt在learn In-context时得到了meta-gradient,而这个meta-gradient的计算在更大的accessible memory下具有更好的性能,这并不冲突。 - 那继续沿用这这个思考,在LLM中,对于示例样例的计算会得到一组gradient,那这个gradient在一些logic reasoning的任务上,如果不加入一些模块化的设计,必然在逻辑推理任务上不能取得一些比较好的效果。
- 我们可以在训练GPT时添加模块化的结构、如Compositional Transformer、shared global workspace、shared global key-value codebook。加入这些元素可能会提升meta-learning在推理任务上的性能。
- 讲故事就可以这样讲,为了提升meta-learning在推理任务上的性能,所以我们提出了这篇文章中的结构。
- 但是要保证本文涉及的结构能够超过meta-learning with only modular、without modular.
- 这么看来,
-
作者把ICL当做一种隐式的finetuning,这对我有什么启发呢?
- 既然ICL可以当做一种隐私的finetuning,那是不是就可以不通过finetuning来更新梯度了,而是在数据的输入方下功夫,让其具有更好的效果。
- 如果ICL可以当做一个隐式的finetuning的话,那我们可以应用在finetuning中的一些方法来提升ICL中的性能。
- 增加样本量
-
作者还认为ICL本质上是通过attention机制中的keys和values来计算得到了梯度的值,这个值可以当做meta-gradient,所以可以当做隐式地计算了梯度的信息。
-
引用这篇文章的一句话:We have fifigured out the dual form between Transformer attention and gradient descent based optimization.
-
所以这篇文章受这个发现的启发,作者打算将一个常用于优化算法的技术——momentum应用在Transformer的attention中。
-
作者首先在language model中训练得到了MoAttn,取得了与vanilla Transformer一致的效果。
-
接下来作者将上述训练得到的language model在in-context learning中进行实验,得到了结果要比baseline要好,
- 印证了作者对Transformer keys、values本质上是计算前向的梯度值的假设
-
-
-
这篇文章是对meta-optimizer的一个新的理解,将meta-optimizer当做finetuning。即,这篇文章的目的是帮助in-context learning得到一个更好的发展。
Introduction
ICL与finetuning之间的区别?
Different from finetuning which needs additional parameter updates, ICL just needs several demonstration examples prepended before the original input, and then the model can predict the label for even unseen inputs.
finetuning 是需要利用一些下游任务的数据进行retrain,而ICL仅仅需要在原始数据之前输入一些示例样例。
Dual Form Between Gradient Descent Based Optimization and Attention
这篇文章将一个线性层通过梯度下降算法进行优化的过程定义为下面两种式子:
在反向传播算法中, △ W = ∑ i e i ⨂ x ′ i T \bigtriangleup W = \sum_ie_i\bigotimes {x'}_i^T △W=i∑ei⨂x′iT,也就是说 △ W 是 \bigtriangleup W 是 △W是根据一系列的历史输入和相应输出所对应的梯度计算的。
F ( x ) = ( W 0 + △ W ) x F(x) = (W_0 + \bigtriangleup W) x F(x)=(W0+△W)x
F ( x ) = W 0 x + L I n e a r A t t n ( E , X ′ , x ) F(x) = W_0x + LInearAttn(E, X', x) F(x)=W0x+LInearAttn(E,X′,x)
In-Context Learning(ICL)本质上执行了一个隐式的Finetuning。
在3.1章,作者对Transformer Attention as Meta-Optmization进行了一些证明,证明过程没看懂。
In summary, we explain ICL as a process of meta-optimization:
(1) a Transformer-based pretrained language model serves as a meta-optimizer;
(2) it produces meta-gradients according to the demonstration examples through forward computation;
(3) through attention, the meta-gradients are applied to the original language model to build an ICL model.
作者将ICL与Finetuning进行了比较
在Finetuning阶段有一些特别的设计,因为在3.1章节中证明了ICL只对keys和values产生了影响,所以在finetuning阶段时只对keys、values所对应的投影进行更新。
为了更公平的进行比较:
但是我觉得这个设定是不是要求地太高了,因为在
- 指定训练数据只能是在ICL中用到的数据
- 对每个在ICL中出现的数据按照顺序只训练一次。
- 使用与ICL相同的template
作者organize many common properties from following four aspects:
从这下面四个特点,作者认为ICL是一种隐式的finetuning。
- Both Perform Gradient Descent
- 在ICL中的梯度和FT中的梯度,都可以被当做梯度下降
- 唯一不同的是,在ICL中是通过正向计算得到了meta-gradients,而在Finetuning中是通过back-propagation得到了真正的梯度信息,但他们都是作为了梯度的功能使用。The only difference is that ICL produces meta-gradients by forward computation while fifinetuning acquires real gradients by back propagation.
- Same Training Information
- 相同的训练信息
- Same Causal Order of Training Examples
- 相同的因果顺序
- Both Aim at Attention
- 在ICL中,只对keys、values进行计算
- 在这篇文章限制的finetuning中,也只是对keys、values的投影矩阵进行update
最后
与这篇文章相近的一些文章是:
Same work, published earlier: “Transformers learn in-context by gradient descent” https://arxiv.org/pdf/2212.07677.pdf
🤔 既然这篇文章的作者将ICL当做meta-optimizer。而在ICL中的一个比较重要的挑战是不能输入太多的样例。那我们是不是可以多输入几组样本,然后将多组输出信息进行聚合,以获得更好的梯度计算结果呢?
要想将模块化引入到这篇文章中来,首先要问的问题是,ICL能不能很好的解决reasoning的问题、OOD的问题(System2)