.Net 线程安全
- 最省事的lock关键字
- 线程安全对象
- 测试环境
- 例子
- 使用Queue源码和结果
- 运行效果
- 使用ConcurrentQueue的源码和结果
- 运行效果
- volatile关键字
- 易失性内存和非易失性内存的区别
- 易失性内存:
- 非易失性内存:
- volatile 关键字可应用于以下类型的字段:
- 测试代码(添加volatile 关键字)
- 测试效果(添加volatile 关键字)
- 测试代码(==没有volatile 关键字==)
- 测试效果(==没有volatile 关键字==)
- Interlocked
- Decrement和Increment方法递增或递减变量,并将结果值存储在单个操作中。 在大多数计算机上,递增变量不是原子操作,需要以下步骤:
- 细粒度锁定和无锁机制 (SpinWait、 SpinLock)
- 看一下SpinWait的SpinOnce源代码
- SpinLock
最省事的lock关键字
https://blog.csdn.net/iml6yu/article/details/74984466
在多线程操作过程中,最省事的安全操作关键字就是lock,但是这会影响到多线程操作的性能。
线程安全对象
.NET Framework 4 引入了 System.Collections.Concurrent 命名空间,其中包含多个线程安全且可缩放的集合类。 多个线程可以安全高效地从这些集合添加或删除项,而无需在用户代码中进行其他同步。 编写新代码时,只要将多个线程同时写入到集合时,就使用并发集合类。

简单来说使用上述的对象进行多线程之间操作的时候都能确保线程安全
测试环境
- win10
- vs2022
- .net6
- 语言版本 c#10
例子
例子中使用一个主线程往队列中写入一些数据,然后分10个线程进行读取,
分别使用Queue和ConcurrentQueue进行测试,对比两次结果
使用Queue源码和结果
using System.Collections.Concurrent;
using System.Diagnostics;
namespace 一写多读_NetCore_v6
{
internal class Program
{
//声明读取结果接收容器列表
static List<List<string>> list
= new List<List<string>>() {
new List<string>(),
new List<string>(),
new List<string>(),
new List<string>(),
new List<string>(),
new List<string>(),
new List<string>(),
new List<string>(),
new List<string>(),
new List<string>()
};
//队列用于存储生产数据的(一个写入,多个读取)
static Queue<string> strings = new Queue<string>();
//避免程序不能结束声明的变量,表示当前写入线程是否已经把所有数据都写完了
static bool IsReadyComplated = false;
static void Main(string[] args)
{
Console.WriteLine("Hello, World!");
//开10个线程去读取数据
Task.Run(() =>
{
var result = Parallel.ForEach(list, ls =>
{
while (!IsReadyComplated || strings.Count > 0)
{
if (strings.Count > 0)
{
string s;
strings.TryDequeue(out s);
if (s != null)
ls.Add(s);
}
//Task.Delay(0).Wait();
}
});
//判断每个线程读取到的结果是否有重复,也就是是否出现了脏读的问题
if (result.IsCompleted)
{
Console.WriteLine($"读取到的总数据条数:{list.Sum(ls=>ls.Count)}");
list.ForEach(ls =>
{
if (ls.Count != ls.Distinct().Count())
{
Console.WriteLine("存在重复数据");
}
foreach (var l in list)
{
if (l != ls)
{
if (l.Where(item => ls.Contains(item)).Count() > 0)
Console.WriteLine("存在重复数据 Item");
}
}
});
Console.WriteLine("执行完成!");
}
});
//生产数据
OneWrite();//.Wait();
//确保在判断数据的时候程序没有退出而写的一个死循环
while (true)
{
Task.Delay(TimeSpan.FromMinutes(10)).Wait();
}
}
private static void OneWrite()
{
IsReadyComplated = false;
Stopwatch stopwatch = new Stopwatch();
//总数居条数
int total = 100000;
stopwatch.Start();
while (total > 0)
{
strings.Enqueue(total.ToString());
//Task.Delay(1).Wait();//158630.1541
//Thread.Sleep(1);//155031.3485
//await Task.Delay(1);//158206.7742
total--;
}
IsReadyComplated = true;
stopwatch.Stop();
Console.WriteLine(stopwatch.Elapsed.TotalMilliseconds.ToString());
}
}
}
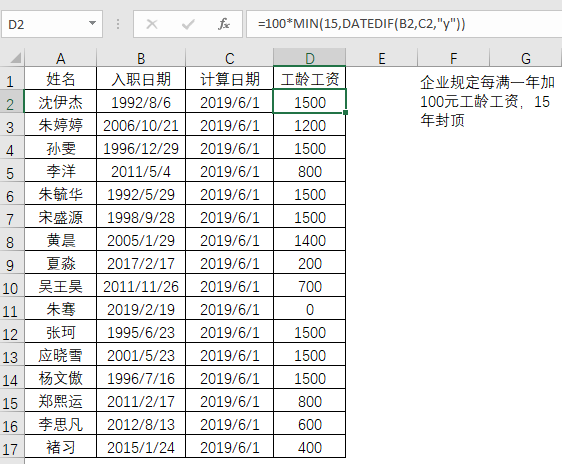
运行效果
我代码中实际生产了100000条数据,但是读取后却是118639条,所以一定是有线程读取出现了重复读取的问题
使用ConcurrentQueue的源码和结果
static ConcurrentQueue strings = new ConcurrentQueue();
using System.Collections.Concurrent;
using System.Diagnostics;
namespace 一写多读_NetCore_v6
{
internal class Program
{
//声明读取结果接收容器列表
static List<List<string>> list
= new List<List<string>>() {
new List<string>(),
new List<string>(),
new List<string>(),
new List<string>(),
new List<string>(),
new List<string>(),
new List<string>(),
new List<string>(),
new List<string>(),
new List<string>()
};
//队列用于存储生产数据的(一个写入,多个读取)
static ConcurrentQueue<string> strings = new ConcurrentQueue<string>();
//避免程序不能结束声明的变量,表示当前写入线程是否已经把所有数据都写完了
static bool IsReadyComplated = false;
static void Main(string[] args)
{
Console.WriteLine("Hello, World!");
//开10个线程去读取数据
Task.Run(() =>
{
var result = Parallel.ForEach(list, ls =>
{
while (!IsReadyComplated || strings.Count > 0)
{
if (strings.Count > 0)
{
string s;
strings.TryDequeue(out s);
if (s != null)
ls.Add(s);
}
//Task.Delay(0).Wait();
}
});
//判断每个线程读取到的结果是否有重复,也就是是否出现了脏读的问题
if (result.IsCompleted)
{
Console.WriteLine($"读取到的总数据条数:{list.Sum(ls=>ls.Count)}");
list.ForEach(ls =>
{
if (ls.Count != ls.Distinct().Count())
{
Console.WriteLine("存在重复数据");
}
foreach (var l in list)
{
if (l != ls)
{
if (l.Where(item => ls.Contains(item)).Count() > 0)
Console.WriteLine("存在重复数据 Item");
}
}
});
Console.WriteLine("执行完成!");
}
});
//生产数据
OneWrite();//.Wait();
//确保在判断数据的时候程序没有退出而写的一个死循环
while (true)
{
Task.Delay(TimeSpan.FromMinutes(10)).Wait();
}
}
private static void OneWrite()
{
IsReadyComplated = false;
Stopwatch stopwatch = new Stopwatch();
int total = 100000;
stopwatch.Start();
while (total > 0)
{
strings.Enqueue(total.ToString());
//Task.Delay(1).Wait();//158630.1541
//Thread.Sleep(1);//155031.3485
//await Task.Delay(1);//158206.7742
total--;
}
IsReadyComplated = true;
stopwatch.Stop();
Console.WriteLine(stopwatch.Elapsed.TotalMilliseconds.ToString());
}
}
}
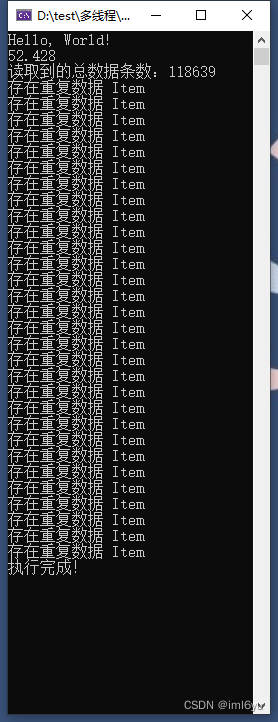
运行效果
volatile关键字
volatile 关键字指示一个字段可以由多个同时执行的线程修改。 出于性能原因,编译器,运行时系统甚至硬件都可能重新排列对存储器位置的读取和写入。 声明为 volatile 的字段将从某些类型的优化中排除。
多个线程同时访问一个变量,CLR为了效率,允许每个线程进行本地缓存,这就导致了变量的不一致性。volatile就是为了解决这个问题,volatile修饰的变量,不允许线程进行本地缓存,每个线程的读写都是直接操作在共享内存上,这就保证了变量始终具有一致性。
在多处理器系统上,由于编译器或处理器中的性能优化,当多个处理器在同一内存上运行时,常规内存操作似乎被重新排序。 易失性内存操作阻止对操作进行某些类型的重新排序。 易失性写入操作可防止对线程的早期内存操作重新排序,以在易失性写入之后发生。 易失性读取操作可防止对线程的后续内存操作重新排序,以在易失读取之前发生。 这些操作可能涉及某些处理器上的内存屏障,这可能会影响性能。
易失性内存和非易失性内存的区别
易失性内存:
它是高速获取/存储数据的内存硬件。它也被称为临时内存。易失性内存中的数据会一直保存到系统可以使用,但是一旦系统关闭,易失性内存中的数据就会被自动删除。RAM(随机存取存储器)和高速缓存存储器是易失性存储器的一些常见示例。在这里,数据获取/存储既快速又经济。
非易失性内存:
这是一种内存类型,即使断电,数据或信息也不会在内存中丢失。ROM(只读存储器)是非易失性存储器的最常见示例。与易失性存储器相比,它在获取/存储方面并不经济且速度慢,但存储的数据量更大。所有需要长时间存储的信息都存储在非易失性存储器中。非易失性存储器对系统的存储容量有巨大影响。
volatile 关键字可应用于以下类型的字段:
- 引用类型。
- 指针类型(在不安全的上下文中)。 请注意,虽然指针本身可以是可变的,但是它指向的对象不能是可变的。 换句话说,不能声明“指向可变对象的指针”。
- 简单类型,如 sbyte、byte、short、ushort、int、uint、char、float 和 bool。
- 具有以下基本类型之一的 enum 类型:byte、sbyte、short、ushort、int 或 uint。
- 已知为引用类型的泛型类型参数。
- IntPtr 和 UIntPtr。
- 其他类型(包括 double 和 long)无法标记为 volatile,因为对这些类型的字段的读取和写入不能保证是原子的。
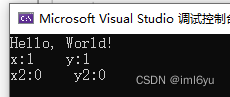
测试代码(添加volatile 关键字)
namespace volatile关键字测试
{
internal class Program
{
static void Main(string[] args)
{
Test test = new Test();
Console.WriteLine("Hello, World!");
Thread thread1 = new Thread(new ThreadStart(() =>
{
test.x = 1;
test.y = 1;
Console.WriteLine($"x:{test.x} y:{test.y}");
}));
Thread thread2 = new Thread(new ThreadStart(() =>
{
int y2 = test.y;
int x2 = test.x;
Console.WriteLine($"x2:{x2} y2:{y2}");
}));
thread1.Start();
thread2.Start();
}
}
public class Test
{
public volatile int x;
public volatile int y;
}
}
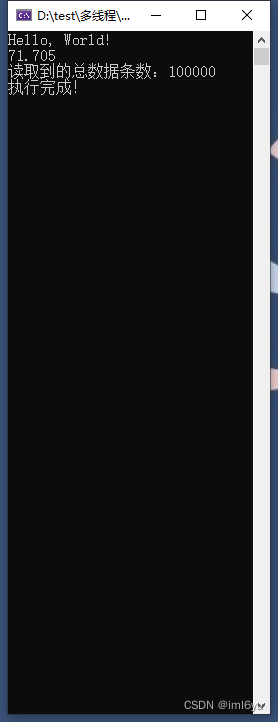
测试效果(添加volatile 关键字)
测试代码(没有volatile 关键字)
namespace volatile关键字测试
{
internal class Program
{
static void Main(string[] args)
{
Test test = new Test();
Console.WriteLine("Hello, World!");
Thread thread1 = new Thread(new ThreadStart(() =>
{
test.x = 1;
test.y = 1;
Console.WriteLine($"x:{test.x} y:{test.y}");
}));
Thread thread2 = new Thread(new ThreadStart(() =>
{
int y2 = test.y;
int x2 = test.x;
Console.WriteLine($"x2:{x2} y2:{y2}");
}));
thread1.Start();
thread2.Start();
}
}
public class Test
{
public int x;
public int y;
}
}
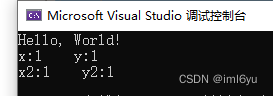
测试效果(没有volatile 关键字)
Interlocked
为多个线程共享的变量提供原子操作。
此类的方法有助于防止当计划程序切换上下文时,当线程更新可由其他线程访问的变量时,或者当两个线程同时在单独的处理器上执行时,可能会出现的错误。 此类的成员不会引发异常。
Decrement和Increment方法递增或递减变量,并将结果值存储在单个操作中。 在大多数计算机上,递增变量不是原子操作,需要以下步骤:
-
将实例变量的值加载到寄存器中。
-
递增或递减值。
-
将值存储在实例变量中。
如果不使用 Increment 并且 Decrement执行前两个步骤后,可以抢占线程。 然后,另一个线程可以执行所有三个步骤。 当第一个线程恢复执行时,它会覆盖实例变量中的值,并丢失第二个线程执行的递增或递减的效果。
该方法 Add 以原子方式将整数值添加到整数变量,并返回该变量的新值。
该方法 Exchange 以原子方式交换指定变量的值。 该方法 CompareExchange 结合两个操作:根据比较的结果,比较两个值,并将第三个值存储在其中一个变量中。 比较和交换操作作为原子操作执行。
确保对共享变量的任何写入或读取访问权限都是原子的。 否则,数据可能会损坏,或者加载的值可能不正确。
https://learn.microsoft.com/zh-cn/dotnet/api/system.threading.interlocked?view=net-7.0
细粒度锁定和无锁机制 (SpinWait、 SpinLock)
https://learn.microsoft.com/zh-cn/dotnet/api/system.threading.spinwait?source=recommendations&view=net-7.0
在查看ConcurrentQueue<T>源码时,发现了这个类
这段代码是 ConcurrentQueue<T>的Enqueue方法
/// <summary>
/// Adds an object to the end of the <see cref="ConcurrentQueue{T}"/>.
/// </summary>
/// <param name="item">The object to add to the end of the <see
/// cref="ConcurrentQueue{T}"/>. The value can be a null reference
/// (Nothing in Visual Basic) for reference types.
/// </param>
public void Enqueue(T item)
{
SpinWait spin = new SpinWait();
while (true)
{
Segment tail = m_tail;
if (tail.TryAppend(item))
return;
spin.SpinOnce();
}
}
System.Threading.SpinWait 是一种轻型同步类型,可用于低级方案,以避免执行内核事件所需的高成本上下文切换和内核转换。 在多核计算机上,如果不得长时间保留资源,更高效的做法是,先让等待线程在用户模式下旋转几十或几百个周期,再重试获取资源。 如果资源在旋转后可用,便节省了几千个周期。 如果资源仍不可用,那么也只花了几个周期,仍可以进入基于内核的等待。 这种“旋转后等待”的组合有时称为“两阶段等待操作” 。
看一下SpinWait的SpinOnce源代码
/// <summary>
/// Performs a single spin.
/// </summary>
/// <remarks>
/// This is typically called in a loop, and may change in behavior based on the number of times a
/// <see cref="SpinOnce"/> has been called thus far on this instance.
/// </remarks>
public void SpinOnce()
{
if (NextSpinWillYield)
{
//
// We must yield.
//
// We prefer to call Thread.Yield first, triggering a SwitchToThread. This
// unfortunately doesn't consider all runnable threads on all OS SKUs. In
// some cases, it may only consult the runnable threads whose ideal processor
// is the one currently executing code. Thus we oc----ionally issue a call to
// Sleep(0), which considers all runnable threads at equal priority. Even this
// is insufficient since we may be spin waiting for lower priority threads to
// execute; we therefore must call Sleep(1) once in a while too, which considers
// all runnable threads, regardless of ideal processor and priority, but may
// remove the thread from the scheduler's queue for 10+ms, if the system is
// configured to use the (default) coarse-grained system timer.
//
#if !FEATURE_PAL && !FEATURE_CORECLR // PAL doesn't support eventing, and we don't compile CDS providers for Coreclr
CdsSyncEtwBCLProvider.Log.SpinWait_NextSpinWillYield();
#endif
int yieldsSoFar = (m_count >= YIELD_THRESHOLD ? m_count - YIELD_THRESHOLD : m_count);
if ((yieldsSoFar % SLEEP_1_EVERY_HOW_MANY_TIMES) == (SLEEP_1_EVERY_HOW_MANY_TIMES - 1))
{
Thread.Sleep(1);
}
else if ((yieldsSoFar % SLEEP_0_EVERY_HOW_MANY_TIMES) == (SLEEP_0_EVERY_HOW_MANY_TIMES - 1))
{
Thread.Sleep(0);
}
else
{
#if PFX_LEGACY_3_5
Platform.Yield();
#else
Thread.Yield();
#endif
}
}
else
{
//
// Otherwise, we will spin.
//
// We do this using the CLR's SpinWait API, which is just a busy loop that
// issues YIELD/PAUSE instructions to ensure multi-threaded CPUs can react
// intelligently to avoid starving. (These are NOOPs on other CPUs.) We
// choose a number for the loop iteration count such that each successive
// call spins for longer, to reduce cache contention. We cap the total
// number of spins we are willing to tolerate to reduce delay to the caller,
// since we expect most callers will eventually block anyway.
//
Thread.SpinWait(4 << m_count);
}
// Finally, increment our spin counter.
m_count = (m_count == int.MaxValue ? YIELD_THRESHOLD : m_count + 1);
}
这个方法里面涉及到一些平台的东西,但是可以看到内部还是有一些Thread.Sleep的方法和Thread.Yield方法。
SpinLock
https://learn.microsoft.com/zh-cn/dotnet/standard/threading/how-to-use-spinlock-for-low-level-synchronization
关键部分执行的工作量最少,因而非常适合执行 SpinLock。 与标准锁相比,增加一点工作量即可提升 SpinLock 的性能。 但是,超过某个点时 SpinLock 将比标准锁开销更大。