Langchain入门到实战
- Langchain中RAG入门
- 官网地址
- Langchain概述
- 代码演示调用RAG功能
- 更新计划
Langchain中RAG入门
Retrieval Augmented Generation 翻译成中文是“检索增强生成”
官网地址
声明: 由于操作系统, 版本更新等原因, 文章所列内容不一定100%复现, 还要以官方信息为准
https://python.langchain.com/
Langchain概述
LangChain是一个用于开发由大型语言模型(LLM)驱动的应用程序的框架。
代码演示调用RAG功能
-
Retrieval chain可以是sql数据库中的数据, 互联网上的数据, 本文以向量数据库为例
-
安装本次运行必要的包
pip install beautifulsoup4 pip install faiss-cpu -
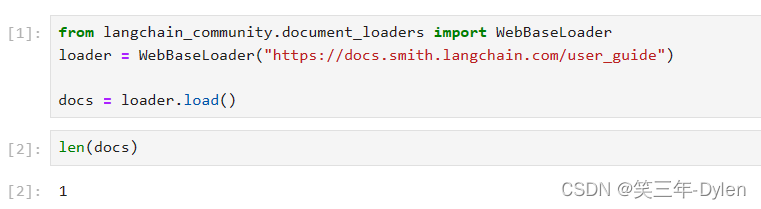
使用 WebBaseLoader加载我们想要建立索引的数据
from langchain_community.document_loaders import WebBaseLoader loader = WebBaseLoader("https://docs.smith.langchain.com/user_guide") docs = loader.load()
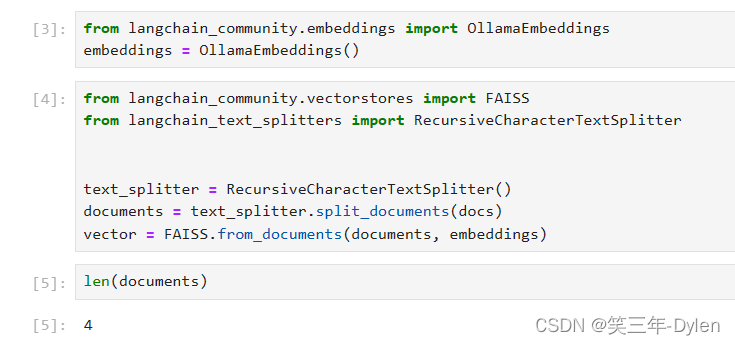
- 接下来需要embedding model和vector store
- embedding model的作用是讲一个一个单词以向量表示, 比如"我", 用一个512维的一维向量表示为[0.122334455, 2.54433222,…], 本例使用OllamaEmbeddings
- vector store是用来存放向量的数据库, 本例使用FAISS
from langchain_community.embeddings import OllamaEmbeddings embeddings = OllamaEmbeddings() from langchain_community.vectorstores import FAISS from langchain_text_splitters import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter() documents = text_splitter.split_documents(docs) vector = FAISS.from_documents(documents, embeddings)
-
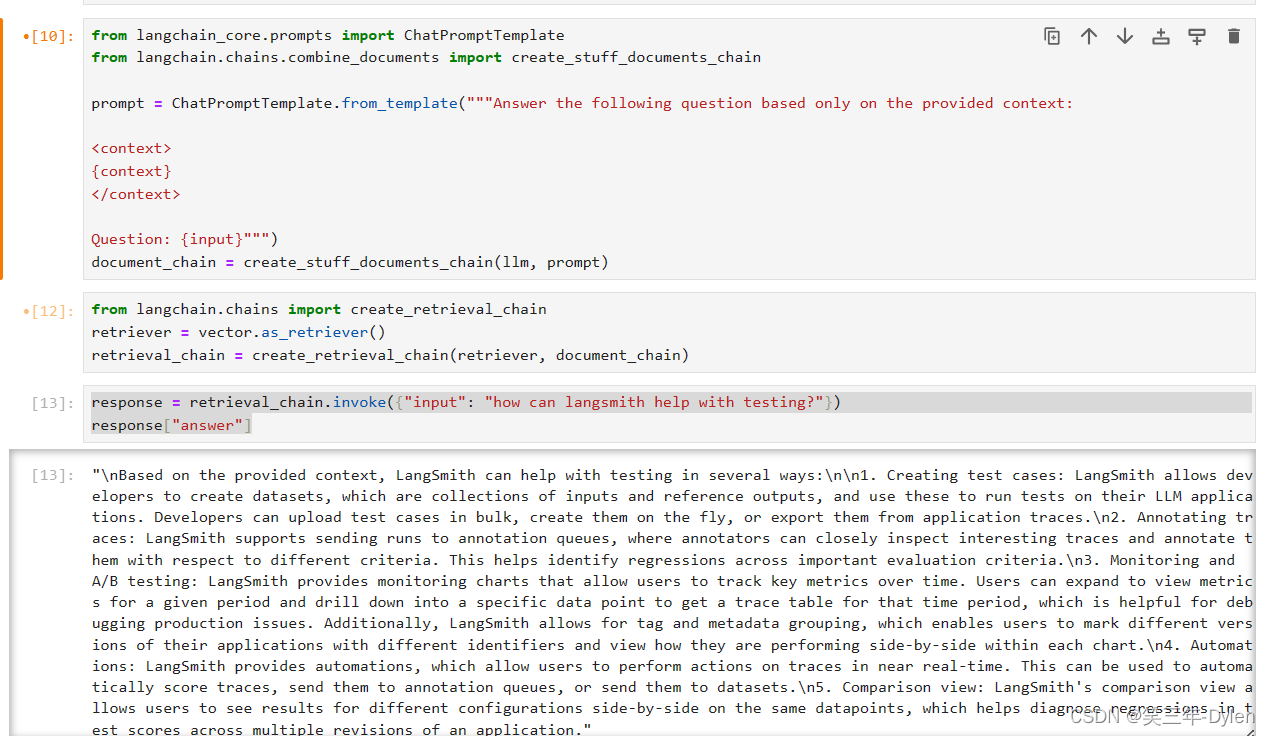
创建一个包含问题并根据检索内容生成答案的一个chain
from langchain_core.prompts import ChatPromptTemplate from langchain.chains.combine_documents import create_stuff_documents_chain prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context: <context> {context} </context> Question: {input}""") document_chain = create_stuff_documents_chain(llm, prompt) -
从向量数据库中检索内容, 并让大模型根据已有知识回答问题
from langchain.chains import create_retrieval_chain retriever = vector.as_retriever() retrieval_chain = create_retrieval_chain(retriever, document_chain) response = retrieval_chain.invoke({"input": "how can langsmith help with testing?"}) response["answer"]
更新计划
欲知后事如何, 请听下回分解