前言
目前闲鱼不少业务正在从H5/Weex升级到Kun(基于W3C标准&Flutter打造的混合高性能终端容器),从测试角度来看,我们希望这种升级迭代对于用户体验是正向的,所以用好性能测试这把标准尺就显得格外重要。
早期做性能保障时,我们在一些核心场景要上线或者上线之后遇到问题时,才去跑一些性能测试,这种方式只知道性能变差了,至于差在哪里,就只能反推开发去查问题,效率低且容易出问题。今年我们提出了基于容器分层的性能测试,目的是提前将性能风险点抛的更前置、更明确,特别对于Kun,除了容器本身的影响,Flutter引擎也会影响性能体验。
我们要测什么
性能指标对齐
在确定我们要做性能分层测试后,第一个问题就随之而来——性能测试到底要测什么,什么样的指标才能够去衡量一个页面的好坏。我们有两个选择:A、业界通用的指标,和友商APP的度量标准对齐;B、开发打点,测试侧对数据进行清洗;我们毫不犹豫选择了方案A,因为我们期望的性能测试并不只是在闲鱼内部赛马,而是说这些数据也能与友商以及业界标杆APP看齐,追求更加极致的用户体验。最终我们KO确定的指标如下:
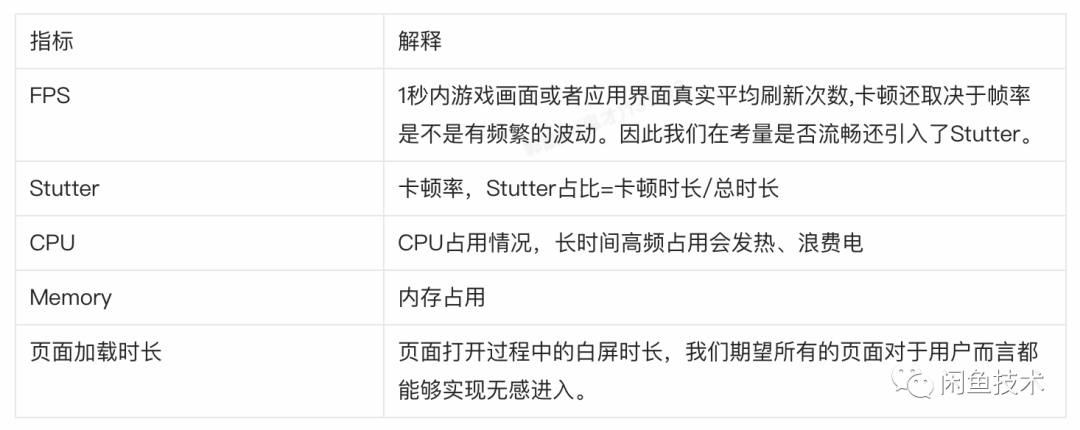
我们对现有的主干业务场景以及技术栈进行了梳理,并结合核心的业务场景和关键能力组件,建立对于引擎电商领域核心的数据观察策略,沉淀各个能力层和领域层度量体系,用于衡量在各个领域层开展相关性能优化取得的效果。
1. 明确基于Flutter引擎层,对齐Flutter页面和Kun页面的度量体系标准;
2. 分别基于组件层面和核心业务,搭建benchMark测试场景;
3. 回归业务,从核心业务层观测判定性能优化结果

分层性能场景
我们按照上文中提及的分层策略,确定了最终测试的场景,在benchMark中,我们侧重于关注组件和核心组件场景的性能情况,最后会在闲鱼APP的上层业务中,验证对大盘整体水位的影响,如下图所示为我们性能测试分层覆盖的内容:

多维度度量
闲鱼APP是混合技术栈,其中包含H5、Weex、Native以及Flutter、KUN,目前闲鱼有很多业务正在逐渐从H5/Weex升级到Kun,那我们如何拉齐标准,保证APP性能的稳定性呢?为此我们通过多维度的测试,来保障性能的稳定:
• 极限压测门槛:使用中、低端机压测,关注在极限场景下,APP是否会出现Abort或crash;
• 横向对比:横向对比我们会将技术栈升级前后的两个版本进行对比;
• 版本对比:业务迭代跟随版本需做回归,确定版本的波动指标;
• benchMark测试:构建极速验证版benchMark工具平台,部分场景通过mock数据排除网络等不稳定因素的干扰,快速验证组件层面的性能波动;
除此之外,不同的应用场景,我们对指标的使用也略有不同:
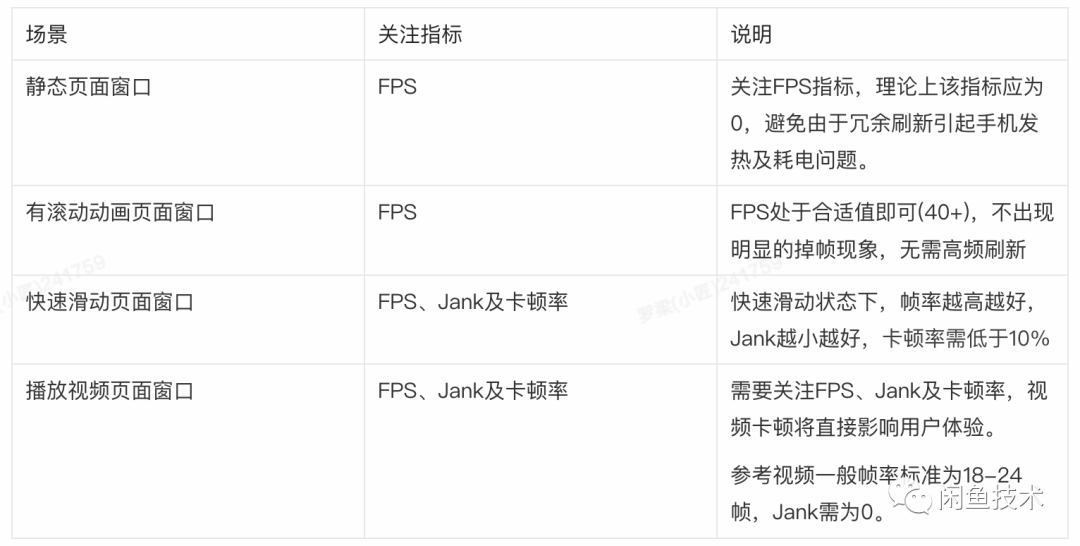
通过以上过程分析,和多维度性能度量体系的建立,我们已经明确了整个性能分层测试的纲领——怎么度量、度量什么内容。接下来就是实操过程——如何更方便、更快捷的把这些数据测出来,同时更直观的展示给开发同学,让他们能够确定自己的优化是有效的。
我们该怎么测
测试脚本
滑动速度的快慢,对性能稳定性数据的产出起到关键性作用,我们在性能测试过程中,通过不断的调试优化脚本,最终使滑动的方式尽量贴合用户的操作习惯,区分快慢滑场景,对性能数据进行采集。如下图所示为我们模拟用户快慢滑场景的测试录屏。


另外,为了保障脚本的通用性和易用性,我们封装了通用脚本库,在这些库中包含了如何提取环境变量、如何开始性能收集以及一些关于录屏、分帧等操作。对于简单的测试需求,大多数使用者只需要在前台勾勾选选就能够完成测试需求,而不需要每个业务方都投入精力去维护一套测试代码。
基建建设与能力升级
我们分析闲鱼现有的性能平台能力,虽然一定程度上能够支撑性能分层测试,但是在易用性、扩展性上还是存在一些缺陷,主要存在以下4个问题:
• 设备排队久:开发同学经常会问任务为什么一直在执行中,然后排查之后发现大家的任务都集中成一台设备上执行。
• 任务创建复杂:随着老平台的使用,创建任务表单字段在不断的增长,从而导致创建任务时经常会选错或填错。
• 报告对比难:老性能平台大多数应用场景是在版本的性能测试,所以报告对比能力较弱,很多时候需要大家手动整理几个报告来查看差异。
• 数据需频繁订正:老性能平台在页面加载时长测试能力上一直比较薄弱,需要测试同学订正每个录屏数据,确定页面加载的起始帧和结束帧,在有大量benchMark测试需求时,这种订正成本暴露的更加明显。
针对以上问题,我们设计了性能实验室2.0,其整体架构如下图所示

设备库优化
首先针对设备排队问题,我们扩展了闲鱼的手机设备池,从原有的8台设备扩展到了16台,覆盖了低、中、高机型。同时针对开发同学不知道该选什么设备的问题,我们对各类设备进行了分组圈选打标,以保障各类任务都有不同的设备在执行,在同组设备中,如果开发选择的设备正在执行任务,我们的任务调度系统会在该设备组中选择同样型号的设备来执行任务,这样在提高任务的执行效率的基础上,同时也能让机器分担的任务更加均匀,确保设备的性能水位是基本持平。
性能任务模板
针对于任务创建流程长,参数填写复杂容易出错的问题,我们引入了任务模板的概念。在设计任务模板时尽量考虑高扩展性,用户如果有需要额外的字段,只需要通过动态添加相关环境变量即可传入,脚本底层也封装了相关参数获取方法。通过该设计使脚本任务的参数和平台的参数进行解耦,用户在使用模板创建任务时,不需要考虑脚本内部需要的参数以及细节,只需要调整安装包地址即可。

建立数据归档
解决了任务创建复杂、执行慢的问题后,遗留下来的问题就是各种类型报告的比较。在容器分层性能测试中,我们除了对业务场景进行性能测试,还需要对不同的容器、不同的benchMark进行测试比较,如果依旧采用手工整理数据进行比较成本高、容易出错且回溯困难。因此我们对结果展示功能进行了扩展,用户不仅能够查看单次报告数据,还能够挑选任意的其他报告进行比较,这样开发同学可以在任务结束之后,通过筛选对比,一目了然地确定优化是否有效。

有什么效果
经过一阶段的实践,目前性能实验室2.0已经上线试运行约15天,累计执行任务360余个:
• 人力成本降低:之前开发创建任务时总是找相关同学答疑,新平台上线后,除了新增模板以及设备需求,该类问题已不存在。同时对于启动时长的起始帧/结束帧的订正问题也给予了解决,从之前的10分钟手动订正降低至2-3分钟确认无误即可。
• 高效稳定:任务成功率94%,设备排队问题得到一定缓解。
• 数据分析便捷:通过新平台,开发同学可以直接任意比较相关实验数据,更快得到测试结论,释放了整理数据的人力。
• 分层验证效果:通过benchMark的建设,负责不同优化点的同学使用对应的benchMark模板即可快速验证其优化效果,各行其是,也能够快速定位到问题。
• 问题深入化:通过新平台的使用以及对比,我们发现在Flutter的一些性能数据收集上存在问题,通过调研了解到相关原因,并找到了新的收集方法。
我们还要做什么
目前针对于容器分层性能测试已经实现了一个小的闭环,开发同学已经能够完全自助测试并且分析相关数据,在后期我们会持续深入挖掘相关工作。
• 丰富完成benchMark,更细化地确定优化效果以及最终收益
• 减少性能测试的等待时间,提升测试效率
• 制定标准的发布标准要求,保障新技术演进有质有量
• 将性能测试前置到版本集成前,性能问题发现更前置
• 探索问题定位能力