📋 个人简介
- 💖 作者简介:大家好,我是阿牛,全栈领域优质创作者。😜
- 📝 个人主页:馆主阿牛🔥
- 🎉 支持我:点赞👍+收藏⭐️+留言📝
- 📣 系列专栏:java 小白到高手的蜕变🍁
- 💬格言:要成为光,因为有怕黑的人!🔥

目录
- 📋 个人简介
- 前言
- HashMap源码分析
- 总结
- 结语
前言
HashMap的底层原理一直以来是面试必问的问题,本节将基于源码分析一下!jdk7版本的HashMap和jdk8的HsahMap底层原理不同,本文主要以jdk8里的HashMap来分析,最后会总结jdk7与jdk8中HashMap的底层原理,用来对比不同!
HashMap源码分析
在分析源码之前,你先要了解HashMap源码中的几个重要常量:
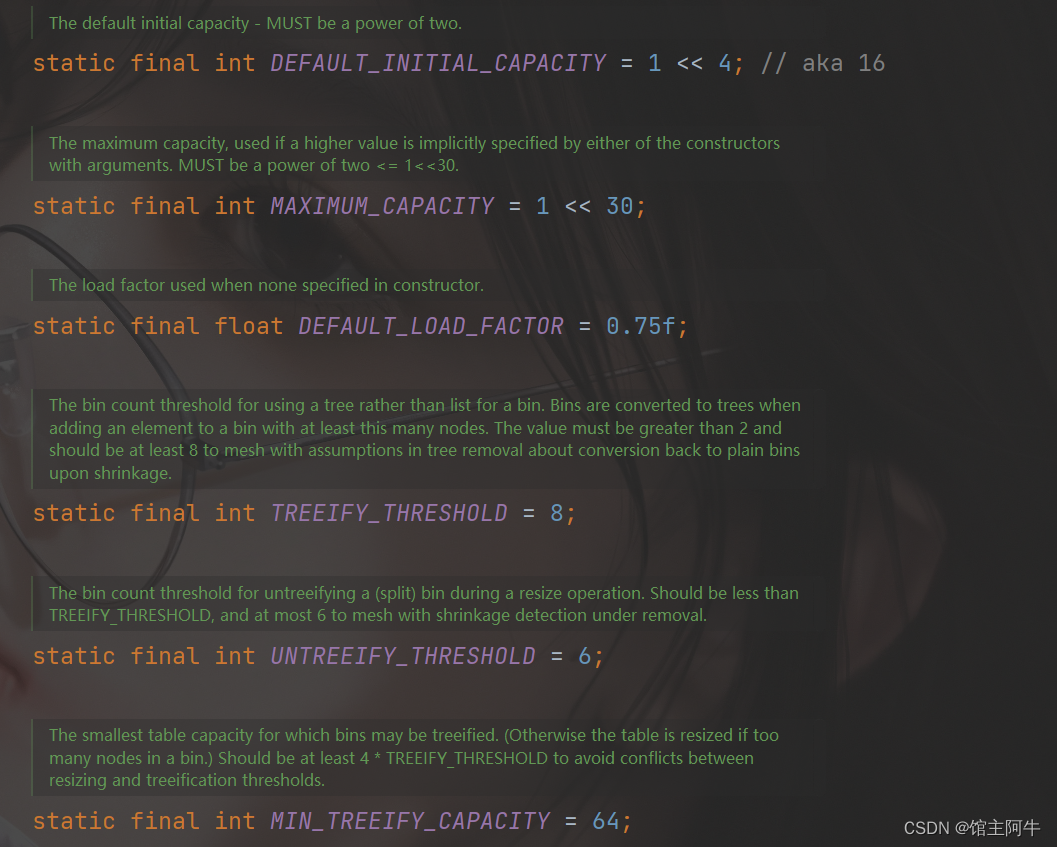
DEFAULT _ INITIAL _ CAPACITY : HashMap 的默认容量,16
MAXIMUM _ CAPACITY : HashMap 的最大支持容量,2^30
DEFAULTLOAD _ FACTOR : HashMap 的默认加载因子,0.75
TREEIFY _ THRESHOLD : Bucket 中链表长度大于该默认值,转化为红黑树,8
UNTREEIFY _ THRESHOLD : Bucket 中红黑树存储的 Node 小于该默认值,转化为链表 。
MIN _ TREEIFY _ CAPACITY :桶中的 Node 被树化时最小的 hash 表容量。(当桶中 Node 的数量大到需要变红黑树时,若 hash 表容量小于 MIN _ TREEIFY _ CAPACITY 时,此时应执行 resize 扩容操作这个 MIN _ TREEIFY _ CAPACITY 的值至少是 TREEIFY _ THRESHOLD 的4倍。
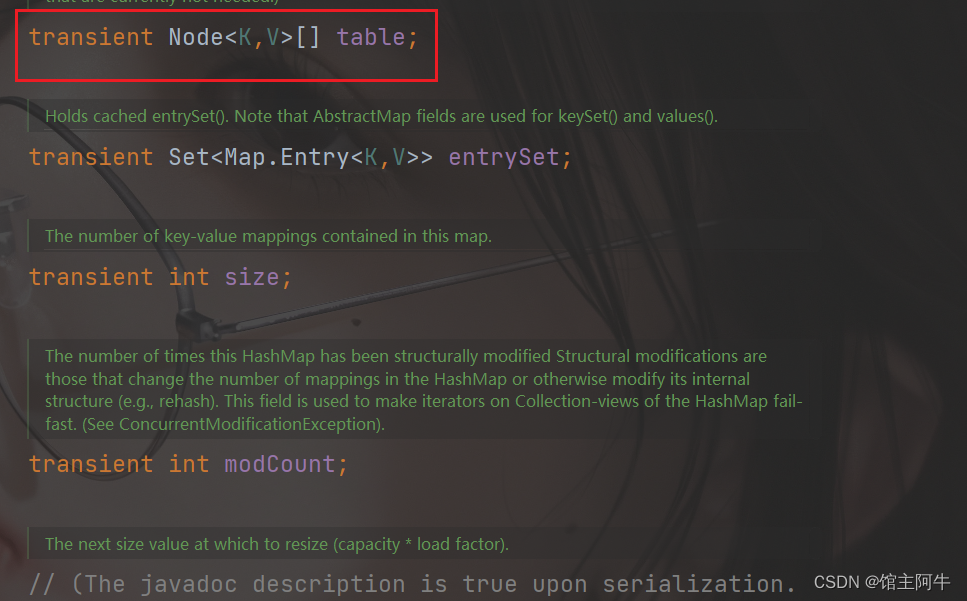
table :存储元素的数组,总是2的 n 次幕
entrySet :存储具体元素的集
size : HashMap 中存储的键值对的数量
modCount : HashMap 扩容和结构改变的次数。
threshold :扩容的临界值,=容量*填充因子=16*0.75=12
loadFactor :填充因子,创建HashMap时会将 DEFAULTLOAD _ FACTOR 赋值给它,即0.75
标红的几个变量要尤其注意!
那么接下来我们来分析了!
首先创建HashMap对象:

首先给填充因子loadFactor赋值为0.75!
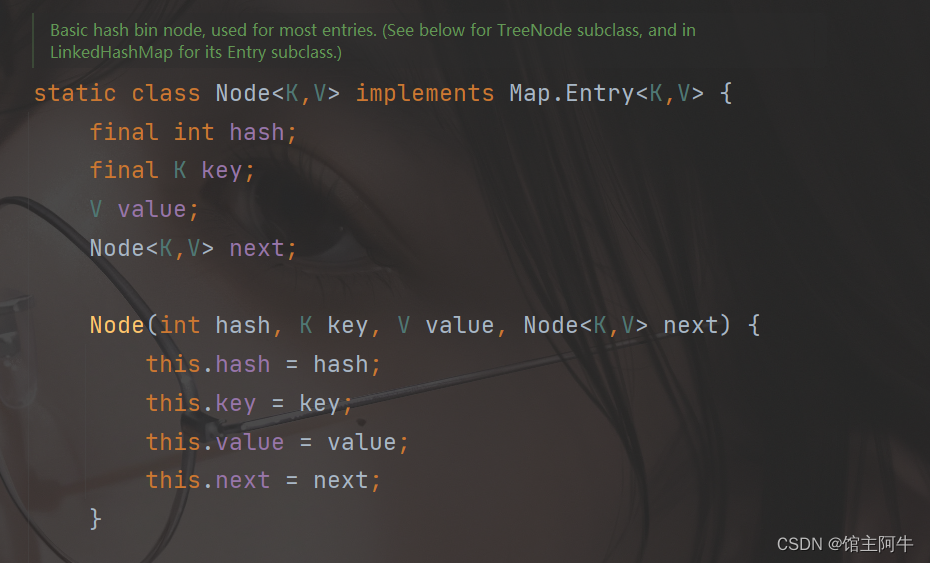
然后再来看看装这个key-value的Node类型的数组以及Node内部类(jdk7为Entry类型的数组,都一样,换了个名)
然后我们就需要从put方法入手看看发生了什么:

需要计算一个key的Hash值

用到了HashCode方法,这就是为啥我们说重写equals有时要重写HashCode,我们当时在HashSet那片中写过!
putVal这个方法里分支较多,我们要慢慢看,不难!
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
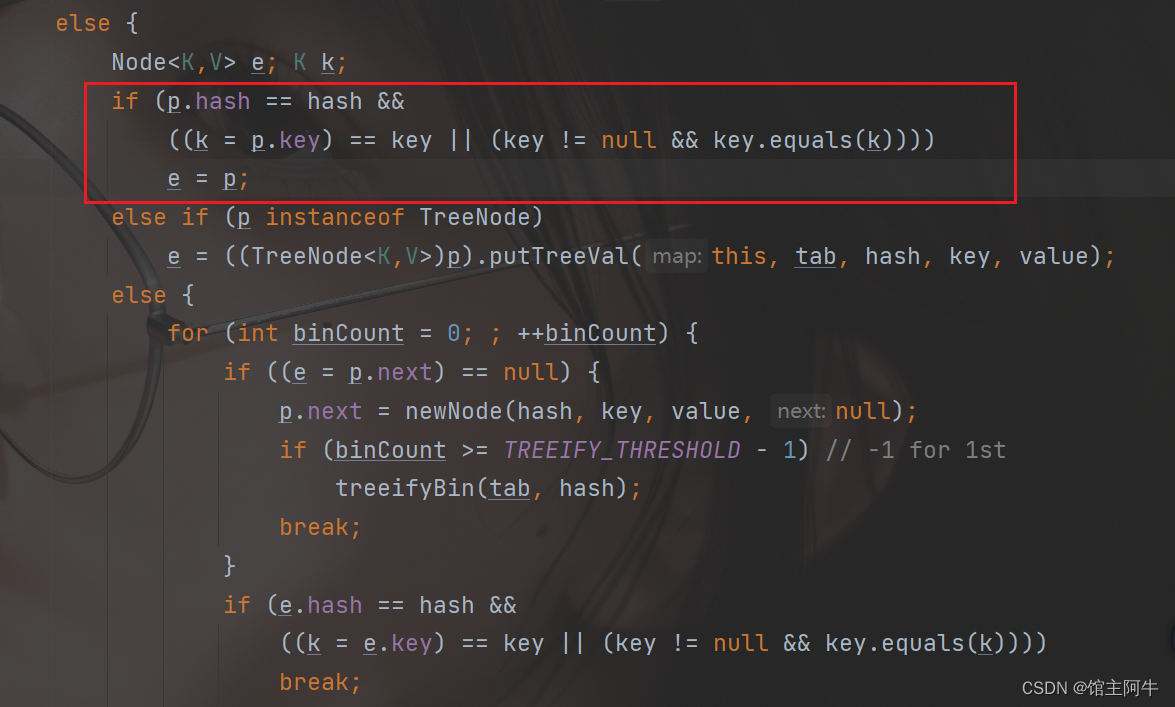
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
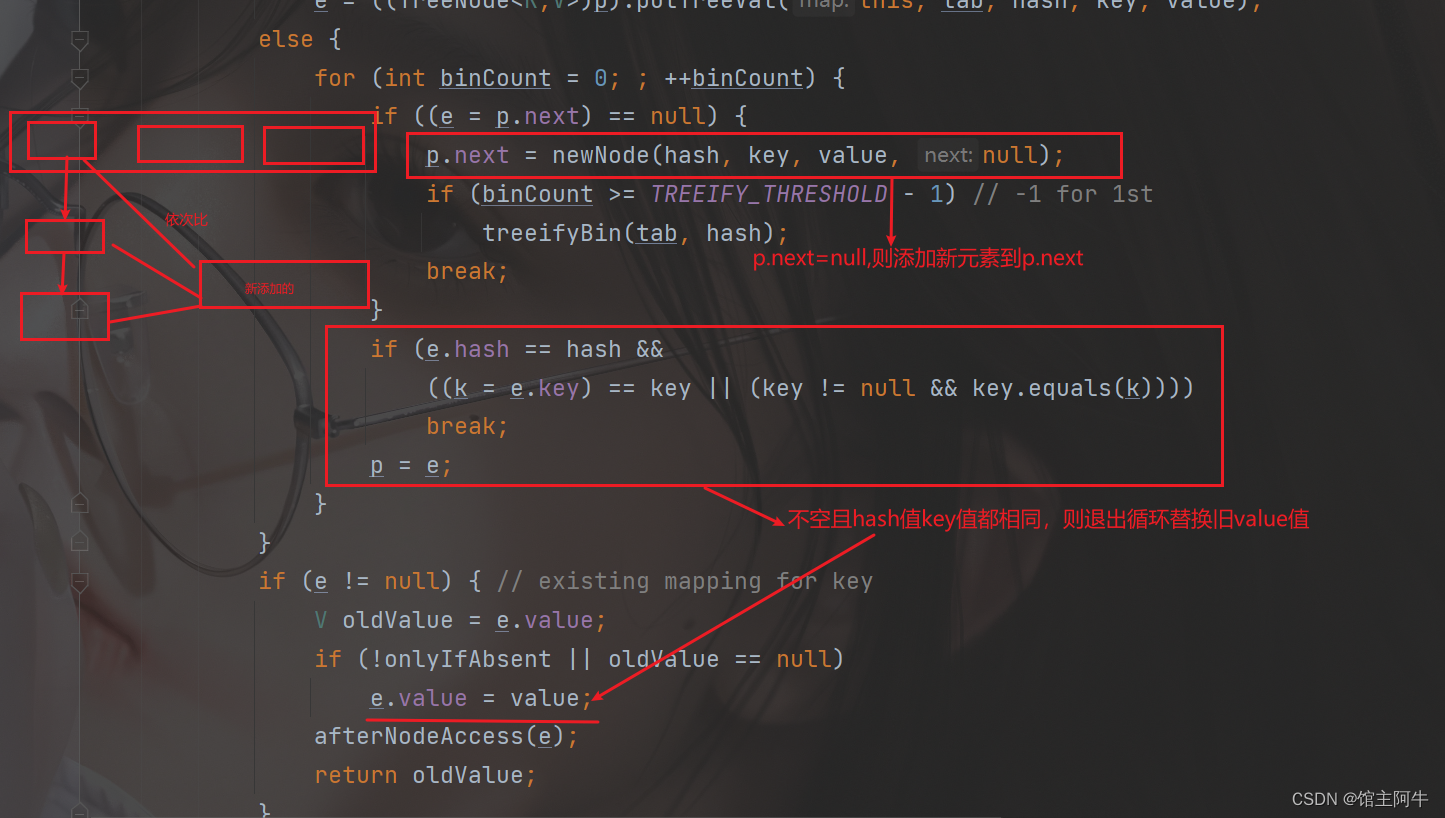
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
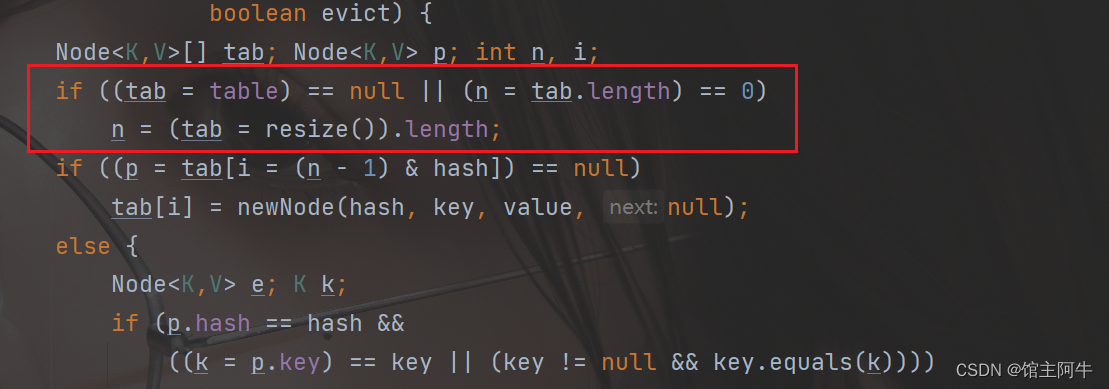
这一块说明数组为空,也就是我们刚开始添加数据!
此时执行resize()方法扩容!
这个resize的逻辑分支也多,通过分析,首次put元素,resize会将底层数组长度创建好,长度为16!
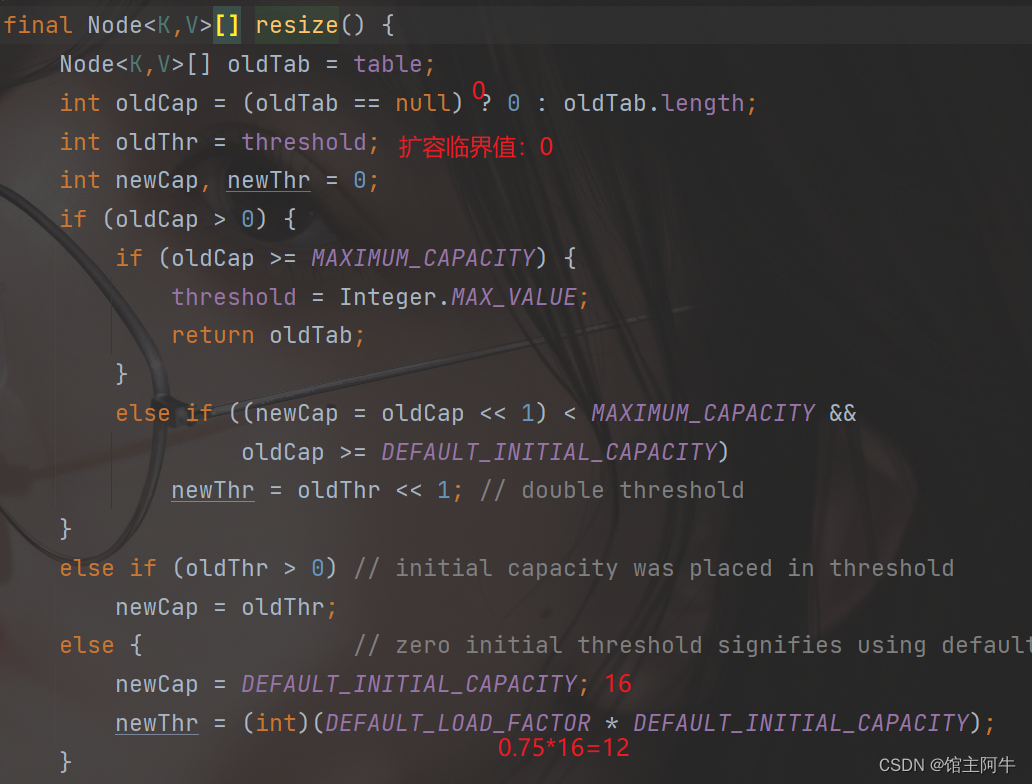

我们继续回到putVal方法:
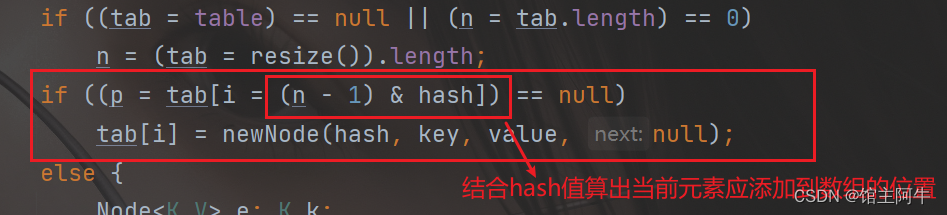
如果当前的要添加元素的数组位置为空,则将这个元素添加到这个位置!
如果数组位置不为空
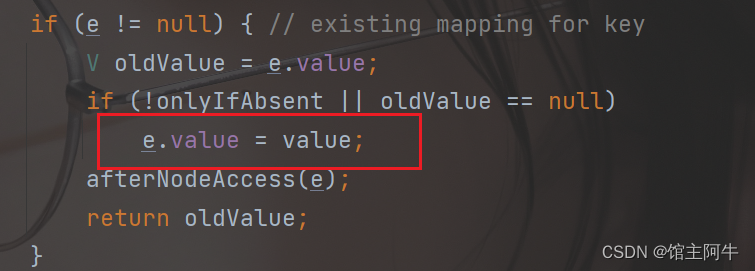
如果要添加元素Hash值和当前位置元素的Hash值相同,且key值也相同,则替换value值。
如果Hash值不同或者key值不同,则循环比较链表中的元素
还有一层就是当前链表长度大于等于8时,转换为红黑树存储链表元素
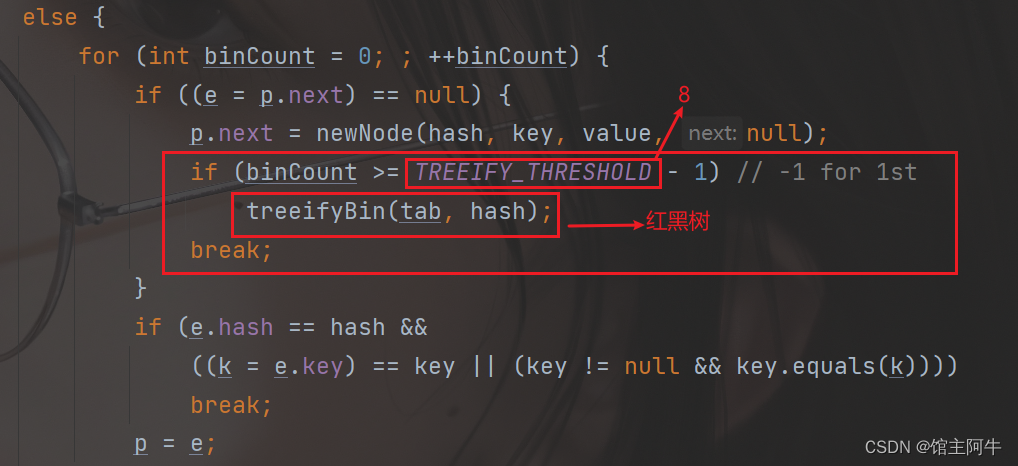
但我们进入到treeifyBin发现当前链表长度大于等于8时,不一定转换为红黑树存储链表元素
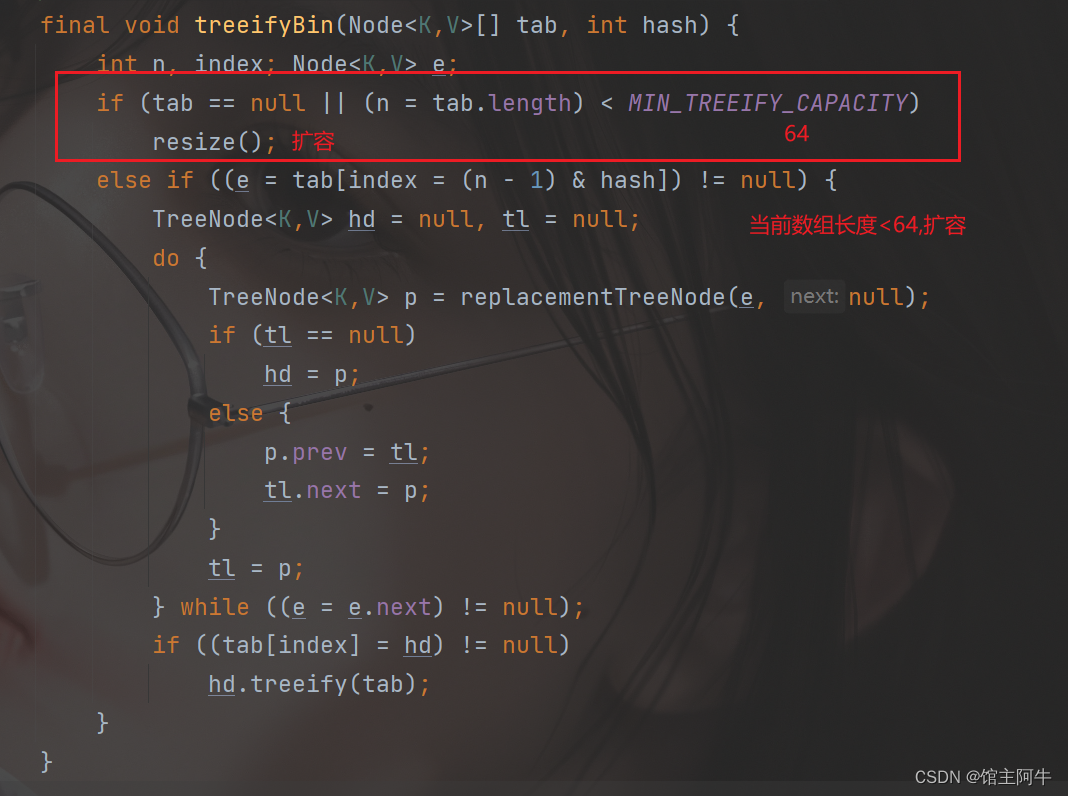
还要满足当前数组长度大于64才转变为红黑树,否则就扩容一下底层数组,让链表长度短一些就行,毕竟红黑树是个比较复杂的树形结构!
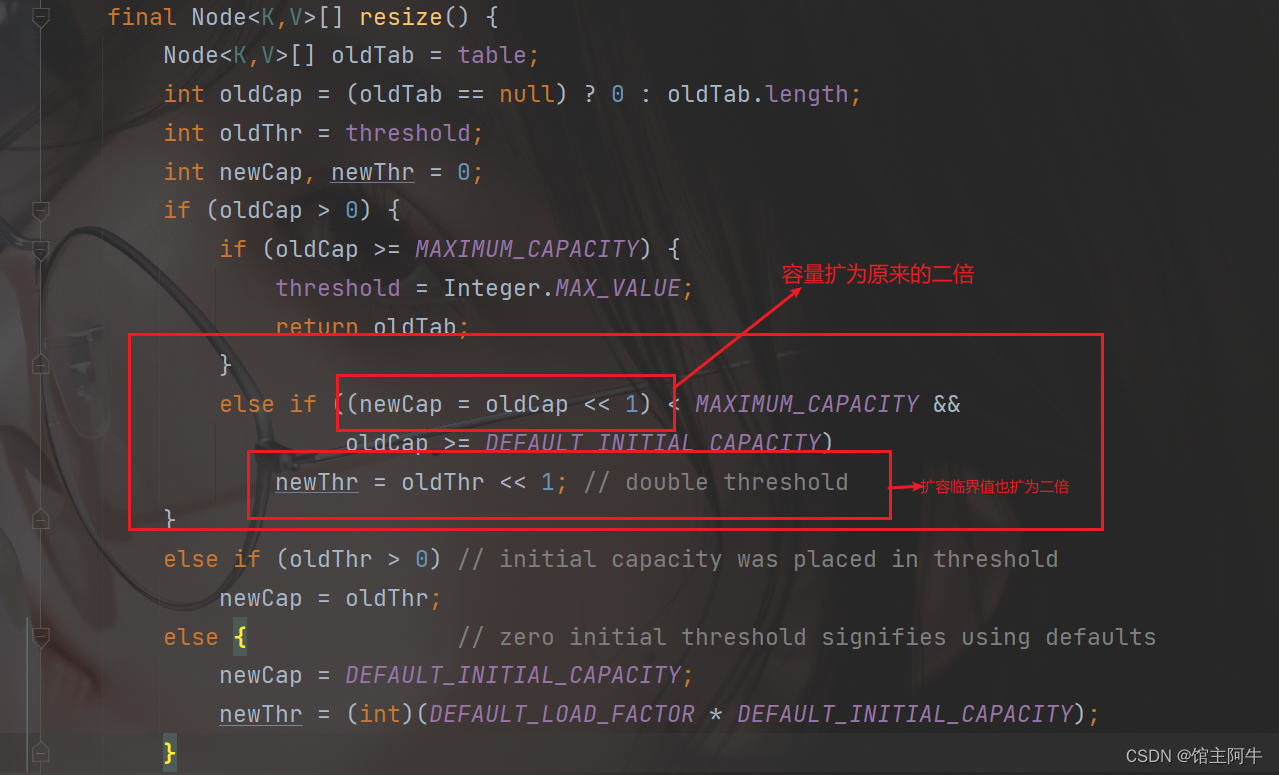
关于扩容:
总结
jdk7
HashMap map = newHashMap ();
在实例化以后,底层创建了长度是16的一数组 Entry [ ] table。
然后进行put (key1,value1)添加元素:
首先,调用key1所在类的 hashCode ()计算key1哈希值,此哈希值经过某种算法计算以后,得到在 Entry 数组中的存放位置。
- 如果此位置上的数据为空,此时的key1-value1添加成功。——>情况一
- 如果此位量上的数据不为空,(意味着此位置上存在一个或多个数据(以链表形式存在)),比较key1和已经存在的一个或多个数据key的哈希值:
- 如果key1的哈希值与已经存在的数据的哈希值不相同,此时key1-value1添加成功。——>情况二
- 如果key1的哈希值和已经存在的某一个数据(key2-value2)的哈希值相同,继续比较:调用key1所在类的 equals(key2)
- 如果 equals ()返回 false :此时key1-value1添加成功。——>情况三
- 如果 equals ()返回 true :使用value1替换value2。
补充:关于情况二和情况三:此时key1-value1和原来的数据以链表的方式存储,在不断的添加过程中,会涉及到扩容问题,默认的扩容方式:数组长度扩容为原来容量的2倍,并将原有的数据复制过来。扩容临界值也扩为原来的2倍!
jdk8
jdk8相较于jdk7在底层实现方面的不同:
- new HashMap():底层没有创建一个长度为16的数组。
- jdk8底层的数组是: Node [],而非 Entry []。
- 首次调用 put ()方法时,底层创建长度为16的数组。
- jdk7底层结构只有:数组+链表。jdk8中底层结构:数组+链表+红黑树。当数组的某一个索引位置上的元素以链表形式存在的数据个数>=8且当前数组的长度>64时,此时此索引位置上的所有数据改为使用红黑树存储。
结语
如果你觉得博主写的还不错的话,可以关注一下当前专栏,博主会更完这个系列的哦!也欢迎订阅博主的其他好的专栏。
🏰系列专栏
👉软磨 css
👉硬泡 javascript
👉flask框架快速入门