头节点存在的目的:
在单链表的使用中,头结点(Header Node)是一个常用的概念,特别是在进行链表操作时。头结点不是数据域中实际存储的数据节点,而是作为链表操作的辅助节点,它包含对第一个实际数据节点的引用。以下是一些在使用单链表时可能需要头结点的情况:
1. **简化插入操作**:头结点可以简化插入操作,特别是在插入节点到链表的头部时。不需要修改已有节点的指针,只需要改变头结点的指针即可。
2. **统一插入和删除操作**:头结点使得对链表的插入和删除操作更加统一。无论是插入还是删除,都可以通过头结点来定位到操作位置的前一个节点,而不需要关心链表的具体内容。
3. **处理空链表**:在处理空链表时,头结点非常有用。例如,当检查链表是否为空时,只需要检查头结点的指针是否为`NULL`,而不需要遍历整个链表。
4. **保护头结点**:头结点可以作为链表的防护措施,当链表为空时,头结点可以防止访问非法的内存地址。
5. **方便遍历链表**:头结点可以作为遍历链表的起点,从头结点开始,可以逐一访问链表中的每个节点。
6. **实现双向链表**:在实现双向链表时,头结点可以同时存储向前和向后的指针,这样可以更方便地实现双向遍历和操作。
总结来说,头结点在单链表的使用中提供了许多便利,它使得链表的操作更加简洁、统一,并且更加安全和高效。因此,在实现和操作单链表时,头结点是一个非常有用的工具。
当然很多时候你也是可以不进行初始化的。但是初始化之后对于代码是书写可以更方便。
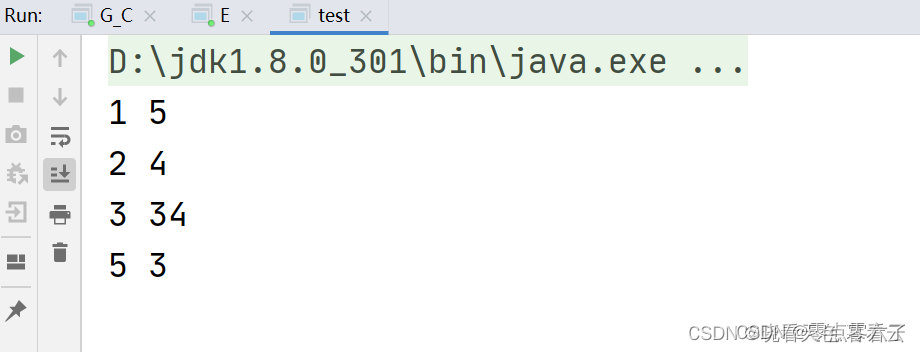
举例哨兵位的申请和头结点的申请的区别:
在C语言中,哨兵位节点和申请空间的实现代码主要区别在于它们各自的应用场景和目的。
1. 哨兵位节点:
哨兵位节点通常用于解决链表中的循环链表问题。在循环链表中,我们需要一个特殊的节点来标记链表的末尾,这个特殊的节点就是哨兵位节点。哨兵位节点的实现代码通常包括创建一个哨兵位节点,并将其指向链表的头节点。
以下是一个简单的哨兵位节点的实现代码:
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int data;
struct Node* next;
} Node;
Node* createSentryNode(Node* head) {
Node* sentry = (Node*)malloc(sizeof(Node));
sentry->data = -1; // 哨兵位节点的数据域通常设置为一个特殊值,如-1
sentry->next = head;
return sentry;
}
int main() {
Node* head = (Node*)malloc(sizeof(Node));
head->data = 1;
head->next = (Node*)malloc(sizeof(Node));
head->next->data = 2;
head->next->next = (Node*)malloc(sizeof(Node));
head->next->next->data = 3;
head->next->next->next = head; // 创建循环链表
Node* sentry = createSentryNode(head);
// 接下来可以使用sentry节点进行循环链表的操作,如查找、删除等
return 0;
}
2. 申请空间的申请代码:
申请空间的申请代码通常用于动态分配内存空间,例如在程序运行过程中创建动态数据结构。在C语言中,我们通常使用`malloc()`函数来申请内存空间。
以下是一个简单的申请空间的实现代码:
#include <stdio.h>
#include <stdlib.h>
int main() {
int* ptr = (int*)malloc(sizeof(int)); // 申请一个整数大小的内存空间
if (ptr == NULL) {
printf("内存申请失败\n");
return 1;
}
*ptr = 42; // 在申请的内存空间中存储一个整数
printf("存储的整数: %d\n", *ptr);
free(ptr); // 释放申请的内存空间
return 0;
}
//SList.c文件
#include"SList.h"
//链表的申请空间
SLTNode* SLBuyNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("newnode:error");
exit(1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}