【论文速递】TPAMI2022 - 小样本分割的整体原型激活
【论文原文】:Holistic Prototype Activation for Few-Shot Segmentation
获取地址:https://ieeexplore.ieee.org/document/9839487
CSDN下载:https://download.csdn.net/download/qq_36396104/87381093
博主关键词: 小样本学习,语义分割,整体性,原型
推荐相关论文:
【论文速递】CVPR2022 - 学习 什么不能分割:小样本分割的新视角
- https://blog.csdn.net/qq_36396104/article/details/128658168
摘要:
近年来,传统的基于深度cnn的分割方法取得了令人满意的性能,但其本质上是大数据驱动技术,难以推广到未见类别。随后开发了小样本分割,以在低数据状态下执行相关操作。遗憾的是,由于训练范式和网络架构的因素,现有方法容易对基类目标进行过拟合,分割边界不准确,在一定程度上阻碍了研究的进展。在本文中,我们提出了一个整体原型激活(HPA)网络来缓解这些问题。其新颖的设计可以概括为三个方面:1)一种无需训练的派生基类先验表示的方案。2)原型激活模块(PAM),通过高置信度过滤不相关类的对象,生成可靠的激活映射和匹配良好的查询特征。3)交叉引用译码器(cross - reference Decoder, CRD)用于交互特征加权和多层次特征聚合。 在标准小样本分割基准(PASCAL-5i和COCO-20i)上进行的大量实验验证了该方法的有效性。此外,在弱标签分割、零样本分割和视频对象分割等多个扩展任务上的优异性能也说明了它的灵活性和多功能性。我们的代码可以在https://github.com/chunbolang/HPA上公开获取。
关键词 -小样本学习,小样本分割,语义分割,原型激活,交叉引用
简介:
通过大规模标记数据集,深度卷积神经网络(cnn)在图像识别、目标检测、语义分割等多个视觉任务中取得了前所未有的研究进展[1][2][3][4][5][6][7][8]。然而,收集如此庞大的带注释的训练样本需要消耗大量的人力和物力,特别是对于密集的预测问题(如分割)。因此研究了一系列半监督和弱监督方法,但对大量全标记或弱标记图像的要求的性质没有改变[9]。此外,当推理阶段在未见类别上执行时,模型的泛化能力可能是脆弱的。在这种情况下,为了解决上述问题,提出了小样本学习(FSL),即学习可转移的元知识,然后利用很少的可用信息将其泛化[10]。
在本文中,我们进行了FSL在图像分割领域的应用,称为小样本分割(FSS)。给定一个要分割的原始(查询)图像,FSS模型将利用几个密集注释(支持)图像提供的信息,根据建立的语义类别检索目标区域。支持样本越少,任务就越有挑战性。在最极端的情况下,这些模型要求仅依靠一个支持数据从背景中分割物体,也称为1-shot segmentation。
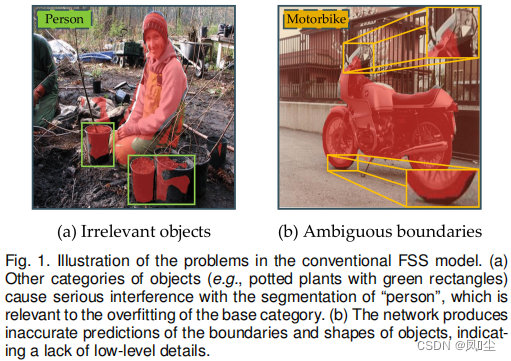
一般来说,FSS框架通过掩码平均池化操作[12]提取特定类别(即原型[11])的特征表示,然后将其嵌入到查询分支中,以某种方式指导分割,例如SG-One[12]中的“空间注意和乘法”,FWB[13]中的“空间注意和串联”,CANet[14]中的“扩展和串联”。然而,在 上述框架的指导阶段,只考虑了单一的前景表示,在抵抗不相关的语义对象[15][16][17]时表现出较低的性能,如图1(a)所示。从更广泛的角度来看, 网络倾向于过度拟合基本类别,导致区域的虚假激活。事实上,这是有道理的 。例如,给定“桌子”(基本)和“椅子”(新奇)两个语义类别,网络如何借助“椅子”原型成功地在包含这两个类别的查询图像中确定“桌子”作为背景? 毕竟,这两个类在语义上比后台类更相似。此外,由于数据有限和网络设计不合理,预测结果中存在典型的欠分割现象,主要表现为目标体不完整或边界模糊(如图1(b))。本文主要针对这两个问题。
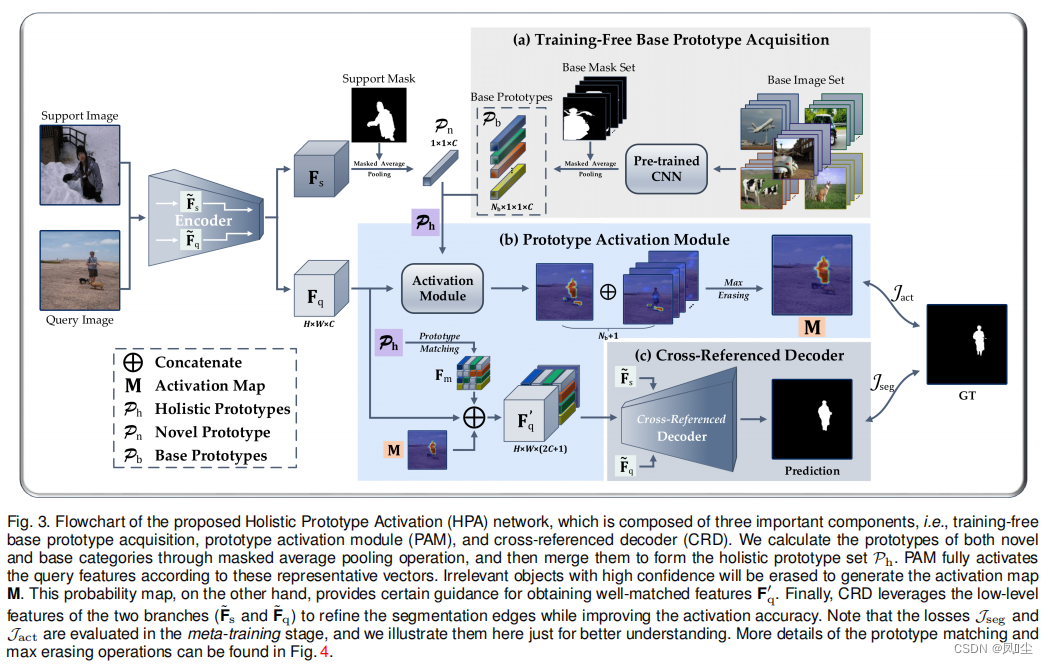
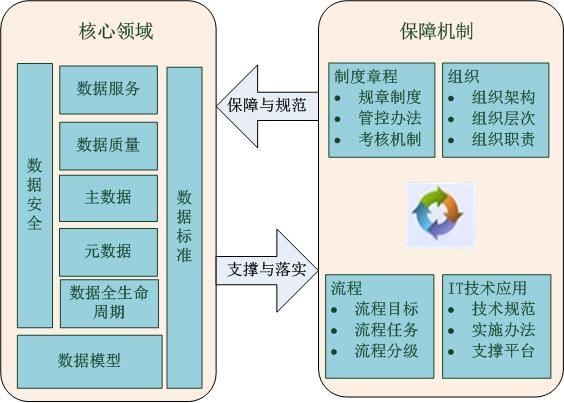
对于第一个问题,我们认为一些基本类别的信息在元构建阶段也有帮助,但在以前的工作中被忽略了。 还是以上面提到的“桌子”和“椅子”的分割任务为例,既然很难利用“椅子”的特征来识别“桌子”,为什么不引入“桌子”本身的特征来辅助这个过程呢?换句话说,如果一个像素或一个区域与“表”类非常相似,那么我们可以将其归类为高置信度的背景。基于这一概念的最简单的实现之一是修改Wang et al.[15]提出的PANet。具体而言,在元训练阶段结束时,将部分基础数据集馈送到训练良好的骨干网络中,得到每个类的原型,并在测试时将这些代表性向量补充到无参数最近邻分类器中。但是这种像素-像素分割操作复杂度高,预测结果不自然(请参考[15]的失败案例),因此我们换一种思路进行探讨。所提出的原型激活模块(PAM)将基本原型与当前的新原型集成在一起,形成一个整体原型集,然后根据这个集合激活查询图像中每个目标的区域。如果对象区域被基础原型以高置信度激活,则对应的位置将在最终的激活映射中被擦除(即设置为0)。按照先进的FSS架构[18][19],该特征映射以拼接的形式嵌入到查询分支中。另外,对近期论文[14][17][18][20]中常用的“expand & concenate”操作也做了相应的修改。在每个位置选择和特征向量最相似的原型并放置,提供一个匹配良好的特征作为参考。
对于第二个问题,一个直观的解决方案是引入查询图像的低级特征,就像几个高级语义分割框架[21][22][23]设计的那样。 虽然这可能有助于分割边界的细化,但仍然存在目标体不完整的现象。我们认为,在样本有限的情况下,提高前景激活精度的关键是捕捉支持图像和查询图像之间的共存特征,然而,在单个原型的指导下,仅通过像素级特征匹配是远远不够的。因此,交叉引用译码器(cross - reference Decoder, CRD)的提出统一地缓解了上述问题。基于DeepLabv3+[21]解码器构建了CRD模块。在此基础上,采用一种包含两个互补分支的交互特征加权方案,分别对底层特征映射的相互依赖和自我依赖进行建模请注意,这种重新加权策略只包含一个可学习的参数来平衡两个分支的贡献,这对需要避免过拟合的FSS范式非常友好。然后将处理后的特征以多级特征聚合的方式与主路径的高级语义特征合并,丰富了分割线索。
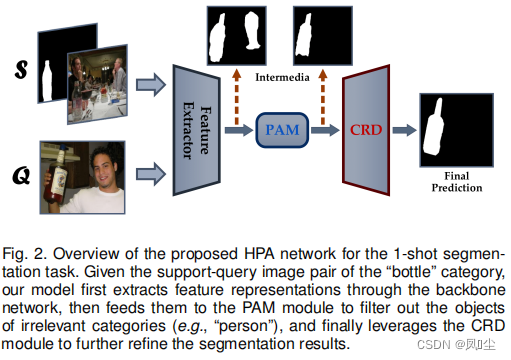
在上述两个模块的基础上,我们建立了一个新的FSS框架,称为整体原型激活(HPA)。 图2说明了我们的模型的数据流,并简单地显示了每个组件的作用。给定特定类别(例如,瓶子)的查询图像,PAM模块通过抑制基本类别的不相关对象(例如,人)来处理提取的特征,并给出粗粒度的预测。最后,CRD模块利用底层信息细化分割结果,生成精确的对象边界。
在多种基准上进行了大量实验,验证了HPA的有效性,HPA的性能大大优于先进的方法。此外,令人惊讶的是,所提出的模型/组件在几个扩展任务上也表现出了出色的性能,如广义小样本分割、弱标签分割、零样本分割和视频对象分割。据我们所知,这是第一次如此全面地研究FSS模型在多个密集预测任务上的可转移性和可扩展性。 主要工作成果如下:
- 提出了一种利用基本类别信息为模型推理提供更多支持的新思想,这在以前的工作中被忽略了。
- 我们为FSS开发了一个整体原型激活(HPA)网络,以缓解基类的过拟合并生成准确的分割边界。据我们所知,这是第一个明确利用基础原型来解决FSS中的过拟合问题的工作。
- 所提出的PAM和CRD模块分别可作为原型匹配和特征解码器的大容量即插即用组件。
- HPA在PASCAL-5i和COCO-20i数据集上都取得了优异的性能,大大超过了先进的方法。